7 De las palabras a las clases de palabras
7.1 Introducción
En los capítulos precedentes has estado trabajando con las palabras de los textos desde el punto de vista gráfico, es decir, has considerado una palabra como una secuencia de caracteres (letras diría la RAE) entre dos espacios en blanco o signos de puntuación. Con esta concepción se puede averiguar muchas cosas sobre los textos, y seguirás usándola en alguno de los capítulos que restan, pero vamos a detenernos un poco en el análisis de las clases de palabras.
El etiquetado gramatical, a veces llamado desambiguación léxica, (PoS tagging = Parts of Speech Tagging = ‘etiquetado de las partes de oración’) es uno de los problemas a los que los expertos en NLProc (Natural Language Processing) han dedicado muchas horas de trabajo y han creado herramientas realmente fantásticas, sobre todo para el inglés. Las hay para muchas lenguas, incluida la española, pero no son tan buenas como las desarrolladas para el inglés o, cuando lo son, no son sencillas de usar o no se hablan con R.
Dentro del entorno de R hay varios paquetes que pueden etiquetar morfológicamente un texto. Son paquetes como {koRpus} que depende de {Treetagger}; {coreNLP} que depende de las librarías Java del Stanford Core NLP. La librería {cleanNLP} ha sido la última en aparecer, la instalación depende del Stanford Core NLP o de spaCy que dependen de Java y de Python respectivamente. Tienes una tercera posibilidad más sencilla de usar, el paquete {udpipe}, que es el que vas a usar mínimamente aquí.
7.1.1 Etiquetado gramatical automático (PoS Tagging)
El etiquetado gramatical es una forma de anotar las palabras de un texto con la categoría gramatical o clase de palabras (sustantivo, preposición, verbo, determinante…) correspondiente con una serie de etiquetas.
| A | María | le | gustan | los | helados |
| ADP | PROPN | PRON | VERB | DET | NOUN |
En el ejemplo anterior (tabla 7.1), etiquetado con el sistema de etiquetas del Universal POS Tag (UPOS) del proyecto de Universal Dependencies, ADP indica que es una preposición; PROPN que es un nombre propio; PRON que es un pronombre, VERB que se trata de un verbo; DET que es un determinante y NOUN un sustantivo común. Pero dependiendo de los sistemas y herramientas de etiquetado, la información puede ser muy detallada como en el caso de FreeLing, que utiliza el sistema de etiquetas Eagles. El resultado del análisis de de la misma oración con Freeling es el de la tabla 7.2.
| A | SPS00 |
| María | NP00SP0 |
| le | PP3CSD00 |
| gustan | VMIP3P0 |
| los | DA0MP0 |
| helados | NCMP000 |
Fíjate en el verbo gustan y en el sustantivo helados del cuadro anterior. La secuencia de letras y números en el caso de gusta informan de que es un verbo (V) principal (M), indicativo (I), presente (P), tercera persona (3) del singular (P); en el caso de helados indican que se trata de un sustantivo (N), común (C), masculino (M) y singular (P). Los ceros anulan las posiciones no utilizadas. Fíjate en María, es nombre (N) propio (P), como no puede tener género ni número en esas posiciones (tercera y cuarta) presenta sendos ceros, pero en la quinta y sexta posiciones helados tiene ceros, en cambio María aclara que se trata de un nombre de persona (SP).
Algunos de los sistemas de análisis automatizado son una maravilla y permiten análisis sintácticos en forma de árboles como el de la figura 7.1 y también de correferencias como el de la figura 7.2), en el que además tienes las notación fonética amplia.
](imagenes/07-arbol_udpipe.png)
Figura 7.1: Árbol sintáctico obtenido con UDPipe en línea
](imagenes/07-arbol_freeling.png)
Figura 7.2: Análisis de correferencia y notación fonética obtenido con la demo de Freeling
El asignar las etiquetas automáticamente a cada palabra puede parecer una tarea sencilla, sin embargo, es muy complicada puesto que muchas palabras pueden pertenecer a más de una categoría. Por ejemplo, la palabra sobre puede ser un sustantivo o una preposición en una oración como Tráeme el sobre que está sobre la mesa. Canto puede ser sustantivo, como en El canto del gallo o en Se golpeó con el canto de la puerta, o un verbo Mañana canto en Madrid. Bajo puede ser adjetivo en La casa tiene el techo bajo, primera persona del presente de indicativo del verbo bajar en Ahora bajo del desván, sustantivo cuando se refiere al instrumento musical como en Me gustó cómo tocaba el bajo y una preposición en El delincuente está bajo vigilancia. La máquinas se pueden volver locas con frases como El hombre bajo que está bajo las escaleras toca el bajo. Por este motivo se han desarrollado diversos algoritmos de aprendizaje automático (Learning machine) para realizar estas tareas. Unos se basa en corpus que han sido anotados manualmente y otros en reglas del tipo: si la palabra X es desconocida o ambigua, si le precede un determinante y le sigue un verbo, entonces es un sustantivo.
7.2 Etiquetado con {udpipe}
Instalar esta librería es tan sencillo como cualquier otra de R. Basta con que ejecutes en la consola
Recuerda que, una vez instalada, cuando tengas que utilizarla, la tendrás que invocar con
Así que instálala e invócala. Carga también la librería {tidyverse}.
El siguiente paso es bajar de internet el modelo de lengua. Para el español hay dos, son igual de buenos e igual de malos, pero como tu objetivo, por ahora, no es un análisis científico, sino aprender, descargarás ambos. Ten en cuenta que se guardarán en el directorio de trabajo. Usa estas dos instrucciones:
Tardará unos minutos en bajar. Todo depende de la conexión. Durante la descarga del modelo ancora aparecerá algo semejante a lo que hay en la casilla siguiente, pero lo referente al sitio dónde se grabará será diferente (son las líneas que comienzan /Users/JMFR/Dropbox/cuentapalabras, pues depende del directorio de trabajo y su ubicación dentro de cada ordenador).
Downloading udpipe model from https://raw.githubusercontent.com/jwijffels/udpipe.models.ud.2.4/master/inst/udpipe-ud-2.4-190531/spanish-ancora-ud-2.4-190531.udpipe to /Users/JMFR/Dropbox/cuentapalabras/spanish-ancora-ud-2.4-190531.udpipe
Visit https://github.com/jwijffels/udpipe.models.ud.2.4 for model license details
probando la URL 'https://raw.githubusercontent.com/jwijffels/udpipe.models.ud.2.4/master/inst/udpipe-ud-2.4-190531/spanish-ancora-ud-2.4-190531.udpipe'
Content type 'application/octet-stream' length 20319093 bytes (19.4 MB)
==================================================
downloaded 19.4 MB
language file_model
1 spanish-ancora /Users/JMFR/Dropbox/cuentapalabras/spanish-ancora-ud-2.4-190531.udpipe
url
1 https://raw.githubusercontent.com/jwijffels/udpipe.models.ud.2.4/master/inst/udpipe-ud-2.4-190531/spanish-ancora-ud-2.4-190531.udpipe
download_failed download_message
1 FALSE OKSi todo ha ido bien, en el directorio cuentapalabras tendrás dos ficheros con los nombres
spanish-ancora-ud-2.4-190531.udpipe
spanish-gsd-ud-2.4-190531.udpipePero es posible que la secuencia de números tras ud quizá sea diferente, todo depende de la versión que tengas de la librería {udpipe} y la fecha de descarga. Estos dos ficheros ocupan 20.3 y 28 MB respectivamente. Una vez descargados los modelos, los tendrás siempre a mano, por lo que no es necesario descargarlos cada vez que quieras usarlos. Al igual que con las librerías, el que lo hayas descargado, no supone que esté disponible en R, por lo que el siguiente paso es cargar el modelo en la memoria del ordenador. Para tenerlos claros, pues puedes cargar ambos, yo empleo los nombres modelo_gsd y modelo_ancora, pero solo utilizaré en esta explicación el modelo_ancora. La forma de cargarlos es (comprueba en tu ordenador cuál es la secuencia de dígitos y cámbiala si es necesario en cualquiera de las dos órdenes que hay a continuación).
para el modelo_ancora. Para el modelo-gsd
Para explicarte cómo funciona y mostrarte mínimamente lo que hace, vas a crear un vector de caracteres para que lo analice. Corta y pega en el editor de RStudio el texto de la casilla que hay a continuación y ejecuta la orden para que se almacene en la memoria de R.
texto <- "Se me permitirá que antes de referir el gran suceso de que fui testigo, diga algunas palabras sobre mi infancia, explicando por qué extraña manera me llevaron los azares de la vida a presenciar la terrible catástrofe de nuestra marina."texto <- iconv(texto, from = "Latin1", to = "UTF-8") para que {udpipe} pueda analizarlo.
Ahora hay que analizarlo. Para ello crearás un nuevo objeto, llámalo analisis, en el que se guardará el resultado del etiquetado que se realiza con udpipe_annotate(). Esta función exige dos argumentos: el modelo de análisis, en tu caso es lo que creaste en el paso anterior y tienes guardado en modelo_ancora y el texto que analizará, que es el que acabas de cortar y pegar.
Tan pronto como la ejecutes, se creará un objeto llamado analisis. Es de un tipo peculiar, una lista. Quizá el tipo de objeto de R más enredado y complicado de manejar. Como el resultado de analisis es, en realidad, una tabla, la vas a convertir a una tibble.
Ahora tienes una vieja conocida, una tabla con 43 líneas (observaciones) y 14 variables (columnas). Vas a examinarla para que te explique qué es lo que contiene cada una de las columnas, aunque todas no serán útiles y podrás ignorarlas.
¿Recuerdas cómo ver el contenido de un objeto Data en RStudio? O haces clic en el nombre del objeto en la pestaña Environment, o escribes en la consola View() y entre los paréntesis escribes el nombre del objeto que quieres curiosear; en este caso View(analisis). Una vez que lo hayas hecho, se abrirá una nueva pestaña en la zona del editor. Dependiendo del ancho de la ventana del editor, verás más o menos material. Yo he agrandado la ventana para poder ver las 20 primeras entradas (filas) y casi todas las columnas, como puedes ver en la figura 7.3. Pero todo depende de la pantalla que tenga tu ordenador.
.png)
Figura 7.3: Figura 3. Contenido de analisis tras analizarlo con udpipe
Al ejecutarse la orden, R ha realizado muchísimo trabajo. Ha dividido el texto en oraciones (sentence), aunque en este caso el párrafo (paragraph_id) solo tiene una oración (sentence_id). Lo ha dividido en palabras-token –incluida la puntuación– (token), las ha numerado (token_id), las ha lematizado (lemma), ha asignado las etiquetas según el estándar UPOS Tag Set (upos), y ha extraído los rasgos morfológicos de cada palabra (feats). Fíjate en todo lo que es capaz de hacer en muy poco tiempo. De acuerdo, la muestra es muy breve.
De todas las columnas de esta enorme tabla, las más importantes son las etiquetadas upos, token y lemma. Las demás pueden ser interesantes, especialmente la columna feats (= rasgos) porque ofrece los detalles morfológicos de cada una de las palabras. Las que no tienen ningún interés son las dos últimas columnas porque está prácticamente vacías. deps no tiene ningún contenido, de ahí los NA y misc no informa de gran cosa puesto que la gran mayoría de las casillas también están vacías (NA).
Es un hecho confirmado, aunque no cuantificado para el español, que la clase de palabras más abundante en cualquier texto son los sustantivos. Pero ya no es tan fácil decidir si en un texto abundan más los verbos o los adjetivos. Si los adverbios abundan o escasean… Toda esa información la tienes recogida en la tabla analisis. Extraigamos el contenido. Puedes hacerlo con
Tan pronto como ejecutes el código anterior, aparecerá en la consola el resultado en forma de tabla.
## # A tibble: 10 × 2
## upos n
## <chr> <int>
## 1 NOUN 9
## 2 DET 8
## 3 ADP 7
## 4 VERB 6
## 5 ADJ 3
## 6 PRON 3
## 7 PUNCT 3
## 8 SCONJ 2
## 9 ADV 1
## 10 AUX 1Se confirma que los sustantivos (NOUN) es la clase de palabras más abundante (en el ejemplo), seguida por los determinantes (DET) y las preposiciones (ADP). Hay dos conjunciones subordinantes (SCONJ), un adverbio (ADV) y un verbo auxiliar (AUX). Pero has visto que las tablas no son lo mejor para comunicar rápida y eficazmente los resultados. Aquí sí porque la muestra textual es muy breve, tan solo un párrafo, con una única oración y 43 palabras-token y 32 palabras-tipo. Pero lo puedes mostrar con facilidad con una gráfica como la de la figura 7.4.
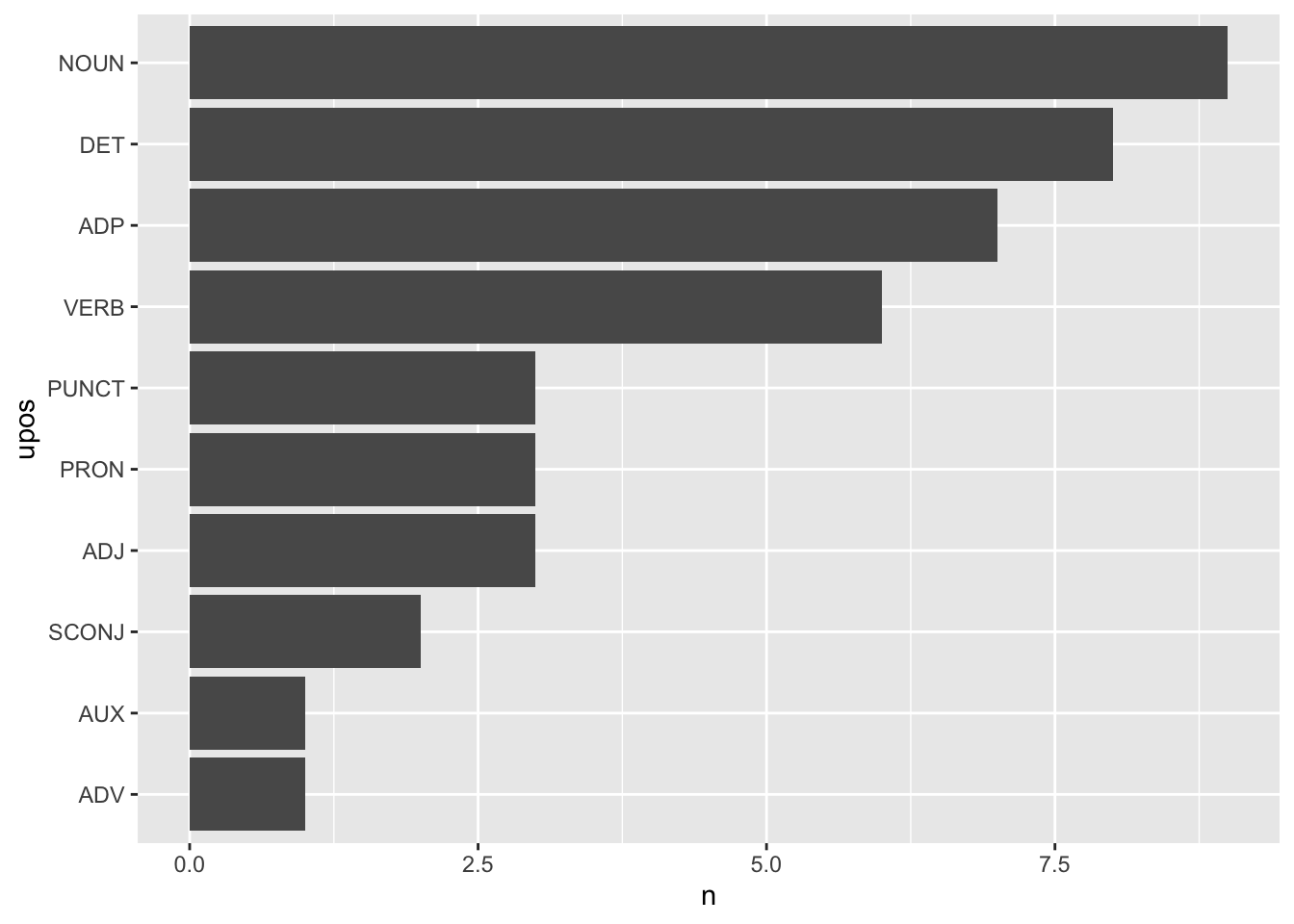
Figura 7.4: Recuento de las distintas categorías gramaticales en la frase de ejemplo
Esta gráfica se traza con unas pocas líneas de código.
analisis %>%
count(upos, sort = T) %>%
mutate(upos = reorder(upos, n)) %>%
ggplot(aes(upos, n)) +
geom_col() +
coord_flip()Lo que hacen lo has visto ya en numerosas ocasiones en capítulos anteriores, pero no viene mal recordarlo. Tomará los datos de la tabla analisis, contará con count() las ocurrencias de upos, pero como quieres que aparezcan ordenadas por frecuencias, tienes que crear una columna interna, invisible, con mutate(), en la que se ordenarán los valores de upos por el número de veces que aparezca cada uno. Después le pides a ggplot que lo dibuje, y que los datos que ha de tener en cuenta son upos en el eje horizontal y n en el vertical; que debe dibujar una gráfica de barras con geom_col() y te permites un pequeño alarde de diseño al dibujar la gráfica con barras horizontales en vez de verticales con coord_flip().
Pero no te interesa saber solamente los datos referentes a las diversas partes de la oración del texto, sino que quieres estudiar deternidamente algunas de ellas, por ejemplo, los sustantivos, o los adjetivos, o los nombres propios. Extraer cualquier parte de la oración no es muy complicado… Para extraer los sustantivos basta con
El resultado con un texto tan breve es parco y no merece la pena presentarlo en una gráfica.
## # A tibble: 9 × 2
## token n
## <chr> <int>
## 1 azares 1
## 2 catástrofe 1
## 3 infancia 1
## 4 manera 1
## 5 marina 1
## 6 palabras 1
## 7 suceso 1
## 8 testigo 1
## 9 vida 1Para contar tan solo los sustantivos, primero hay que seleccionar con filter() aquellas palabras-token cuya upos sea igual a NOUN (o ADJ, VERB, ADV, SCONJ… o lo que quieras examinar), y después contar las palabras que están guardadas en token. Si quieres ver los adjetivos, tan solo tienes que cambiar NOUN por ADJ y volver a ejecutar la línea. El resultado tiene que ser
## # A tibble: 3 × 2
## token n
## <chr> <int>
## 1 extraña 1
## 2 gran 1
## 3 terrible 1Como puedes ver es rápido e increiblemente sencillo.
7.3 Etiquetado de una novela
Acabas de ver las posibilidades más básicas con un texto mínimo. Lo que vas hacer a continuación puede llevar algo más de tiempo. Lo que te voy a mostrar es cómo hacerlo con una novela extensa, Los Pazos de Ulloa de Emilia Pardo Bazán; después lo complicaré con todos los Mensajes de Navidad. Incluso podría complicarlo con un análisis de los diez primeros Episodios Nacionales de Benito Pérez Galdós.
Cierra RStudio y vuélvelo a arrancar. Es la mejor manera de asegurarte de que no hay cosas raras por ahí escondidas. El inicio es el normal: cargar las tres librerías que te serán necesarias. Así que adelante.
Ahora cargas el modelo de {udpipe} que necesitas. Utiliza ancora, así que
A continuación, vas a cargar la novela de Pardo Bazán con read_lines(), que solo necesita, realmente, conocer de dónde leer el texto. Lo vas a bajar del repositorio del proyecto, pero nada te impide guardarlo después en tu disco duro, ya te he contado cómo puedes hacerlo. Sin embargo, el texto tiene tres primeras líneas que informan de la autora, del título y la fecha, unos mínimos metadatos, como no tienes interés en analizarlos, le indicas a read_lines() que se las salte con skip = 3. El último argumento, locale = default_locale() es para que tu ordenador lea adecuadamente desde el respositorio y no confunda las letras con diacríticos.
Pazos_Ulloa <- read_lines("https://tinyurl.com/7PartidasPazos",
skip = 3,
locale = default_locale())Sabrás que lo ha leído cuando en Environment aparezca el objeto Pazos_Ulloa y te informe de que es un Large character (2815 elements, 1.2 Mb). Es un texto grande, tiene casi 174 000 palabras-token y cerca de 23 000 palabras-tipo.
Pazos_Ulloa <- iconv(Pazos_Ulloa, from = "Latin1", to = "UTF-8") para que udpipe pueda analizarlo.
Antes de proceder al análisis hay que retocar un poco el texto para evitar un resultado indeseado. La ortografía del español exige que la raya, con la que se marcan los incisos, se emplee de la misma manera que los paréntesis: la de apertura se une a la primera palabra y la de cierre a la última. En los textos de carácter narrativo las distintas intervenciones de los personajes se marcan con una raya y no debe dejarse espacio de separación entre la raya y el comienzo del enunciado (RAE, Ortografía básica, 89). Por lo que hay que, contraviniendo las normas ortográficas del español, introducir un espacio en blanco. Es sencillo, gracias a gsub() y las reglas de expresión regular:
Pazos_Ulloa <- gsub("[-–—]", " — ", Pazos_Ulloa)
Pazos_Ulloa <- gsub(" ([\\.,;:])", "\\1", Pazos_Ulloa)
Pazos_Ulloa <- gsub(" {2,10}", " ", Pazos_Ulloa)
Pazos_Ulloa <- gsub("^ ", "", Pazos_Ulloa)La primera instrucción busca todos los tipos de rayas y guiones e inserta un espacio a ambos lados. Como esa instrucción introduce un espacio en blanco entre la raya y un signo de puntuación que le siga, la siguiente se encarga de borrar cualquier espacio en blanco que haya antes de un punto, una coma, un punto y coma o dos puntos. Como también han podido quedar dos o más espacios en blanco juntos –para expresar el dos o más, con un límite máximo arbitrario, utiliza {2,10}– y en el siguiente paso se reducen a uno solo. La última instrucción lo que hace es borrar el espacio en blanco que haya antes de las rayas inicial de diálogo –el acento circunflejo indica en el comienzo de la cadena–.
El siguiente paso es analizarlo. Ten un poco de paciencia, le llevará algo de tiempo, unos cuatro minutos y medio. Le vas a pedir que guarde el resultado en PU_analisis.
Por último, conviertes el resultado en una tabla para que sea más fácil manejar y extraer los datos.
Ya tienes analizado el texto. En Environment habrá aparecido el objeto PU_analisis y te informará de que tiene 210782 observaciones (filas) y 14 variables (columnas). Ahora es cuestión de extraer la información. Te vas a limitar, como en el caso anterior, a ver las estadísticas básicas de las clases de palabra que hay en Los Pazos de Ulloa y a extraer los sustantivos, adjetivos y verbos más frecuentes. En primer lugar, la estadística de las clases de palabras que vas a representar una gráfica de barras (figura 7.5).
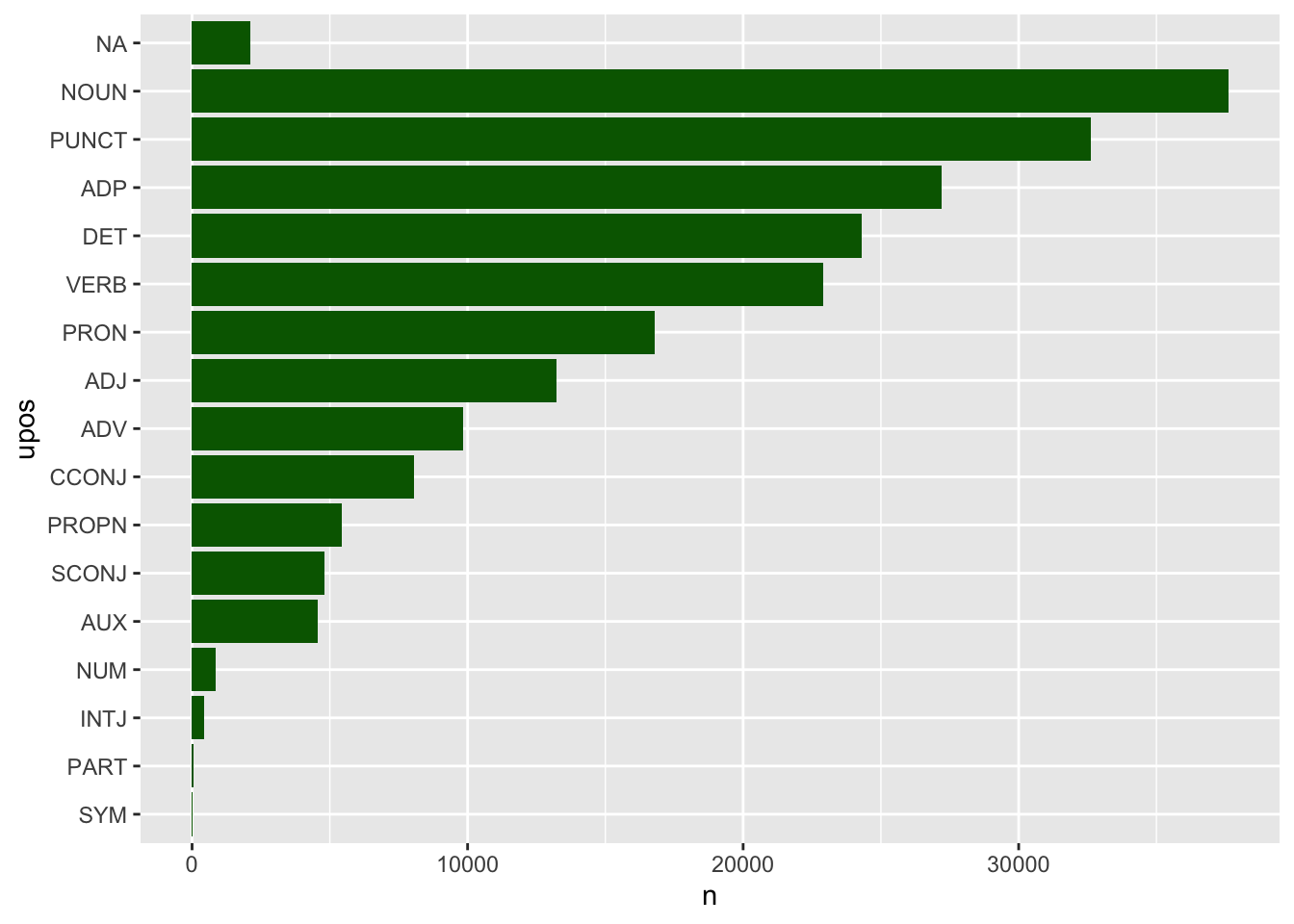
Figura 7.5: Las clases de palabras en Los Pazos de Ulloa
que se consigue con estas líneas código
PU_analisis %>%
count(upos, sort = T) %>%
mutate(upos = reorder(upos, n)) %>%
ggplot(aes(upos, n)) +
geom_col(fill = "darkgreen") +
coord_flip()Te habrá llamado en seguida la atención el NA de la primera barra. No corresponde a ninguna clase de palabra según el sistema de etiquetas UPOS. Tiene una sencilla explicación. Las formas verbales con clíticos, como sofrenarlo, agarrándose, empeñándose, que aparecen en el primer enunciado del primer párrafo de Los Pazos de Ulloa, las ha descompuesto en los dos (o tres, como en diciéndoselo) elementos que lo constituyen: la forma verbal y el clítico. Como en esos casos no puede etiquetar la palabra gráfica con una clase de palabra determinada, retiene la forma original y en upos no da valor alguno (NA) y, a continuación, crea una entrada independiente para cada componente de la palabra gráfica y las etiqueta como VERB o AUX –los infinitivos– y PRON.
Puedes ignorar, pero no borrar, esa información de la tabla para que no la contemple, porque no es una parte de la oración que debas tener en cuenta. La forma de hacerlo es decirle a R que pase de esas observaciones con la función drop_na(). Es una función que debe ir antes de hacer el recuento con count(), con lo que el código para dibujar la gráfica como la de la figura 7.6 es
PU_analisis %>%
drop_na(upos) %>%
count(upos, sort = T) %>%
mutate(upos = reorder(upos, n)) %>%
ggplot(aes(upos, n)) +
geom_col(fill = "darkgreen") +
coord_flip()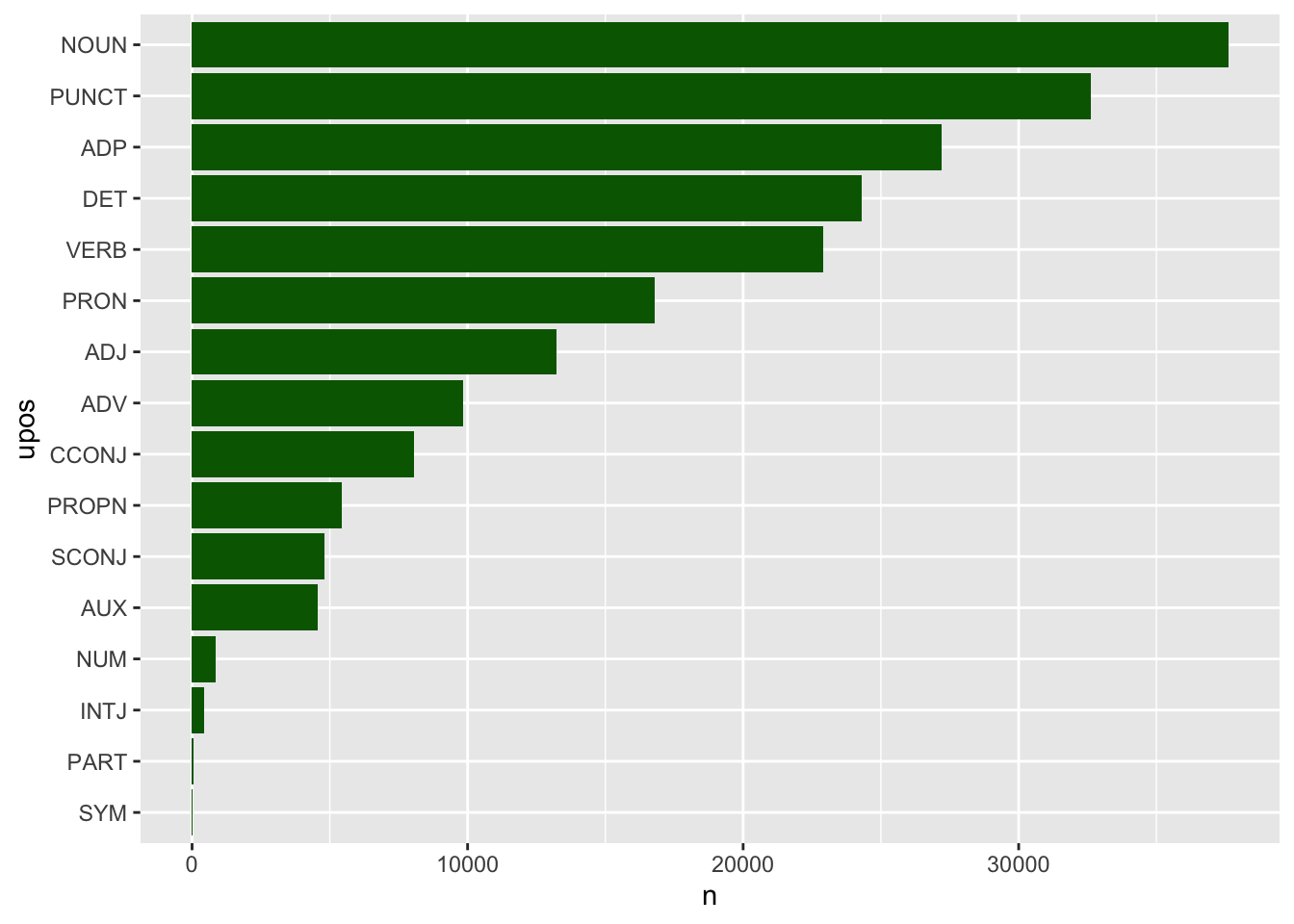
Figura 7.6: Las clases de palabras en Los Pazos de Ulloa
Fíjate que ha desparecido la barra NA.
Averiguar cuáles son los sustantivos (NOUN) más frecuentes en Los Pazos de Ulloa y representarlos en un gráfico como el de la figura 7.7 es realmente sencillo. Pero como hay más de 9 000, los limitarás, con top_n() a los 30 más frecuentes.
PU_analisis %>%
filter(upos == "NOUN") %>%
count(token, sort = T) %>%
mutate(token = reorder(token, n)) %>%
top_n(30) %>%
ggplot(aes(token, n)) +
geom_col(fill = "darkgreen") +
coord_flip()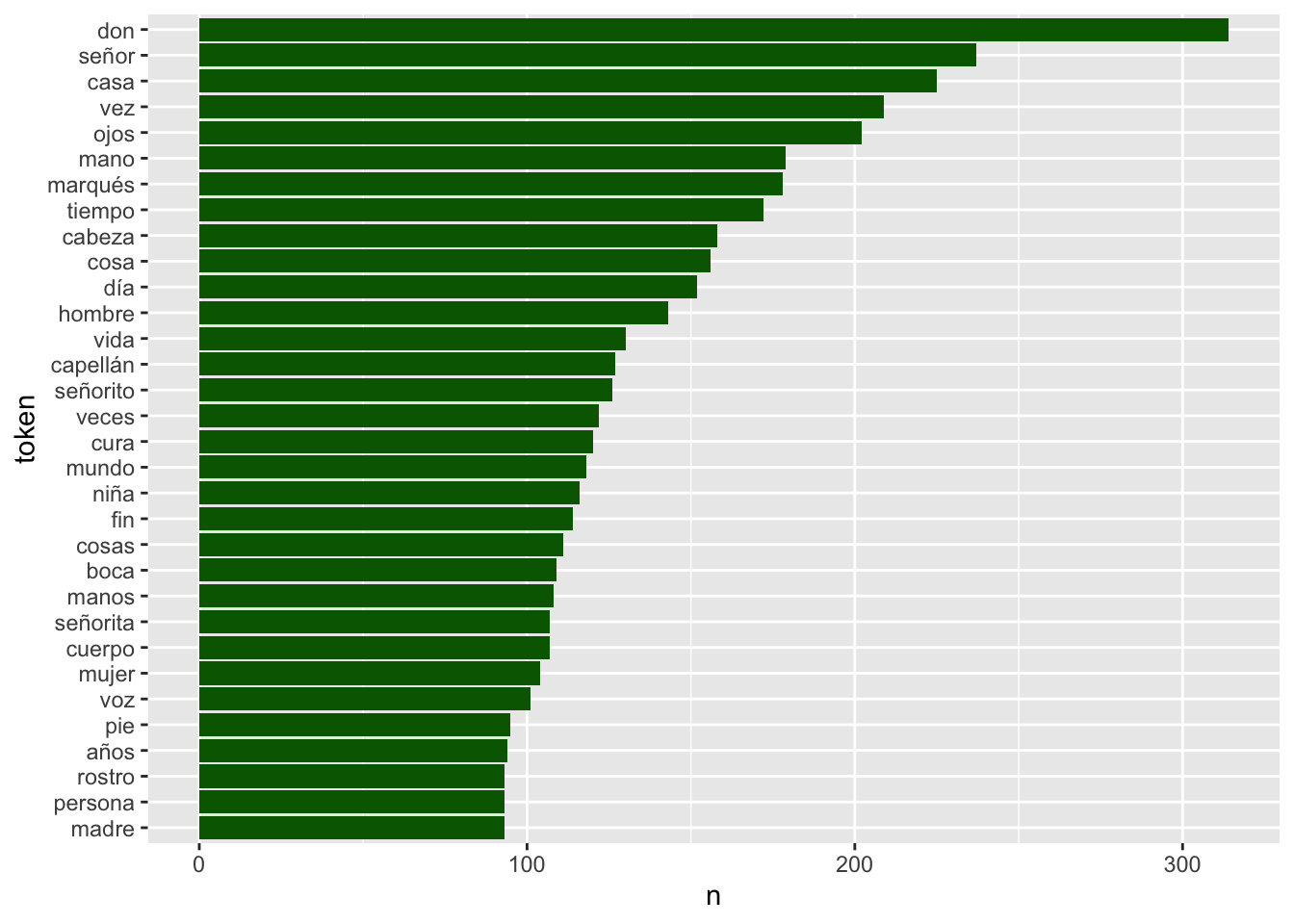
Figura 7.7: Los 30 sustantivos más frecuentes en Los Pazos de Ulloa
Si cambias NOUN por cualquier otro valor de upos puedes extraer los datos referentes a cada clase de palabra. Ahora bien, si quieres extraer los verbos te encontrarás con un ligero problema. Para extraerlos, cambia NOUN por VERB y vuelve a ejecutar el código. Deberás obtener una gráfica como la de la figura 7.8.
PU_analisis %>%
filter(upos == "VERB") %>%
count(token, sort = T) %>%
mutate(token = reorder(token, n)) %>%
top_n(30) %>%
ggplot(aes(token, n)) +
geom_col(fill = "maroon") +
coord_flip()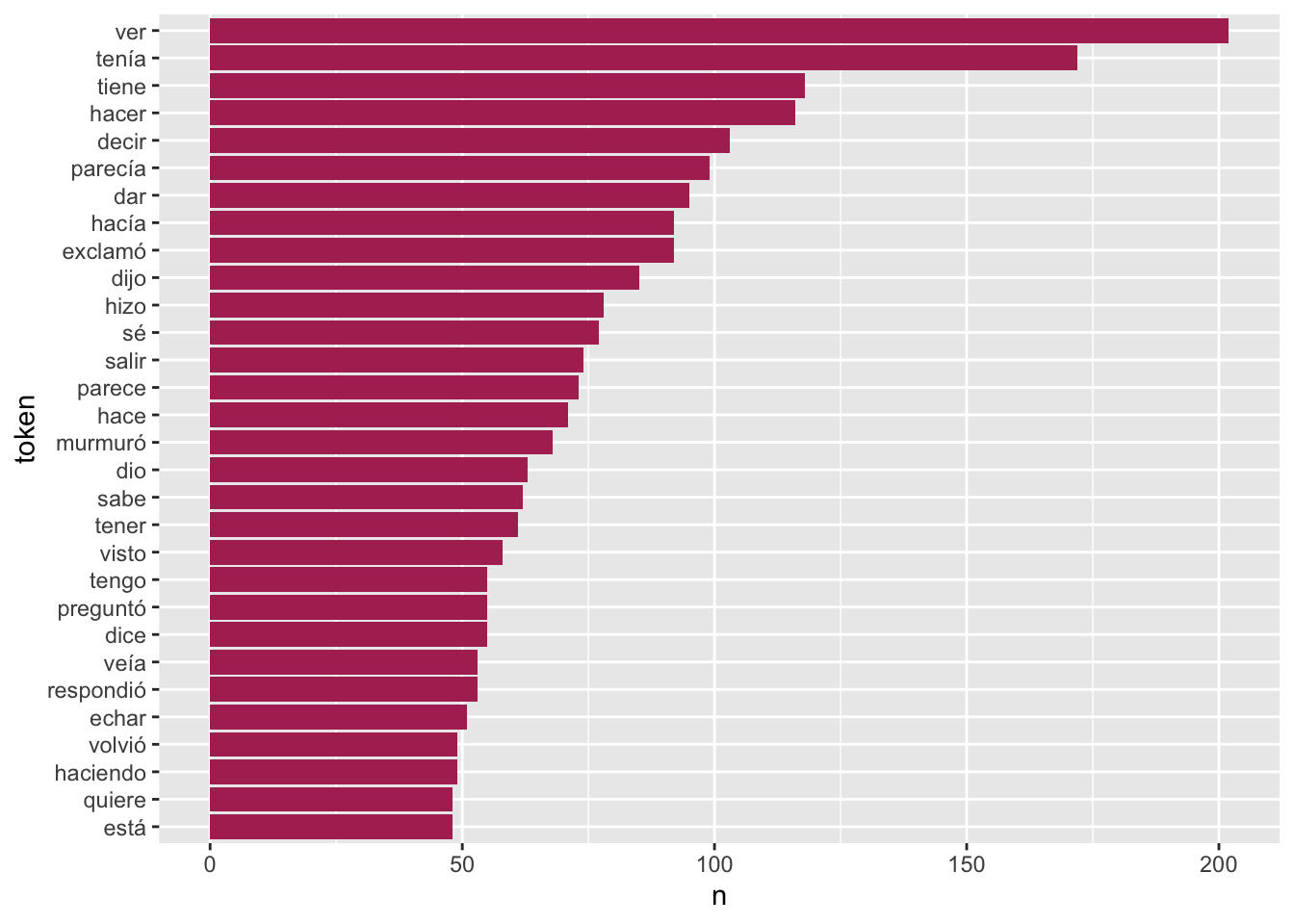
Figura 7.8: Las 30 formas verbales más frecuentes en Los Pazos de Ulloa
Aquí el problema es que los árboles no te dejarán ver el bosque. El bosque son los verbos, no las distintas formas verbales (los árboles), reducidos a su forma más básica: el infinitivo, que es con el que los buscaríamos en un diccionario.
Al analizar el texto, udpipe se encargó de lematizarlo y creó la columna lemma, con lo que extraer los diferentes verbos que hay en Los Pazos de Ulloa es realmente sencillo. Hay que pedirle que cuente el contenido de la variable lemma y no el de token.
PU_analisis %>%
filter(upos == "VERB") %>%
count(lemma, sort = T) %>% # En el paso anterior decía token, ahora lemma
mutate(lemma = reorder(lemma, n)) %>%
top_n(30) %>%
ggplot(aes(lemma, n)) +
geom_col(fill = "orange") +
coord_flip()## Selecting by n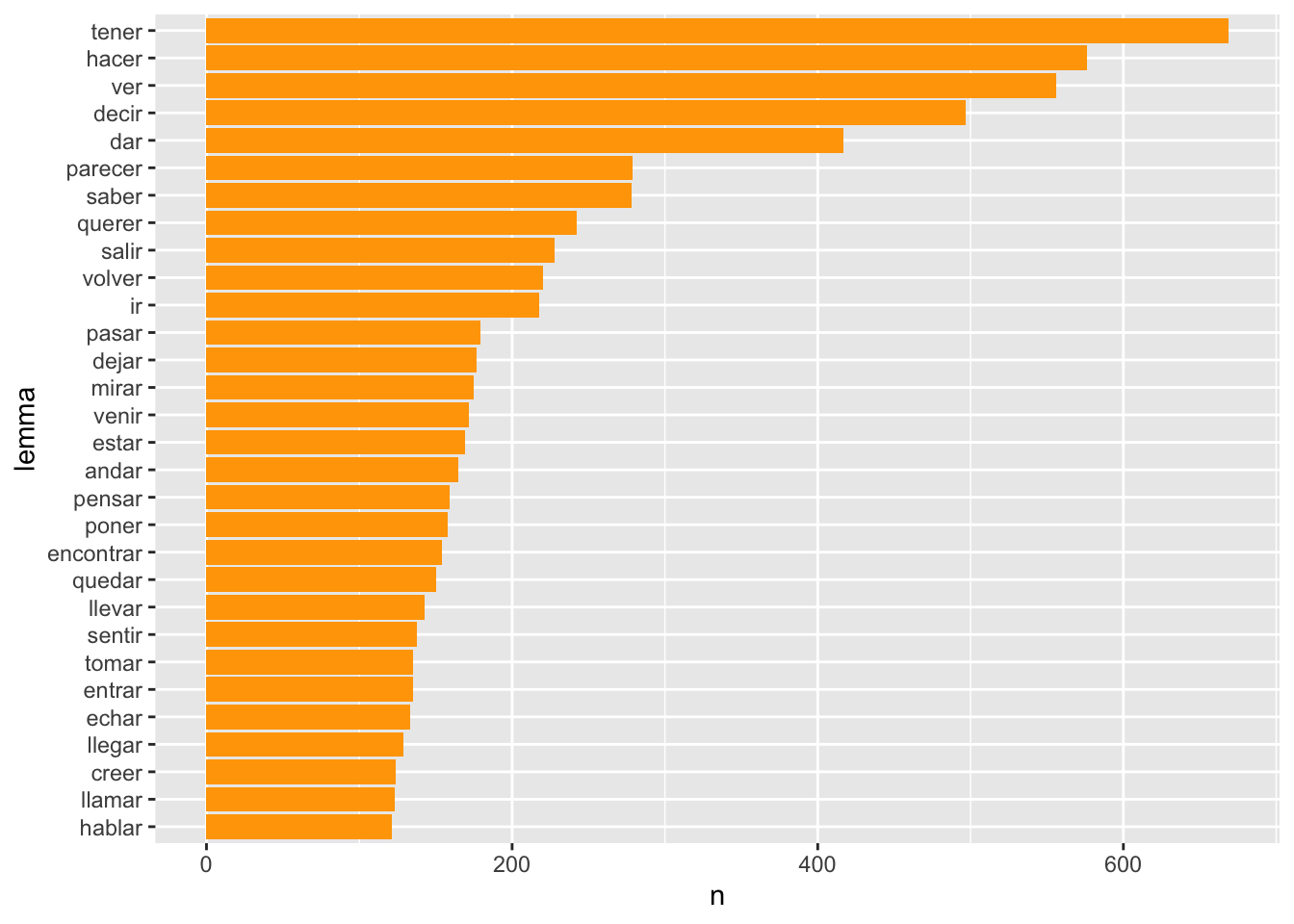
Figura 7.9: Los 30 lemas verbales más frecuentes en Los Pazos de Ulloa
El resultado es el de la gráfica de la figura 7.9. Sin embargo, no están todos los verbos que hay en Los Pazos de Ulloa. Faltan 318 ocurrencias de verbos puesto que los ha etiquetado como auxiliares (AUX). Sin tocar para nada el contenido de la tabla, puedes extraer tanto los VERB como los AUX. Tan solo tienes que añadir el operador booleano OR, que se representa con la barra |, a la hora de seleccionar con filter() los datos. El único cambio que tienes que hacer es añadir | upos == "AUX" en la función filter() y obtendrás la gráfica de la figura 7.10.
PU_analisis %>%
filter(upos == "AUX" | upos == "VERB") %>%
count(lemma, sort = T) %>%
mutate(lemma = reorder(lemma, n)) %>%
top_n(30) %>%
ggplot(aes(lemma, n)) +
geom_col(fill = "orange") +
coord_flip()## Selecting by n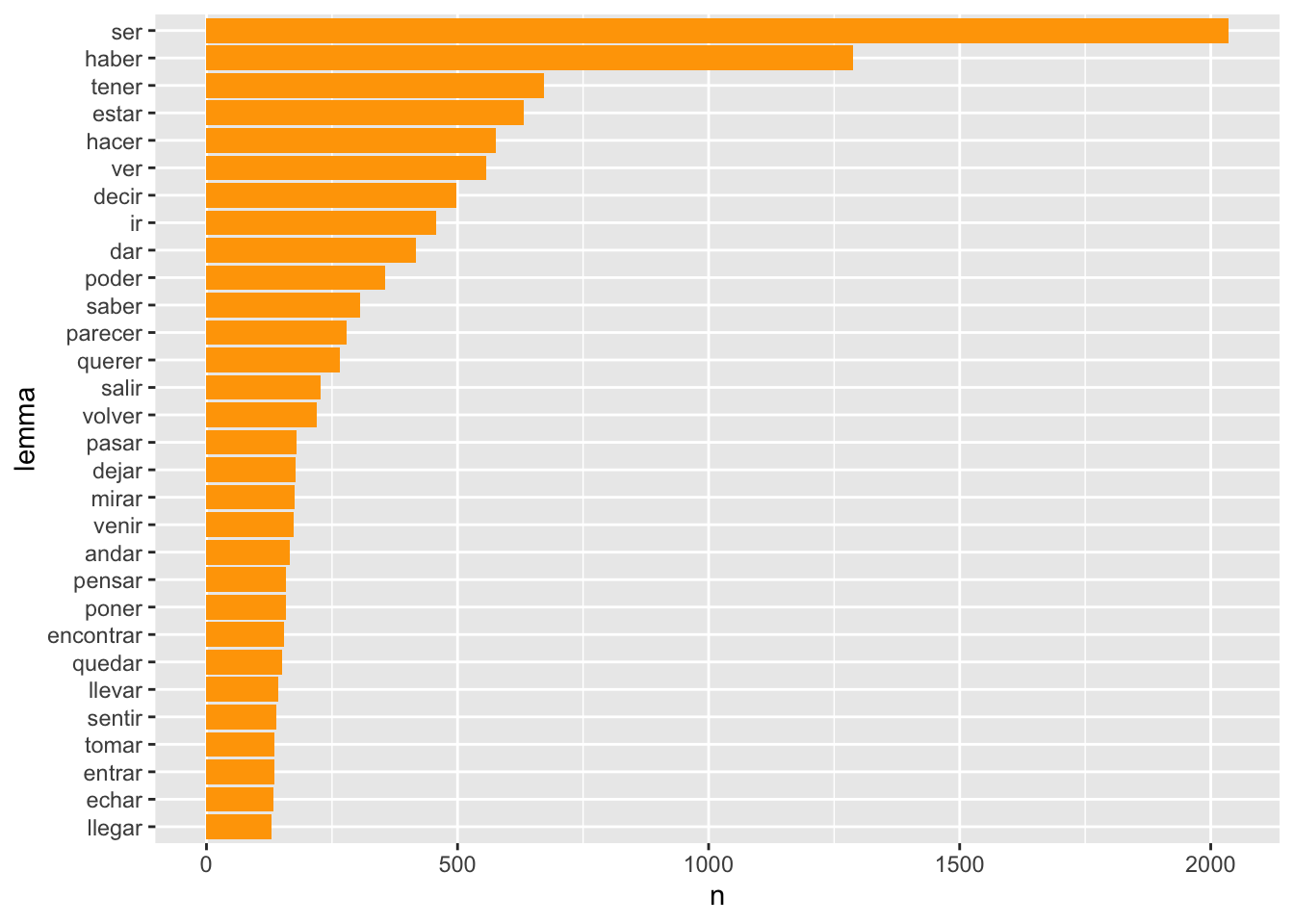
Figura 7.10: Las 30 formas verbales (principales y auxiliares) más frecuentes en Los Pazos de Ulloa
Como puedes comprobar, con muy poco esfuerzo puedes obtener montañas de información lingüística que antes podía llevar muchísimas horas de trabajo manual.
7.4 De nuevo los Mensajes
En el apartado anterior has estado trabajando con un solo texto, el de la novela de Emilia Pardo Bazán, y te dije que complicaría un poco la cosa. Cargar y analizar un único texto es relativamente sencillo, como has podido ver. Ahora te vas a enfrentar, de nuevo, con la carga y análisis automatizado de todos los Mensajes de Navidad. Como de costumbre, sal de RStudio, vuélvelo arrancar y carga las tres librerías que vas a utilizar.
Ahora cargas el modelo de {udpipe} que necesitas. Utiliza ancora.
El paso siguiente es leer todos los textos para después analizarlos. Ya conoces la rutina de otros capítulos, aunque hay unas pequeñas novedades, para que vayas aprendiendo trucos de programación. Lo primero es obtener los nombres de los ficheros con:
En esta ocasión, los años no los vas a extraer de los nombres de los ficheros que tienes guardados en el vector ficheros, sino que usarás otra fórmula que ya he mencionado en otro momento. En R es muy fácil crear vectores, tanto de caracteres como numéricos, y no importa si el contenido es una secuencia o repite uno o varios valores. Los números de los años en los que se han pronunciado los mensajes es una serie que va desde 1975 a 2023. R crea secuencias numéricas, ya lo viste con anterioridad, con el elemental sistema de escribir el número de inicio y el de finalización separándolos con dos puntos. Escribe en la consola
El resultado tiene que ser
## [1] 1975 1976 1977 1978 1979 1980 1981 1982 1983 1984 1985
## [12] 1986 1987 1988 1989 1990 1991 1992 1993 1994 1995 1996
## [23] 1997 1998 1999 2000 2001 2002 2003 2004 2005 2006 2007
## [34] 2008 2009 2010 2011 2012 2013 2014 2015 2016 2017 2018
## [45] 2019 2020 2021 2022 2023Ahí tienes la secuencia sin gran esfuerzo. La vas a guardar en anno. Pero como los números de los años los usarás como secuencias de caracteres, tienes que convertirlos en caracteres y eso lo consigues con la función as.character(), lo que ya viste en el capítulo anterior. Con lo que la expresión es
Para poder agrupar los datos por reyes, pues examinarás uno y otro y, a veces, los compararás, tienes que crear un vector, llamado rey en el que tiene que aparecer 39 veces el nombre del rey Juan Carlos I y once el de Felipe VI. Vas a usar dos funciones, una dentro otra: c() y rep(). La primera concatena dos o más vectores que vas a crear con rep(), y este crea un vector repitiendo el primer argumento cuantas veces se le indique en el segundo, aunque este truco ya te lo enseñé en otro capítulo. Escribe en el editor
Cuando la ejecutes, aparecerá en Environment un vector de caracteres –chr– llamado rey que tendrá 50 elementos. Puedes comprobar el contenido escribiendo en la consola rey y pulsando intro. Se imprimirá
## [1] "Juan Carlos I" "Juan Carlos I" "Juan Carlos I"
## [4] "Juan Carlos I" "Juan Carlos I" "Juan Carlos I"
## [7] "Juan Carlos I" "Juan Carlos I" "Juan Carlos I"
## [10] "Juan Carlos I" "Juan Carlos I" "Juan Carlos I"
## [13] "Juan Carlos I" "Juan Carlos I" "Juan Carlos I"
## [16] "Juan Carlos I" "Juan Carlos I" "Juan Carlos I"
## [19] "Juan Carlos I" "Juan Carlos I" "Juan Carlos I"
## [22] "Juan Carlos I" "Juan Carlos I" "Juan Carlos I"
## [25] "Juan Carlos I" "Juan Carlos I" "Juan Carlos I"
## [28] "Juan Carlos I" "Juan Carlos I" "Juan Carlos I"
## [31] "Juan Carlos I" "Juan Carlos I" "Juan Carlos I"
## [34] "Juan Carlos I" "Juan Carlos I" "Juan Carlos I"
## [37] "Juan Carlos I" "Juan Carlos I" "Juan Carlos I"
## [40] "Felipe VI" "Felipe VI" "Felipe VI"
## [43] "Felipe VI" "Felipe VI" "Felipe VI"
## [46] "Felipe VI" "Felipe VI" "Felipe VI"
## [49] "Felipe VI" "Felipe VI"Lo podrías haber hecho con tres líneas de código como has visto en otra ocasión, pero no merece la pena.
A continuación, has de crear la tabla en la que se almacenarán los textos según los vaya leyendo el ordenador.
Ya puedes leer todos los textos con el bucle for. Pero, como en el caso de Los Pazos de Ulla, podría haber problemas con las rayas de los incisos, tienes que incluir las tres líneas de búsqueda y reemplazo que se encargarán de adecuarlas para el análisis.
for (i in 1:length(ficheros)){
discurso <- read_lines(paste("datos/mensajes",
ficheros[i],
sep = "/"))
# Líneas que se encargan de las rayas
discurso <- gsub("[-–—]", " – ", discurso)
discurso <- gsub(" ([\\.,;:])", "\\1", discurso)
discurso <- gsub(" ", " ", discurso)
discurso <- gsub("^ ", "", discurso)
# Sigue…
temporal <- tibble(anno = anno[i],
rey = rey[i],
parrafo = seq_along(discurso),
texto = discurso)
mensajes <- bind_rows(mensajes, temporal)
}mensajes$texto <- iconv(mensajes$texto, from = "Latin1", to = "UTF-8") para que {udpipe} pueda analizarlo. Esta línea la añades tras el bucle for.
Ahora viene todo lo nuevo. Analizar cada uno de los textos. Exigirá un nuevo bucle for. Aunque podrías analizar todos los textos con un único comando
no lo harás porque después no podrías extraer los datos por años ni por reyes. Así que los analizarás separadamente, aunque al final los tendrás todos en una sola tabla, lo que te permitirá manejarla con mayor comodidad. Pero antes vas a duplicar, con nombres diferentes, las variables anno y rey. Los nuevos nombres son AnnoMensaje y ReyMensaje. Los emplearás para crear nuevas columnas en el proceso de análisis. Podríamos haberlas creado al principio, pero para mantener la unidad del código, he visto que es mejor duplicarlas.
Ahora crea una tabla vacía que llamarás Mensajes_Analizado en la que recopilarás el resultado de los análisis. Lo vas hacer con la función tibble() y especificarás el nombre de cada columna y qué tipo de datos contendrá cada una de ellas. Todas, salvo dos, las dos primeras, son de caracteres.
Mensajes_Analizado <- tibble(parrafo_id = integer(),
enunciado_id = integer(),
enunciado = character(),
token_id = character(),
token = character(),
lema = character(),
upos = character(),
xpos = character(),
rasgos = character(),
anno = character(),
rey = character())El bucle for extraerá de mensajes cada uno de los mensajes por años. Los analizará. Retocará un poco las columnas, puesto que añadirá dos nuevas: anno y rey; borrará cinco que creará el análisis y que no te serán necesarias; renombrará otras, para poder diferenciar las variables de las funciones y evitar equívocos; limpiará la secuencia de caracteres doc que aparece en la columna parrafo_id e incorporará a Mensajes_Analizado cada uno de los mensajes según los vaya analizando. Para evitar problemas indeseados, borrará los objetos temporal y analisis. Es una precaución extra y, por tanto, prescindible. El código del bucle es
for(i in 1:length(AnnoMensaje)){
temporal <- mensajes %>%
filter(anno == AnnoMensaje[i]) %>%
select(texto)
analisis <- as_tibble(udpipe_annotate(modelo_ancora,
temporal$texto))
analisis <- analisis %>%
add_column(anno = AnnoMensaje[i],
rey = ReyMensaje[i]) %>%
select(-(paragraph_id),
-(deps),
-(misc),
-(head_token_id),
-(dep_rel)) %>%
rename(parrafo_id = doc_id,
enunciado_id = sentence_id,
enunciado = sentence,
lema = lemma,
rasgos = feats) %>%
mutate(parrafo_id = as.numeric(str_extract(parrafo_id, "\\d+")))
Mensajes_Analizado <- bind_rows(Mensajes_Analizado, analisis)
rm(temporal, analisis)
}Ya conoces, de sobra, el funcionamiento de los bucles for, por lo que solo me centraré en lo que sucede en cada línea en cada una de las iteraciones del bucle.
Para analizar cada mensaje, lo primero que has de hacer es extraer de mensajes el texto de cada año con select() y guardarlo en temporal. Pero para que sea mensaje a mensaje, la única columna de mensajes que te sirve es anno, por lo que se lo indicas con filter() y puesto que tienes nada menos que 44 años y tienes que seleccionarlos secuencialmente, el valor lo extraerá del vector AnnoMensaje y, para saber cuál le corresponde en cada momento, entre corchetes, le indicas cuál será con el valor de i.
En la línea siguiente analizarás el texto que has guardado en la columna texto de temporal (temporal$texto) cuyo resultado se guardará en analisis, pero lo guardarás como una tibble con as_tibble() porque los resultados de udpipe_annotate() son un objeto lista y es una pesadilla manejarlos.
El siguiente grupo de instrucciones, que se ejecutarán todas dentro del objeto analisis, es decir, dentro de la tabla en la que se ha guardado el análisis, añade dos columnas con add_column() que se llamarán anno y rey y cuyo valor lo tomará secuencialmente, dependiendo del valor de i, de AnnoMensaje y ReyMensaje.
Después borrará con select() cinco columnas (nombre_variable) que son inútiles. Lo que en realidad le está diciendo es que tome todas las columnas salvo las que indicas entre los paréntesis. De ahí el – que antepones a cada (nombre_variable).
A continuación, renombras con rename() algunas de las columnas para que los nombres sean los mismos que los que usaste cuando creaste la tabla Mensajes_Analizado. Recuerda que para renombrar primero has de poner el nuevo nombre y después, separados por un igual, el nombre que quieres cambiar.
La columna parrafo_id se pobló en cada análisis con la secuencia doc y un número. Puesto que solo te interesa el número, que será el del número del párrafo, tienes que eliminar esas tres letras. Para eso usarás mutate(), con lo que cambiarás el contenido de la columna parrafo_id. Dado que partes de una columna cuyo contenido son caracteres, tienes que convertirlos en números con as.numeric() y, como lo más sencillo es extraer los números y volverlos a guardar en parrafo_id, usarás la fórmula de expresión regular str_extract(), que necesita saber cuál es la variable de la que tiene que extraer los datos, y cuál es el patrón de extracción. La variable es parrafo_id y el patrón son los dígitos. La manera de indicarlos en R con una expresión regular es \\d+, aunque también [0-9]+, o [[:digit:]]+.
La penúltima línea del bucle lo que hace es ir acumulando en Mensajes_Analizado el resultado del mensaje que se analiza en cada iteración. Recuerda que cuando se inicia el bucle, la tabla Mensajes_Analiza está vacía y que en cada vuelta añades con bind_rows() el contenido de analisis. Como son tablas con número idéntico de columnas no tendrás problema alguno.
La última línea borra los objetos temporal y analisis. Realmente no es necesario, pero es la manera de asegurarte de que no quedan datos que se puedan mezclar.
Cuando ejecutes el bucle ten un poco de paciencia, le llevará unos tres minutos.
7.4.1 Reordenar las columnas
Por último, para que sea más fácil ver las columnas, las vas a reordenar. Las variables anno y rey han quedado en el extremo derecho de la tabla y son datos que te interesa tener a la vista. Se puede hacer de dos maneras: por la posición, o por el nombre. Qué sistema usar depende del tamaño de la tabla. Para averiguar el nombre de las columnas se usa la función colnames() y entre los paréntesis se escribe el nombre del objeto del que se quiere extraer los nombres de las variables (columnas) que lo constituyen:
La ejecución de esta función dará como resultado
## [1] "parrafo_id" "enunciado_id" "enunciado"
## [4] "token_id" "token" "lema"
## [7] "upos" "xpos" "rasgos"
## [10] "anno" "rey"Con esta sencilla instrucción sabes cuántas columnas hay, cómo se llaman y en que orden están. La primera es parrafo_id, la quinta token y la novena rasgos. Como quieres que anno y rey, que están en las posiciones 10 y 11, sean la primera y la segunda, basta con crear un vector de números –efímero– con el orden en que quieres tener las columnas c(10,11,1,2,3,4,5,6,7,8,9). La instrucción es
Lo que hace es volver a copiar en Mensajes_Analizado el contenido que tiene, pero reordenando las columnas de acuerdo con el vector que creas con c(). Vuelve a ejecutar colnames(Mensajes_Analizado). Verás que anno y rey ahora están en la primera y segunda posición y que rasgos es la última, la undécima.
## [1] "anno" "rey" "parrafo_id"
## [4] "enunciado_id" "enunciado" "token_id"
## [7] "token" "lema" "upos"
## [10] "xpos" "rasgos"¿Qué pasaría si la expresión fuera c(10:11,1:9)?
7.5 Las clases de palabras en ambos reyes: extraer y representar los datos
Ya tienes todos los mensajes navideños analizados y etiquetados en la tabla Mensajes_Analizado. Ahora quieres comparar el uso de las partes de la oración (clases de palabras) que ha empleado cada rey. Puedes caer en la tentación de recurrir al código que utilizaste con doña Emilia Pardo Bazán y modificarlo para usarlo con Mensajes_Analizado y los nuevos nombres de columnas. Hazlo, es absolutamente lícito y válido. Todos usamos y reutilizamos secciones de código que hemos escrito con anterioridad o que han escrito otros.
Recupera ese fragmento de código y reescríbelo. Debería ser algo como esto
Mensajes_Analizado %>%
drop_na(upos) %>%
count(upos, sort = T) %>%
mutate(upos = reorder(upos, n)) %>%
ggplot(aes(upos, n)) +
geom_col(fill = "darkgreen") +
coord_flip()que daría como resultado una gráfica como la de la figura 7.11.
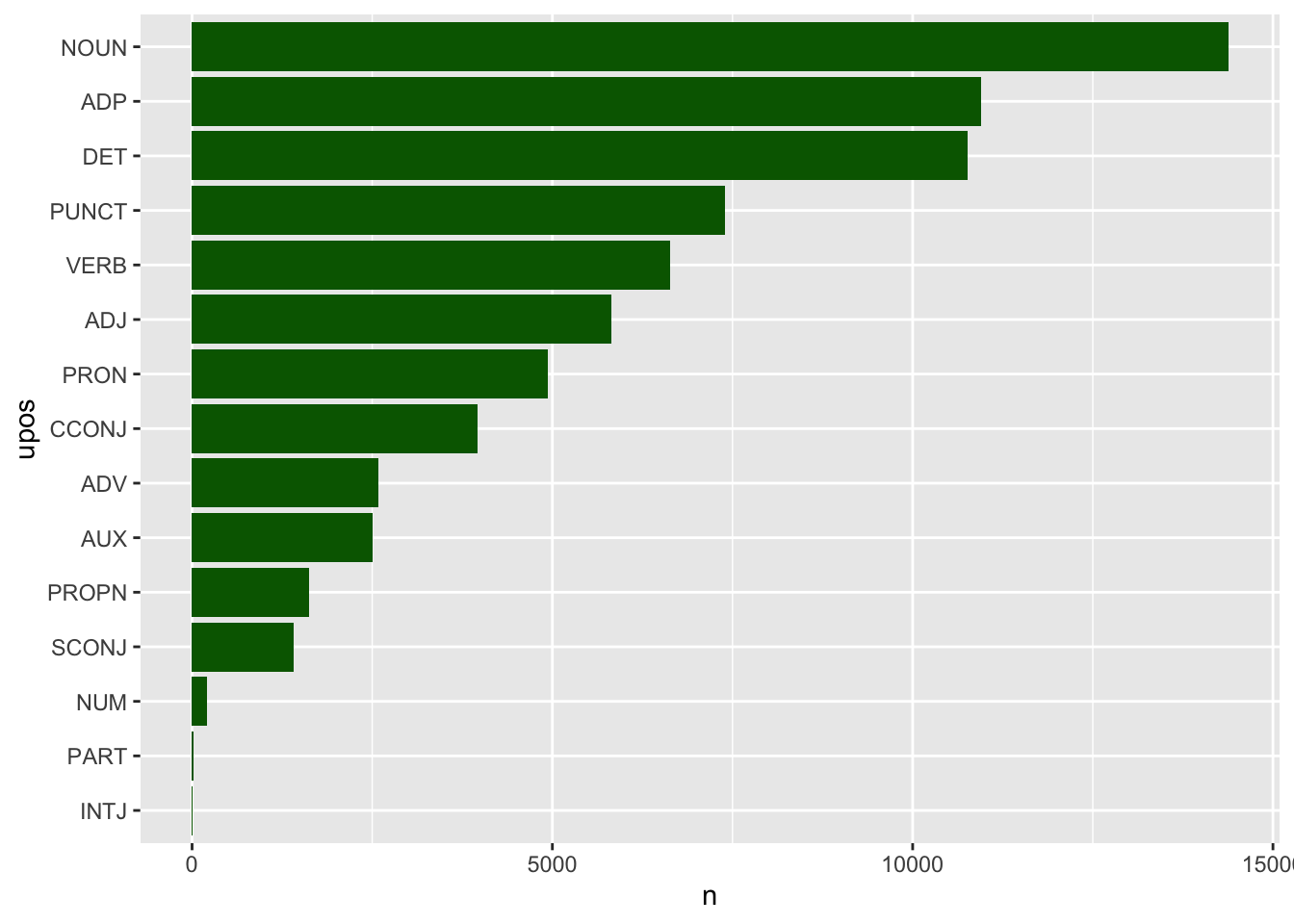
Figura 7.11: Partes de la oración en los mensajes de Navidad 1975-2023
Pero esa gráfica representa las clases de palabras que hay en todo el corpus. No para cada uno de los reyes. ¿Cómo lo arreglarías?
El código que hay a continuación sirve para obtener una gráfica como la figura 7.12 que muestra la comparativa entre las clases de palabras utilizadas por el rey Felipe VI y las empleadas por el rey Juan Carlos I.
clases <- Mensajes_Analizado %>%
group_by(rey) %>%
drop_na(upos) %>%
count(upos, sort = T)
ggplot(clases, aes(upos, n)) +
geom_col() +
coord_flip() +
facet_wrap(~rey)He dividido el código en dos bloques. El primero (clases) creará una tabla en la que se almacenarán los datos. El segundo (ggplot) será el responsable de trazar las gráficas. Así se facilita la reutilización de ambos procedimientos con mínimos cambios.
En clases guardarás los datos que extraerás de Mensajes_Analizados. Como quieres comparar por reyes, tienes que agrupar los datos con group_by(rey). Recordarás que había casillas en las que no había datos. Eran los casos en los que hay formas verbales con clíticos y que el sistema no puede etiquetar; puesto que es es un dato que no interesa, lo eliminas con drop_na(upos). Por último, tienes que hacer el recuento con count(n). Ya tienes la tabla con los datos y puedes proceder a dibujarla.
El segundo bloque de código es el responsable de trazar la gráfica (figura 7.12). Es muy elemental, para que te pueda servir de esqueleto para otros casos. Ya sabes que la función responsable del dibujado es ggplot() que requiere saber de dónde sacar los datos (clases) y qué pintar en cada eje (upos, n) –en el eje horizontal la variable categórica y en el vertical la continua–. Con la función geom_col() seleccionas el tipo de gráfico, en este caso de barras. No necesita más argumentos, podrías usar fill="" para colorear las barras. Como es más sencillo observar estas dos gráficas con los valores de upos en el eje vertical y las frecuencias en el horizontal, giras la gráfica con coord_flip(). Por último, como tienes dos conjuntos de datos, los del rey Felipe y los del rey Juan Carlos, lo mejor es crear una gráfica en la que aparezcan ambas en un solo cuadro. Para esto utilizas facet_wrap() y le indicas cuál es la variable que regirá la creación de las viñetas ~rey.
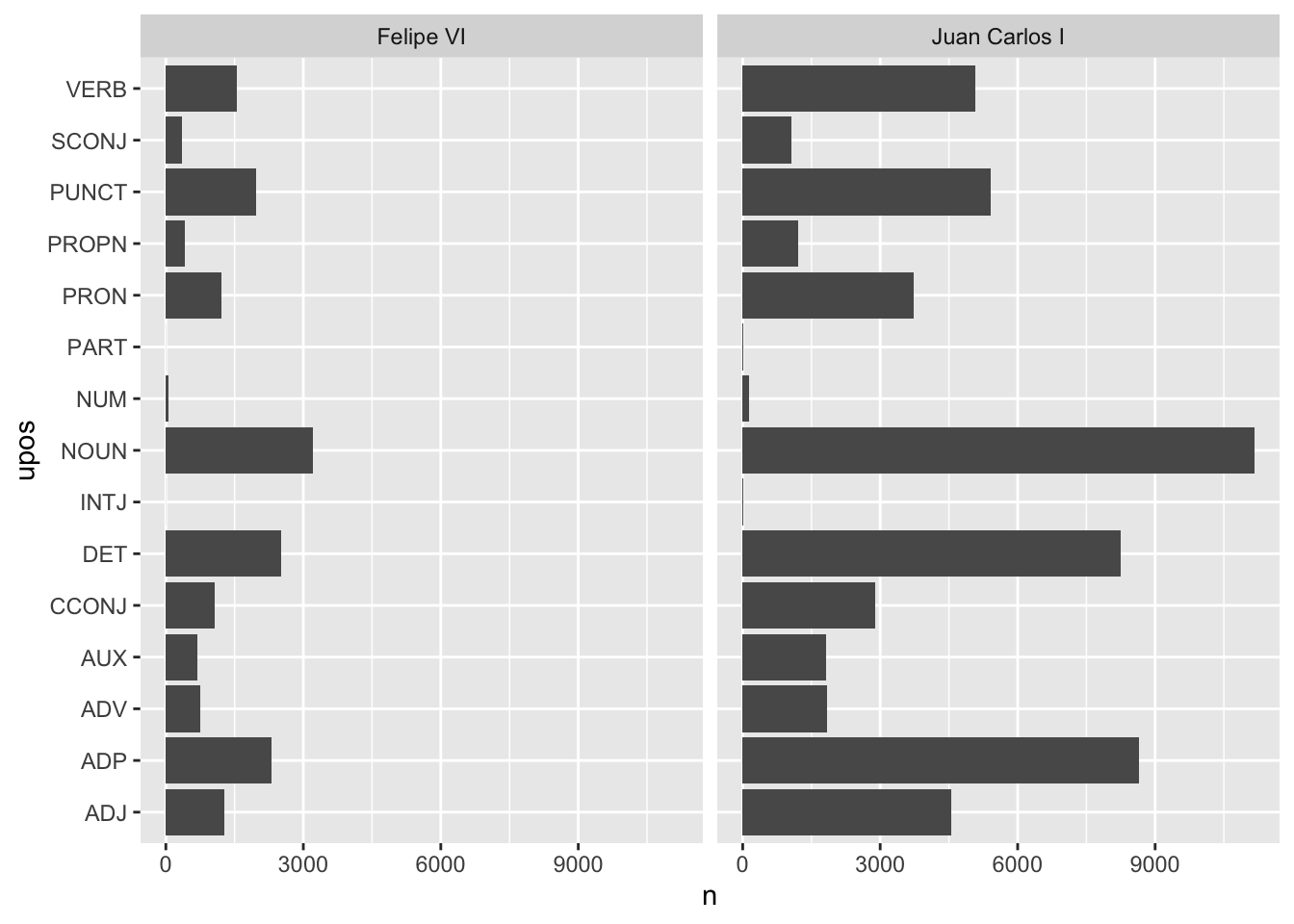
Figura 7.12: Comparativa del uso de partes de la oración utilizadas por Felipe VI y Juan Carlos I. Frecuencias absolutas
Perfecto. Ya tienes una gráfica (figura 7.12) en la que puedes ver que Juan Carlos tiene una mayor frecuencia de uso de todas las clases de palabras que ha establecido el etiquetado. Pero quizá no sea tan perfecto.
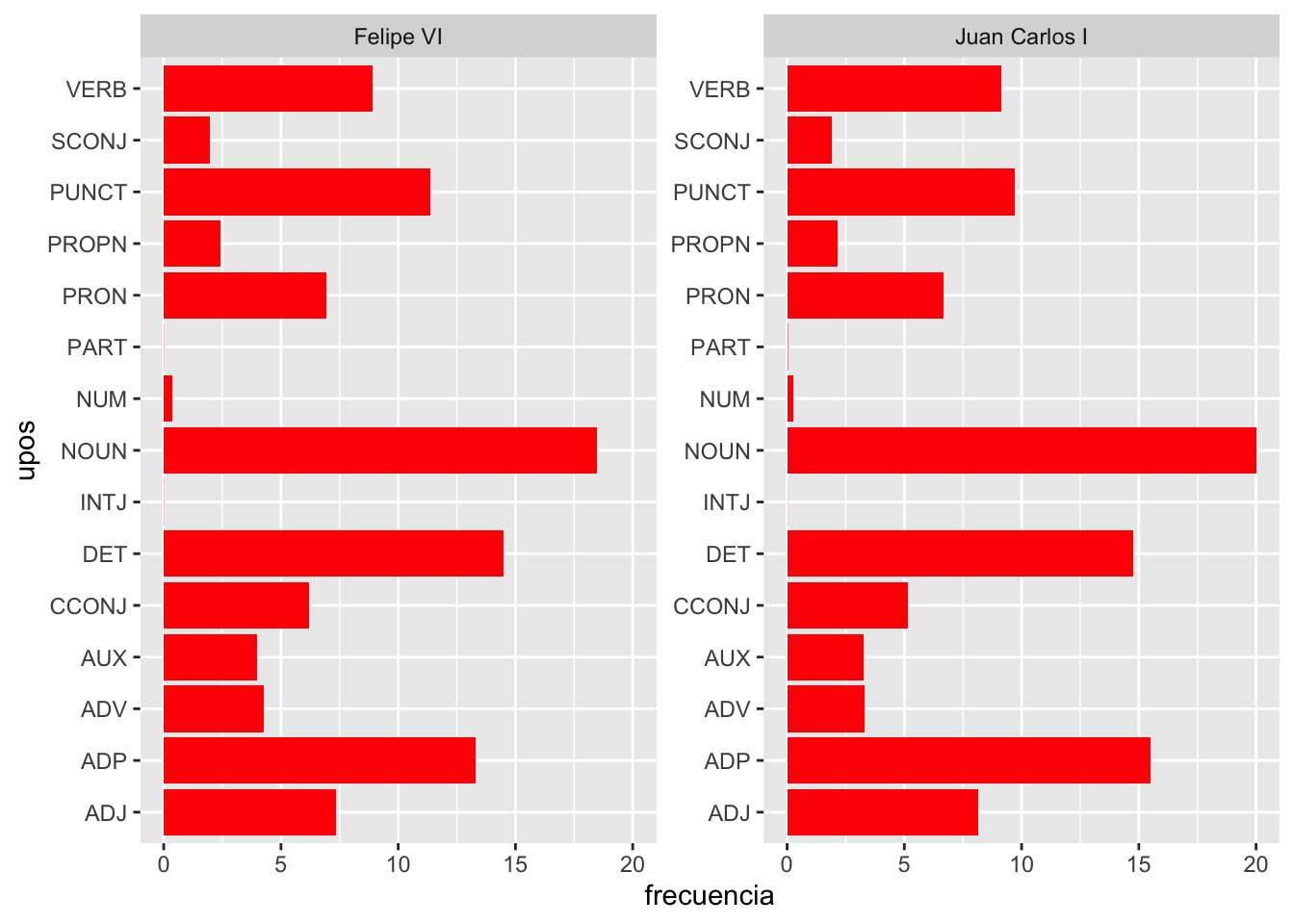
Figura 7.13: Comparativa del uso de partes de la oración utilizadas por Felipe VI y Juan Carlos I. Frecuencias relativas
r length(list.files("datos/mensajes")) mensajes de Navidad y sabes cómo extraer los datos, averigua cuáles son los 20 sustantivos y verbos (todos) más usados por cada uno de los reyes. Deberías obtener dos gráficas como las de las figuras 7.14 y 7.15. Todo lo que necesitas está más atrás. Salvo que has de añadir scales = "free_y" como segundo argumento si usas facet_wrap().
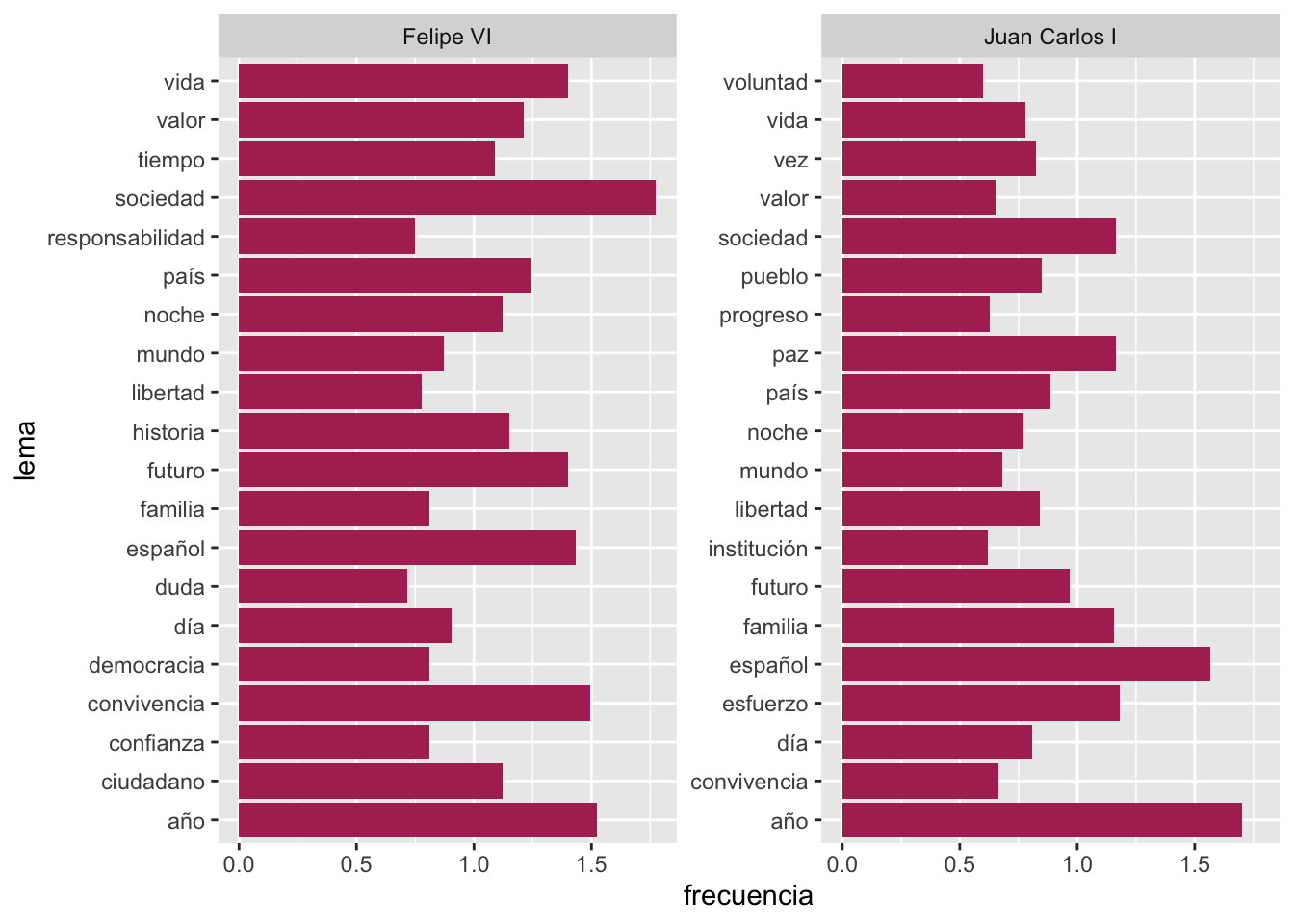
Figura 7.14: Los 20 sustantivos (lemas) más frecuentes de cada rey
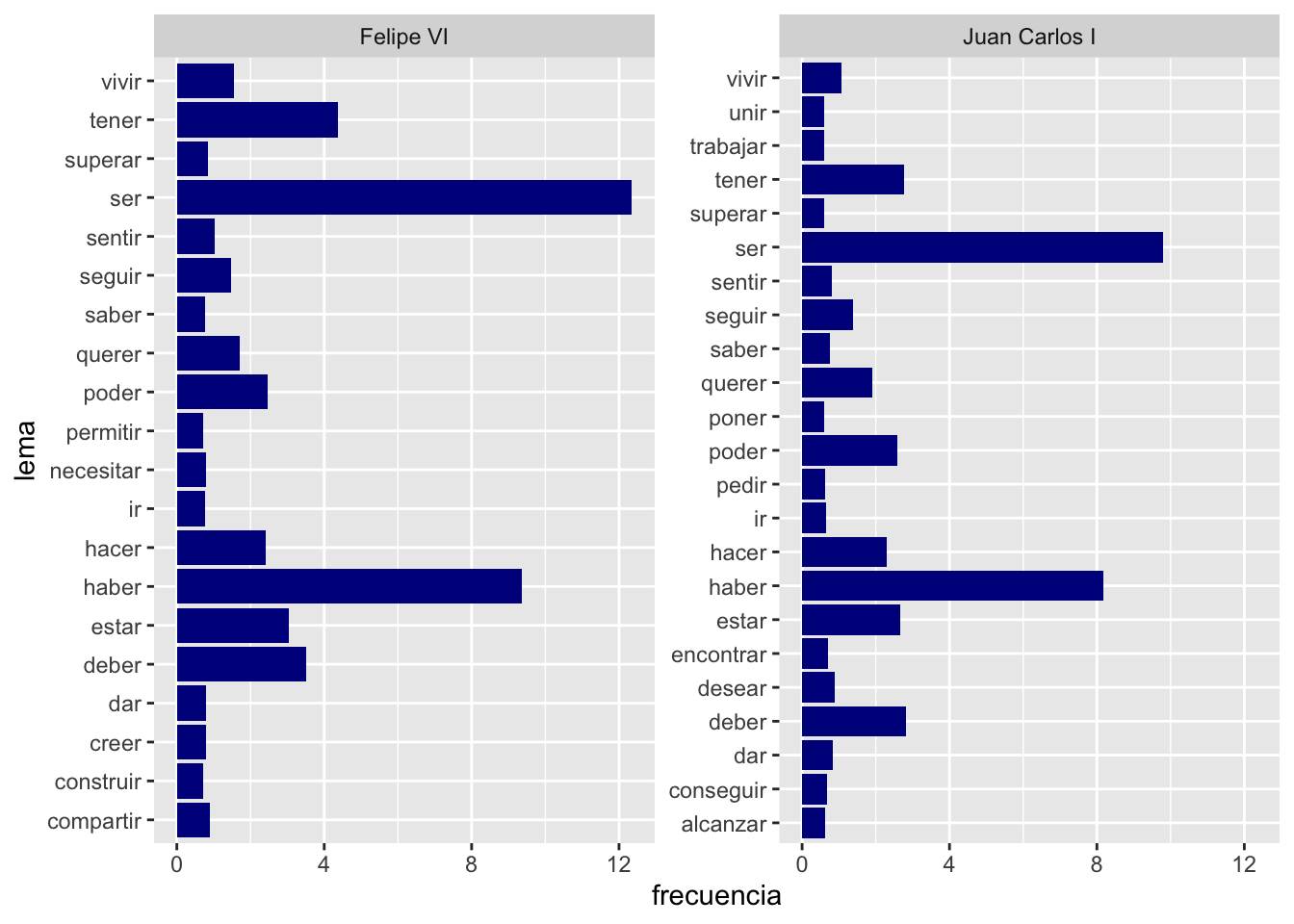
Figura 7.15: Los 20 verbos (lemas) más frecuentes de cada rey
7.6 Nota final
En este capítulo te he mostrado como hacer un análisis morfológico etiquetando con la librería {udpipe}. Te he mencionado que existe una serie de librerías bajo de nombre general de Freeling, que creo que es de los mejorcito que hay para el español. El problema es que instalarlo es una pesadilla porque no está pensado para el usuario final, sino como un conjunto de librerías que se pueden integrar en otros programas.
Si tienes un ordenador Apple, hay una manera muy sencilla de instalar Freeling. Se explica en la página titulada Install freeling on Mac OSX. Una vez instalado, de acuerdo con las instrucciones de esa página, se puede manejar desde R, pero de una manera muy rudimentaria, aunque efectiva.
freeling <- "/usr/local/Cellar/freeling/4.2_4/bin/analyze -f es.cfg <"
# El 4.2_4 puede variar. Las dos últimas cifras pueden ser mayores, compruébalo.
analizable <- "datos/mensajes/2022.txt"
# Indica dónde está el fichero que se quiere analizar
resultado <- "analizado.txt"
# Indica cómo se llamará el resultado y dónde se guardará (raíz de cuentapalabras)
proceso <- paste(freeling, analizable, ">", resultado, sep = " ")
# Une todos los elementos anteriores
system(proceso) # Ejecuta el análisis
El resultado sería el mismo, pues crearía la secuencia
10, 11, 1, 2, 3, 4, 5, 6, 7, 8, 9como has visto cuando creaste el vectoranno(1975:2023). Para regresar pulsa↩︎Añade después de
count(), en el primer bloque,mutate(frecuencia = n/sum(n)*100). En el segundo bloque, dentro deggplot(), cambianporfrecuencia. Para regresar pulsa↩︎