14 Mapas con R: Un poco de geografía lingüística II
14.1 Introducción
Los mapas que has dibujado en el capítulo anterior son suficientemente buenos cuando no necesitas gran precisión. Sin embargo, a veces puedes necesitar mayor detalle en lo que se refiere a los límites territoriales, que pueden ir desde los límites de la comunidad autómona o al municipio. Todo depende del objetivo. Pero eso hace que sea algo más complicado que lo que has visto en la sección anterior.
Con los datos sobre el hinojo he redibujado el mapa limitándolo al territorio que comprende el Atlas Lingüístico y Etnográfico de Aragón, Navarra y La Rioja (ALEARN). Y lo he hecho con los límites provinciales, como puedes ver en el mapa que hay la figura 14.1.
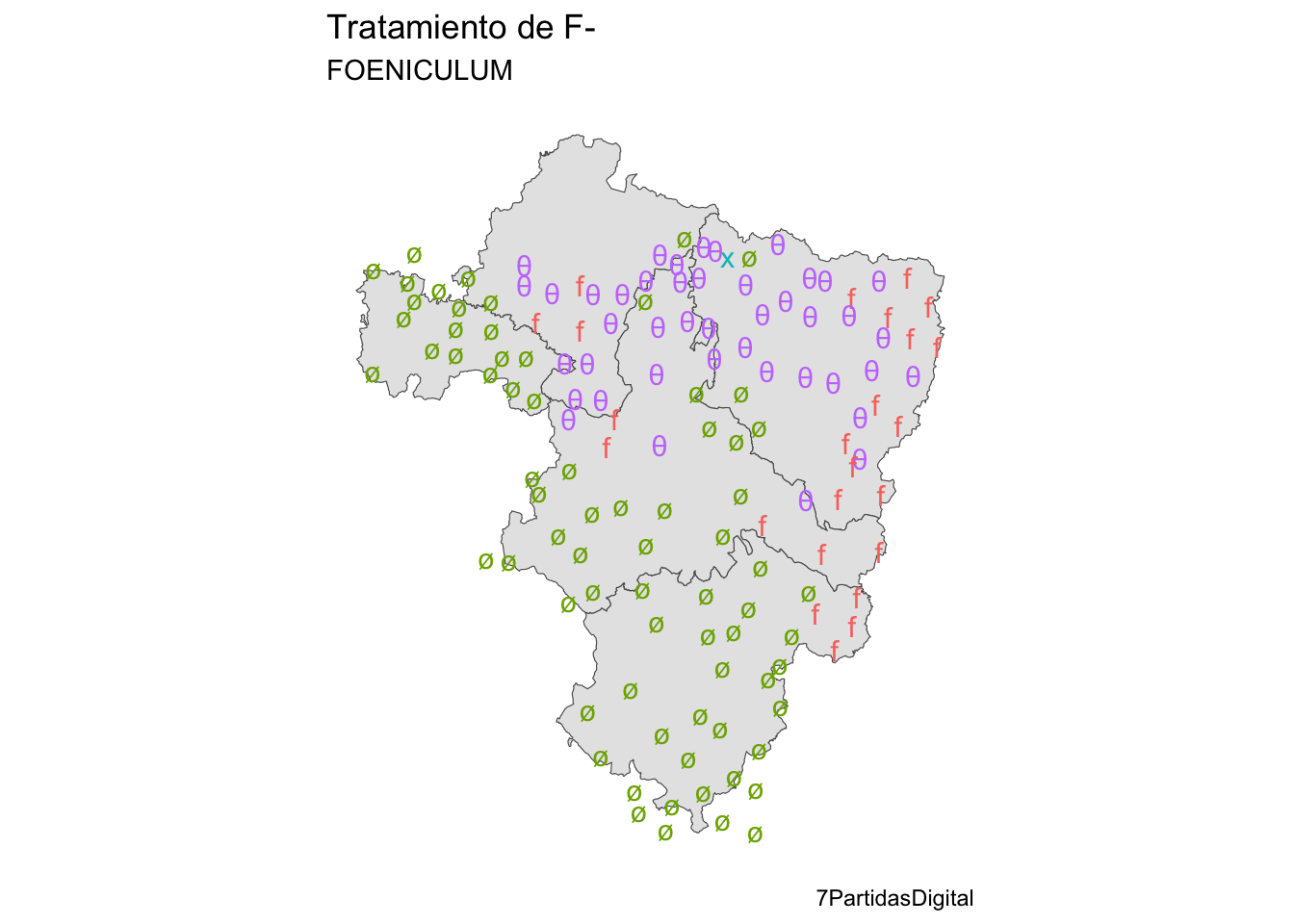
Figura 14.1: Los resultados de F- incial en en ALEARN sobre un mapa con los límites provinciales
Para dibujarlo la cosa se ha complicado un poco. Necesitarás dos nueva librerías, {sf}, {giscoR}, por lo que es un poco más complejo.
14.2 Obtención de los materiales
Ya sabes cómo instalar una librería. Puedes hacerlo desde el panel Packages o con la instrucción install.packages(c("sf", "giscoR")). Así que adelante. Instálalas.
{giscoR} es una librería de R que es una herramienta que facilita descargar y manipular esos datos GISCO directamente desde la base de datos para uso en análisis y visualizaciones. Mientras que {sf} es una librería que permite trabajar con datos espaciales en R, facilitando la manipulación y visualización de datos geográficos.
GISCO es el acrónimo de Geographic Information System of the European Commission, que es un sistema de información geográfica que proporciona datos espaciales y geográficos sobre Europa. Estos datos incluyen información sobre límites administrativos, regiones, ciudades y otros elementos geográficos relevantes para la investigación y el análisis.
Con estas dos librerías puedes trazar con sencillez mapas sobre los que situar los resultados que te interesen. Los niveles de granularidad son 0 para límites nacionales, 1 grandes áreas económicas, 2 regiones al estilo de las comunidades autónomas, y 3 divisiones al estilo de las provincias en España. Tanto individualmente (figura 14.2) como todas las de una comunidad autónoma (figura 14.3) o de toda España.
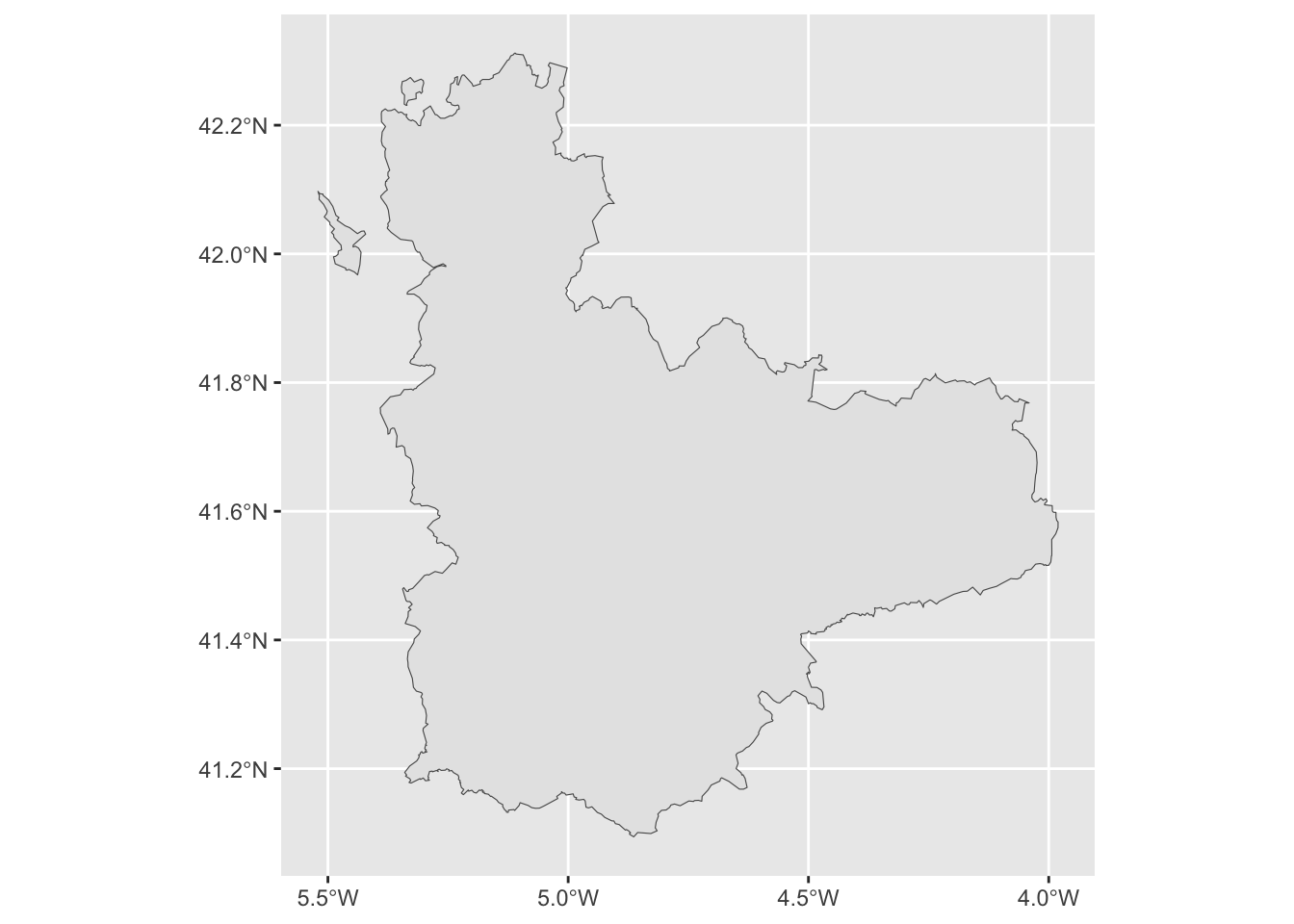
Figura 14.2: La provincia de Valladolid según ESP_adm2
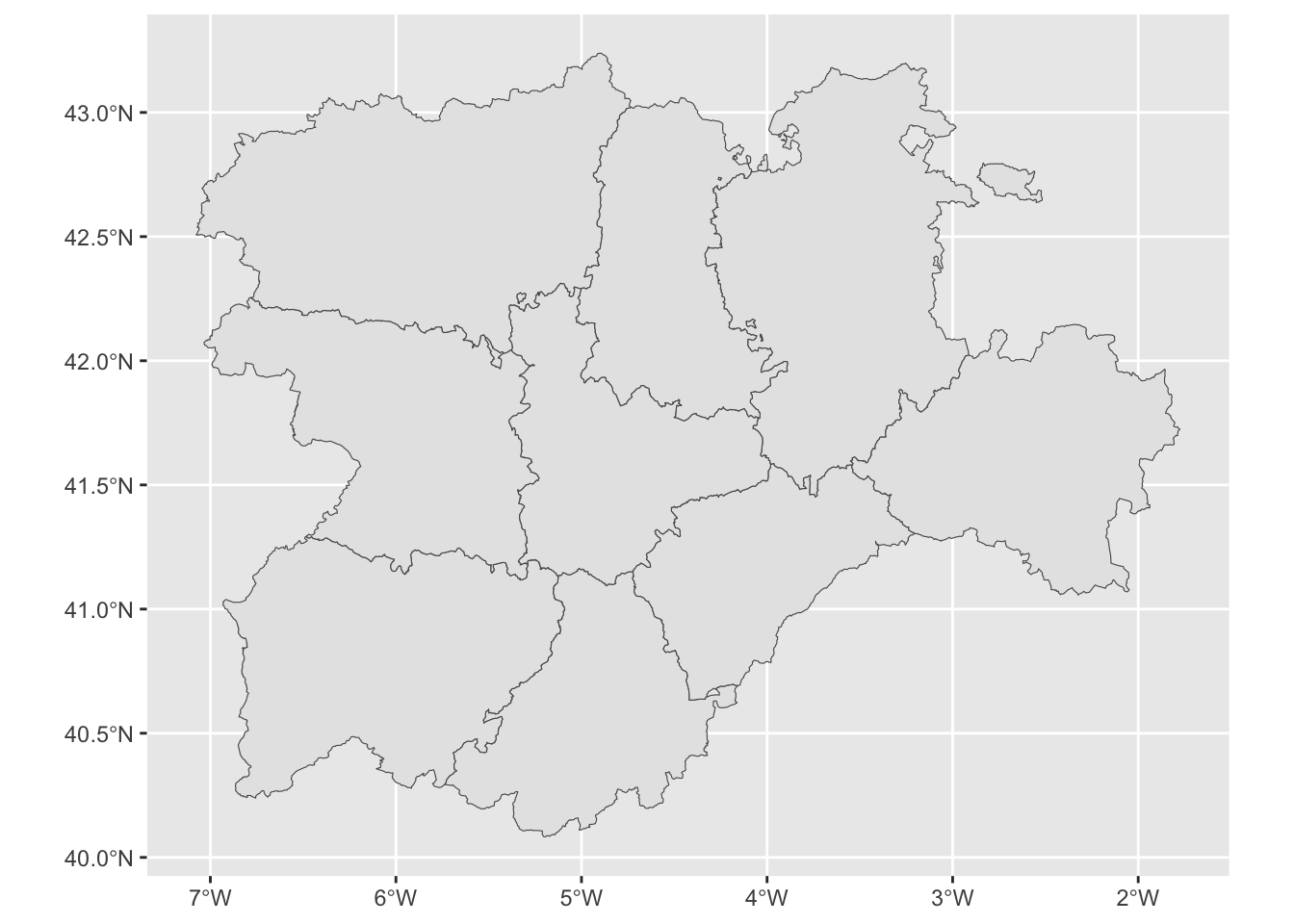
Figura 14.3: Las provincias de Castilla y León
Qué granularidad debes utilizar depende del objetivo de tu análisis. Si trabajar, por ejemplo, con un atlas regional (de pequeño dominio) solo te interesarán las provincias de ese territorio o tan solo la región considerada en el atlas. En cambio, si quieres usar una atlas de tipo supranacional (de gran dominio), entonces necesitas todos los territorios que lo constituyen, aunque a veces tan solo te puedan interesar unas regiones determinadas.
14.3 Un atlas de pequeño dominio y otro de gran dominio
Vas a trabajar con ambos tipos. El primer caso, un atlas de pequeño dominio: el Atlas Lingüístico y Etnográfico de Aragón, Navarra y La Rioja, por lo que solo te intereresarán esas tres comunidades autónomas y sus provincias. En el segundo, un atlas de gran dominio: el Atlas Lingüístico de la Península Ibérica (ALPI) y te interesa no solo el territorio de España, sino también Portugal y parte del sur de Francia, aunque en estos dos últimos hay que renunciar a las divisiones administrativas que pudieran equivaler a nuestras provincias.
En el primer caso obtendrás un mapa como el de la figura 14.4.
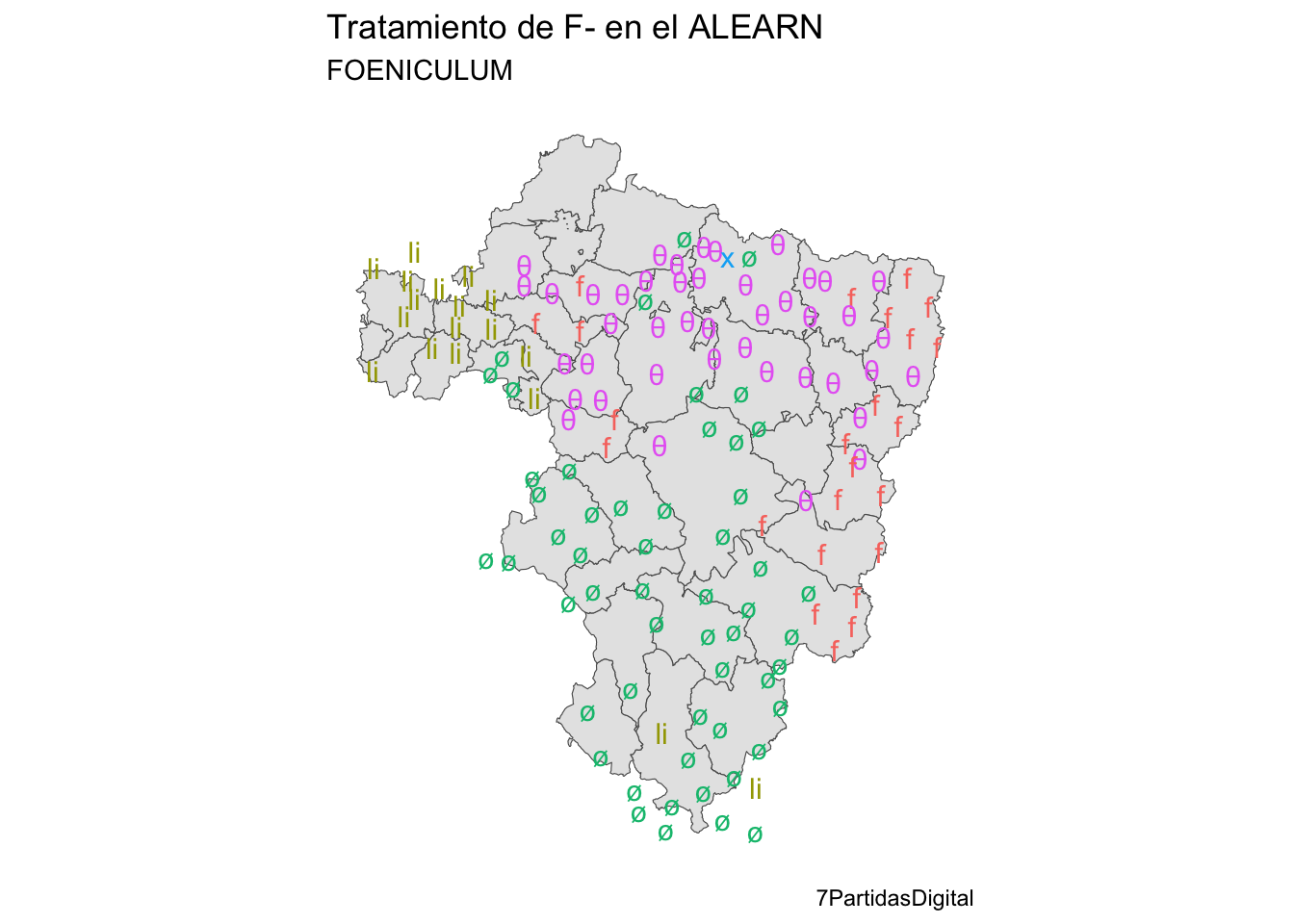
Figura 14.4: Los resultado de F- inicial en el ALEARN sobre un perfil comarcal
En el segundo, el de la figura 14.5, es un pelín más complicado de hacer, aunque la mayoría de los elementos son los mismos.
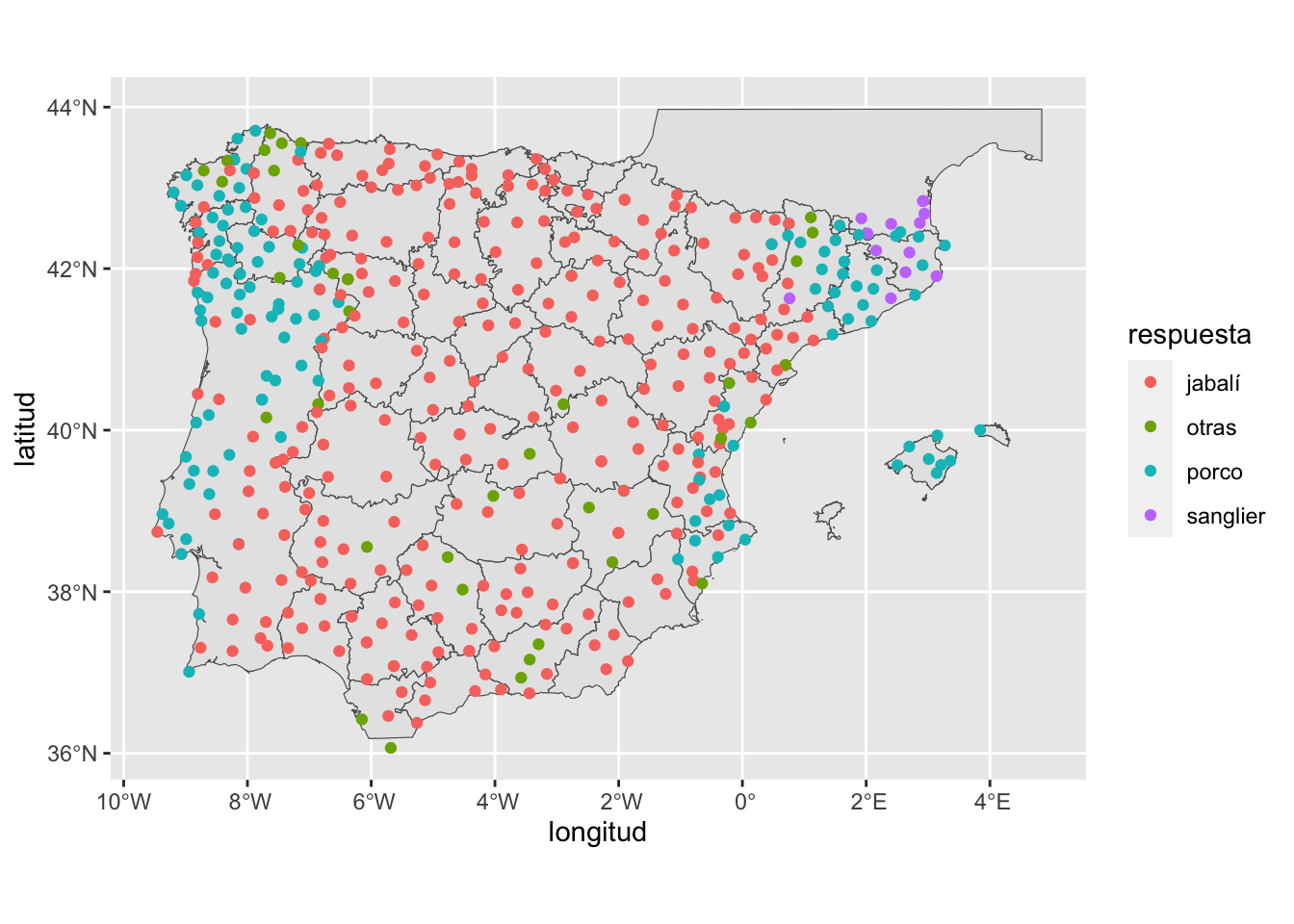
Figura 14.5: Las designaciones del Sus scrofa en la Iberorromania
14.4 Un atlas de pequeño dominio
Para el atlas de pequeño dominio de la figura 14.4 he utilizado el código que hay a continuación. Córtalo y pégalo en el editor de RStudio, pero no lo ejecutes. Lee las explicaciones y ve ejecutándolo según te indique.
library(tidyverse)
library(sf)
library(giscoR)
esp_ccaa <- gisco_get_nuts(country = "ES", nuts_level = "2", resolution = "10")
ALEARN <- c("Aragón", "Comunidad Foral de Navarra", "La Rioja")
ALEARN_mapa <- esp_ccaa %>% filter(NAME_LATN %in% ALEARN)
datos <- read_tsv("https://raw.githubusercontent.com/7PartidasDigital/AnaText/master/datos/geolinguistic/hinojo_alearn.txt")
datos <- datos %>%
mutate(F_inicial = str_replace_all(F_inicial, "li", "ø"))
ggplot(data = ALEARN_mapa) +
geom_sf(fill = NA, color = "black") +
geom_text(data = datos,
aes(x = longitud, y = latitud, label = F_inicial, colour = F_inicial),
size = 4) +
theme(legend.position = "none",
panel.grid.major = element_line(color = "white"),
panel.grid = element_blank(),
axis.title = element_blank(),
axis.text = element_blank(),
axis.ticks = element_blank(),
panel.background = element_blank(),
rect = element_blank()) +
labs(title = "Tratamiento de F-",
subtitle = "FOENICULUM",
caption = "© JMFR")14.4.1 Explicación del código
Lo primero es cargar las tres librerías que va a necesitar. Empieza con {tidyverse} que es la que se encargará de hacerte la vida más fácil en el manejo de las tablas de datos que utilizarás.
Tan pronto como la cargues, el sistema te responderá con el clásico aviso de los paquetes que la constituyen
La siguiente librería que has de cargar es {sf}, que te ayudará a manejar los datos geográficos
que te responderá con el mensaje
y por último debes cargar {giscoR} que se encargará de recolectar los datos geográficos que manejará {sf}.
El siguiente paso es obtener con gisco_get_nuts los datos que se encargarán de dibujar los límites geográficos y los guardarás en la variable esp_ccaa. Esta función necesita varios atributos. El primero es el del país country="ES". Puesto que lo que quieres es representarlo sobre las comarcas tienes que cargar el mapa del nivel 2 y lo consigues con el atributo nuts_level="2". Por último, le tienes que indicar la resolución del mapa. El valor por defecto es 20, pero lo vas a hacer con una resulución algo mejor, por lo que pondrás resolution = "10".
Tan pronto ejecutes la orden, se habrá cargado la información en el objeto esp_ccaa que tendrá 19 observaciones y 10 variables o columnas. El contenido es complejo. Puedes verlo ejecutando en la consola
Hay muchísima información. La más importante para tu trabajo son las variables NAME_LATN y NUTS_ID. La primera contiene el nombre de la comunidad autónoma y la segunda su código NUTS, usaremos cualquiera de para identificarla en los mapas. La tercera es geometry que es la que contiene la información geográfica que se usará para dibujar el mapa. Las demás son informativas y no las necesitas para este trabajo.
Como te he dicho contiene los nombre de las comunidades. No son los oficiales, pero son lo que habrás de usar para filtrar la información. Puedes ver los nombres de las comunidades ejecutando en la consola
## [1] "Extremadura" "Cataluña"
## [3] "Comunidad Valenciana" "Illes Balears"
## [5] "Andalucía" "Región de Murcia"
## [7] "Ciudad Autónoma de Ceuta" "Ciudad Autónoma de Melilla"
## [9] "Canarias" "Galicia"
## [11] "Principado de Asturias" "Cantabria"
## [13] "País Vasco" "Comunidad Foral de Navarra"
## [15] "La Rioja" "Aragón"
## [17] "Comunidad de Madrid" "Castilla y León"
## [19] "Castilla-La Mancha"los códigos de las comunidades autónomas, con los que también podrías filtrar la información, pero son menos evidentes para nosotros.
## [1] "ES43" "ES51" "ES52" "ES53" "ES61" "ES62" "ES63" "ES64" "ES70" "ES11"
## [11] "ES12" "ES13" "ES21" "ES22" "ES23" "ES24" "ES30" "ES41" "ES42"Esta tabla se trata de una data.frame del tipo sf, que contiene simple features. Puedes averiguar cuál es el tipo del objeto esp_ccaa
Como solo nos interesa dibujar las comunidades de Aragón, Navarra y La Rioja, tienes que extraer la información de estos tres territorios. Puedes hacerlo de dos maneras. En la primera, lo primero que tienes que hacer es declarar los territorios que deseas dibujar. La manera más sencilla es creando un nuevo vector con los nombre de las tres comunidades, y para conseguirlo has de concaternarlos con la función c().
Para comprobar que lo has hecho bien, ejectura en la consola
deberá imprimirse este resultado:
## [1] "Aragón" "Comunidad Foral de Navarra"
## [3] "La Rioja"Ahora debes extraer la información de mapa y guardarla en ALEARN_mapa puesto que contendrá la información para dibujar el mapa de esas tres comunidades y las comarcas en las que están divididas (los límites provinciales se pierden). Para ello tienes que usar la función filter() que permite extraer solo una parte de las líneas que contenga una tabla.
Esta línea de código le dice a R que extraiga de esp_ccaa todas las líneas cuya variable NAME_LATN tengan cualquiera de los valores que haya en el vector ALEARN. Si todo ha ido bien, en la ventana Environment debería aparecer una tabla llamada ALEARN_mapa que tiene 3 observaciones y 10 variables. Si no es así, comprueba que los nombres de las tres comunidades son tal y como aparecen en la columna NAME_LATN. Puedes verlos ejecutando en la consola
## [1] "Extremadura" "Cataluña"
## [3] "Comunidad Valenciana" "Illes Balears"
## [5] "Andalucía" "Región de Murcia"
## [7] "Ciudad Autónoma de Ceuta" "Ciudad Autónoma de Melilla"
## [9] "Canarias" "Galicia"
## [11] "Principado de Asturias" "Cantabria"
## [13] "País Vasco" "Comunidad Foral de Navarra"
## [15] "La Rioja" "Aragón"
## [17] "Comunidad de Madrid" "Castilla y León"
## [19] "Castilla-La Mancha"Hay otra columna que tiene los nombres, NUTS_NAME. Esa columna es multialfabeto, y te puedes encontrar (no en este caso) los nombres en griego y en lenguas eslavas con alfebeto cirílico. Podrías usarla, pero nos quedamos con la de NAME_LATN que es la que contiene los nombres en alfabeto latino.
Ahora tienes que leer los datos lingüísticos que se encuentran en el fichero hinojo_alearn.txt que hay en el respositorio del proyecto y guardarlos en la tabla ALEARN_datos. Para ello has de usar la función read_tsv() que ya conoces. La instrucción es la siguiente:
ALEARN_datos <- read_tsv("https://raw.githubusercontent.com/7PartidasDigital/AnaText/master/datos/geolinguistic/hinojo_alearn.txt")Cuando ejecutes la instrucción anterior, se imprimirá en la consola la información que te indica cómo se llama cada una de las columnas de la tabla y qué tipo de valores tiene cada una de ellas.
## Rows: 179 Columns: 8
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: "\t"
## chr (6): atlas, provincia, poblacion, id, F_inicial, cl_inter
## dbl (2): latitud, longitud
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Échale una ojeada a la tabla ejecutando en la consola
aunque solo imprimirá las primeras diez líneas:
## # A tibble: 179 × 8
## atlas provincia poblacion latitud longitud id F_inicial cl_inter
## <chr> <chr> <chr> <dbl> <dbl> <chr> <chr> <chr>
## 1 ALEARN Burgos Bugedo 42.6 -3.02 BU400 li x
## 2 ALEARN Burgos Bugedo 42.7 -2.75 BU400 li x
## 3 ALEARN Castellón Arañuel 40.1 -0.482 CS300 li x
## 4 ALEARN Castellón Segorbe 39.9 -0.485 CS301 ø x
## 5 ALEARN Castellón Bejís 39.9 -0.704 CS302 ø x
## 6 ALEARN Cuenca Valdemeca 40.2 -1.74 CU200 <NA> <NA>
## 7 ALEARN Cuenca Santa Cruz de M… 40.0 -1.26 CU400 ø x
## 8 ALEARN Guadalajara Tortuera 41.0 -1.80 GU200 <NA> <NA>
## 9 ALEARN Guadalajara Orea 41 -1.73 GU400 ø x
## 10 ALEARN Huesca Sallent de Gáll… 42.8 -0.335 HU100 θ x
## # ℹ 169 more rowsNo me entretengo en explicarte el contenido de cada una de ellas. Ya lo hice al comienzo de este capítulo. Pero no te sorprendas porque las nueve primeras líneas sean valores de lugares de la provincia de Burgos, Castellón, Cuenca y Guadalajara (también los hay de Valencia y Álava). No hay error. Los diseñadores del atlas creyeron necesario incluir una serie de puntos de las zonas circundantes para tener una mejor visión de la complejidad dialectal de Aragón, Navarra y La Rioja.
LLegó la hora de imprimir el mapa. Ya tienes todos los datos. En ALEARN_mapa la información geográfica y en ALEARN_datos la información lingüística. Para imprimirlo sería suficiente estas líneas:
ggplot() +
geom_sf(data = ALEARN_mapa) +
geom_text(data = ALEARN_datos,
aes(x=longitud,
y=latitud,
label = F_inicial,
colour = F_inicial),
size = 4)pero imprimirían el mapa con la cuadrícula de fondo y la leyenda lateral que no es nada informativa ni atrayente. Habría que añadir las líneas de código cosmético. Pero antes te explico que hace cada una de las líneas de código anteriores. Como estas con ggplot() las diversas líneas se encadenan con un signo de adición + al final de cada línea. No lo olvides, o estarás un buen rato buscando el error. La función geom_sf(data = ALEARN_mapa) es la responsable de dibujar la capa que representa el territorio. Prúebalo. Ejecuta en la consola
Se habrá impreso en la ventana Plots el mapa que hay en la figura 14.6.
Figura 14.6: Las comarcas de las comunidades de Aragón, Navarra y La Rioja
Tan solo ha dibujado los límites de las comarcas de las tres comunidades autónomas reflejadas en el ALEARN. La siguiente línea de código, que es la más larga, por el momento, se ocupa de situar en el mapa el resultado de cada punto de encuenta y que tienes recogidos en ALEARN_datos.
. . . +
. . . +
geom_text(data = ALEARN_datos,
aes(x=longitud,
y=latitud,
label = F_inicial,
colour = F_inicial),
size = 4)Usas las función geom_text() porque lo que pretendes es que imprima los símbolos fonéticos de los resultados f, θ y ø que tienes en la variable F_inicial y le indicas que los datos se encuentran en la tabla ALEARN_datos (no olvides de anteponer data =, te puede ahorrar más de un quebradero de cabeza).
Con aes() le indicas que en el eje x = debe situar los puntos que le indique la columna longitud y en el eje y = lo que diga la columna latitud. Es decir, dentro del mapa localiza el punto donde se crucen los valores de longitud y latitud y, una vez que lo hayas localizado, escribe, con label =, el contenido que haya en la columna (variable) F_inicial. Lo que hace colour = es mirar cuantos valores diferentes hay en F_inicial y otorgarle a cada uno de ellos un color diferente. Como hay tres valores posibles, usará tres colores. Los elige R, aunque podrías establecerlos tú, pero, evidentemente, complicaría la programación.
Con la última línea size = determinas el tamaño de la letras que se van a imprimir en cada punto del mapa. Aquí es cuestión de prueba y error. Todo depende del destino final del gráfico. Lo que ves en la figura 14.7 es lo que se imprimiría al juntar las dos primeras líneas con las del grupo que te acabo de presentar.
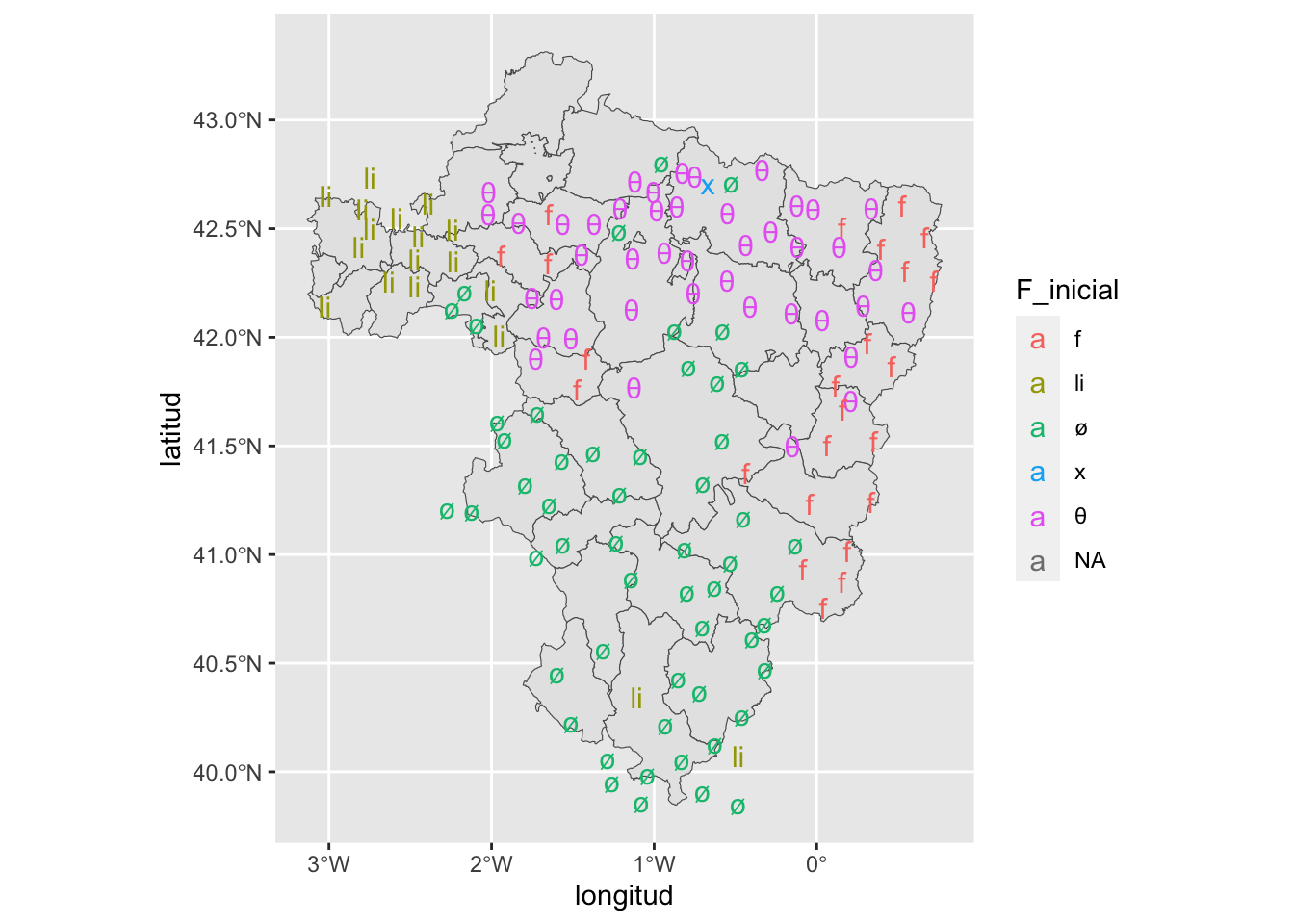
Figura 14.7: El mapa de los resultados con leyenda y fondos
En la consola puede que se haya impreso este mensaje de aviso:
Warning message:
Removed 39 rows containing missing values (geom_text).Te avisa, sencillamente, de que en ALEARN_datos hay 39 puntos de encuesta en los que no hubo respuesta y que contienen el valor NA y que, por tanto, no los puede representar.
El resto del código, es la serie de instrucciones que hacen que no se imprima el fondo gris, la cuadrícula, la leyenda lateral, las indicaciones de latitud y longitud y añade el título en la parte superior.
. . .
theme(legend.position = "none",
panel.grid.major = element_line(color = "white"),
panel.grid = element_blank(),
axis.title = element_blank(),
axis.text = element_blank(),
axis.ticks = element_blank(),
panel.background = element_blank(),
rect = element_blank()) +
labs(title = "Tratamiento de F- en el ALEARN",
subtitle = "FOENICULUM")El resultado tiene que ser el del mapa de la figura 14.8.
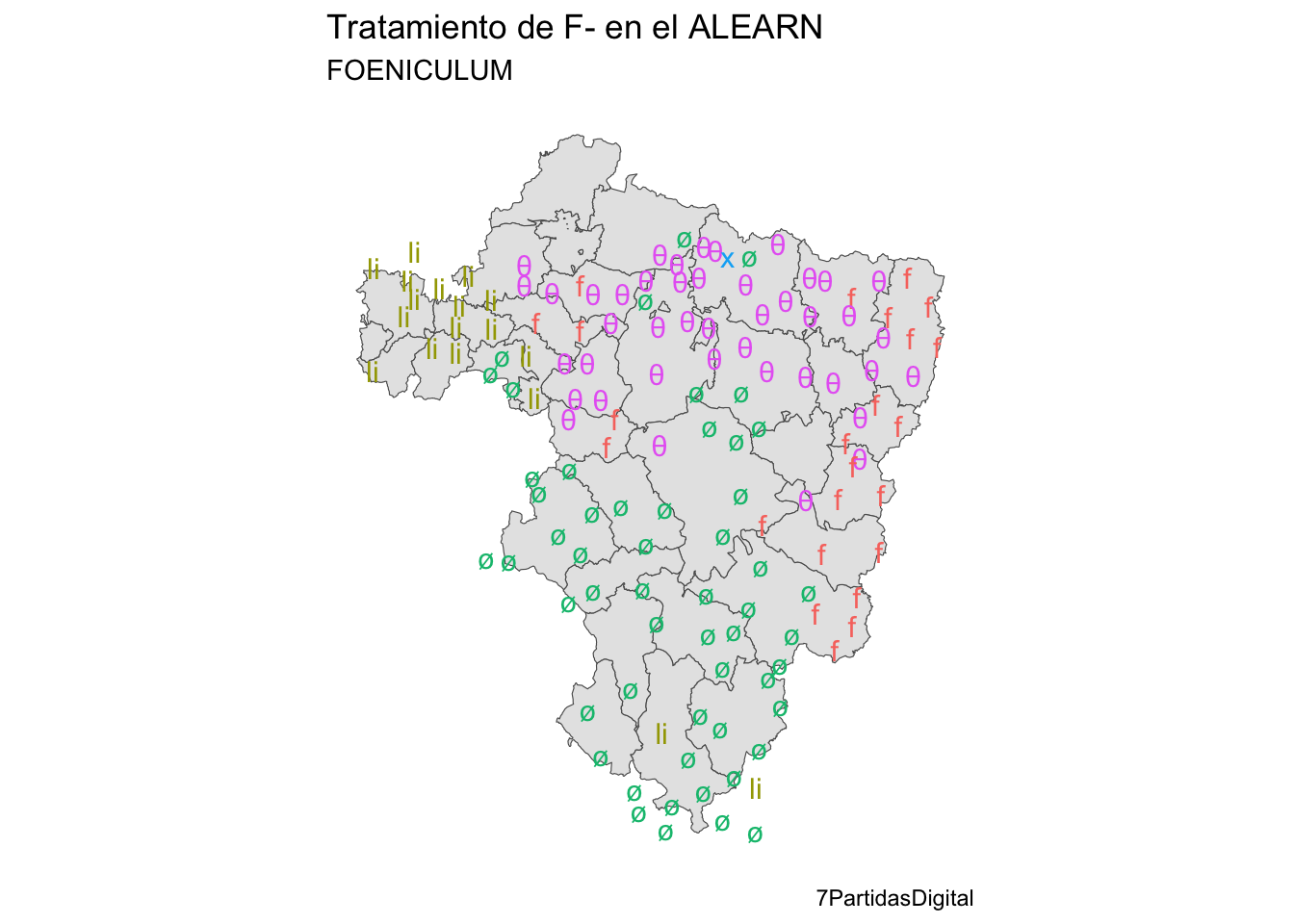
Figura 14.8: Mapa embellecido con los resultados
14.5 Atlas de gran dominio
14.5.1 Los datos lingüísticos
En la península Ibérica solo hay un atlas de gran dominio, el Atlas Lingüístico de la península Ibérica que no solo incluye la España peninsular e islas Baleares, sino también dos países más: Portugal y Andorra y una pequeña porción de Francia, el Rosellón. Es un atlas concebido por Ramón Menéndez Pidal a principios del siglo XX y que dirigió Tomás Navarro Tomás desde el Centro de Estudios Históricos en los años veinte y treinta del siglo pasado. Aunque la mayoría de las encuestas se realizaron entre 1931 y 1936, el proyecto se paró a causa de la guerra civil. Tras la contienda se retomó la labor parcialmente y en 1962 se publicó el primer tomo, con 75 mapas.
Los materiales anduvieron perdidos y cuando afloraron se empezaron a poner a disposición de los investigadores en los servidores del CSIC. De ahí se han extraido los datos referentes a diez preguntas procedentes del segundo cuaderno de encuesta.
| puntos | pregunta |
|---|---|
| 458 | Guisantes |
| 493 | Mariquita |
| 496 | Lagartija |
| 502 | Aguzanieves |
| 520a | Jabalí |
| 600a | Cadera |
| 704 | Cuna |
| 751 | LLevar a cuestas |
| 753a | Dar volteretas |
| 825 | Levadura |
Las respuestas a estas diez cuestiones se pueden consultar en la web del ALPI –Consulta mapas–. Se trata de una página de resultados que ofrece una compleja tabla que no permite extraer de manera automática los resultados (figura 14.9).
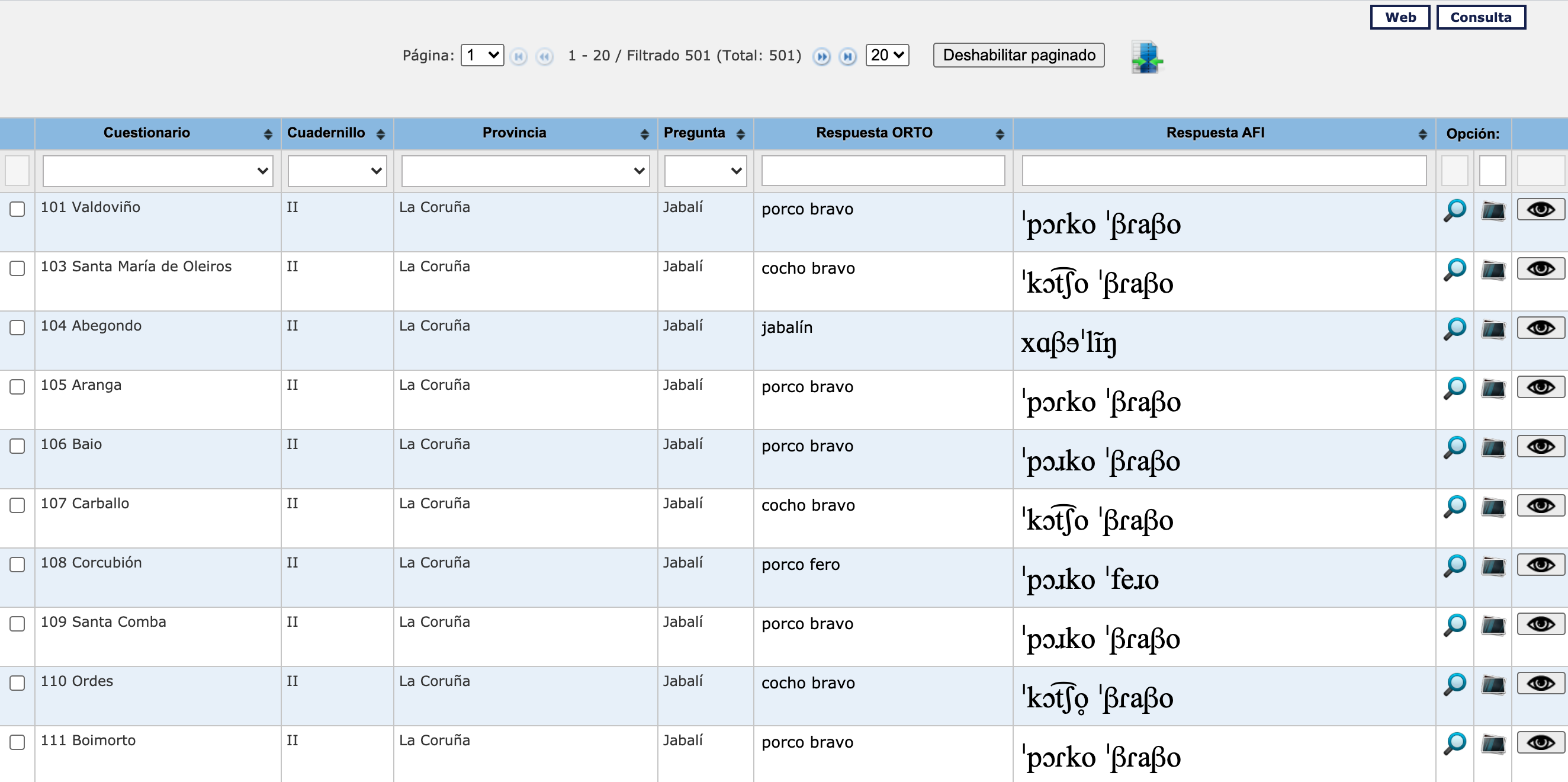
Figura 14.9: Captura de la primera página de resultados del ALPI
Aún así, se han podido recoger y formar una tabla que contiene las respuestas a esas diez preguntas en todos los puntos de encuesta del ALPI. Es una tabla con las columnas correspondientes al código de identificación (id), la pregunta (pregunta), la respuesta ortográfica (ortografia) (que es una recreación hecha por los investigadores del CSIC a partir de las transcipciones fonéticas de los cuadernos de encuesta) y la transcripción AFI (afi), que es una conversión desde el alfabeto RFE, que es el que usa el ALPI, a un sistema de transcripción fonética que puede viajar por la red y está estandarizado. No se han recogido el nombre del lugar, el de la provincia ni la referencia al cuestionario en el que figuran las cuestiones puesto que es información ociosa para el objetivo de este capítulo.
La tabla creada tiene este aspecto
| id | pregunta | ortografia | afi |
|---|---|---|---|
| 100 | Cuna | berce | ˈbɛɾθe |
| 101 | Cuna | berce | ˈbɛɾθe |
| 102 | Cuna | berce | ˈbɛɾθe |
| 103 | Cuna | berce | ˈbɛɾθə |
| 104 | Cuna | berce | ˈbɛɾθə |
| 105 | Cuna | berce | ˈbɛɾθi |
| 106 | Cuna | berce | ˈbɛɾs̺i̥ |
| 107 | Cuna | berce | ˈbɛɾθi̥ |
| 108 | Cuna | berce | ˈbɛɹs̺i̥ |
| 109 | Cuna | berce | ˈbɛɾse |
Lo primero que tienes que hacer es leer la tabla. Pero antes de hacerlo has de cargar la librería {tidyverse}, que es esencial para hacer la vida más fácil en el manejo de tablas.
Lee ahora la tabla con
alpi <- read_tsv("https://raw.githubusercontent.com/7PartidasDigital/AnaText/master/datos/geolinguistic/alpi.txt")Esta tabla tiene más de 5600 líneas, pero solo vas a usar las correspondientes a las respuestas que se obtuvieron a la pregunta del jabalí, por lo que vas a borrar todas las demás. Para ello tan solo tienes que usar la función filter(), como puedes ver en esta instrucción que hay a continuación. Con ella lo que le pides a R es que conserve aquellas líneas en las que el contenido de la variable pregunta sea idéntico a (==) Jabalí. Recuerda que si lo escribes con minúscula, o te olvidas de la tilde de la i no obtendrás resultado alguno. Los ordenadores son exasperadamente literales.
Tan pronto como la ejecutes, la tabla se habrá reducido a 503 líneas. Échale una ojeada ejecutando en la consola
Se habrán impreso las diez primeras líneas de la tabla, muy parecida a la que viste antes, pero en la que las columnas 2, 3 y 4 han cambiado totalmente sus valores.
## # A tibble: 503 × 4
## id pregunta ortografia afi
## <chr> <chr> <chr> <chr>
## 1 100 Jabalí porco bravo ˈpɔɾko ˈβɾaβo
## 2 101 Jabalí porco bravo ˈpɔɾko ˈβɾaβo
## 3 102 Jabalí porco bravo ˈpɔɾko ˈβɾaβo
## 4 103 Jabalí cocho bravo ˈkɔt͡ʃo ˈβɾaβo
## 5 104 Jabalí jabalín xɑβɘˈlĩŋ
## 6 105 Jabalí porco bravo ˈpɔɾko ˈβɾaβo
## 7 106 Jabalí porco bravo ˈpɔɹko ˈβɾaβo
## 8 107 Jabalí cocho bravo ˈkɔt͡ʃo ˈβɾaβo
## 9 108 Jabalí porco fero ˈpɔɹko ˈfeɹo
## 10 109 Jabalí porco bravo ˈpɔɹko ˈβɾaβo
## # ℹ 493 more rowsYa tienes toda la información lingüística que vas a necesitar. Ahora has de conseguir el mapa sobre el que cartografiarás los resultados.
14.5.2 Dibujar el mapa
Como ya he dicho, el ALPI es un atlas de gran dominio y, además, supranacional puesto que abarca España (península e islas Baleares), Portugal (continental), Andorra y una minúscula parte del sur de Francia, por lo que para ubicar los resultados de las encuestas has de utilizar un mapa que represente esos territorios. Podrías hacerlo con la función borders() de ggplot().
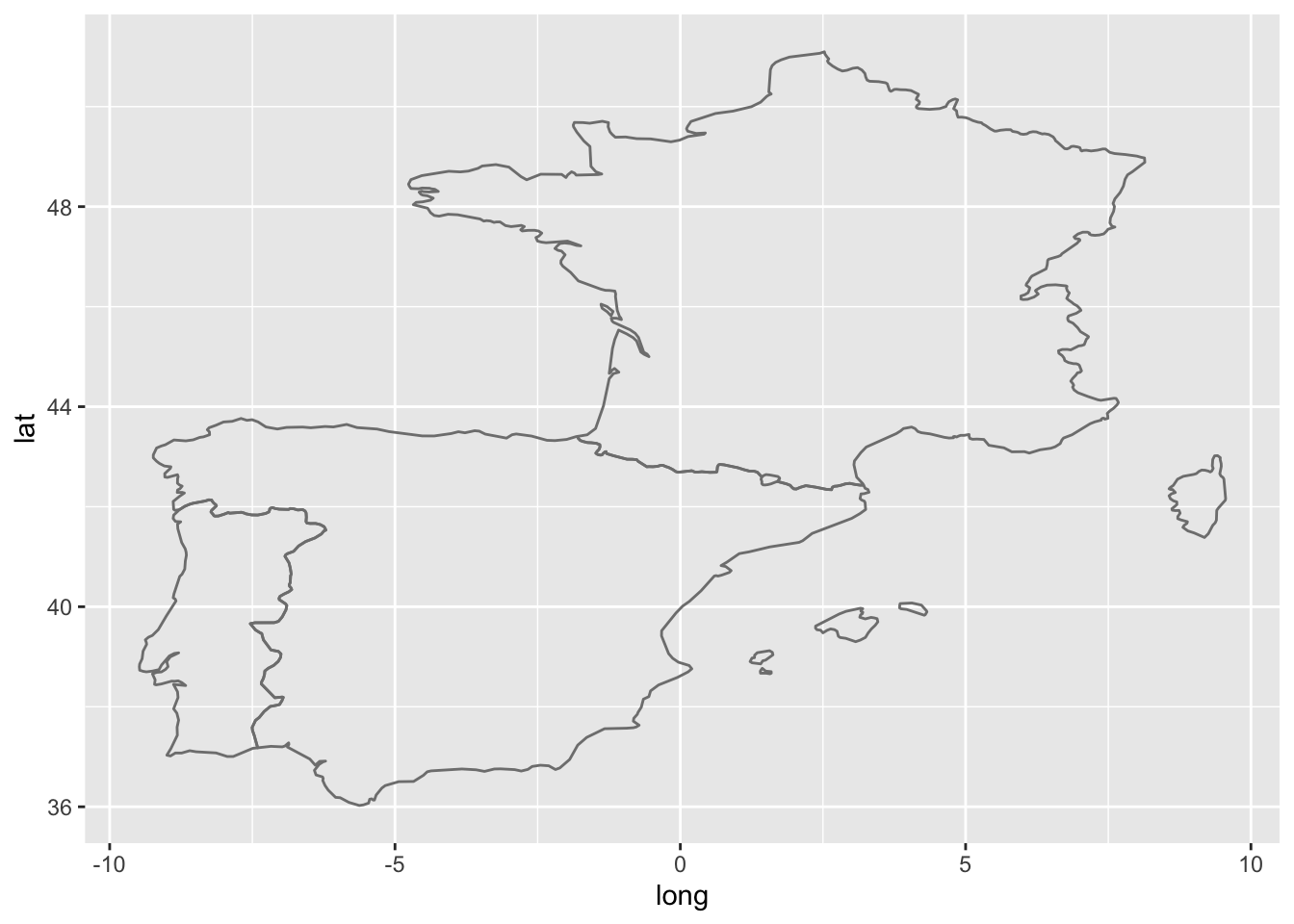
Figura 14.10: Siluetas de España, Portugal, Andorra y Francia con borders
Esta función dibuja toda Francia, incluída la isla de Córcega, como puedes ver en el mapa de la figura 14.10. Pero de Francia solo nos interesa un pequeño territorio del sur, el Rosellón. Como mucho nos interesaría que dibujara el territorio al sur del paralelo 44 y al oeste del meridiano 5, como puedes ver en el mapa de la figura 14.11. Con este sistema, excelente en otros momentos, no puedes conseguir el resultado pertinente, por lo que a un sistema que permita pueda dibujar el ámbito geográfico pertinente.
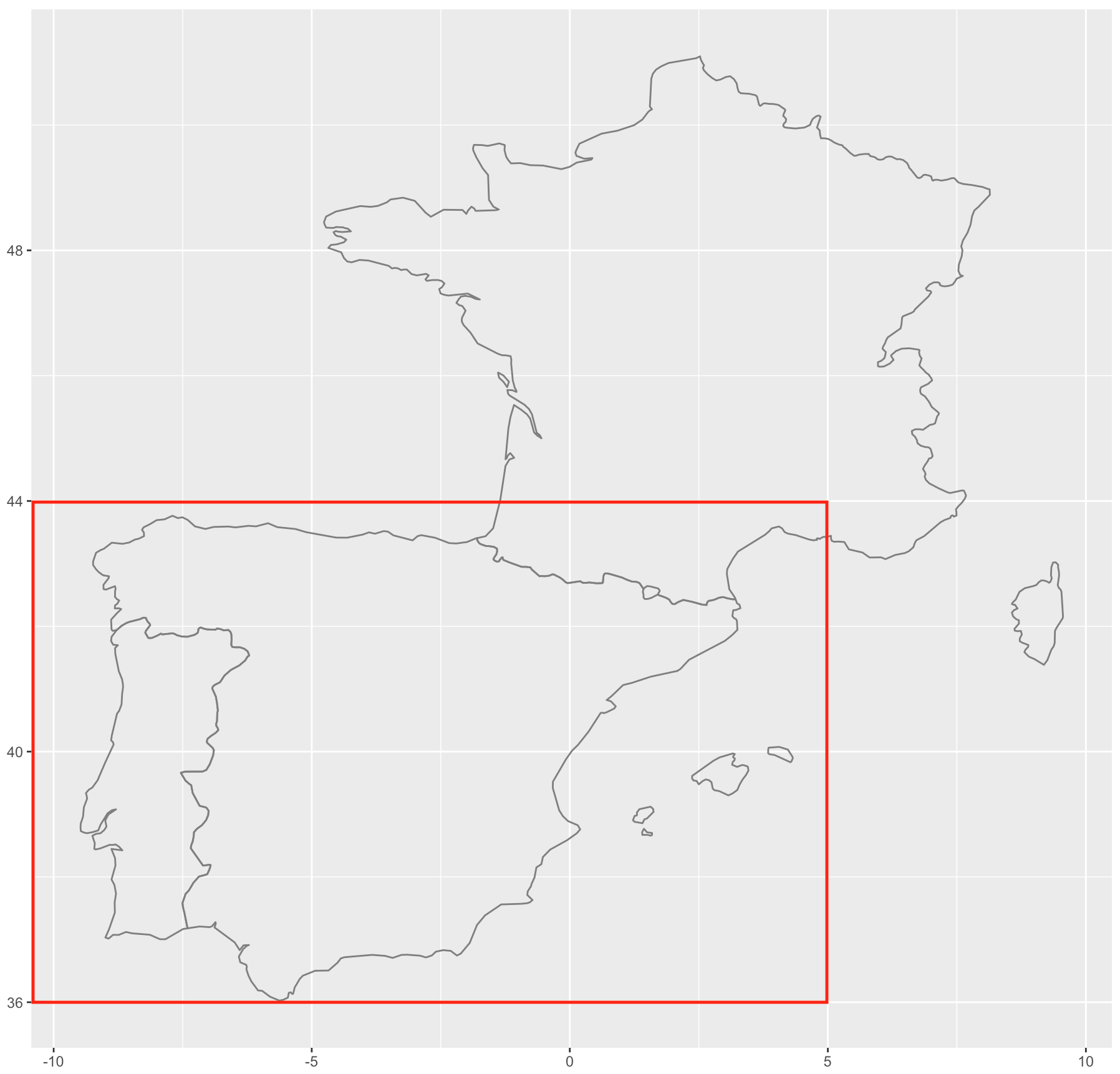
Figura 14.11: Zona que interesa (recuadro rojo
Para ello usarás las misma librerías que en la sección anterior, {sf} y {giscoR}. La primera es la que se encargará de manejar los datos geográficos y la segunda la que te proporcionará los datos geográficos necesarios para dibujar el mapa. Por lo que has de cargar las dos librerías.
En esta ocasión, vamos a hacer que el mapa incluya los límites de las provincias españolas, por lo que has de usar la función gisco_get_nuts() con el atributo nuts_level = "3" que es el que corresponde a las provincias. El resto de los atributos son los mismos que en la sección anterior: country = "ES" y resolution = "20". La instrucción es la siguiente:
Habrá aparecido un nuevo objeto en Environment llamado esp_prov con 59 filas y diez columnas. Tienen la misma información que has visto en la sección anterior. Por curiosidad, vamos a mirar el nombre de cada una de las provincias con
## [1] "Tenerife" "A Coruña" "Lugo"
## [4] "Ourense" "Pontevedra" "Asturias"
## [7] "Cantabria" "Araba/Álava" "Gipuzkoa"
## [10] "Bizkaia" "Navarra" "La Rioja"
## [13] "Huesca" "Teruel" "Zaragoza"
## [16] "Madrid" "Ávila" "Burgos"
## [19] "León" "Palencia" "Salamanca"
## [22] "Segovia" "Soria" "Valladolid"
## [25] "Zamora" "Albacete" "Ciudad Real"
## [28] "Cuenca" "Guadalajara" "Toledo"
## [31] "Badajoz" "Cáceres" "Barcelona"
## [34] "Girona" "Lleida" "Tarragona"
## [37] "Alicante/Alacant" "Castellón/Castelló" "Valencia/València"
## [40] "Eivissa y Formentera" "Mallorca" "Menorca"
## [43] "Almería" "Cádiz" "Córdoba"
## [46] "Granada" "Huelva" "Jaén"
## [49] "Málaga" "Sevilla" "Murcia"
## [52] "Ceuta" "Melilla" "El Hierro"
## [55] "Fuerteventura" "Gran Canaria" "La Gomera"
## [58] "La Palma" "Lanzarote"Quizá te sorprenda que aparezcan como nombres de provincias todas y cada una de las islas canarias y Baleares, pero es información que ofrece la Unión Europea, y ellos sabrán porqué lo hacen así. Lo que te interesa saber es que esos son los nombres que tienen si quieres representar cualquiera de las provincias españolas y las islas que componen los dos archipiélagos.También están los códigos NUTS, pero es más claro el nombre que no un secuencia alfanumérica.
Ahora has de recuperaqr los datos para dibujar el mapa de Francia, el de Portugal y el de Andorra, aunque con estos países no nos vamos de entretener con las subdivisiones como hicimos con las provincias. Para ello has de usar la función gisco_get_countries() con los atributos country = "FR", country = "PT" y country = "AD" respectivamente. Usa las tres instrucciones que tienes a continuación para conseguirlo:
fra <- gisco_get_countries(country = "FR")
prt <- gisco_get_countries(country = "PT")
and <- gisco_get_countries(country = "AD")Verás que en este caso cada una de las nuevas tablas solo tiene una observación y seis variables. De esas seis la importante es geometry Ya tienes la lista de todos los territorios que quieres dibujar en el mapa.
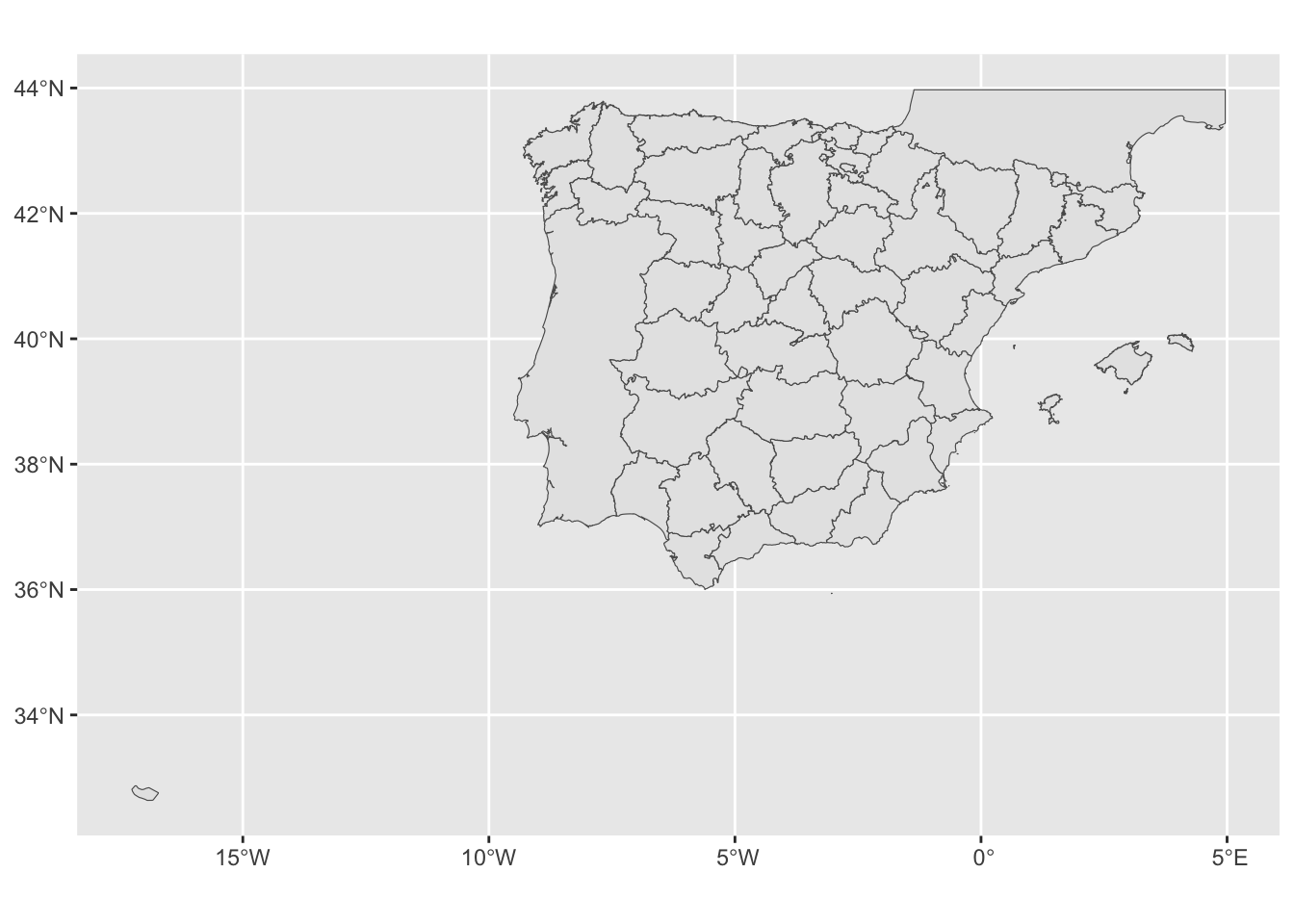
Figura 14.12: Especio geográfico que se quiere representar
14.5.3 Las coordenadas de los puntos de encuesta
Ya tienes los datos para dibujar el mapa —esp_prov, fra, prt y and— y los datos lingüísticos —alpi—. Sin embargo, falta un detalle. La localización de cada uno de los puntos de encuesta. Al contario de lo que viste en la sección Un atlas pequeño dominio, el objeto con los datos lingüísticos que has leído del repositorio del proyecto no tiene las coordenadas de cada punto de encuesta. Tienes que conseguirlas.
No vas a buscarlos a mano, ni tampoco con la librerías como {georeference} porque tendrías muchos errores y te llevaría mucho tiempo. En el proyecto 7PartidasDigital hemos creado un fichero tsv en el que se han localizado todos los puntos de encuesta de varios atlas lingüísticos peninsulares: Atlas Lingüístico y Etnográfico de Andalucía –ALEA–, Atlas Lingüístico y Etnográfico de Aragón, Navarra y La Rioja –ALEARN–, Atlas Lingüístico (y Etnográfico) de Castilla-La Mancha –ALCLM–, Atlas Lingüístico de Castilla y León –ALCYL–, Atlas dialectal de Madrid –ADIM–, Petit Atles Linguistic del Domini Català –PALDC– y, por supuesto, el Atlas lingüístico de la península Ibérica –ALPI– (en el futuro, según tengamos acceso a los materiales, se añadirán los puntos de encuesta del Atlas lingüístico y etnográfico de Cantabria, el Atlas Lingüístico Galego, etc.).
La estructura del fichero con esta información es la que puedes observar en la tabla que hay a continuación.
## Rows: 1558 Columns: 7
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: "\t"
## chr (5): atlas, id, poblacion, provincia, CCAA
## dbl (2): latitud, longitud
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.| atlas | id | poblacion | latitud | longitud | provincia | CCAA |
|---|---|---|---|---|---|---|
| ADIM | M1 | Mangirón | 40.96408 | -3.587009 | Madrid | Madrid |
| ADIM | M2 | Buitrago de Lozoya | 40.98729 | -3.646177 | Madrid | Madrid |
| ADIM | M3 | Lozoya | 40.95550 | -3.799294 | Madrid | Madrid |
| ADIM | M4 | Patones | 40.85464 | -3.489306 | Madrid | Madrid |
| ADIM | M5 | Navacerrada | 40.72645 | -4.021921 | Madrid | Madrid |
| ADIM | M6 | El Boalo | 40.71722 | -3.919913 | Madrid | Madrid |
| ADIM | M7 | Alalpardo | 40.62820 | -3.480723 | Madrid | Madrid |
| ADIM | M8 | Meco | 40.55122 | -3.338020 | Madrid | Madrid |
| ADIM | M9 | Santa María de la Alameda | 40.59782 | -4.262920 | Madrid | Madrid |
| ADIM | M10 | Valdemorillo | 40.48650 | -4.091224 | Madrid | Madrid |
La variable atlas contiene la sigla de los atlas lingüísticos recogidos. La variable id contiene la referencia al punto de encuesta. Es el único valor inequívoco en lo que respecta a la identificación del punto. Los nombres de las poblaciones, recogidos en la variable poblacion, son muy problemáticos, pues los nombre que dan los diversos atlas pueden tener variaciones ortográficas, haber cambiado totalmente, e incluso haber desaparecido. Las columnas latitud y longitud corresponden a la coordenadas del punto de encuesta lugar. No se puede decir a qué punto concreto corresponde del municipio (en el caso de que sea un municipio) ya que la tabla se ha construido con la librería {georeference} y, cuando ha habido errores de localización, se ha corregido manualmente localizando el lugar en Google Maps o con las coordenadas que ofrece Wikipedia para las diversas ciudades y poblaciones que tiene recogidas en cualquiera de sus versiones. La columna provincia contiene el nombre de la provincia en el que se encuentra el lugar encuestado. En el caso de Francia son departamentos y en el de Portugal distritos. La última variable, CCAA recoge el nombre de la comunidad autónoma en la que se ubica cada punto de encuesta. En el caso de los puntos de encuesta de Portugal, Francia y Andorra es el nombre del país.
Con esta tabla ya puedes obtener las coordenadas para cada punto de encuesta de cualquier atlas lingüístico cuyos datos quieras representar en un mapa de manera diferente a como parecen en las publicaciones originales.
Como estas trabajando con el ALPI, y en el fichero hay información de otros seis atlas, tan solo te interesa acceder a los datos del ALPI. Ya sabes que la forma de borrar de una tabla o extraer de ella datos es por medio de la función filter(). Reducir el objeto atlas de 1558 a los poco más de 500 puntos que conforman la red de puntos del ALPI se consigue con
Cuando ejecutes la orden anterior, podrás ver que el objeto atlas tiene ahora 524. El siguiente paso es incorporar al objeto alpi la información de las variables latitud y longitud.
Recordarás que cuando querías borrar las palabras vacías, usaste la función anti_join(). Lo que esta hacía era mirar en el objeto que le indicabas en el argumento y comprobar si en el texto que estabas analizando existían esas palabras y si existían las borraba. Ahora se trata de unir, añadir, a alpi las columnas longitud y latitud del objeto atlas. Hay varias funciones para unir dos tablas: full_join(), left_join(), right_join() e inner_join(). Cada una de ellas tiene un comportamiento diferente.
Para estas uniones tiene que haber una variable en común. En este caso será id que es la única que es inequívoca para cada uno de los atlas, pues, como te he dicho, los nombres de las poblaciones han podido cambiar con respecto a los nombres que ofrecen los diversos atlas lingüísticos. Por ejemplo, en el ALEA el punto GR400 corresponde a Cúllar-Baza, pero el nombre oficial de esta población granadina es, desde 1986, Cúllar. Otro caso extremo es la desginación de algunos puntos de encuenta en el PALDC. El punto 149 de este atlas se identifica como Vilafranca del Maestrat que se corresponde con Villafranca del Cid (nombre oficial castellano) o Vilafranca (nombre oficial valenciano). Estos pequeños problemas llevan cierto tiempo al recolectar los datos.
Incorpora a alpi las informaciones geográficas contenidas en atlas por medio de la variable común id. En este caso particular es indiferente que uses inner_join(), left_join() o right_join() puesto que todas ofrecerán el mismo resultado: añadirán a continuación de la columna afi todas las columnas de atlas.
Con right_join() el resultado sería (la cantidad de columnas que se imprima depende del ancho de la consola):
## # A tibble: 552 × 10
## id pregunta ortografia afi atlas poblacion latitud longitud provincia
## <chr> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <chr>
## 1 100 Jabalí porco bravo ˈpɔɾko… ALPI Sismundi 43.7 -7.87 La Coruña
## 2 101 Jabalí porco bravo ˈpɔɾko… ALPI Valdoviño 43.6 -8.16 La Coruña
## 3 102 Jabalí porco bravo ˈpɔɾko… ALPI Miño 43.3 -8.21 La Coruña
## 4 103 Jabalí cocho bravo ˈkɔt͡ʃo… ALPI Santa Ma… 43.3 -8.32 La Coruña
## 5 104 Jabalí jabalín xɑβɘˈl… ALPI Abegondo 43.2 -8.28 La Coruña
## 6 105 Jabalí porco bravo ˈpɔɾko… ALPI Aranga 43.2 -8.02 La Coruña
## 7 106 Jabalí porco bravo ˈpɔɹko… ALPI Baio 43.2 -8.99 La Coruña
## 8 107 Jabalí cocho bravo ˈkɔt͡ʃo… ALPI Carballo 43.2 -8.71 La Coruña
## 9 108 Jabalí porco fero ˈpɔɹko… ALPI Corcubión 42.9 -9.19 La Coruña
## 10 109 Jabalí porco bravo ˈpɔɹko… ALPI Santa Co… 43.0 -8.81 La Coruña
## # ℹ 542 more rows
## # ℹ 1 more variable: CCAA <chr>Si utilizas left_join() sería:
## # A tibble: 503 × 10
## id pregunta ortografia afi atlas poblacion latitud longitud provincia
## <chr> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <chr>
## 1 100 Jabalí porco bravo ˈpɔɾko… ALPI Sismundi 43.7 -7.87 La Coruña
## 2 101 Jabalí porco bravo ˈpɔɾko… ALPI Valdoviño 43.6 -8.16 La Coruña
## 3 102 Jabalí porco bravo ˈpɔɾko… ALPI Miño 43.3 -8.21 La Coruña
## 4 103 Jabalí cocho bravo ˈkɔt͡ʃo… ALPI Santa Ma… 43.3 -8.32 La Coruña
## 5 104 Jabalí jabalín xɑβɘˈl… ALPI Abegondo 43.2 -8.28 La Coruña
## 6 105 Jabalí porco bravo ˈpɔɾko… ALPI Aranga 43.2 -8.02 La Coruña
## 7 106 Jabalí porco bravo ˈpɔɹko… ALPI Baio 43.2 -8.99 La Coruña
## 8 107 Jabalí cocho bravo ˈkɔt͡ʃo… ALPI Carballo 43.2 -8.71 La Coruña
## 9 108 Jabalí porco fero ˈpɔɹko… ALPI Corcubión 42.9 -9.19 La Coruña
## 10 109 Jabalí porco bravo ˈpɔɹko… ALPI Santa Co… 43.0 -8.81 La Coruña
## # ℹ 493 more rows
## # ℹ 1 more variable: CCAA <chr>mientras que con inner_join():
## # A tibble: 503 × 10
## id pregunta ortografia afi atlas poblacion latitud longitud provincia
## <chr> <chr> <chr> <chr> <chr> <chr> <dbl> <dbl> <chr>
## 1 100 Jabalí porco bravo ˈpɔɾko… ALPI Sismundi 43.7 -7.87 La Coruña
## 2 101 Jabalí porco bravo ˈpɔɾko… ALPI Valdoviño 43.6 -8.16 La Coruña
## 3 102 Jabalí porco bravo ˈpɔɾko… ALPI Miño 43.3 -8.21 La Coruña
## 4 103 Jabalí cocho bravo ˈkɔt͡ʃo… ALPI Santa Ma… 43.3 -8.32 La Coruña
## 5 104 Jabalí jabalín xɑβɘˈl… ALPI Abegondo 43.2 -8.28 La Coruña
## 6 105 Jabalí porco bravo ˈpɔɾko… ALPI Aranga 43.2 -8.02 La Coruña
## 7 106 Jabalí porco bravo ˈpɔɹko… ALPI Baio 43.2 -8.99 La Coruña
## 8 107 Jabalí cocho bravo ˈkɔt͡ʃo… ALPI Carballo 43.2 -8.71 La Coruña
## 9 108 Jabalí porco fero ˈpɔɹko… ALPI Corcubión 42.9 -9.19 La Coruña
## 10 109 Jabalí porco bravo ˈpɔɹko… ALPI Santa Co… 43.0 -8.81 La Coruña
## # ℹ 493 more rows
## # ℹ 1 more variable: CCAA <chr>En los tres casos obtienes un tabla de 503 observaciones (filas) y diez variables (columnas). Así que, elige uno de los tres _join() y ejecútalo.
Comprueba cómo efectivamente ha crecido el número de columnas (variables) de alpi. Ejecuta en la consola
Podrás comprobar que hay 10 columnas: las cuatro originales de alpi y las seis que tiene atlas.
## Rows: 503
## Columns: 10
## $ id <chr> "100", "101", "102", "103", "104", "105", "106", "107", "10…
## $ pregunta <chr> "Jabalí", "Jabalí", "Jabalí", "Jabalí", "Jabalí", "Jabalí",…
## $ ortografia <chr> "porco bravo", "porco bravo", "porco bravo", "cocho bravo",…
## $ afi <chr> "ˈpɔɾko ˈβɾaβo", "ˈpɔɾko ˈβɾaβo", "ˈpɔɾko ˈβɾaβo", "ˈkɔt͡ʃo …
## $ atlas <chr> "ALPI", "ALPI", "ALPI", "ALPI", "ALPI", "ALPI", "ALPI", "AL…
## $ poblacion <chr> "Sismundi", "Valdoviño", "Miño", "Santa María de Oleiros", …
## $ latitud <dbl> 43.70717, 43.60976, 43.34911, 43.33589, 43.21667, 43.23469,…
## $ longitud <dbl> -7.869936, -8.161575, -8.211247, -8.324253, -8.283330, -8.0…
## $ provincia <chr> "La Coruña", "La Coruña", "La Coruña", "La Coruña", "La Cor…
## $ CCAA <chr> "Galicia", "Galicia", "Galicia", "Galicia", "Galicia", "Gal…14.5.4 Cartografiar los datos
Ya tienes todos los elementos para cartografiar los datos referentes a las respuestas que los encuestados dieron para la pregunta Jabalí. Sin embargo, no son respuestas uniformes. Vas a comprobar cuántas respuestas diferentes ha habido. Para ello tan solo tienes que contar con count() para ver cuáles son los valores que hay en ortografia.
Cuando ejecutes la orden anterior, se imprimirá en la consola el comienzo de la tabla de resultados.
## # A tibble: 66 × 2
## ortografia n
## <chr> <int>
## 1 jabalín 110
## 2 jabalí 100
## 3 porco-bravo 24
## 4 porco bravo 23
## 5 <NA> 22
## 6 porc singlar 21
## 7 javardo 19
## 8 porco-montês 13
## 9 javali 11
## 10 xabaril 11
## # ℹ 56 more rowsunique(alpi$respuestas). El resultado es el mismo. Recuerda que en R las cosas se pueden hacer de más de una manera.
Hay 66 respuestas diferentes. Eso puede ser un auténtico desastre. Échale un ojo al mapa (fig. 14.13) que podría resultar.

Figura 14.13: Resultado con todos los valores de ortografia
Un auténtico batiburrillo de respuestas, aunque puedes ver una serie de agrupaciones. Aquí es donde tienes que tomar una serie de decisiones de cómo interpretar y presentar los datos y los resultados. Quizá la manera más elemental sea tener en cuenta el étimo puesto que hay varias formas que se remontan al latín PORCUS (porco, porc y puerco) y otras al arabismo ǧabalī ‘de monte’. Un tercer grupo lo pueden constituir las formas cochino, marrano, gorrino, todos sinónimos de puerco (< PORCUS). El cuarto son las formas sanglier, senglar y singlar, formas relacionadas con la forma francesa sanglier (< SINGULARIS) y, por último las formas bacó ‘cerdo’. Después tienes que todas las formas salvo jabalí suelen tener un calificativo: bravo, montés, jabalí, muntanyés, etc. Hay una extramada variabilidad.
Échale una nueva ojeada al mapa (fig. 14.14), aunque sin la leyenda, que será más claro.
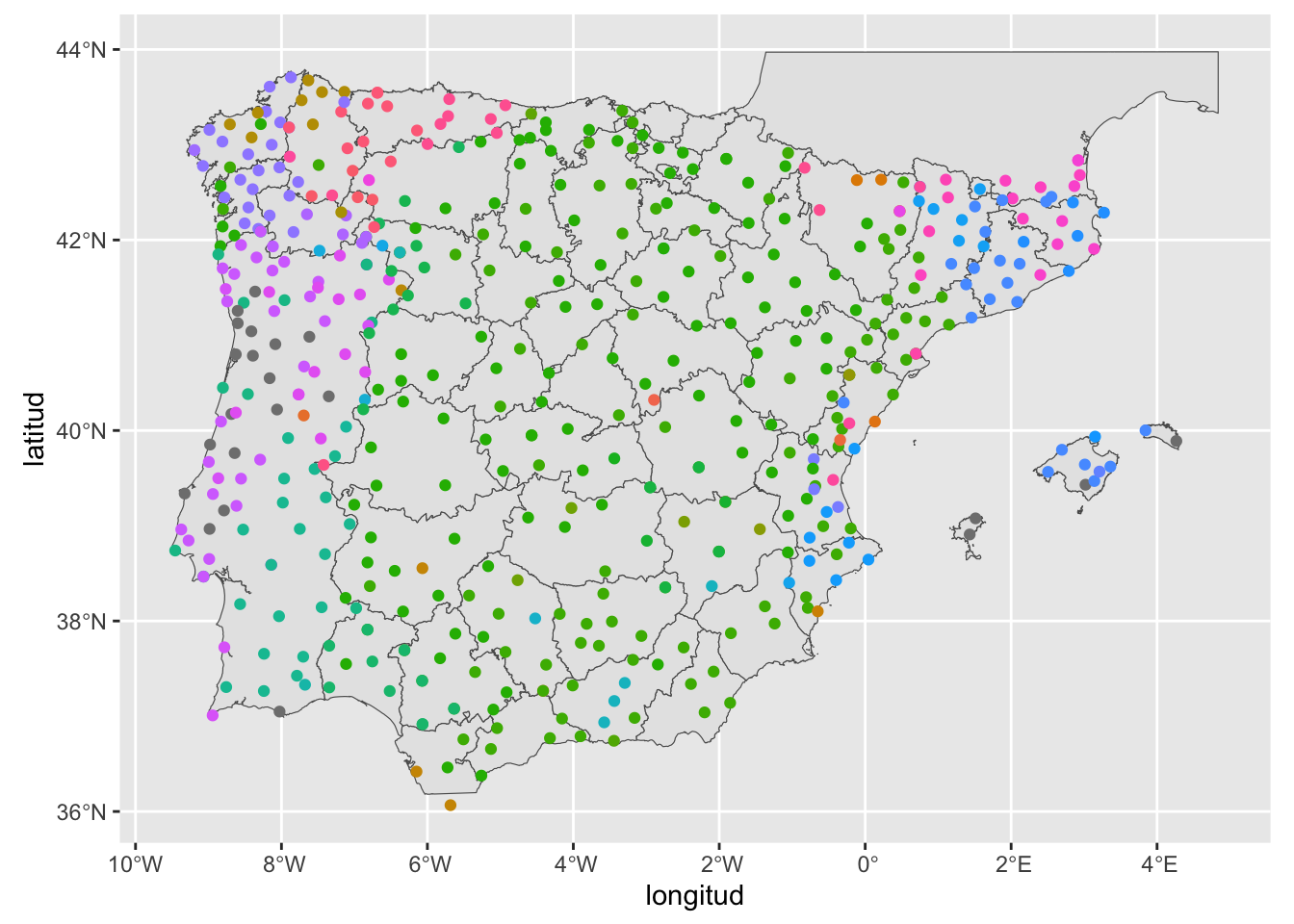
Figura 14.14: Resultados ortográficos de la denominación del Sus scrofa en la península Ibérica
Se puede ver una cierta distribución. Vas a reducirla a cinco posibilidades: derivados de PORCUS, derivados de ǧabalī, relacionados con el francés sanglier, con el catalán bacó y, en último lugar, un grupo que recoja las demás formas. Esto complica un poco el manejo de la tabla. Pero no mucho.
Lo primero es deshacerse de los puntos en los que no hubo respuesta. Son los NA. Para logarlo tienes la función drop_na(). Así que, adelante.
Ahora viene lo más complicado. Reducir la maraña de 65 variantes gráficas a cuatro formas básicas: PORCUS, ǧabalī, sanglier y el resto bajo la etiqueta otras. Para esto tienes que crear una nueva columna a la que llamarás respuesta y rellenarás las casillas con una de esas cuatro posibilidades dependiendo del valor la columna ortografia. La nueva columna se crea con una vieja conocida: mutate(). Lo complicado es reducir las 65 respuestas a tan solo cinco.
Aquí entran en juego las reglas de expresión regular con la función str_detect() y un condicional múltiple con la función case_when(). En esta instrucción ten muchísimo cuidado con los paréntesis; es muy fácil no cerrarlos bien. El código para reducirlo a esos cuatro valores es el que tienes a continuación. Córtalo y cópialo en el editor de RStudio, pero no lo ejecutes hasta haber leído la explicación.
alpi <- alpi %>%
mutate(respuesta = case_when(
str_detect(ortografia, "^p[ueo]+rc") ~ "porco",
str_detect(ortografia, "^[cxjsha]?h?a[bv]") ~ "jabalí",
str_detect(ortografia, "^s.*gl") ~ "sanglier",
TRUE ~ 'otras'
)
)14.5.4.1 Explicación del código
Como te he dicho vas a añadir una columna llamada respuesta a alpi y esto se consigue con mutate().
La función case_when() comprueba que se cumpla alguna de las condiciones que se establezcan dentro del paréntesis y que es la detección de una patrón de caracteres determinado. Lo que está haciendo es preguntando si el valor de cada una de las casillas de la columna ortografia comienza por alguno de los grupos de letras que hay en cada expresión de str_detect(). En el momento que alguna sea verdadera (TRUE) se rellena la casilla correspondiente de la variable respuesto con el valor que hay tras la tilde ~. Si no se cumple ninguna de las tres establecidas en las expresiones str_detect() entonces se rellenará con otras. El esquema gráfico de esta condicional es el de la figura 14.15).
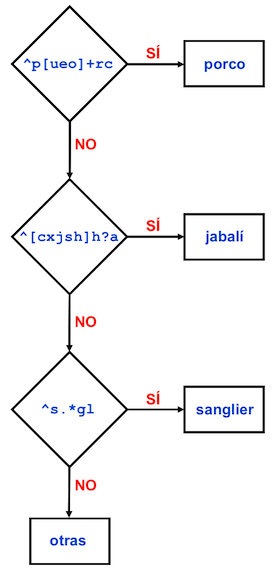
Figura 14.15: Esquema de flujo de case_when()
La función str_detect() lo que hace es mirar si en la variable ortografia, primer argumento de la función, hay alguna de las secuencias que hay entre los corchetes. Por ejemplo, en el primer caso tienes ^p[ueo]+rc. Esta expresión regular lo que le dice a str_detect() es que mire si el valor de la casilla comienza por –el ^– una p y le sigue una o más veces –el +– una u, una e o una o, por eso están encerrado entre corchetes [], y a continuación debe haber una r seguida de una c. Esta expresión será verdadera (TRUE) en todas aquellas celdas de ortografia que comiencen por porc o puerc, por lo que la casilla correspondiente de la nueva columna respuesta se rellenará con el valor porco.
En la segunda expresión de str_detect() es, sin duda, la más complicada, puesto que la gama de formas gráficas es muy grande. Lo que le pides a R es que siempre la casilla ortografia comience –^– por una c, x, j, s, h o una a, por eso está la secuencia entre corchetes [cxjsha]. Puesto que cualquiera de estas letras puede aprecer o no se le pospone a la fórmula un signo de interrogación. En algunos casos a la c le puede seguir una h –chabalín–, por eso hay una h seguida de ?. Para asegurar la expresión y que los resultados sean todos los posibles relacionados con jabalí le indicas que a continuación tiene que haber una a, pero esto te abre la posibilidad de capturar todos aquellos casos en que la respuesta ortográfica comience por sa y eso incluiría sanglier, por lo que tienes que poner una restricción: la consonante que sigue a esa sílaba inicial y, en este caso solo hay dos letras posibles b y v con lo que añades la disyuntiva [bv]. Con esta complicada expresión regular puedes reducir las 21 formas ortográficas para los derivados de ǧabalī a tan solo una, que es el valor que se guardará en las casillas correspondientes de la nueva columna respuesta. Estas son las 21 formas ortográficas que hay en esta cuestion:
## [1] "jabalín" "jabalí" "xabaril" "xabalí" "xabarín" "xabalín"
## [7] "javali" "javaril" "javardo" "javato" "habalín" "sabarín"
## [13] "jabarín" "jabaril" "xabarí" "jabalises" "jabalís" "jabato"
## [19] "abalí" "jabali" "chabalín"No creo que sea necesario que me demore en explicar la dos últimas reglas –^s.*gl– porque son meridianamente clara. Extraerá estas formas:
## [1] "singlar" "sanglier" "senglar"Ejecuta el código y échale una ojeada a la tabla resultante ejecutando en la consola
Podrás ver que la última línea corresponde a la nueva columna respuesta.
## Rows: 481
## Columns: 11
## $ id <chr> "100", "101", "102", "103", "104", "105", "106", "107", "10…
## $ pregunta <chr> "Jabalí", "Jabalí", "Jabalí", "Jabalí", "Jabalí", "Jabalí",…
## $ ortografia <chr> "porco bravo", "porco bravo", "porco bravo", "cocho bravo",…
## $ afi <chr> "ˈpɔɾko ˈβɾaβo", "ˈpɔɾko ˈβɾaβo", "ˈpɔɾko ˈβɾaβo", "ˈkɔt͡ʃo …
## $ atlas <chr> "ALPI", "ALPI", "ALPI", "ALPI", "ALPI", "ALPI", "ALPI", "AL…
## $ poblacion <chr> "Sismundi", "Valdoviño", "Miño", "Santa María de Oleiros", …
## $ latitud <dbl> 43.70717, 43.60976, 43.34911, 43.33589, 43.21667, 43.23469,…
## $ longitud <dbl> -7.869936, -8.161575, -8.211247, -8.324253, -8.283330, -8.0…
## $ provincia <chr> "La Coruña", "La Coruña", "La Coruña", "La Coruña", "La Cor…
## $ CCAA <chr> "Galicia", "Galicia", "Galicia", "Galicia", "Galicia", "Gal…
## $ respuesta <chr> "porco", "porco", "porco", "otras", "jabalí", "porco", "por…Comprueba ahora cuantos valores diferentes hay en la variable respuesta. Puedes hacerlo con
o con
En cualquier caso serán cuatro posibilidades, las que determinaste para cada búsqueda con case_when(). La única diferencia es la cantidad de información que da una y otra respuesta. Quizá la más interesante sea la primera, puesto que te informa de en cuantos puntos se dio cada una de esas respuestas.
## # A tibble: 4 × 2
## respuesta n
## <chr> <int>
## 1 jabalí 308
## 2 porco 120
## 3 otras 40
## 4 sanglier 13Es evidente que en el ámbito iberorrománico los hablantes, en los años 1930, preferían los derivados de ǧabalī y en segundo lugar los de PORCUS. Ya es hora de verlo reflejado en el mapa (fig. 33) y extraer las conclusiones pertinentes.
El código es el mismo que usaste antes, solo que ahora tienes que cambiar de qué columna debe extraer los valores para asignar los colores (color =).
ggplot() +
geom_sf(data = esp_prov, fill = "white", color = "black") + # España
geom_sf(data = fra, fill = "white", color = "black") + # Francia
geom_sf(data = prt, fill = "white", color = "black") + # Portugal
geom_sf(data = and, fill = "white", color = "black") + # Andorra
coord_sf(xlim = c(-10, 5), ylim = c(36, 44), expand = FALSE) +
geom_point(data = alpi,
aes(x = longitud,
y = latitud,
color = ortografia))En el primer intento fue ortografia, ahora es la nueva variable respuesta, así que el código será
ggplot() +
geom_sf(data = esp_prov, fill = "white", color = "black") + # España
geom_sf(data = fra, fill = "white", color = "black") + # Francia
geom_sf(data = prt, fill = "white", color = "black") + # Portugal
geom_sf(data = and, fill = "white", color = "black") + # Andorra
coord_sf(xlim = c(-10, 5), ylim = c(36, 44), expand = FALSE) +
geom_point(data = alpi,
aes(x = longitud,
y = latitud,
color = respuesta))Lo que dibujará este hermoso mapa de la figura 14.16.
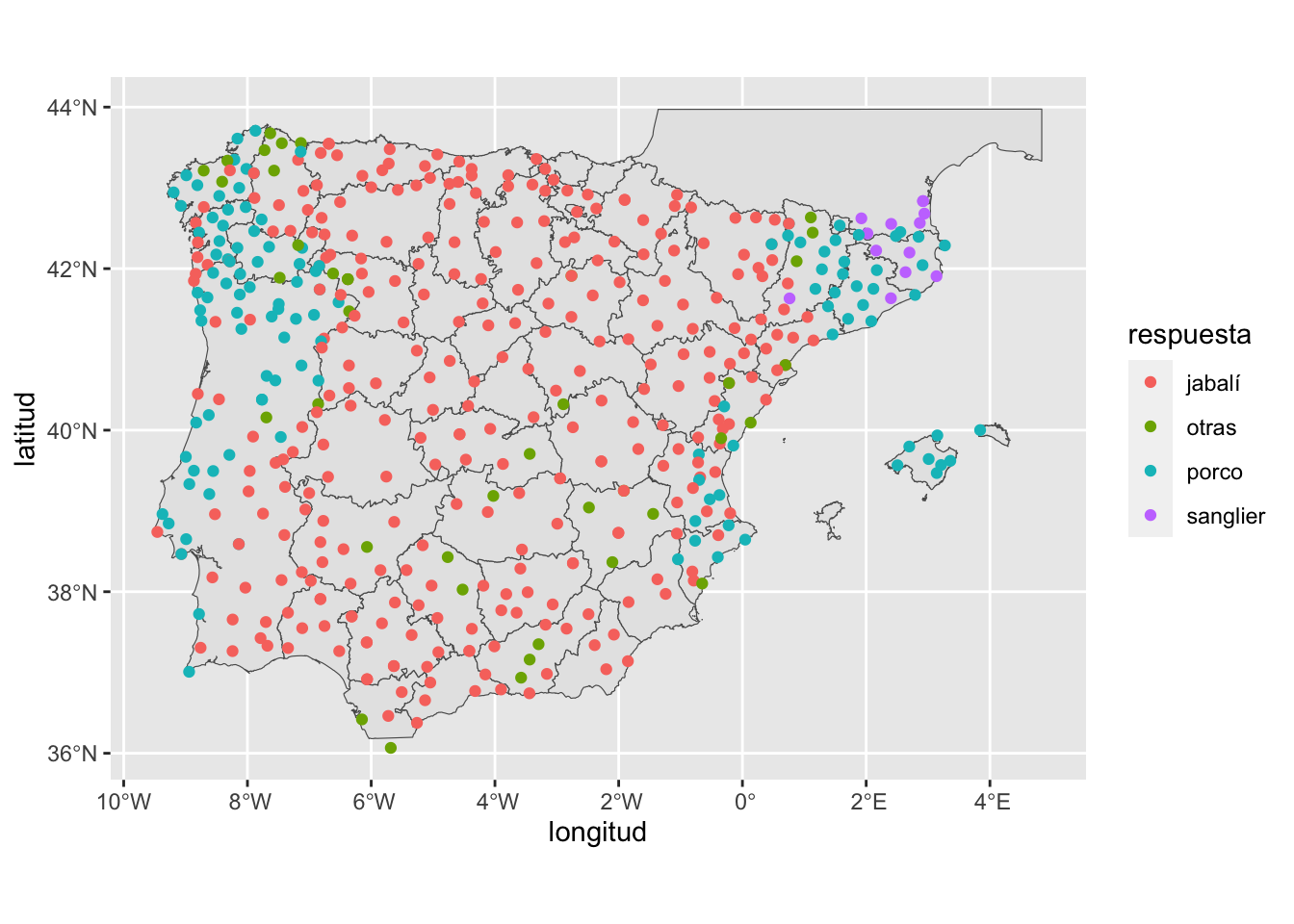
Figura 14.16: Resultados reducidos de las respuestas del ALPI a la pregunta «Jabalí»
Es evidente que en la zona central de la iberorromania predominan los derivados de ǧabalī y que en las zonas laterales (gallego-portugués y catalán) los de PORCUS, aunque hay una fuerte penetración de ǧabalī en el gallego y del Tajo hacia el sur en el portugués y, además, ha divido el territorio catalán en dos puesto que la forma mayoritaria en Tarragona son derivados de ǧabalī, mientras que en Lérida, Barcelona y Gerona predominan los de PORCUS, aunque con varios puntos de la forma francesa sanglier, que es la que predomina en el Rosellón.
Lo puedes observar mejor en el mapa de la figura 15.17, en el que los huecos entre los puntos se han rellenado y forman unas áreas más claras y que efectivamente, los derivados de ǧabalī son los que predominan en el ámbito Ibeororrománico y le han ido comiendo el terreno a los de PORCUS en las área laterales y que hay islotes en los que hay formas cuyo primer elemento no contiene las formas dominantes (marrano, cochino, guarro, tocino, etc. que puede estar seguido o no de un adjetivo tipo bravo, javalí, sauvatge, montanyès, etc.)
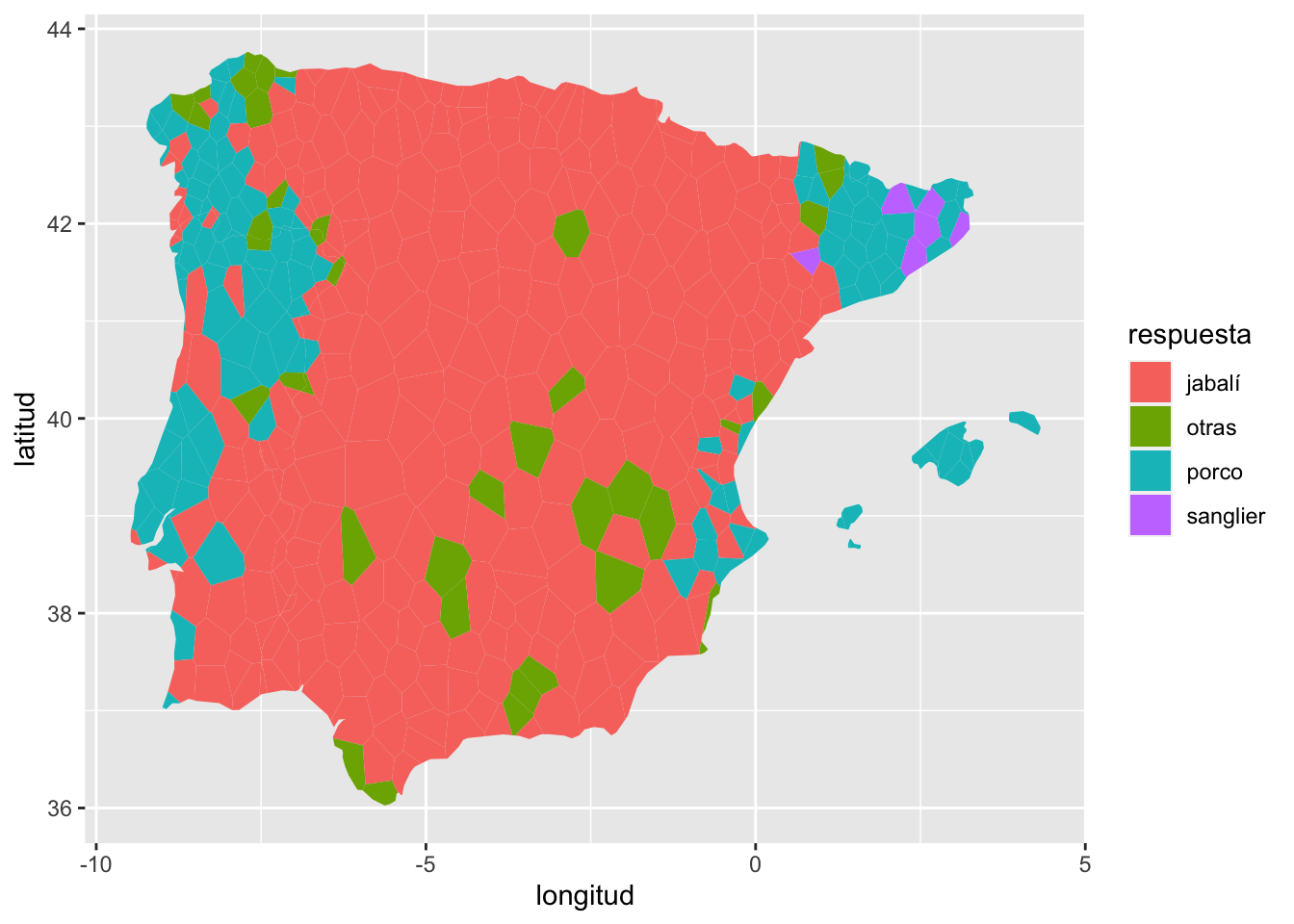
Figura 14.17: Áreas de distribución de los derivados ortográficos para las designaciones del Sus scrofa
14.6 Diagramas de Voronoi con un atlas de pequeño dominio
El mapa con el que se cierra la sección anterior (fig. 14.17) está trazado con los llamados polígonos de Voronoi o Thiessen que es una manera elegante y matemáticamente adecuada para determinar el difusión de un fenómeno dialectal y representarlo en un mapa. De nuevo, las matemáticas que permiten el trazado de los polígonos de Voronoi son de infarto. Sin embargo, los programadores han creado una librería que permite el dibujarlos con cierta sencillez en R. Se trata de la librería {deldir}. Ya sabes cómo.
No vas a trazar el mapa anterior (fig. 14.17) puesto que los datos encierran un pequeño problema que los diagramas de Voronoi no pueden resolver: las respuestas múltiples de los encuestados. Para esta explicación vas a establecer las áreas de seseo, ceceo y distinguidoras en Andalucía a partir de los datos del Atlas Lingüístico de Andalucía. Este atlas tiene un mapa, el 1705, que se titula «áreas de mantenimiento o neutralización de la oposición /s/ : /θ/». Este es en realidad un mapa resumen, pues no da datos brutos sino resumidos por medio de símbolos, uno para cada una de las cuatro posibilidades que los investigadores establecieron: distinción, seseo, ceceo y polimorfismo (hay otra mucha información que no interesa para el objetivo de esta sección).
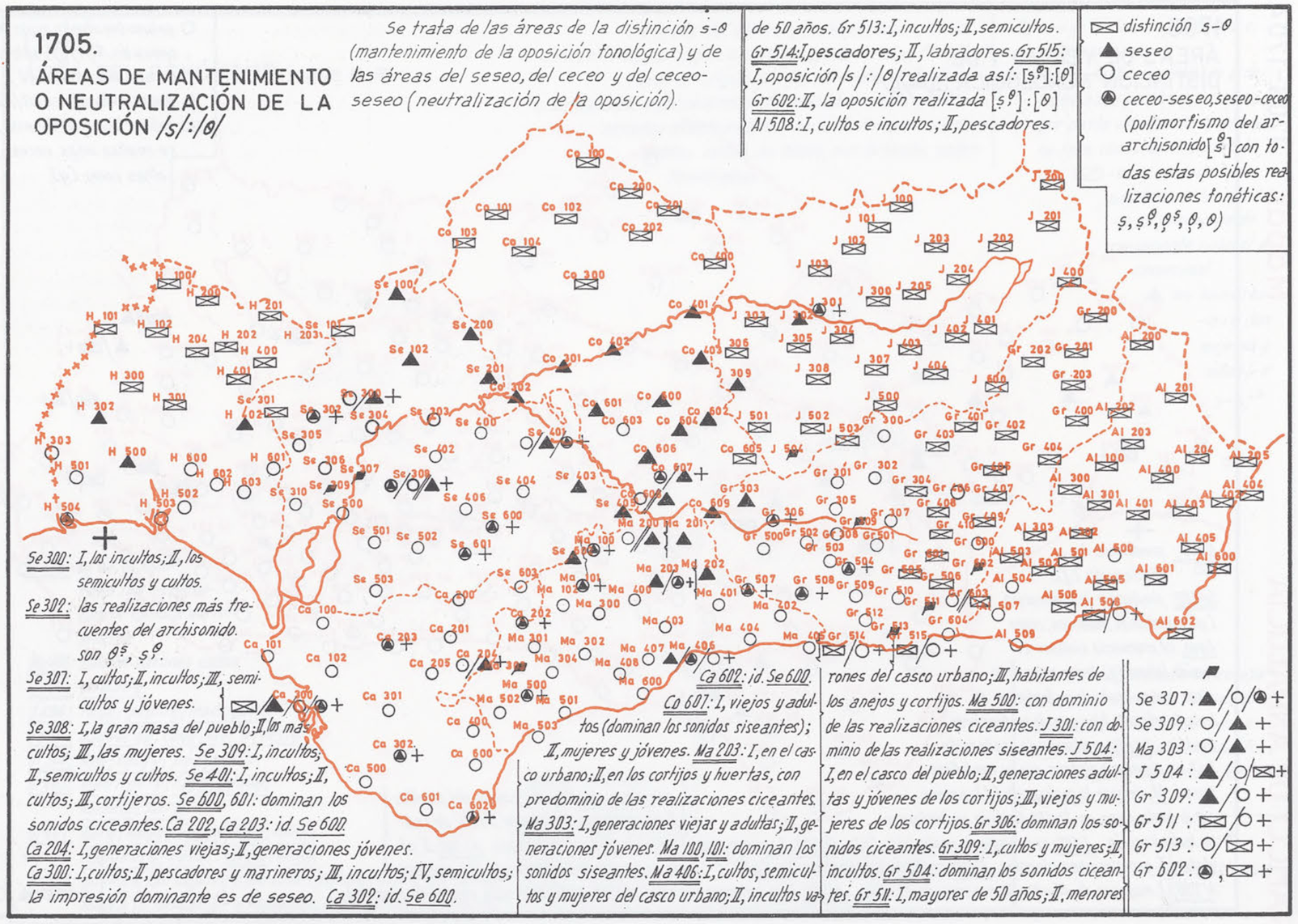
Figura 14.18: Mapa 1075 del ALEA
A partir de ese mapa 1705 se ha creado una tabla con dos columnas: id, que corresponde al código identificativo de cada punto de encuesta, y resultado, en la que aparece una de las cuatro posibles respuestas que he mencionado. Este es el aspecto de la tabla.
| id | resultado |
|---|---|
| AL100 | distinción |
| AL200 | distinción |
| AL201 | distinción |
| AL202 | distinción |
| AL203 | distinción |
| AL204 | distinción |
| AL205 | distinción |
| AL300 | distinción |
| AL301 | distinción |
| AL302 | distinción |
Vas a aprender a dibujar el mapa de Andalucía y representar en él con los polígonos de Voronoi las áreas que distinguen, sesean, cecean y en las que hay polimorfismo.
14.6.1 Al teclado
Carga las librerías que vas a necesitar. Son estas tres.
Ten en cuenta que las tres librerías imprimirán mensajes de carga. No los reproduzco para no alargarme.
Lo siguiente es cargar los datos. La tabla seseo-alea es una fichero separado por tabuladores que se encuentra en el repositorio del proyecto 7PartidasDigital que vas a guardar en el objeto alea. Esta es la url https://raw.githubusercontent.com/7PartidasDigital/AnaText/master/datos/geolinguistic/seseo-alea.txt y la orden para leerlo es
alea <- read_tsv("https://raw.githubusercontent.com/7PartidasDigital/AnaText/master/datos/geolinguistic/seseo-alea.txt")Al cargarlo se impimirá el consabido mensaje en el que te informa del nombre de las variables y del tipo de datos que contiene cada una de ellas.
## Rows: 228 Columns: 2
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: "\t"
## chr (2): id, resultado
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Ahora tienes que añadirle la información geográfica de cada punto. Es decir, las coordenadas geográficas para cada uno de los puntos de encuesta. Ya lo has usado al tratar con el ALPI, aunque la manera de cargarla la tienes más atrás, te lo recuerdo. Primero lees la tabla con la información geográfica de los atlas lingüísticos.
atlas <- read_tsv("https://raw.githubusercontent.com/7PartidasDigital/AnaText/master/datos/geolinguistic/ATLAS_LINGUISTICOS.txt")Al cargarse se imprimirá el aviso con los nombres de las variables y el el tipo de contenido.
## Rows: 1558 Columns: 7
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: "\t"
## chr (5): atlas, id, poblacion, provincia, CCAA
## dbl (2): latitud, longitud
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Ahora tienes que extraer de atlas las coordenadas y adjuntarlas a la tabla de los datos, a alea. La tabla atlas tiene las coordenadas de varios atlas lingüísticos, como puedes comprobar en esta tabla.
| atlas | n |
|---|---|
| ALPI | 524 |
| ALEA | 228 |
| ALCYL | 208 |
| PALDC | 189 |
| ALEARN | 177 |
| ALCLM | 162 |
| ALECan | 47 |
| ADIM | 16 |
| ALECAn | 7 |
Como lo que te interesa es la información referente al ALEA, solo tienes que borrar la información que no se refiera al ALEA con filter().
Lo que reducirá el tamaño de atlas de las más de 1500 líneas que tiene a tan solo 228, que es el número de puntos de encuesta del ALEA.
Ahora tienes que unir ambas tablas con left_join() de manera que la tabla alea importe las coordenadas (latitud y longitud) que hay en atlas.
Puedes examinar el contenido de la tabla con
lo que te mostrará las diez primeras línea de la tabla y podrás comprobar que se han incorporado las columnas atlas, poblacion, latitud, longitud, provincia y CCAA.
## # A tibble: 228 × 8
## id resultado atlas poblacion latitud longitud provincia CCAA
## <chr> <chr> <chr> <chr> <dbl> <dbl> <chr> <chr>
## 1 AL100 distinción ALEA Lúcar 37.4 -2.42 Almería Andalucía
## 2 AL200 distinción ALEA Topares 37.9 -2.23 Almería Andalucía
## 3 AL201 distinción ALEA Vélez-Rubio 37.6 -2.07 Almería Andalucía
## 4 AL202 distinción ALEA El Contador 37.6 -2.36 Almería Andalucía
## 5 AL203 distinción ALEA Oria 37.5 -2.30 Almería Andalucía
## 6 AL204 distinción ALEA La Perulera 37.4 -2.16 Almería Andalucía
## 7 AL205 distinción ALEA Pulpí 37.4 -1.75 Almería Andalucía
## 8 AL300 distinción ALEA Alcóntar 37.3 -2.60 Almería Andalucía
## 9 AL301 distinción ALEA Bacares 37.3 -2.45 Almería Andalucía
## 10 AL302 distinción ALEA Gérgal 37.1 -2.54 Almería Andalucía
## # ℹ 218 more rowsSolo necesitas las columnas id, resultado, latitud y longitud. Si quieres puedes quedarte con esas cuatro solo. Podrías hacerlo con:
Ya tienes toda la información necesaria para representar los datos sobre un mapa. Tan solo te falta el mapa.
Como estás operando únicamente con el territorio de la comunidad de Andalucía, entonces te interesan descargar los datos para. Recordarás que te dije que en el sistema GISCO hay cuatro niveles de granularidad para los mapas:
| Nivel | Nombre | Descripción | Ejemplo en España |
|---|---|---|---|
| NUTS 0 | País | Estado miembro | España |
| NUTS 1 | Grandes regiones socioeconómicas | Agrupaciones de comunidades autónomas | Noroeste (Galicia, Asturias, Cantabria) |
| NUTS 2 | Regiones básicas | Comunidades y ciudades autónomas | Galicia, Madrid, Cataluña, Ceuta, Melilla |
| NUTS 3 | Pequeñas regiones | Provincias, islas principales y ciudades autónomas | A Coruña, Madrid, Gipuzkoa, Tenerife |
Tan solo te interesa la comunidad autónoma de Andalucía y, además, no te hacen falta los límites de las provincias, por lo que necesitas obtener los datos del nivel 2, comunidades autónomas.
A continuación hay que extaer los datos de Andalucía, pero como cabe la posibilidad de que el nombre esté a la inglesa (Adalusia), hay que contemplar este caso. Puedes comprobarlo con:
## [1] "Cataluña" "Comunitat Valenciana"
## [3] "Galicia" "Principado de Asturias"
## [5] "Cantabria" "País Vasco"
## [7] "Comunidad Foral de Navarra" "La Rioja"
## [9] "Aragón" "Comunidad de Madrid"
## [11] "Castilla y León" "Castilla-La Mancha"
## [13] "Extremadura" "Illes Balears"
## [15] "Andalucía" "Región de Murcia"
## [17] "Ciudad de Ceuta" "Ciudad de Melilla"
## [19] "Canarias"No lo parece, pero como esa información está fuera de nuestro control y siempre cabe la posibilidad de que alguien lo cambie, hay que usar la siguiente expresión para obtener únicamente los datos de Andalucía:
Lo que has hecho ha sido extraer un subconjunto (subset) de nuts2 en el que la columna NAME_LATN puede contener la palabra Andalucía o Andalusia, aunque acabamos de comprobar que no es el caso.
Ya tienes todo lo necesario para representar sobre el mapa los datos como el que hay en la figura 14.19.
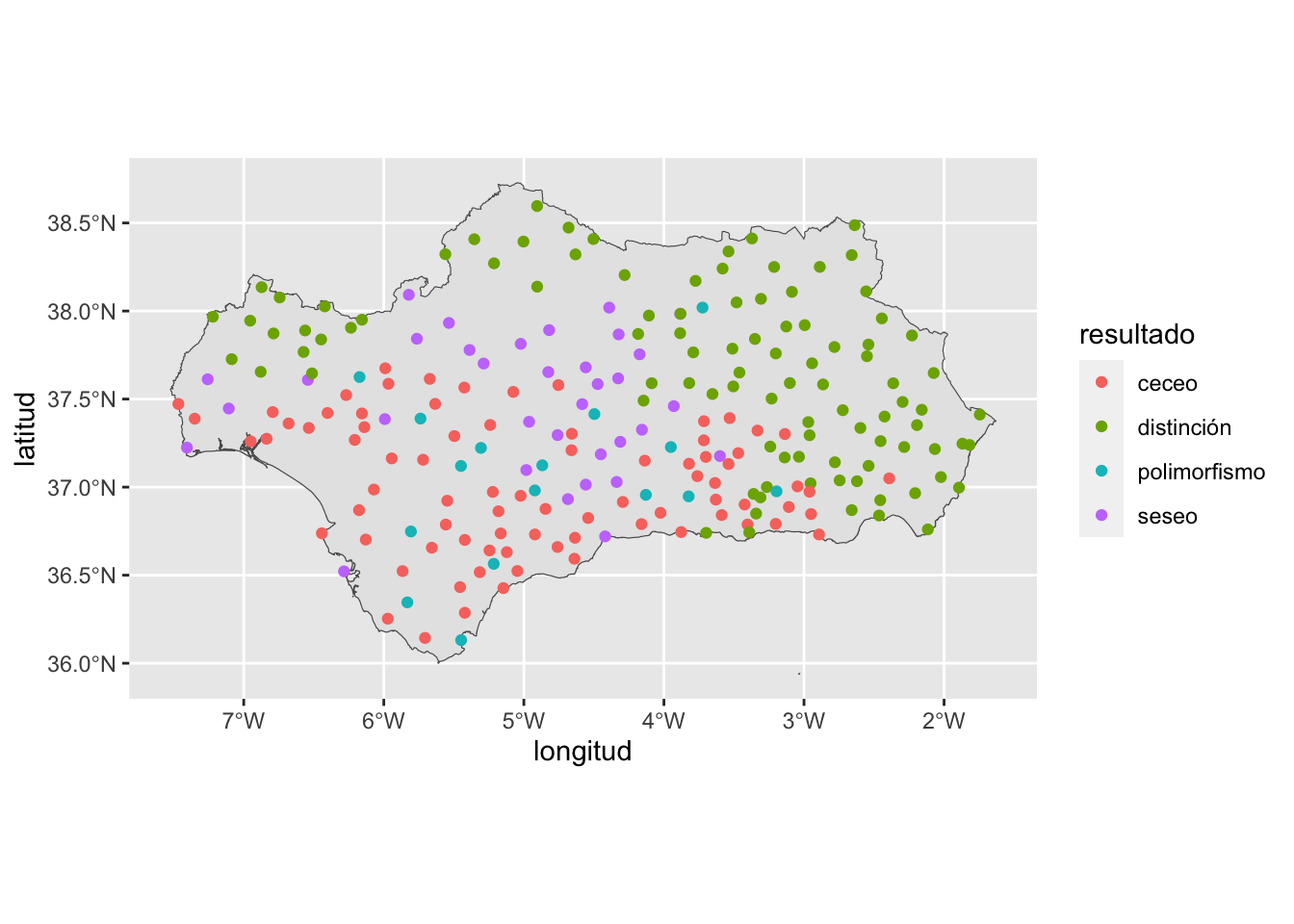
Figura 14.19: Puntos distinguidores, seseantes, ceceantes y polimórficos en el ALEA
Puedes ver algunos los patrones areales, pero no son claros porque es una ensalada de puntos. Aquí es donde entran los polígonos Voronoi. La instrucción para dibujar el mapa de la figura 14.19 era
ggplot() +
geom_sf(data = andalucia) +
geom_point(data = alea,
aes(x = longitud,
y = latitud,
color = resultado))en el que le estás diciendo que dibuje un mapa con los datos de andalucia (geom_sf) y que dibuje con geom_point() los puntos de alea con las coordenadas longitud y latitud y que los coloree según la variable resultado.
Para dibujarlo con los polígonos Voronoi lo primero es calcularlos polígonos Voronoi a partir de las coordenadas de los puntos que tienes en alea:
Esta orden te devolverá un objeto con los polígonos Voronoi que se han calculado a partir de las coordenadas de los puntos de alea. A continuación hay que extraer los polígonos de Voronoi:
y ahora ha que convertirlo en polígonos sf que son los que entiende ggplot, y lo consigues con:
vor_polys <- lapply(seq_along(tiles), function(i) {
tile <- tiles[[i]]
# Crear matriz de coordenadas cerrada del polígono
coords <- cbind(tile$x, tile$y)
coords <- rbind(coords, coords[1,])
# Crear objeto POLYGON y luego sf
poly <- st_polygon(list(coords))
# Crear sf con datos del punto correspondiente
sf_poly <- st_sf(
resultado = alea$resultado[i],
geometry = st_sfc(poly),
crs = st_crs(andalucia) # Mantener CRS igual
)
sf_poly
})
voronoi_sf <- do.call(rbind, vor_polys)pero esto haría que los polígonos Voronoi no tuvieran el mismo sistema de referencia espacial que el mapa de Andalucía. Por lo que hay que transformar los polígonos Voronoi al mismo sistema de referencia espacial que el mapa de Andalucía:
Ahora ya puedes dibujar el mapa con los polígonos Voronoi. La orden es la siguiente:
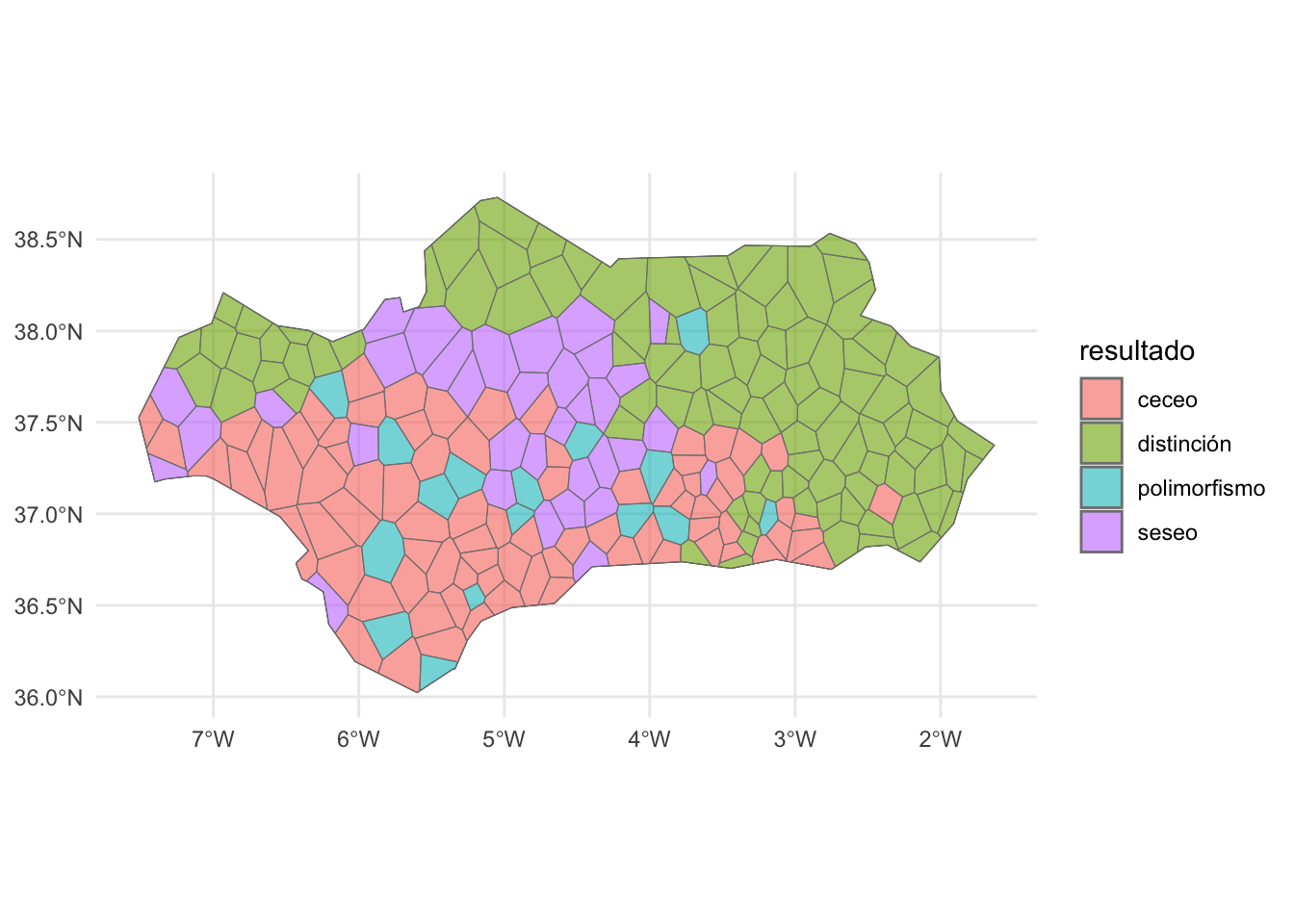
Figura 14.20: Áreas de distribución de los hablantes distinguidores, seseantes, ceceantes y polimórficos
Parece que la forma mayoritaria en la Andalucía de los años sesenta, cuando Alvar hizo las encuestas, es la neutralización de la oposición /s/:/θ/ frente a la distinción. Puedes simplificar aún más el mapa y ver tan solo dos zonas (y posibles islotes): neutralización y distinción. El mapa resultante sería el de la figura 14.21.
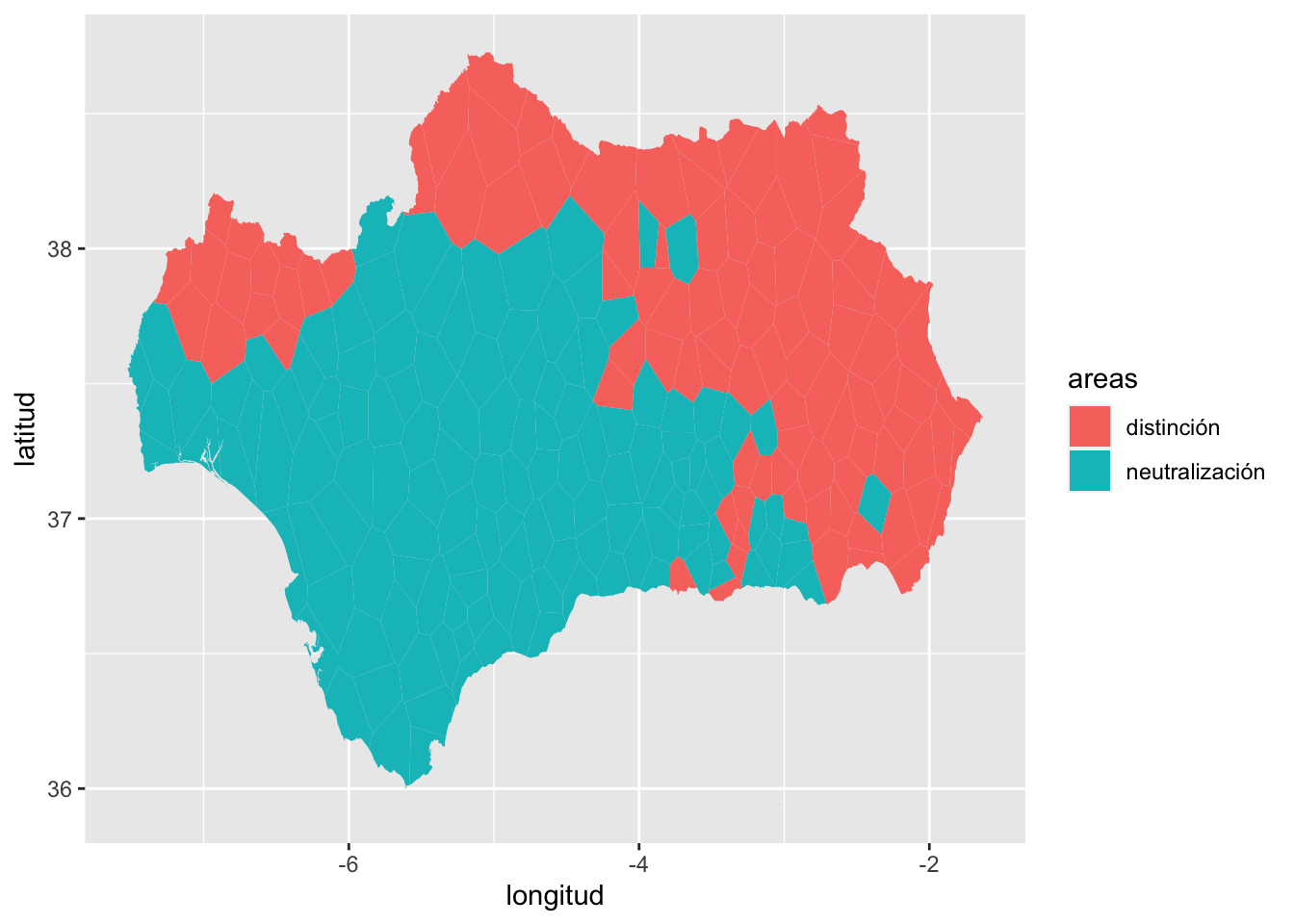
Figura 14.21: Zonas distinguidoras y neutralizadoras de la oposición /s/:/θ/
Es muchísimo más claro que el anterior. Para conseguirlo solo he tenido que crear una nueva variable en alea para reducir las cuatro posibilidades a dos: neutralización, que recoge poliformismo, seseo y ceceo y distinción.
case_when() que es para cuando las posibilidades son más de dos. Tómate como el reto final de este capítulo el averiguar cuál es la función que haría el trabajo. Ya la has visto en un capítulo anterior.
