A Nubes de palabras
El capítulo Topic Modeling comenzaba con la nubes de palabras del legajo que habías encontrado en un remoto archivo (A.1), pero no te expliqué cómo las puedes construir en R. Ese es el objetivo de este apéndice, crear nubes de palabras.
![Nubes de palabras del _legajo_ del capítulo Topic Modeling]](imagenes/09-nube-filosofos.png)
Figura A.1: Nubes de palabras del legajo del capítulo Topic Modeling]
Para crear nubes de palabras necesitas la librería wordcloud y una dependencia de la misma que se llama RColorBrewer que se ocupa de los colores. Así que instálalas.
A continuación invoca {wordcloud} junto con {tidyverse} y {tidytext}. No tienes que preocuparte de {RColorBrewer} ya que la cargará automáticamente {wordcloud}.
## Loading required package: RColorBrewerPuesto que las palabras que te interesará recoger en la mubes son las palabras semánticas y no las palabras gramaticales, el siguiente paso es cargar la lista de palabras vacías.
vacias <- read_csv("https://raw.githubusercontent.com/7PartidasDigital/AnaText/master/datos/diccionarios/vacias.txt",
locale = default_locale())Ahora debes cargar un fichero de texto. En el capítulo Análisis de sentimientos aplicado a la literatura te facilité la dirección de los diez primeros episodios nacionales de Pérez Galdos y tres novelas de autores contemporáneos:
- Los jinetes del Apocalipsis de Vicente Blasco Ibáñez (
cuatro_jinetes_apocalipsis.txt) - Los pazos de Ulla de Emilia Pardo Bazán (
pazos_ulloa.txt) - La Regenta de Leopoldo Alas Clarín (
LaRegenta.txt).
Tan solo te falta la ruta, que también la tienes en ese capítulo, pero te la recuerdo.
Así que lee una de las novelas.
texto_entrada <- read_lines(paste(ruta, "cuatro_jinetes_apocalipsis.txt", sep = ""),
locale = default_locale())El siguiente paso es dividirlo en palabras-token y borrar las palabras vacías. Pero antes debes convertir el vector texto_entrada en una tibble. Pero para hacer la cosa más fácil, indícale que la columna en la que va a guardar el texto se llamará texto.
Ahora ya puedes dividirlo en palabras-token, limpiarlo, averiguar cuáles son las palabras-tipo y su frecuencia y, por último dibujar la nube. El código que hay a continuación dibujará la nube de palabras de la figura A.2.
texto_analisis %>%
unnest_tokens(palabra, texto) %>%
anti_join(vacias) %>%
count(palabra, sort = T) %>%
with(wordcloud(palabra,
n,
max.words = 100,
color = brewer.pal(8, "Dark2")))
Figura A.2: Nube de la palabras de Los cuatro jinetes del Apocalipsis
Creo que tienes claro lo que hacen las cuatro primeras líneas, lo has visto una y otra vez. Lo nuevo está en la línea que comienza con with. Esta función sirve para invocar otra función con todos los argumentos que esta requiere. La función que invocas es wordcloud y sus argumentos son las palabras que ha de usar, que las tienes en la variable palabra, la frecuencia de cada palabra que tienes en n, el máximo de palabras que quieres que se impriman y los colores. También podrías indicarle la frecuencia mínima que han de tener las palabras para aparecer en la nube. Lo indicarías con el argmuento min.freq= n donde n es el número mínimo de la frecuencias que debe tener en cuenta.
Esta última es la más complicada. La función brewer.pal es la responsable de seleccionar los colores. Requiere dos argumentos, el número de colores que ha de utilizar. El mínimo son 3, el máximo depende de la paleta de colores. Puedes verlas en la figura A.3, y de ahí puedes seleccionar el literal del segundo argumento, que es el nombre la paleta.
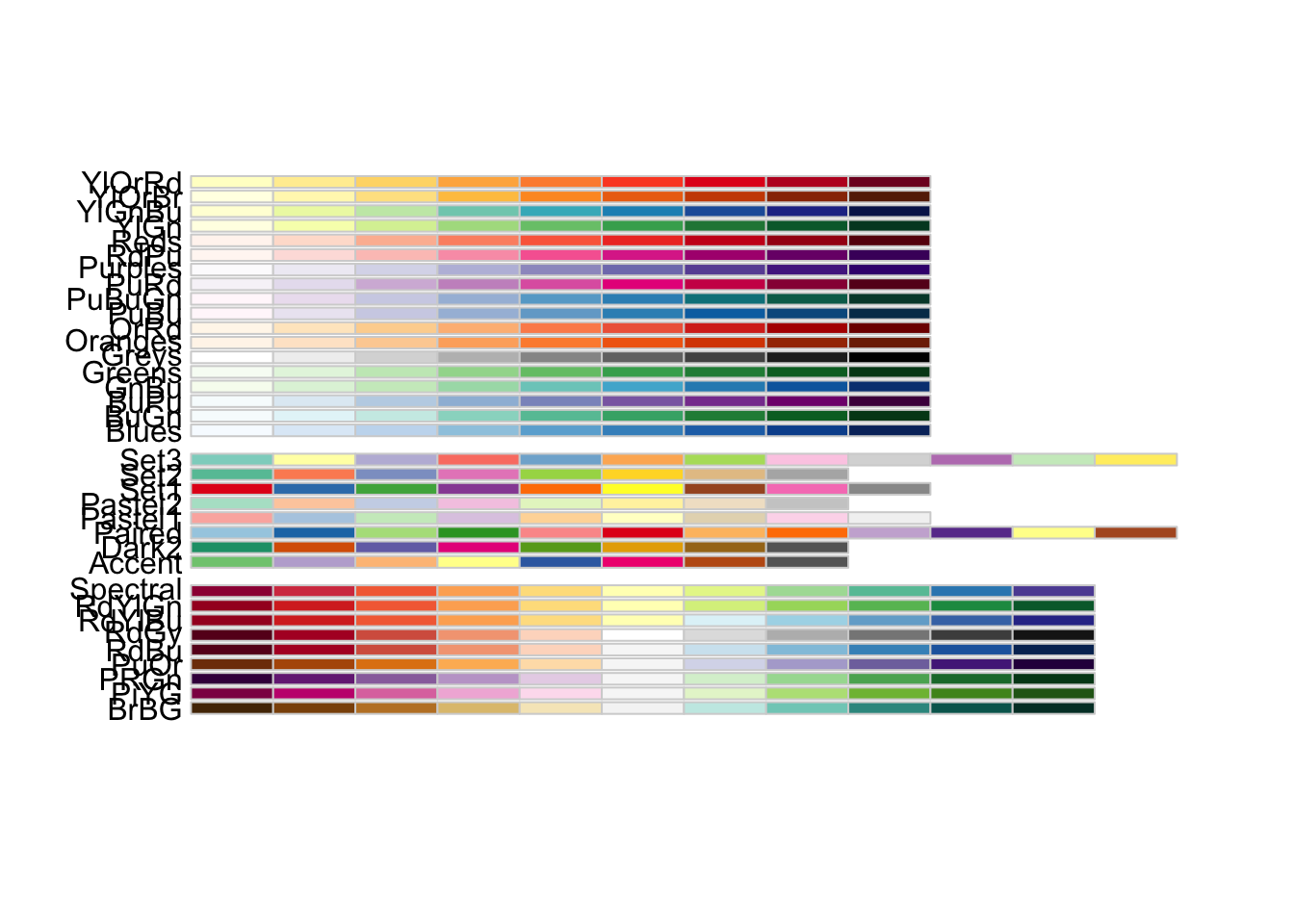
Figura A.3: Paleta de colores de RColorBrewer
