17 Lingüística de corpus II
Extracción de datos del analizador de OSTA
17.1 Introducción
En el capítulo anterior has visto cómo extraer datos desde la página web de OSTA y visulizarlos. En esta ocasión lo que harás será extraer los datos de la página html que ofrece el analizador de OSTA.
El analizador de OSTA, que es una programa desarrollado por Francisco Gago Jover y Javier Pueyo Mena, permite cargar un archivo de texto etiquetado de acuerdo con las normas del HSMS (Hispanic Seminary of Medieval Studies) y analizarlo morfológicamente y asignar el lema correspondiente a cada forma. El resultado es un archivo HTML llamado TEXT.SIGLA.vrt.html (donde SIGLA es el código que cada texto tiene en el HSMS, pero nada obsta a que lo llames como creas pertinente. La ilustración que hay a continuación muestra un ejemplo de este archivo.
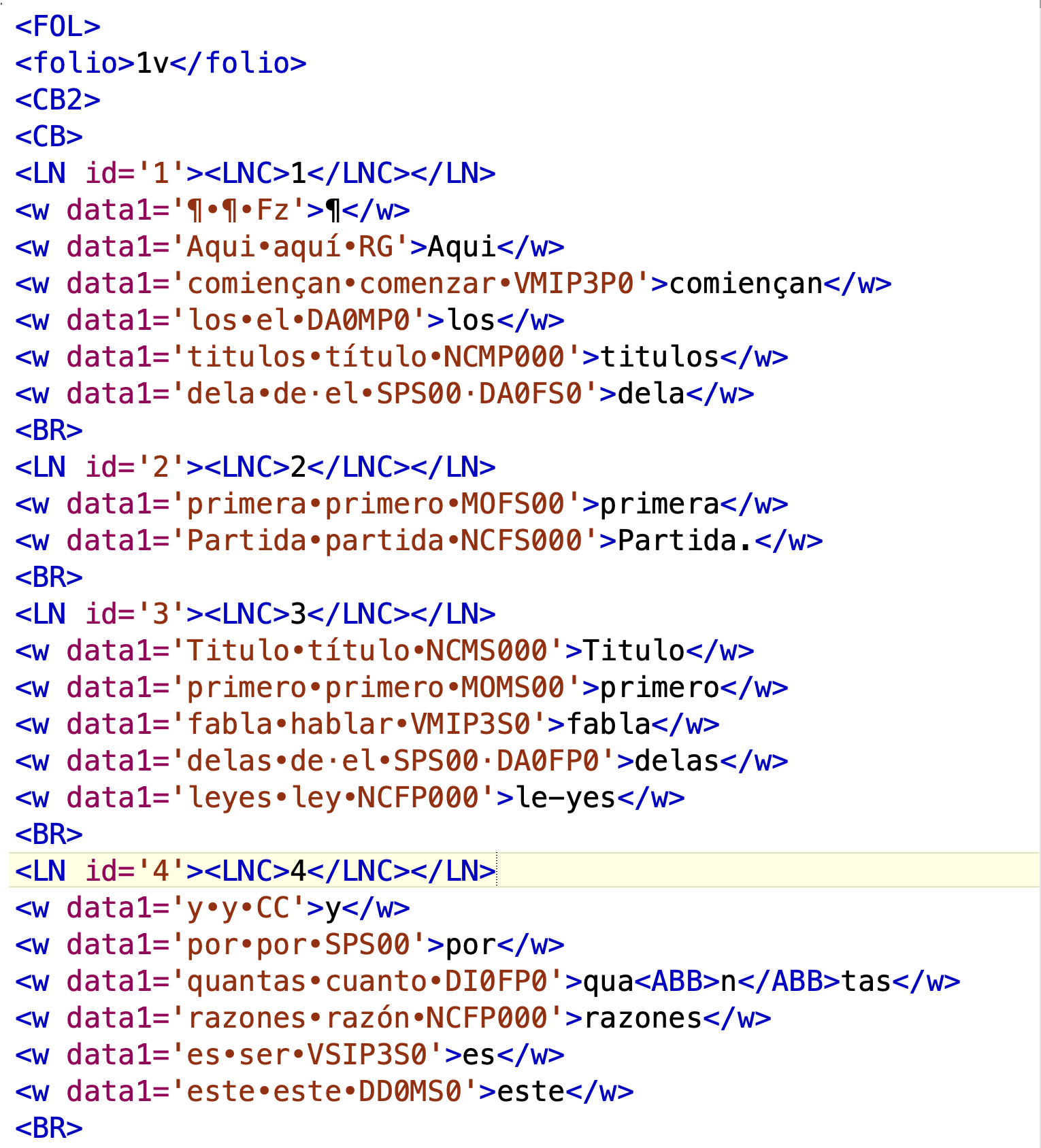
Figura 17.1: Vista del interior de un fichero .vrt.html de OSTA
Este fichero está diseñado para visualizarse en un navegador web (Puedes verlo si pulsas este enlace), pero también se puede analizar con R. Para ello, es necesario extraer los datos y convertirlos a un formato que R pueda manejar.
17.2 Extracción de datos de la página TEXT.SPO.vrt.html
Para extraer los datos de la página HTML, hay que utilizar el paquete rvest de R, que permite leer y manipular documentos HTML. Como lo más seguro es que no lo tengas instalado, lo primero que harás es instalarlo. Para ello, ejecuta el siguiente código en la consola de RStudio:
Recuerda que solo has de instalarla una vez.
Lo siguiente es cargar las dos librerías que vas a necesitar: rvest y tidyverse. La primera leerá el fichero HTML y la segunda, como ya sabes, te ayudará a manipular los datos para obtener al final una visualización interesante.
El fichero que vas a analizar es un poquillo pesado, tiene 39.4 MB, así que lo leerás directamente desde la red (tardará un poquito, aunque depende de la conexión a internet).
html_text <- read_file("https://raw.githubusercontent.com/7PartidasDigital/AnaText/refs/heads/master/datos/osta/TEXT.SPO.vrt.html")Ahora hay que extraer los datos de la página HTML, solo te interesa lo que hay dentro de las etiquetas que tienen este aspecto <w data1='comiençan•comenzar•VMIP3P0'>comiençan</w>. Para ello, se utiliza la función html_nodes() que selecciona los nodos que contienen los datos que interesan. En este caso, los nodos que contienen la forma limpia de marcas de abreviaturas, añadidos, borrados y otros detalles paleográficos, el lema y la etiqueta morfológica. Con lo que te has de quedar con todo lo que hay dentro de las comillas simples que están a continuación de data1=, en el ejemplo comiençan•comenzar•VMIP3P0. Es un proceso que requiere varios pasos.
Lo primero es analizar el texto HTML para que localice los nodos que contienen los datos que interesan.
R ya sabe cuál es la estructura del fichero HTML. Lo sabrás porque en la ventana **Environment*** habrá aparecido unhtml_docy te aclara que es unaList of 2(por ahora dejamos de explicar esto, nos sacaría de lo importante y nos perderíamos en explicaciones técnicas complejas. <a href="https://youtu.be/8ndmtEIUH0s" target="_blank">Aquí puedes acceder a un vídeo en el que te lo explican</a>). Ahora tienes que decirle qué nodo (etiqueta del HTML) te interesa. Como he dicho, son los que tienen la etiquetaw. Para extraerlas usarás la funciónhtml_nodes()y lo guardarás enw_tags`.
Ahora ya tienes los nodos que interesan guardados en w_tags, pero aún no tienes los datos que quieres analizar. Para obtenerlos, utilizarás la función html_attr(). Corta y pega el código siguiente en el editor de RStudio. No lo ejecutes hasta leer la explicación que hay a continuación.
datos <- w_tags %>%
html_attr("data1") %>%
tibble(data1 = .) %>%
separate(data1,
into = c("forma", "lema", "pos"),
sep = "•",
remove = TRUE,
fill = "right",
extra = "merge") %>%
drop_na(forma, lema, pos) %>%
mutate(row_index = row_number())La función html_attr("data1") se encarga de extraer el atributo data1 de cada nodo w, el cual contiene la forma, el lema y la etiqueta morfológica. Luego, tibble(data1 = .) convierte el resultado en una tabla de una sola columna llamada data1. A continuación, separate(data1, into = c("forma", "lema", "pos"), sep = "•", remove = TRUE, fill = "right", extra = "merge") separa los datos en tres columnas: forma, lema y pos, y para ello se basa en el carácter • que separa cada uno de los elementos. La opción remove = TRUE elimina la columna original data1 (para evitar líos), mientras que fill = "right" se asegura de que las filas con menos de tres elementos se rellenen con valores vacíos (sería raro, pero puede ocurrir). Por último, mutate(row_index = row_number()) agrega una columna llamada row_index que contiene el índice original de cada fila y que corresponde, como he he dicho a la posición que ocupa dentro de todo el texto.
Ejecútalo. Ahora habrá aparecido en la ventana Environment un objeto llamado datos, que es una tabla que tiene 788246 líneas y 4 columnas. Échales un ojeada con
## # A tibble: 788,246 × 4
## forma lema pos row_index
## <chr> <chr> <chr> <int>
## 1 HSMS0208 RMK RMK 1
## 2 . PUNCT PUNCT 2
## 3 Alfonso RMK RMK 3
## 4 X RMK RMK 4
## 5 el RMK RMK 5
## 6 Sabio RMK RMK 6
## 7 rey RMK RMK 7
## 8 de RMK RMK 8
## 9 Castilla RMK RMK 9
## 10 y RMK RMK 10
## # ℹ 788,236 more rowslo que te mostrará las primeras diez entradas de la tabla datos, aunque no serán muy interesantes porque son de las primeras líneas que contienen los metadatos del texto. Lo importante es que ya tienes los datos que necesitas. En esta página puedes recorrerla toda haciendo clic en los números de la parte inferior derecha, en tu ordenador solo podrás verlo si haces clic en el nombre datos en la ventana Environment, se abrirá una nueva pestaña con el contenido de datos. El texto comienza en la línea 47.
17.3 Analizar los datos
Ahora vamos a ver en qué posiciones, a lo largo de todo el texto de las Siete Partidas, se encuentras las formas del verbo hacer, hablar, el sustantivo hijo y la preposición hasta impresas con f- inicial y en cuáles con h- inicial. Para ello, vas a filtrar los datos de la tabla datos que has creado en el paso anterior.
Tienes, como sabes, tres columnas: forma, lema y pos (hay cuatro, pero row_index por ahora no es útil). Para extraer los datos tienes que hacer una doble selección. Has de seleccionar las filas cuya columna lema sean igual a hacer, hablar, hijo o hasta y, además, que las palabras contenidas en la columna forma comiencen por f-. En un segundo paso deberás buscar los casos en que la columna forma comience por h-. (Solo lo presento con el caso del verbo hacer, te dejo las demás para que le tomes el tranquillo al sistema).
Lo primero es decirle cuál es el patrón de búsqueda que vas a utilizar y has de declararlo por medio de estas variables. Aquí puedes utilizar expresiones regulares, que son una forma de buscar patrones en cadenas de texto con una precisión increíble.
pattern_forma <- "patrón de búsqueda"
pattern_lema <- "patrón de búsqueda"
pattern_pos <- "patron de búsqueda"Puesto que quieres localizar las formas de hacer que comienzan por f- , el patrón de búsqueda será ^f-. El símbolo ^ indica que la forma ha de comenzar por f- (de acuerdo, perderemos los casos de los compuestos y derivados del tipo deshacer o prohijar).
Puesto quieres limitarlo a un único lema, el verbo hacer, has de indicar en pattern_lema el lema que quieres buscar:
En este momento, no te interesa buscar por etiqueta morfológica, luego no hace falta que declares el patrón de búsqueda para la columna pos. Que podría tener este aspecto si quiseras limitarlo a las formas del indicativo:
Ahora tienes que filtrar los datos de la tabla datos que has creado. Para lograrlo, utilizarás la función filter(), que te permite seleccionar filas basadas en condiciones específicas. En este caso, vas a buscar las formas que comienzan por f- y que tienen como lema hacer y, además, le pides que no haga distinción entre palabras escritas en mayúsculas y minúsculas (para un ordenador Hacer y hacer son totalmente diferentes).
El bloque de código que tienes a continuación te muestra cómo filtrar los datos de la tabla datos que has creado en el paso anterior. Corta y copia todo el bloque en el editor de RStudio, y borra el # de las dos líneas debajo de # Forma y Lema. El bloque de código te servirá para hacer varios tipos de búsquedas. Si quieres hacer otras búsquedas, puedes descomentar las líneas correspondientes (quitar el # al principio de la línea) y comentar las que no quieras utilizar (poner un # al principio de la línea).
filtrado <- datos %>%
filter(
# Lema:
# str_detect(lema, regex(pattern_lema, ignore_case = TRUE))
# Forma y Lema:
# str_detect(forma, regex(pattern_forma, ignore_case = TRUE)) &
# str_detect(lema, regex(pattern_lema, ignore_case = TRUE))
# Forma y pos:
# str_detect(forma, regex(pattern_forma, ignore_case = TRUE)) &
# str_detect(pos, regex(pattern_pos, ignore_case = TRUE))
# Búsqueda compleja con Forma, Lema y pos:
# str_detect(forma, regex(pattern_forma, ignore_case = TRUE)) &
# str_detect(lema, regex(pattern_lema, ignore_case = TRUE)) &
# str_detect(pos, regex(pattern_pos, ignore_case = TRUE))
)El código para buscar los casos de hacer que comienzan por f- debe tener este aspecto:
filtrado_1 <- datos %>%
filter(
# Lema
#str_detect(lema, regex(pattern_lema, ignore_case = TRUE))
# Forma y Lema
str_detect(forma, regex(pattern_forma, ignore_case = TRUE)) &
str_detect(lema, regex(pattern_lema, ignore_case = TRUE))
# Forma y pos:
# str_detect(forma, regex(pattern_forma, ignore_case = TRUE)) &
# str_detect(pos, regex(pattern_pos, ignore_case = TRUE))
# Búsqueda compleja con Forma, Lema y pos:
# str_detect(forma, regex(pattern_forma, ignore_case = TRUE)) &
# str_detect(lema, regex(pattern_lema, ignore_case = TRUE)) &
# str_detect(pos, regex(pattern_pos, ignore_case = TRUE))
)Fíjate que he llamado a la tabla resultante filtrado_1, que es la que contiene las formas de hacer que comienzan por f-. Al ejecutar el código, verás que en la ventana **Environment*** aparece un nuevo objeto llamadofiltrado_1`; es una tabla que tiene 12900 filas y 4 columnas. Si quieres ver las primeras diez filas de la tabla, ejecuta el siguiente código:
## # A tibble: 12,900 × 4
## forma lema pos row_index
## <chr> <chr> <chr> <int>
## 1 fazer hacer VMN0000 128
## 2 fazen hacer VMIP3P0 149
## 3 fazer hacer VMN0000 298
## 4 fizo hacer VMIS3S0 562
## 5 fizieron hacer VMIS3P0 638
## 6 fiziesen hacer VMSI3P0 785
## 7 fechas hacer VMP00PF 880
## 8 fazen hacer VMIP3P0 909
## 9 faze hacer VMIP3S0 1085
## 10 fazer hacer VMN0000 1106
## # ℹ 12,890 more rowsSi has seguido los pasos correctamente, verás que la tabla filtrado_1 contiene las formas del verbo hacer que comienzan por f- y que tienen como lema hacer y una nueva columna llamada row_index que indica la posición de cada forma en el texto original.
Ahora has de repetir el proceso para las formas que comienzan por h-. Para ello, has de cambiar el patrón de búsqueda de la variable pattern_forma a ^h-.
El patrón de búsqueda del lema seguirá siendo el mismo, hacer. Luego no tienes que hacer nada.
Ahora hay que filtrar los datos. El código es idéntico al anterior, solo has de cambiar el nombre de la tabla en la que guardarás los resultados. En este caso filtrado_2.
filtrado_2 <- datos %>%
filter(
# Lema
#str_detect(lema, regex(pattern_lema, ignore_case = TRUE))
# Forma y Lema
str_detect(forma, regex(pattern_forma, ignore_case = TRUE)) &
str_detect(lema, regex(pattern_lema, ignore_case = TRUE))
# Forma y pos:
# str_detect(forma, regex(pattern_forma, ignore_case = TRUE)) &
# str_detect(pos, regex(pattern_pos, ignore_case = TRUE))
# Búsqueda compleja con Forma, Lema y pos:
# str_detect(forma, regex(pattern_forma, ignore_case = TRUE)) &
# str_detect(lema, regex(pattern_lema, ignore_case = TRUE)) &
# str_detect(pos, regex(pattern_pos, ignore_case = TRUE))
)Si has seguido los pasos correctamente, verás que en la ventana **Environment*** aparece un nuevo objeto llamadofiltrado_2`; una tabla que tiene 12900 filas y 4 columnas. Ya sabes cómo ver las diez primeras filas:
## # A tibble: 1,111 × 4
## forma lema pos row_index
## <chr> <chr> <chr> <int>
## 1 hase hacer VMIP3S0 11513
## 2 hase hacer VMIP3S0 243577
## 3 hizo hacer VMIS3S0 479984
## 4 hazer hacer VMN0000 479988
## 5 hiziese hacer VMSI3S0 480002
## 6 hechas hacer VMP00PF 480040
## 7 hecho hacer VMP00SM 480051
## 8 hizo hacer VMIS3S0 480056
## 9 hiziese hacer VMSI3S0 480063
## 10 hecho hacer VMP00SM 480170
## # ℹ 1,101 more rowsYa te puedes hacer una idea de que hay preferencia por las formas con f- inicial. Vamos a ver gráficamente cómo se distribuyen a lo largo de todo el texto de las Siete Partidas. Localizar el punto exacto en el que comienza cada una de las Siete Partidas es una labor que hay que hacer a mano. Los trabajos manuales son inevitables en la investigación.
hitos <- c(48, 142733, 287142, 474978, 545778, 633713, 701506)
hitos_etiquetas <- c(" Primera", "Segunda", "Tercera", "Cuarta", "Quinta", "Sexta", "Séptima")En hitos he marcado en qué posición comienza cada una de las Partidas. En hitos_etiquetas he puesto los nombres de cada una de las Partidas. Ahora hay que crear un gráfico que muestre la distribución de las formas del verbo hacer a lo largo de todo el texto.
El gráfico será semejante a un código de barras, donde cada forma localizada es una línea vertical. Para ello, utilizarás la función geom_linerange() que permite crear líneas verticales en las posiciones especificadas. geom_vline() te permitirá añadir líneas verticales en el lugar en que comienza cada Partida, lo cual tienes guardado en hitos. scale_x_continuous() se encarga de configurar el eje x del gráfico, donde se mostrarán las posiciones de los hitos y las etiquetas correspondientes, que tienes guardadas en hitos_etiquetas. Por último, theme_minimal() aplica un tema minimalista al gráfico. Corta, pega y ejecuta.
ggplot() +
geom_linerange(
data = filtrado_1,
aes(x = row_index, ymin = 0, ymax = 1),
color = "blue", alpha = 0.7
) +
geom_vline(
xintercept = hitos,
color = "red", linetype = "dashed"
) +
scale_x_continuous(
"Tiempo narrativo",
breaks = hitos,
labels = hitos_etiquetas,
expand = c(0.01, 0.01)
) +
theme_minimal() +
theme(axis.text.y = element_blank(),
axis.ticks.y = element_blank()) +
labs(
title = "Casos de hacer con f- inicial",
y = NULL
)
En la ventana **Plot*`** habrá aparecido un gráfico semejante (prácticamente idéntico al que hay justo encima de estas líneas). En él puedes ver cómo se distribuyen las formas que se escriben con f- del verbo hacer a lo largo de todo el texto de las Siete Partidas. Verás que en la Cuarta Partida hay mucho espacio en blanco. ¿Qué querrá decir?
Ahora vas a hacer lo mismo con las formas que comienzan por h-. Para ello, has de cambiar el nombre de la tabla en la que guardarás los resultados. En este caso filtrado_2 (He cambiado el color de las líneas azul a verde; y el título del gráfico, todo lo dem´s es idéntico).
ggplot() +
geom_linerange(
data = filtrado_2, # CAMBIA AQUÍ LA TABLA DE DATOS
aes(x = row_index, ymin = 0, ymax = 1),
color = "green", alpha = 0.7
) +
geom_vline(
xintercept = hitos,
color = "red", linetype = "dashed"
) +
scale_x_continuous(
"Tiempo narrativo",
breaks = hitos,
labels = hitos_etiquetas,
expand = c(0.01, 0.01)
) +
theme_minimal() +
theme(axis.text.y = element_blank(),
axis.ticks.y = element_blank()) +
labs(
title = "Casos de hacer con h- inicial",
y = NULL
)
17.4 Conclusión
Ahora ya solo te queda interpretarlos. Para mí es evidente que las formas con h- inicial son mucho menos frecuentes que las que comienzan por f-. Pero resulta curiosa la concentración de los casos de h- en la Cuarta Partida (los espacios en blanco se han rellenado), y al comienzo de la Sexta Partida con algún caso suelto en la Primera Partida y en la Segunda Partida. ¿Tendrán el mismo comportamiento los casos de hablar, hijo y hasta?
Nada de esto lo podrías haber observado manualmente. Ni con algunas otras herramientas que he probado (como AntConc o Voyant Tools). La ventaja de utilizar R es que puedes hacer análisis de este tipo de forma rápida y sencilla, y además puedes repetir el proceso con otros lemas o formas sin tener que empezar de cero.
Trata ahora de averiguar si en esta edición hay preferencia por -ss- o por s en las formas del pretérito imperfecto de subjuntivo. Te ayudo un poco, en pattern_pos has de poner VMIS para el pretérito imperfecto de subjuntivo.
