16 Lingüística de corpus I
16.1 Visualizaciones de las búsquedas del Old Spanish Textual Archive
16.1.1 Introducción
Para el estudio e investigación del español (o iberorrománico central) medieval hay varios corpus disponibles en la red como los de la red Charta o el Atlas Histórico del Español, basado en los datos de la red Charta. El más interesante es, sin duda, el Old Spanish Textual Archive que se remonta a las transcripciones electrónicas que desde 1977 se prepararon para el Dictionary of Old Spanish Language en el Hispanic Seminary of Medieval Studies (HSMS).
Este corpus recoge textos literarios, en el más amplio sentido de la palabra literario dado que incluye textos poéticos, narrativos, históricos, científicos, legales, religiosos…, etiquetados morfológicamente y lematizados. En él se pueden hacer búsquedas complejas jugando con qué datos se quieren extraer y limitándolos por medio de una serie de metadatos. Con este sistema se pueden obtener en pantalla unas concordancias KWICK que se pueden repesar a mano.

También permite acceder a la transcripción del folio del códice o impreso en que se documenta cada una de las formas.

Este es un buen proceder cuando se buscan unos pocos casos para argumentar o documentar un rasgo lingüístico. Sin embargo, no ofrece visualizaciones gráficas de los datos, como sí lo hacen algunos de los corpus integrados en la red Charta o el AHE.
Esto, a primera vista, es una limitación, sin embargo, puede solventarse con facilidad dado que OSTA ofrece la posibilidad de descargar los resultados de la búsqueda. Se hace por medio de un fichero que contiene la forma buscada (con el lema y la etiqueta gramatical), el contexto que le precede y sigue a la forma y una docena larga de metadatos (entre otros: autor, título, fecha de producción y copia, lugar de producción/copia, la biblioteca en la que se conserva el ejemplar transcrito…).
El fichero que se descarga tiene la extensión tsv. Estos ficheros lo que contienen es una tabla con los mismos datos que se ven en pantalla (algunos solo se ven si se sitúa el ratón sobre una palabra), pero separados por medio de tabuladores. Es el mismo tipo de fichero que los csv, solo que estos separan las diferentes columnas por medio de comas, pero como los textos pueden tener anidados signos de puntuación (los cuales pueden ser de interés en un análisis lingüístico), es mucho mejor usar los tabuladores, dado que respetan el valor de los signos de puntuación. Esta tabla puede ir desde unas pocas líneas hasta un máximo de 249.999 resultados.
Esta tabla se puede manejar con programas como Excel, pero también con lenguajes de programación como Python o R. Puesto que el trabajo que usualmente se hace con los corpus lingüísticos son análisis estadísticos y visualizaciones de los datos como en la imagen 1, una opción excelente para realizar es utilizar R.
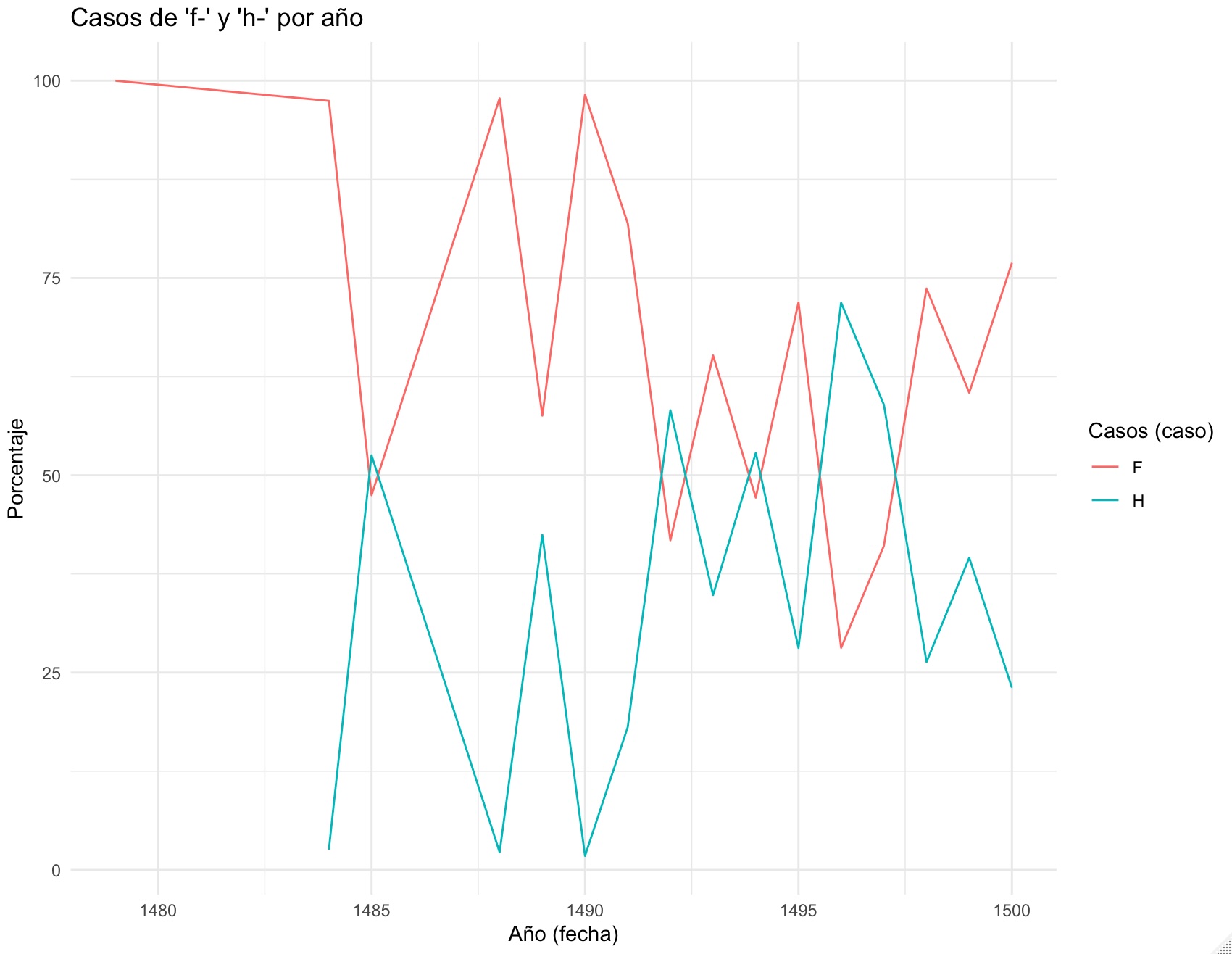
Figura 16.1: La evolución de los resultados de F- en los incunables
16.1.2 Obtención de los datos
Lo primero que vamos a hacer es una búsqueda en OSTA. Nos planteamos la pregunta de cuál es la distribución de los resultados gráficos de F- inicial latina, como, por ejemplo, en FARINA > farina > harina, pero hay que descartar casos como FESTA > fiesta, en los que se mantuvo siempre la f-, aunque hubo casos como FOCU > _fuego- > huego constituyen un pequeño problema puesto que el estadio huego no triunfó y regresó al estadio fuego.
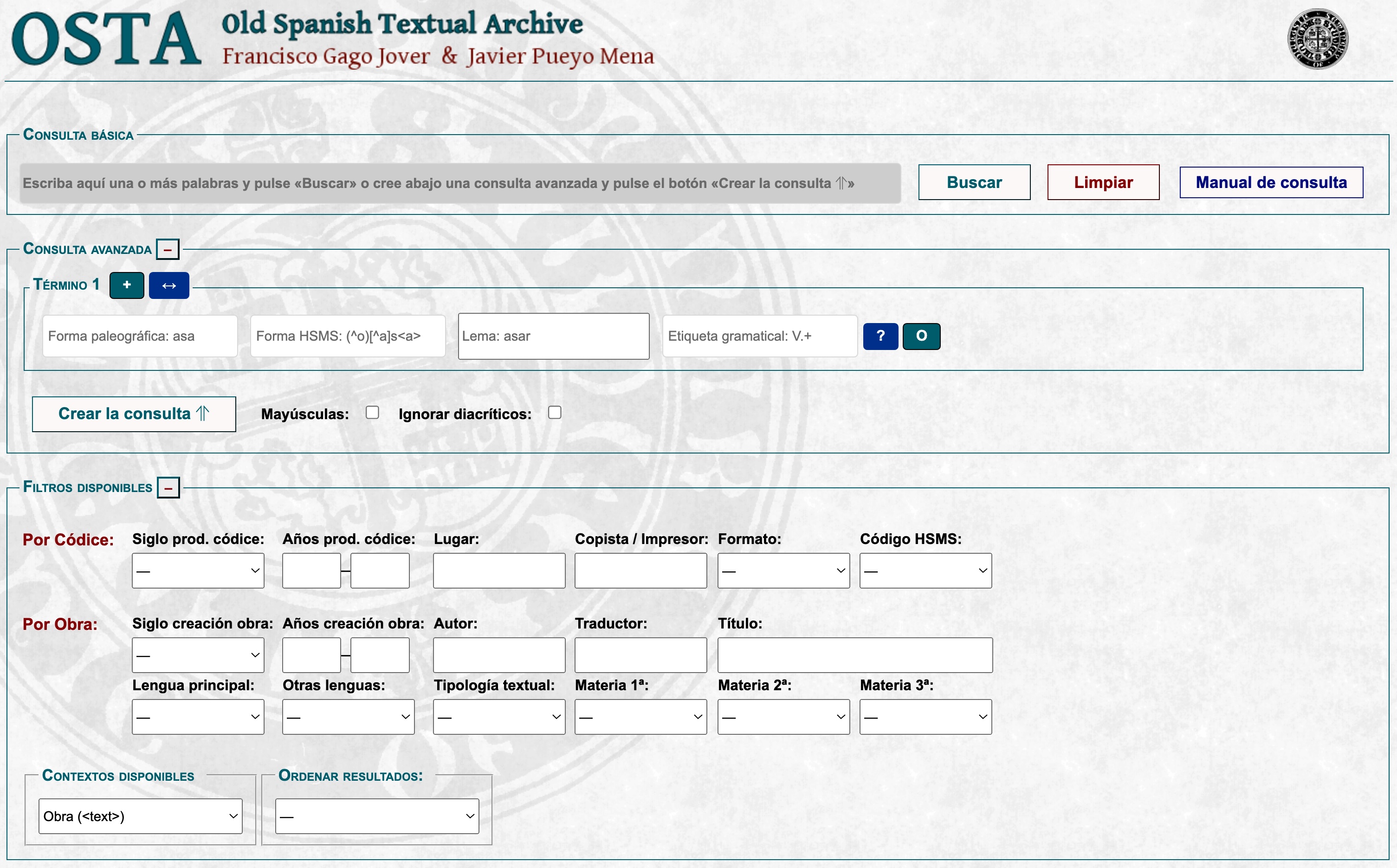
Figura 16.2: Pantalla de búsqueda de OSTA
Has de tener una pequeña estrategia de búsqueda. No puedes extraer todos los datos a la vez. Lo primero que vas a localizar y descargar son todos los casos de palabras escritas con f-, y cuyo étimo se remonte a una palabra que en latín tenía F-. Así pues, en el bloque Consulta Avanzada, en la casilla Forma paleográfica, introduces f.+. Esto hace que el motor de búsqueda encuentre cualquier palabra que empiece por f y tenga al menos una letra más. El punto (.) significa que debe haber una letra después de la f y el signo más (+) indica que puede haber una o más letras adicionales. Por otra parte, como quieres limitarlo a aquellos casos que se remonten a una F- latina y, como asumes que en estos casos el resultado final tiene h-, restringes la búsqueda a las formas cuyo lema comience con h-. Para lograrlo, has de que escribir en la casilla Lema la secuencia: h.+, que le indica al motor de búsqueda que se limite a localizar aquellas formas que comiencen por f- y cuyo lema lo haga por h .
A continuación haces clic en la casilla Crear la consulta ⥣, que enviará la información a la primera casilla, la que están en gris bajo la etiqueta Consulta básica. Si lo has hecho, debes ver que en ella dice [(word='f.+' & lemma='h.+'%c)]. Si lanzas la búsqueda, basta con pulsar el botón Buscar que hay a la derecha de la caja, tras unos segundos, te informará de que ha encontrado más de 535.401 formas (la cifra puede variar puesto que cada cierto tiempo se añaden nuevos textos a OSTA) que se documentan desde el Auto de los Reyes Magos (manuscrito) hasta la edición de 1770 de la Historia Clámades y Claramonda. Podría interesarte verlo a lo largo de toda la historia de la lengua, pero no seas ambicioso, por ahora lo limitarás al último cuarto del siglo XV y dentro de un formato novedoso para aquel momento: los libros impresos.
El tercer bloque de OSTA se titulada Filtros disponibles. Aquí puedes restringir la búsqueda con gran precisión. Como solo queremos localizar los casos en libros impresos del siglo XV, has de hacer clic en la casilla Formato. Se abrirá un desplegable; ahí selecciona incunable.
Lanza la búsqueda. Será de todas aquellas formas que haya en OSTA que comiencen con una f (mayúscula o minúscula), cuyo lema empiece con una h, pero limitada a los incunables, es decir, a los textos impresos entre 1472 y 1500. Haz clic en buscar (lo marca el selector de Formato en el que has elegido incunable).

Si todo ha ido bien aparecerá una caja (como la de la imagen anterior) titulada Resultados de la consulta. Ahí te informa de cuál es la búsqueda (consulta) que has lanzado y de los filtros que has aplicado y cómo ha organizado los resultados. También detalla que hay 78.779 casos en 225 textos (esto es lo de menos) y que la frecuencia regularizada por millón de palabras es 2438.75 (dato que tampoco es de interés en este momento).
Verás que en la parte superior de esa caja dice [Descargar: TSV]. Haz clic sobre TSV (que estará en azul salvo que hayas cambiado el esquema de colores del navegador). En unos pocos segundos (todo depende de la conexión a internet) se habrá descargado un fichero (en teoría estará en la carpeta de descargas del ordenador) cuyo nombre es OSTA-resultados-dd-mm-aaaa-hh_mm_ss.tsv (las letras tras resultado corresponden al sello de fecha y hora). Es poco claro, así que cámbialo por otro que te indique qué es lo que contiene. Para este tutorial se ha usado f-h-incunable.tsv (que se interpreta como que contiene los casos de palabras escritas con f cuyo lema comienza por h impresas entre 1472 y 1500, o lo que es lo mismo, en libros incunables).
Ahora vas a conseguir los casos en los que las formas de los lemas que se escriben con h- están escritas con h- (mayúscula y minúscula). Ve a la casilla de Consulta avanzada y en donde escribiste f.+ escribe ahora h.+. Haz clic en Crear la consulta ⥣. Puesto que sigues teniendo los filtros que aplicaste en la búsqueda anterior, y los quieres volver a usar, pulsa sobre Buscar. Ahora la casilla de resultados te dirá que hay 86067 casos en 340 textos. Perfecto. Descarga el TSV y renómbralo h-h-incunablea.tsv.
Sin embargo, todo no ha ido tan perfecto. Si te fijas en los primeros resultados, verás que las palabras que esta última busqueda ha extraído son han, honestad, habito, honrrados. Ninguna de ellas cumple el criterio de tu búsqueda. Ha recuperado palabras que comienzan con h- pero que no se remontan a étimos con F-.
Lo que harás ahora es algo que puede parecer absurdo, pero es necesario. Vas a localizar todas aquellas palabras que tienen una h en el lema, pero que no comienzan ni por f ni h, es decir, has de extraer todas aquellas formas que empiezan por vocal y cuyo lema lo hace con h. En la casilla Consulta avanzada escribe [^fh].+. Puesto que no tienes que cambiar ningún otro filtro ni elemento de la búsqueda, haz clic en Crear la consulta ⥣ y a continuación en Buscar.
Esta rara expresión —[^fh].+— lo que le dice al motor de búsqueda es que localice todas las palabras que no (lo indica el ^) empiecen por f ni por h.
Cuando aparezcan los resultados, descarga el TSV y renómbralo 0-h-incunables.tsv.
El motivo de obtener este fichero es conseguir una lista de todos los lemas que comienzan con h- y que no se pueden remontar a una F- latina. Bueno, siempre pueda haber un escriba (en este caso cajista) veleidoso —puede ser que introdujera una errata— que haya podido escribir fombre, fospital o fuvieron en vez de ombre, ospital o uvieron, pero asumimos (🤞) que no lo haya hecho, aunque si lo hubiera hecho, serían estadísticamente irrelevantes.
Con esta lista de palabras eliminarás todos aquellos casos de h- que se remonten a un lema con h- pero que no proceden de una F- inicial latina.
Antes mencioné los casos en que una F- latina pasó a f- y que durante algún tiempo se escribieron con h- como en el caso de FOCU > huego, FEBRUARIU > hebrero o el arabismo fulano que se documenta, pocas veces (en OSTA hay 14 casos), como hulano (hay un caso de hulana en un modernísimo desdoblamiento genérico). Vamos a extraer también estos datos. Para ello, en la casilla Consulta avanzada escribe h.+ y en la casilla lema f.+. Haz clic en Crear la consulta ⥣ y, a continuación, en Buscar. Son muy pocos casos, 350 en cincuenta textos, y uno de los más abundates es el antropónimo Háñez, es decir Fáñez. Descarga el fichero y renómbralo como h-f-incunables.tsv.
Ya tienes todos los materiales. Ahora vas a analizarlos.
16.2 Análisis de los datos
Arranca RStudio, abre el editor de scripts y escribe y ejecuta la primera instrucción, que es cargar la librería que te ayudará a preparar los datos.
Lo primero que has de hacer es leer los ficheros con los datos que has recolectado de OSTA. No te vas a romper la cabeza con los nombres de los objetos en el que lo vas a leer, pues son temporales. Lo más sencillo, las letras de abecedario.
a <- read_tsv("DIRECTORIO DONDE LO TENGAS/f-h-incunables.tsv")
b <- read_tsv("DIRECTORIO DONDE LO TENGAS/h-h-incunables.tsv")
c <- read_tsv("DIRECTORIO DONDE LO TENGAS/h-f-incunables.tsv")
d <- read_tsv("DIRECTORIO DONDE LO TENGAS/0-h-incunables.tsv")En Environment habrá catro tabla llamadas a, b, c y d. Todas ellas con 17 columnas y un número variables de observaciones, es decir de líneas.
Ahora reunirás en una sola tabla el contenido de a, b y c que tienen todos los datos de los casos de f y h mientras en c están los casos raros de h- en los que hoy hay f pero que se remontan a una F-.
Ahora deberás tener en la ventana de Global Environment un nuevo objeto llamado datos con 168030 observaciones y 17 variables. Son todos los casos de palabras cuyo étimo se remonta a una F- inicial latina que aparecen en todos los incunables que tiene recogidos OSTA, pero el número de textos es muchísimo más amplio.
Échale una ojeada al tabla que has creado. Teclea en la consola datos y pulsa enter/intro. Esto hará que se imprima el comienzo de la tabla. No será tan bonita como la que hay a continuación, pero tendrá prácticamente la misma información.
## # A tibble: 168,030 × 17
## Nº Códice `Fecha Inicio Códice` `Fecha Fin Códice`
## <dbl> <chr> <chr> <chr>
## 1 1 SAF 1472-06-10 1472-06-10
## 2 2 SAF 1472-06-10 1472-06-10
## 3 3 SAF 1472-06-10 1472-06-10
## 4 4 SAF 1472-06-10 1472-06-10
## 5 5 SAF 1472-06-10 1472-06-10
## 6 6 SAF 1472-06-10 1472-06-10
## 7 7 SAF 1472-06-10 1472-06-10
## 8 8 SAF 1472-06-10 1472-06-10
## 9 9 SAF 1472-06-10 1472-06-10
## 10 10 SAF 1472-06-10 1472-06-10
## # ℹ 168,020 more rows
## # ℹ 13 more variables: Lugar <chr>,
## # `Copista/Impresor` <chr>, Biblioteca <chr>, Obra <chr>,
## # `Fecha Inicio Obra` <chr>, `Fecha Fin Obra` <chr>,
## # Título <chr>, Autor <chr>, Traductor <chr>, Folio <chr>,
## # `Contexto previo` <chr>,
## # `Término Buscado <Lema> [Etiqueta]` <chr>, …Lo que haya aparecido en la consolo de tu ordeanador no se parecerá en nada a lo qué estás viendo. Aquí sale de una forma bonita y explorable. Puedes recorrer todas las columnas (de la tabla anterior) si haces clic en el triangulito (‣) que hay en la línea con el nombre de las variables. Verás cómo se llama cada variable (columna) y el tipo de contenido. Si quieres ver más filas, haz clic en cualquiera de los numeritos o en el Next que hay en la parte inferior. La que se ha impreso en tu consola es solo una mirada sencilla, pero si haces clic en el objeto datos que hay en la ventana Environment, se abrirá una pestaña en donde esté el editor de R y te dará acceso a la tabla, con lo que podrás inspeccionarla con detenimiento.
Te dije que a, b y c eran temporales. Bórralos para que la ventana de Environment no esté llena de objetos inútiles. Lo consigues con la instrucción que hay en la siguiente caja.
En Environment solo debería de haber dos objetos: d y datos. Si es así, toda va bien. En caso contrario es que hay datos de sesiones anteriores. Lo mejor en esos casos es cerrar RStudio y comenzar de nuevo.
Vas a reducir un tanto la tabla datos, pues hay mucha información que no te hace falta, como el contexto anterior y el posterior y la gran mayoría de los metadatos. Aunque ya has visto cómo se llama cada una de las columnas al revisar la tabla datos, no viene mal verlos con un sencilla instruscción
## [1] "Nº"
## [2] "Códice"
## [3] "Fecha Inicio Códice"
## [4] "Fecha Fin Códice"
## [5] "Lugar"
## [6] "Copista/Impresor"
## [7] "Biblioteca"
## [8] "Obra"
## [9] "Fecha Inicio Obra"
## [10] "Fecha Fin Obra"
## [11] "Título"
## [12] "Autor"
## [13] "Traductor"
## [14] "Folio"
## [15] "Contexto previo"
## [16] "Término Buscado <Lema> [Etiqueta]"
## [17] "Contexto posterior"Ahí tienes los nombres de las 17 columnas o variables de que constan todos los ficheros tsv que descargaste de OSTA. De estas 17 columnas te vas a quedar con tan solo cinco: el Códice [2], que es el identificador del impreso que aporta los datos; la Fecha de Inicio Códice [3], que indica cuándo se imprimió el libro (en realidad puedes jugar con la Fecha de Inicio Códice y la de Fecha Fin de Códice que en los impresos suele ser la misma: la fecha en que finalizó la impresión del ejemplar); el Lugar [5]; el Copista/Impresor [6] y la que se llama Término Buscado <Lema> [Etiqueta] [16], que es donde está toda la información que te interesa. Todas las demás columnas las vas eliminar porque no te sirven para nada, ocupan espacio en la memoria y pueden enlentecer los cálculos. En otras casos puede que te sean de interés. Ten en cuenta que se borran de la memoria del ordenador, no de los ficheros que tienes en el disco duro.
Corta y pega este fragmento de código en el editor de RStudio, pero no lo ejecutes hasta que hayas leído la explicación de lo que hará.
datos <- datos %>%
select(2, 3, 5, 6, 16) %>%
separate(5, c("forma", "lema", "pos"), sep = " ") %>%
mutate(
forma = tolower(forma),
lema = str_replace_all(lema, "[<>]", ""),
pos = str_replace_all(pos, "[\\[\\]]", ""),
`Fecha Inicio Códice` = substr(`Fecha Inicio Códice`, 1, 4)) %>%
rename(fecha = `Fecha Inicio Códice`) %>%
rename(lugar = `Lugar`) %>%
rename(impresor = `Copista/Impresor`) %>%
rename(sigla = `Códice`)De eliminar las columnas (variables) que no interesan, se ocupa la línea que dice select(2, 3, 5, 6, 16). Podría poner los nombres, pero es un rollo (sobre todo cuando tienen espacios en blanco y tildes) y es más corto y claro usar los números de índice (los que están encerrados entre corchetes) que has visto al revisar los nombres de las columnas.
La columna Término Buscado <Lema> [Etiqueta], la 16, tal y como se descarga de OSTA no la puedes manejar adecuadamente, por lo que hay que dividirla en tres columnas que llamarás forma, lema y pos. Esto se consigue con la línea separate(5, c("forma", "lema", "pos"), sep = " "). El 5 es porque una vez que has seleccionado las columnas en la instrucción anterior, ahora solo tienes 5 variables y no 17, por lo que la que al principio era la 16 ahora es la 5. (¡Sí, sé que es un poco lioso!).
Dentro de las nuevas columnas (forma, lema y pos) hay algo de basura que no interesa y puede complicar el análisis. Los lemas están encerrados entre <…> y las etiquetas morfológicas (pos) entre […]. Además, dado que los ordenadores son absolutamente literales, tienes que convertir a minúsculas todas las formas que en los impresos originales pueden estar escritas con mayúsculas; para el ordenador son distintas fijo e Fijo, así que todas deben estar en minúsculas. Así evitarás errores en los cálculos.
Borrar los símbolos y pasar el contenido de la columna forma a minúsculas se logra con las expresiones forma = tolower(forma), lema = str_replace_all(lema, "[<>]", "") y pos = str_replace_all(pos, "[\\[\\]]", ""), que son argumentos de la instrucción mutate().
Además, la columna Fecha Inicio Códice en muchos casos presenta la estructura aaaa-mm-dd puesto que, por lo general, los incunables informan en su colofón del día, mes y año en que se finalizó la impresión (a veces las fechas están seguidas de las expresiones post quem o ante quem ya que no se sabe a ciencia cierta cuándo se imprimieron algunas ediciones, pero hay datos que permiten establecer una hipótesis; OSTA toma el año que los investigadores creen que se debió de imprimir). Como solo te interesan las cifras del año usas la expresión 'Fecha Inicio Códice' = substr('Fecha Inicio Códice', 1, 4)).
Las cuatro última líneas, que comienzan todas por rename, lo que hacen es renombar con nombres más sencillos, y menos problemáticos (R se lleva muy mal con los espacios en blanco y las letras acentuadas en los nombres de las variables), todas las variables.
Ejecuta ahora el bloque de código y échale una ojeada con la instrucción datos. A ti te saldrá una tabla feucha, pero ya te he contado cómo la puedes ver al completo. Observa esta, que es muy clara.
## # A tibble: 168,030 × 7
## sigla fecha lugar impresor forma lema pos
## <chr> <chr> <chr> <chr> <chr> <chr> <chr>
## 1 SAF 1472 Segovia Juan Párix fasta hasta SPS00
## 2 SAF 1472 Segovia Juan Párix fagan hacer VMSP3P0
## 3 SAF 1472 Segovia Juan Párix faga hacer VMSP1S0
## 4 SAF 1472 Segovia Juan Párix fecħos hecho NCMP000
## 5 SAF 1472 Segovia Juan Párix fazer hacer VMN0000
## 6 SAF 1472 Segovia Juan Párix fazer hacer VMN0000
## 7 SAF 1472 Segovia Juan Párix fazer hacer VMN0000
## 8 SAF 1472 Segovia Juan Párix fijo hijo NCMS000
## 9 SAF 1472 Segovia Juan Párix fecħas hacer VMP00PF
## 10 SAF 1472 Segovia Juan Párix fagamos hacer VMSP1P0
## # ℹ 168,020 more rowsTienes siete columnas:
+ `sigla`: identifica la edición/texto que se ha explorado.
+ `fecha`: el año de publicación.
+ `lugar`: el sitio donde se publicó.
+ `impresor`: da cuenta del taller que la imprimió.
+ `forma`: contiene la forma gráfica de la palabra.
+ `lema`: ofrece el lema.
+ `pos`: presenta la etiqueta gramatical.Ya sabes cómo explorar la tabla, tanto en esta página como en tu ordenador, pues te lo he contado poco antes.
Por pura curiosidad, vas a explorar cuáles son las ciudades en las que se imprimieron las ediciones que están incluidas en OSTA. Lo consigues con la instrucción unique(). Dentro del paréntesis le indicas el argumento datos$lugar —unique(datos$lugar)—, es decir, le estás pidiendo a R que vea cuáles son los literales que hay en la columna lugar de la tabla datos y dado que pueden estar repetidas, le pides que solo te muestre una sola forma de cada una de ellas.
## [1] "Segovia" "Zaragoza" "Sevilla" "Zamora"
## [5] "Huete" "Burgos" "Murcia" "Híjar"
## [9] "Salamanca" "Toulouse" NA "Coria"
## [13] "Toledo" "Valladolid" "Barcelona" "Pamplona"
## [17] "Lérida" "Valencia"NA no es la abreviatura de Navarra, es la manera que tiene R de indicar la ausencia de un dato (NA = not available ‘no disponible’). En este caso, es porque hay algunos casos en los que no se desconoce el lugar de impresión.
Ya tienes la primera gran tabla de datos preparada. Ahora tienes que hacer lo mismo con la tabla d, que servirá para eliminar de datos que tienen una H en el lema, pero no en la forma. A esta nueva tabla la llamarás raros. Como ya te he explicado qué es lo que hace el código, pues es idéntico al de antes, ejecútalo sin más.
raros <- d %>%
select(2, 3, 5, 6, 16) %>%
separate(5, c("forma", "lema", "pos"), sep = " ") %>%
mutate(
forma = tolower(forma),
lema = str_replace_all(lema, "[<>]", ""),
pos = str_replace_all(pos, "[\\[\\]]", ""),
`Fecha Inicio Códice` = substr(`Fecha Inicio Códice`, 1, 4)) %>%
rename(fecha = `Fecha Inicio Códice`) %>%
rename(lugar = `Lugar`) %>%
rename(impresor = `Copista/Impresor`) %>%
rename(sigla = `Códice`)
rm(d) # Borra el fichero de entradaEn la ventana Environment solo tiene que haber dos objetos: datos y raros.
La nueva tabla raros es clave para eliminar de datos todos aquellos casos de formas que tienen h pero que no tenían F en el étimo, es decir, todas aquellas que se remontan a una H en latín (tipo hábito, hombre, haber, etc.), y alguna que otra rareza. Las borrarás en virtud del lema y lo guardarás en un nuevo objeto llamado final. Lo consigues con la instrucción antijoin que le dice que borre en datos todos aquellos casos que se encuentren en raros, pero a la luz de lo que dice la columna lema.
Fíjate en la ventana Environment: los 168030 casos de datos se han reducido a tan solo 29906 en final. Por fin tienes los datos limpios y organizados: todos los casos de F- inicial latina y sus respectivos resultados escritos con h y con f. Para hacer los recuentos con mayor sencillez, hay que crear una nueva variable que llamarás caso. Lo único que vas a hacer es poner una F en aquellos casos que se escribe con f y una H donde la forma está escrita con h. Lo consigues con esta instrucción
final <- final %>%
mutate(caso = if_else(str_starts(forma, "f"),
"F", if_else(str_starts(forma, "h"),
"H", "No")))Lo que le está diciendo es: crea una nueva columna (con mutate()) que se llamará caso y que la rellene condicionalmente. Si la palabra de la columna forma empieza por f, entonces pon un F en la nueva columna caso, pero si comienza con h, entonces pon una H en caso. Si no se cumple ninguna de las dos condiciones anteriores, entonces pon No, que son los casos en que la F- ha llegado al cero gráfico, casos como igo procedente de FICUM.
Échale una ojeada a la tabla escribiendo final en la consola. Aparecerá el comienzo de la tabla, como has visto antes, pero aquí la tienes con un aspecto más elegante y sencillo de revisar.
## # A tibble: 29,906 × 8
## sigla fecha lugar impresor forma lema pos caso
## <chr> <chr> <chr> <chr> <chr> <chr> <chr> <chr>
## 1 SAF 1472 Segovia Juan Párix fijo hijo NCMS0… F
## 2 SAF 1472 Segovia Juan Párix fe he RG F
## 3 SAF 1472 Segovia Juan Párix fijo hijo NCMS0… F
## 4 SAF 1472 Segovia Juan Párix fijos hijo NCMP0… F
## 5 SAF 1472 Segovia Juan Párix fe he RG F
## 6 SAF 1472 Segovia Juan Párix finquen hincar VMSP3… F
## 7 SAF 1472 Segovia Juan Párix fincado hincar VMP00… F
## 8 SAF 1472 Segovia Juan Párix fijos hijo NCMP0… F
## 9 SAF 1472 Segovia Juan Párix fynquen hincar VMSP3… F
## 10 SAF 1472 Segovia Juan Párix feridas herida NCFP0… F
## # ℹ 29,896 more rowsEl bloque de código que hay a continuación lo que hace es recontar cuántos casos de F y de H hay por año, pero como las diferentes ediciones / textos tienen extensiones muy distintas la edición de las Siete Partidas SPO en OSTA tiene 783505 palabras mientras que el texto más breve, las Coplas hechas sobre el casamiento de la hija del Rey de España CHR tan solo tiene 1253) tienes que calcular la frecuencia relativa. Además, lo quieres saber por años, es decir, crear una serie temporal.
resultado <- final %>%
group_by(fecha, caso) %>%
summarise(recuento = n()) %>%
group_by(fecha) %>%
mutate(relativa = recuento / sum(recuento) * 100) %>%
mutate(fecha = as.numeric((fecha))) %>%
ungroup()El código anterior crea una nueva tabla llamada resultado que toma los datos de la tabla llamada final. Lo primero que le dice es que cree un grupo con group_by() utilizando fecha y caso. Una vez que ha creado ese grupo, summarise() crea una nueva columna llamada recuento en la que apuntará cuántos ejemplos hay de H y cuántos de F en cada año.
El siguiente paso es calcular la frecuencia relativa de los usos de Fy H para cada año. Esto lo hace creando una nueva columna con mutate() que se llamará relativa y que se rellenará con el cálculo de lo que hay en la columna recuento dividido por la suma sum() de los valores de recuento, pero agrupados por fecha, que es lo que le has indicado en la línea anterior con el group_by(fecha), y eso lo divida entre 100.
A continuación le dice que el contenido de fecha lo transforme de letras a números. Sí, los ordenadores son un tanto raros, 1472 puede considerarlo como la secuencia de unos caracteres alfanuméricos y no como números. Por eso, si los nombres de los ficheros llevan números, entonces las cifras no las considerará como números sino como caracteres alfanuméricos y los verás desperdigados por el directorio. Por este motivo, para conseguir que los números parezcan que son números y se orden como tales 1, 2, 3… se les pone una serie de ceros a la izquierda 001… 010… 050… 100, 999 y así se organizarán correlativamente como si realmente fueran números en el sentido matemático.
Por último, le dice que se deshaga los grupos con ungroup() puesto que ya no hacen falta. Revisa el contenido de la tabla resultado. Como son solo 43 casos, los vas a imprimir todos en la consola, pero para eso necesitas la expresión que hay en la caja que hay a continuación.
## # A tibble: 43 × 4
## fecha caso recuento relativa
## <dbl> <chr> <int> <dbl>
## 1 1472 F 10 62.5
## 2 1472 H 6 37.5
## 3 1479 F 28 100
## 4 1482 F 746 87.4
## 5 1482 H 108 12.6
## 6 1483 F 133 51.2
## 7 1483 H 127 48.8
## 8 1484 F 518 97.9
## 9 1484 H 11 2.08
## 10 1485 F 45 49.5
## # ℹ 33 more rowsEl resultado en tu ordenador se parecerá a este, que no es muy elegante.
## # A tibble: 43 × 4
## fecha caso recuento relativa
## <dbl> <chr> <int> <dbl>
## 1 1472 F 10 62.5
## 2 1472 H 6 37.5
## 3 1479 F 28 100
## 4 1482 F 746 87.4
## 5 1482 H 108 12.6
## 6 1483 F 133 51.2
## 7 1483 H 127 48.8
## 8 1484 F 518 97.9
## 9 1484 H 11 2.08
## 10 1485 F 45 49.5
## 11 1485 H 46 50.5
## 12 1486 F 244 95.7
## 13 1486 H 11 4.31
## 14 1487 F 1988 93.9
## 15 1487 H 130 6.14
## 16 1488 F 823 93.2
## 17 1488 H 60 6.80
## 18 1489 F 648 50.9
## 19 1489 H 626 49.1
## 20 1490 F 476 68.8
## 21 1490 H 216 31.2
## 22 1491 F 3304 83.1
## 23 1491 H 673 16.9
## 24 1492 F 1690 48.5
## 25 1492 H 1796 51.5
## 26 1493 F 923 71.4
## 27 1493 H 370 28.6
## 28 1494 F 1382 43.5
## 29 1494 H 1794 56.5
## 30 1495 F 2144 70.5
## 31 1495 H 896 29.5
## 32 1496 F 238 28.3
## 33 1496 H 602 71.7
## 34 1497 F 263 42.1
## 35 1497 H 362 57.9
## 36 1498 F 1092 48
## 37 1498 H 1183 52
## 38 1499 F 1574 71.0
## 39 1499 H 644 29.0
## 40 1500 F 1488 76.3
## 41 1500 H 463 23.7
## 42 NA F 7 28
## 43 NA H 18 72Es una tabla con 43 resultados, casi todos agrupados por pares cuyo elemento común es el año, uno para H y otro para F. Al final hay dos para los que no tenemos año, los especialistas nos se han atrevido a dar una fecha, ni siquiera aproximada.
Repasar una tabla y extraer conclusiones de la columna examinando la columna relativa es muy aburrido y poco claro. ¿Por qué no lo conviertes en un gráfico como el que hay al principio de esta página?
Corta y pega en el editor de RStudio el bloque de código que hay a continuación. Puedes ejecutarlo ya, pero te recomiendo que leas las explicaciones que hay debajo de la caja para que sepas que hace cada línea.
ggplot(resultado, aes(x = fecha, y = relativa, color = caso)) +
#geom_line() +
#geom_point() +
geom_smooth(se = FALSE, method = "loess", size = 1.5) +
labs(
title = "Casos de 'f-' y 'h-' por año",
x = "Año de impresión",
y = "%",
color = ""
) +
scale_x_continuous(breaks = unique(resultado$fecha)) +
theme_minimal() +
theme(axis.text.x = element_text(angle = 30, vjust = 0.5, hjust = 1))Es una orden muy compleja, pero sencilla a la vez. Te explico qué hace en cada una de las líneas, incluso las que he marcado con # para que las ignore. Juega tú con ellas para ver cómo cambia el resultado.
La instrucción básica es ggplot(), que es la que se encarga de dibujar el gráfico. Le estás pidiendo que utilice el contenido de la tabla resultado y con la ayuda del argumento aes le indicas:
- que quieres que en el eje horizontal,
x, esté la información relativa a los años, la cual está recogida en la columnafecha; - que en el eje vertical,
y, marque la frecuencia relativa de cada caso, lo que se encuentra en la variablerelativa; - que coloree las líneas de acuerdo a los valores que pueda haber en
caso; en este caso solo usará dos colores: uno para la línea deFy otro para la deH.
Si quieres hacer un gráfico como el que hay al principio de esta página, quita el # que hay antes de geom_line(). Tendrá el aspecto de los dientes de una sierra. Si le quitas el # a geom_point() dibujará un punto exacto de los valores de cada caso, que coincidirán con los picos de la línea que se traza con geom_line().
Con puntos y líneas como lo hace geom_line() queda un poco oscurecida la tendencia, por eso he usado geom_smooth(se = FALSE, method = "loess", size=1.5). Esta instrucción dibujará unas líneas más suaves. El último argumento, size=1.5 lo que hace es dibujar la línea un poco más gruesa. Prueba a ver la diferencia con y sin ese argumento (si lo borras, quita la coma que hay antes de él, o tendrás un problema).
labs se encarga del pie o título del gráfico, además imprimirá en el eje x una leyenda que informará a quien vea la gráfica de qué datos hay en ese eje, y en y cómo se han de entender los valores numéricos del eje vertical. color se encarga de la leyenda que explique la clave de los colores. He preferido dejarla en blanco pues el significado es evidente.
La línea scale_x_continuous(breaks = unique(resultado$fecha)) se encarga de imprimir en el eje horizontal los años. La instrucción theme_minimal() se ocupa del color del fondo y de las líneas de la cuadrícula del gráfico (si pones un # delante de esta línea y vuelves a ejecutar el código, el fondo del gráfico será gris claro). La última línea hace que los números de los años se impriman con una pequeña inclinación para que sea más fácil leerlos, puesto que si los hubiera puesto horizontales habría muy poco espacio entre unos y otros.
16.3 Conclusión
Aquí tienes el gráfico. Elegante e interesante. Ya solo falta interpretarlo y establecer las conclusiones.

Las posibilidades de análisis son tremendas. Solo tienes que extraer los datos que quieres estudiar y representarlos con el gráfico que mejor te convenga.
Ya sabes cómo obtener los datos de OSTA y cómo analizarlos. Ahora te propongo un reto: observar como se comportan los resultados de F- entre 1472 y 1520, que es el periodo la primitiva imprenta y que los espacialistas dividen en dos épocas: incunables y post-incunables. Los datos de los incunables ya los tienes, ahora tienes que recolectar los de los post-incunables. Aquí la complicación es unir las tablas individuales de a, b, c, d de los datos de los incunables y las de los post-incunables. Yo usaría aa, bb, cc y dd para los post-incunables. Para unirlas debes utilizar la expresión a <- bind_rows(a, aa) así unirás a y aa en a, y así sucesivamente. Acuérdate de renombrar los datos cuando los descargues de OSTA de la misma manera que nombraste los de los incunables.
