B Expresiones regulares
B.1 Introducción
En varios lugares a lo largo de este libro he hablado y utilizado las Expresiones regulares. No me he detenido en explicar qué son y cómo funcionan con detalle. No es que lo vaya hacer en este apéndice. El sistema, en verdad, requeriría un libro aparte. Tan solo voy presentar las nociones básicas necesarias para que puedas enfrentarte con búsquedas y reemplazos complejos, como has visto en algunos de los capítulos anteriores. Lo vas hacer de forma práctica, pero no dentro de RStudio. Para este apéndice solo necesitas un editor de texto plano.
Si usas un ordendador Windows el mejor editor de textos planos es NotePad++. Lo puedes descargar de https://notepad-plus-plus.org/downloads/. Si en cambio usas un ordenador de Apple lo mejor es BBEDit si tienes un sistema operativo Mojave o posterior y lo puedes descargar de https://www.barebones.com/products/bbedit/download.html. Aparentemente es de pago, pero puedes usarlo pasado el tiempo de prueba, aunque no tendrás acceso a las funcionalidades de última generación, que no te serán vitales. Si tienes un ordenador con un sistema operativo anterior a Sierra (10.12.6) puedes instalar TextWrangler, que es casi lo mismo, desde esta otra dirección https://www.barebones.com/support/textwrangler/updates.html.
Hay otros editores de texto plano gratuitos como Atom, Geany, Visual Studio Code que valen tanto para Windows como para Mac. Elige tú el que mejor se adecue a tus necesidades y a tu sistema operativo.
B.2 Manos a la obra
Vas a descargarte tres ficheros en texto plano del repositorio de 7PartidasDigital. Uno es una copia de Zaragoza, uno de los Episodios Nacionales de Benito Pérez Galdós. Otro es un texto medieval que corresponde a una vieja ordenanza municipal otorgada por don Juan Manuel en 1345, el tercero es una lista de los 350 miembros del congreso de los diputados (XIV Legislatura). Vas a guardarlos en el directorio datos/. Lo vas a hacer con estas instrucciones de R que leerán y grabrán secuencialmente los ficheros. Hacerlo así tiene la ventaja de que se grabarán con el sistema de codificación que tenga el ordenador que uses, por lo que no tienes que preocuparte por los problemillas de codificación.
library(readr)
zaragoza <- read_lines("https://github.com/7PartidasDigital/AnaText/blob/master/datos/textos/zaragoza.txt",
locale = default_locale())
write_lines(zaragoza, "datos/zaragoza.txt")
ordenanza <- read_lines("https://github.com/7PartidasDigital/AnaText/blob/master/datos/textos/ordenanza1345.txt",
locale = default_locale())
write_lines(ordenanza, "datos/ordenanza1345.txt")
diputados <- read_lines("https://github.com/7PartidasDigital/AnaText/blob/master/datos/textos/diputados.txt",
locale = default_locale())
write_lines(diputados, "datos/diputados.txt")Abre el fichero zaragoza.txt con el editor de texto plano que tengas. Tan pronto lo tengas en pantalla, verás que hay espacios en blanco en medio de las líneas y hay muchas líneas en blanco, como puedes ver en la figura B.1. El mayor problema es que hay una mezcla de espacios en blanco y tabuladores. Los espacios en blanco –los que introduces con la barra espaciadora– se podrían quitar con relativa sencillez con buscar y reemplazar, pero los tabuladores ya son harina de otro costal. Sin embargo, los puedes eliminar con facilidad y todos a la vez, sean espacios o sean tabuladores, por medio de un buscar y reemplazar, pero especial, con una expresión regular.
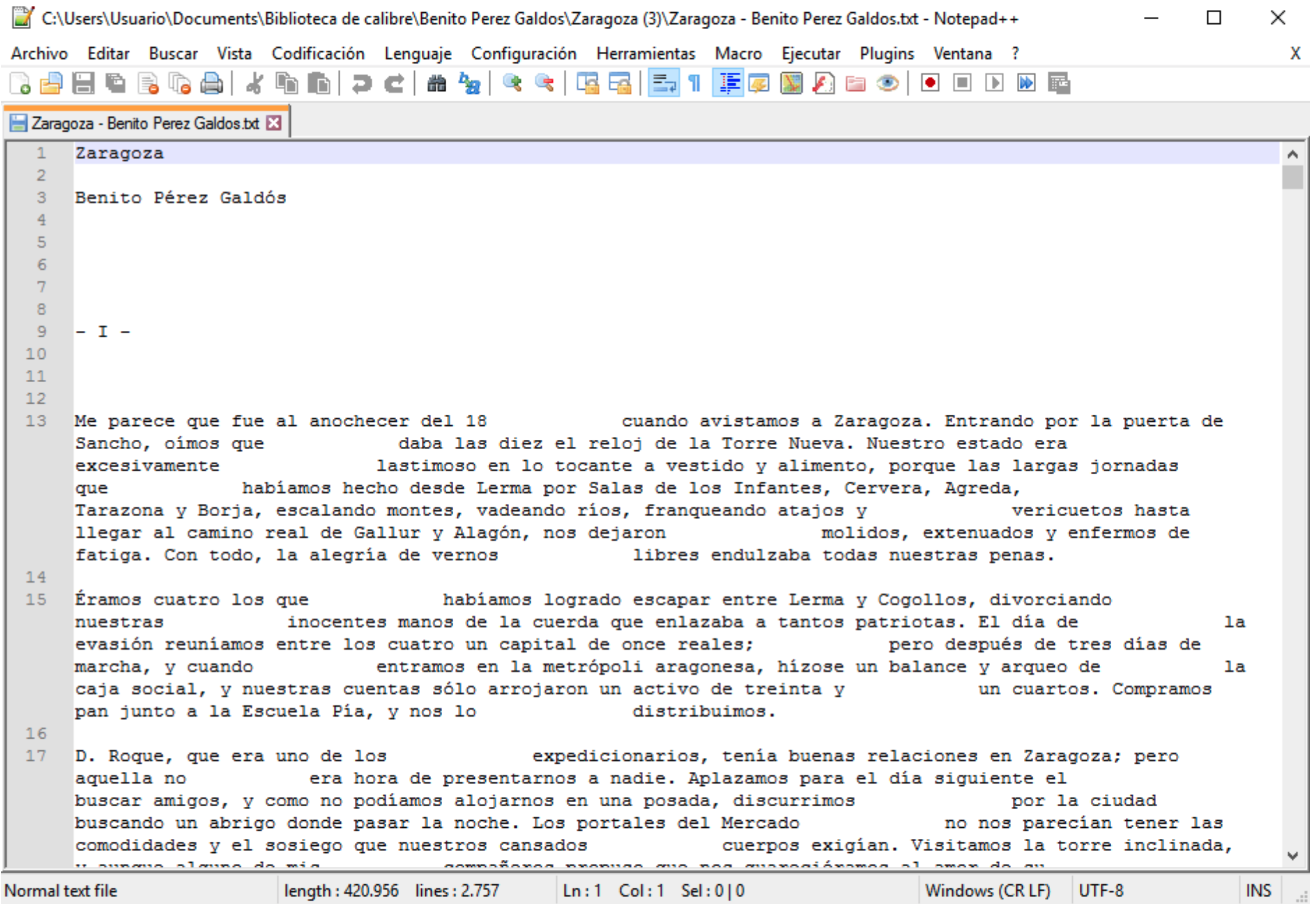
Figura B.1: Pantallazo de NotePad++ con el fichero zaragoza.txt
B.3 Expresiones regulares
Supongo que alguna vez habrás hecho búsquedas en alguno de los dos corpus de la Real Academia Española: el CORDE o el CREA. Si lo has intentado, habrás visto que son muy pobres porque solo cuentan con los comodines * y ? y, como refinamiento, permite los operadores lógicos (AND, OR, NOT) y el operador de distancia DIST/. Los resultados pueden ser paupérrimos en el CORDE puesto que al tratarse de un corpus histórico una palabra puede aparecer escrita de varias formas. Por ejemplo, la tercera persona del presente de indicativo del verbo dezir, decimos, puede documentarse como dezimos y como dezjmos. En el CORDE sería fácil localizarlas, bastaría con poner dez?mos y nos daría todas las posibilidades (aparecerá una rara: dezemos del portugués). Ahora bien, a lo largo de la historia del español se ha cambiado la grafía de z a c con el paso intermedio de ç debido a la desonorización de /dz/ y la consiguiente confusión de grafías. Eso ya no lo podrías obtener con los comodines puesto que de??mos puede extraer como resultados: dezimos, devimos, deximos, devamos, dexamos, etc. Además, tampoco nos permite localizar los datos cuando la inicial es mayúscula. Si el CORDE permitiera expresiones regulares podrías extraer todas las formas gráficas posibles de la primera persona del plural del verbo decir con una sencilla orden (o quizá no tan sencilla).
Cierra el fichero zaragoza.txt y abre el llamado ordenanza1345.txt. Vas a buscar todos los casos de la primera persona del plural del presente de indicativo del verbo decir. Invoca buscar con control + f (cmd + f en Mac). En la casilla Buscar (Find what o Find) introduce
dezimosy pulsa Contar (Count; en Mac pulsa el botón Find all). En la parte baja de la ventana de buscar deberá decir Count: 3 matches; en Mac se abrirá una nueva ventana con los resultados y dirá que hay 3 ocurrences of "dezimos" found in 1 file. Eso se debe a que solo se le ha pedido que busque ese literal, y tan solo ha localizado tres casos. Pero durante mucho tiempo, la vocal i se podía escribir también como una j, por lo que deberías comprobar si hay casos de dezjmos. Introduce ahora
dezjmosAparecerá un total de 12 ocurrencias (no indico desdee ahora, salvo que sea necesario, si es un ordenador Windows o Mac, los resultados tienen que ser idénticos). Ahora deberías comprobar si hay casos la forma deçimos y también deçjmos, e incluso de decimos y decjmos. Pero, además, pueden aparecer con la primera letra en mayúscula. A estas alturas ya no sabrás cuantas hay de cada tipo, pues hay un mínimo de doce formas gráficas posibles. Este problema se puede resolver con una expresión regular. Copia ahora en la casilla de búsqueda lo siguiente
[Dd]e[çcz][ij]mosPero antes de pedirle al editor que las cuente o las localice, hay que indicarle al programa que debe hacer una búsqueda especial. En NotePad++ selecciona en Modo de Búsqueda (Search Mode) la opción Expresión regular (Regular expression). Cuando pulses Contar (Count) deberá presentar el resultado 15. En un Mac con BBEdit / TextWrangler deberás marcar la casilla (segunda línea desde abajo de la ventana de búsqueda) que dice Grep. El resultado será también 15.
Lo que has hecho ha sido decirle que busque toda secuencia que comience por D o d, y esta disyuntiva se expresa encerrando los caracteres entre corchetes, que en la segunda posición haya una e; que en la tercera posición haya una de estas tres: ç, c, o z, en la cuarta puede haber una i o una j (podrías considerar la existencia de casos con y –dezymos–). Lo que acabas de usar es una expresión regular.
Las expresiones regulares, generalmente conocidas por los informáticos como RegEx, son patrones que permiten hacer búsquedas y sustituciones en los textos detectando secuencias de caracteres que cumplan una condición dada (por ejemplo, contener unos caracteres y no otros, comenzar o terminar por una secuencia de caracteres determinada, ir precedido o no por una serie de caracteres, contener ciertos caracteres optativos, estar al principio o al final de la línea, etc.). Las expresiones regulares son una forma de búsqueda más compleja y sofisticada, aunque similar a las búsquedas con comodines. A unos lingüistas computacionales les oí decir en una ocasión que era «una búsqueda con comodines pero con esteroides» y eso, los esteroides lo hace un poco más complicado de manejar y aprender, pero cuando empeizas a usarlas te preguntarás ¿cómo he podido virvir sin ellas?
Cierra el fichero ordenanza1345.txt y abre en el editor el llamado diputados.txt. Este es una de los 350 diputados que fueron elegidos en las elecciones de noviembre de 2019. La lista consta de los apellidos, el nombre de pila, el grupo político al que está adscrito cada uno de ellos y la circunscripción por la que fue elegido.
Analicemos un poco el contenido. Podrás observar que los apellidos están separados del nombre de pila por una coma y un espacio en blanco. También hay espacio en blanco entre el nombre de pila y el grupo político y entre este y la circunscripción. Pero estos espacios en blanco son, en realidad, tabuladores, con lo que ya tienes un patrón bastante claro en la conformación de esta lista:
Apellido Apellido, Nombre de pila TAB grupo TAB circunscripciónLo primero que vas a hacer es obtener solo la lista de los nombres (Apellidos, Nombre). Esto supone borrar desde el tabulador que hay tras el nombre de pila hasta el final de cada línea, para que te quede una lista como esta (solo es el principio):
Ábalos Meco, José Luis
Abascal Conde, Santiago
Aceves Galindo, José Luis
Agirretxea Urresti, Joseba Andoni
Aizcorbe Torra, Juan José
Aizpurua Arzallus, Mertxe
Alcaraz Martos, Francisco José
Alfonso Cendón, Javier
Almodóbar Barceló, Agustín
Alonso Pérez, José Ángel
. . . . . .Después vas a rescribir la lista para que se pueda leer de esta manera (solo te presento los seis primeros):
José Luis Ábalos Meco, del grupo Socialista, obtuvo el escaño por la circunscripción de Valencia.
Santiago Abascal Conde, del grupo Vox, obtuvo el escaño por la circunscripción de Madrid.
José Luis Aceves Galindo, del grupo Socialista, obtuvo el escaño por la circunscripción de Segovia.
Joseba Andoni Agirretxea Urresti, del grupo Vasco (EAJ-PNV), obtuvo el escaño por la circunscripción de Guipúzcoa.
Juan José Aizcorbe Torra, del grupo Vox, obtuvo el escaño por la circunscripción de Barcelona.
Mertxe Aizpurua Arzallus, del grupo EH Bildu, obtuvo el escaño por la circunscripción de Guipúzcoa.
. . . . . . . . . .Hacerlo a mano sería una pesadilla. En Word es posible, pero complicadillo, pues usa su propio sistema. Si te quieres aventurar, la posibilidad de usar reglas de expresión está tras la etiqueta Usar caracteres comodín del menú Buscar y reemplazar.
Vamos con el primer problema. Quieres borrar todo lo que haya tras el nombre de pila hasta el final de la línea. Sabes que tras el nombre de pila hay un tabulador. La expresión regular para borrar todo lo que haya desde ese tabulador hasta el final de la línea es:
\t.+Compruébalo. Invoca buscar y reemplazar (control / cmd + F) en el editor de textos. En la casilla buscar escribe \t.+ y la de reemplazar déjala en blanco. Marca, si no lo está, la casilla Expresión regular (Grep en BBEdit / Textwrangler) y pulsa reemplazar todo. Verás que solo quedan los apellidos y los nombres de pila.
Lo que has hecho ha sido pedirle a la máquina que busque un tabulador \t (la primera ocurrencia) y que borre todo lo que haya tras él, lo que se le indica con un punto ., lo que equivale a decirle que busque cualquier carácter ya sea letra, número, espacio en blanco, símbolo, signo de puntuación, emoticono, etc. que pueda haber a continuación. Puesto que después del tabulador hay más de un carácter, utilizo el cuantificador + que le indica que pueden ser 1 o infinitos. Si no estuviera seguro de que tiene que haber al menos un carácter después del tabulador, debería de haber usado *, que quiere decir cero o infinitos caracteres.
La \ barra le indica a la máquina de búsqueda que lo que hay a continuación no es una t como la que escribes con el teclado, sino que se trata de un metacarácter. Hay varios metacaracteres con significados muy precisos: \d indica los números; \w cualquier carácter alfanumérico (letra, número y el guion bajo); \s representa cualquier espacio en blanco (ya sea el que introduces con la barra espaciadora, el tabulador, el cambio de línea –este tiene el suyo propio \n–, el retorno de carro (algo que queda de las viejas máquinas de escribir) –también tiene su metacarácter propio \r–).
Las letras en mayúscula indican todo lo contrario. Así, \D quiere decir todo menos los dígitos; \W todo menos los caracteres alfanuméricos y el guion bajo; \S cualquier carácter que no sea un espacio en blanco.
Has visto que para indicarle que capture cualquier carácter debe usar el . y el cuantificador es + o *. Cuando quieras usar cualquiera de estos signos para representarse a sí mismo, es decir, como un punto, el signo más o el asterisco, debes anteponerles la \ para que la máquina los interprete adecuadamente como esos signos (\., \+, \*), no como metacaracteres (lo mismo sucede, ya lo verás un poco más adelante, con los corchetes, los paréntesis y las llaves; cuando quieras usarlos para buscarlos tendrás que anteponerles la \: \[, \], \(, \), etc.).
R hay que usar una doble barra para indicar estos metacaracteres. Es una pequeña rareza con la que tendrás que vivir. Así, en R la expresión de búsqueda será \\t.+, mientras que en los editores es \t.+. Tenlo en cuenta, pues puedes pasarte un buen rato preguntándote porqué no funcionó algo como esperabas.
Vamos con el segundo problema: reorganizar los nombres de todas sus señorías para que primero tengamos el nombre de pila y después los apellidos.
Aquí la cuestión es capturar y guardar temporalmente todo lo que haya antes de la coma, y todo lo que haya tras la coma y el espacio hasta el final de la línea e invertirlo, es decir, poner primero el nombre y después los apellidos. La forma de capturar algo es encerrándolo entre paréntesis (LO QUE CAPTURARÁ). Lo primero que quieres capturar es todo lo que haya antes de la coma. Ya te he dicho que todo lo que haya, sea lo que sea, se expresa con .+ (uno o más caracteres cualesquiera) o .* (cero o más). Luego la primera parte de la expresión de búsqueda es (.*).
Si introduces eso en la casilla de búsqueda y le haces clic en buscar (ni se te ocurra darle a reemplazar), verás que marca todo lo que haya en cada línea. Vamos delemitar el alcance de la captura añadiendo tras el paréntesis la , y el espacio en blanco , que son los elementos que separan nítidamente los apellidos y el nombre de pila. Si le das a buscar, seleccionará todo hasta el espacio en blanco.
Ahora vas a capturar ahora el nombre de pila. El proceso es el mismo. Necesitas los paréntesis para guardarlos temporalmente () y la secuencia .* para que recoja todo lo que haya desde el espacio en blanco hasta el final de la línea.
La expresión regular completa es (.*), (.*) que lo que hará, en pocas palabras, es formar un grupo con todo lo que haya antes de la coma, y otro con todo lo que haya tras la coma y el espacio. Ahora viene la magia: invertir los apellidos y el nombre.
Lo que has guardado en cada juego de paréntesis lo puedes recuperar con una barra inclinada \ y el número del grupo. Cada juegos de paréntesis recibe internamente un número, el primero es el \1, el segundo el \2 y así hasta \99. Para invetirlos (reorganizarlos), escribe en la casilla de reemplazar \2 \1 y haz clic en reemplazar todos. El resultado tiene que ser (solo te muestro los diez primeros):
José Luis Ábalos Meco
Santiago Abascal Conde
José Luis Aceves Galindo
Joseba Andoni Agirretxea Urresti
Juan José Aizcorbe Torra
Mertxe Aizpurua Arzallus
Francisco José Alcaraz Martos
Javier Alfonso Cendón
Agustín Almodóbar Barceló
José Ángel Alonso Pérez
. . . . . . . .Vamos con lo más complicado, crear las frases del tipo
José Luis Ábalos Meco, del grupo Socialista, obtuvo el escaño por la circunscripción de Valencia.
Santiago Abascal Conde, del grupo Vox, obtuvo el escaño por la circunscripción de Madrid.
José Luis Aceves Galindo, del grupo Socialista, obtuvo el escaño por la circunscripción de Segovia.
Joseba Andoni Agirretxea Urresti, del grupo Vasco (EAJ-PNV), obtuvo el escaño por la circunscripción de Guipúzcoa.
Juan José Aizcorbe Torra, del grupo Vox, obtuvo el escaño por la circunscripción de Barcelona.
Mertxe Aizpurua Arzallus, del grupo EH Bildu, obtuvo el escaño por la circunscripción de Guipúzcoa.
. . . . . . .Partirás de la lista original:
Ábalos Meco, José Luis Socialista Valencia
Abascal Conde, Santiago Vox Madrid
Aceves Galindo, José Luis Socialista Segovia
Agirretxea Urresti, Joseba Andoni Vasco (EAJ-PNV) Guipúzcoa
Aizcorbe Torra, Juan José Vox Barcelona
Aizpurua Arzallus, Mertxe EH Bildu Guipúzcoa
. . . . . .Como ahora tendrás en la pantalla una versión modificadísima del fichero original, vuelve a cargarlo desde el disco, de otro modo no funcionaría lo que sigue porque no cumpliría los patrones. La regla de búsqueda es:
(.*?), (.*?)\t(.*?)\t(.*)que quiere decir, busca todo lo que haya antes de la coma y guárdalo (.*),. Después localiza y guarda todo lo que haya entre la coma y el espacio en blanco y el primer tabulador , (.*)\t. A continuación captura todo lo que haya entre los dos tabuladores \t(.*)\t. Por último guarda todo lo que haya tras el segundo (y último) tabulador. Por lo tanto, tienes cuatro grupos:
- Apellidos
- Nombre
- Grupo político
- Circunscripción
Ahora solo tienes que escribir en la casilla reemplazar el orden en que quieres recolocar los elementos y los literales que quieres añadir: , del grupo y , obtuvo el escaño por la circunscripción. Lo que debes poner en la casilla de reemplazo es:
\2 \1, del grupo \3, obtuvo el escaño por la circunscripción de \4.Haz clic en reemplazar todo. Fíjate con que poco esfuerzo has conseguido quedarte con solo una parte de la lista, invertir el orden de los elementos e incluso reescribirla.
Lo que ha hecho ha sido poner en primer lugar el nombre, que lo tienes guardado en \2, pones un espacio en blanco e introduces los apellidos que los tienes guardados en el \1, escribes el primer literal , del grupo y le dice que incorpore el grupo político, que está almacenado en \3. Por último introduces el último literal y el valor de la circunscripción que tienes guardada en \4 y cierras cada frase con un ..
B.4 Eliminar las etiquetas HTML de una página
Con las expresiones regulares puedes hacer muchísimas cosas. Ahora vas a acceder a una página web, la vas a guardar en tu ordenador y vas a eliminar todas las etiquetas HTML que tiene la página. Al final tendrás un texto plano con el que podrás hacer otras cosas. Vamos ello.
Con un navegador ve a http://www.aic.uva.es/clasicos/juanmanuel/juanmanuel-edicion.html. Guarda esa página en el ordenador. Basta pulsar el botón derecho del ratón y seleccionar Guardar como. Aquí lo más delicado es seleccionar el tipo. Despliega y selecciona Página web (solo HTML). (Ponle un título un poco más sencillo y claro que el que da por defecto). Guárdalo y sal del navegador. Busca el fichero donde lo hayas guardado (posiblemente esté en la carpeta de descargas) y ábrelo con NotePad++ (o BBEdit / Textwrangler). Verás que está lleno de códigos HTML escritos en azul, rojo y morado (en Mac el esquema de colores puede ser diferente) que se encuentran entre < y >, como puedes ver en la figura B.2.
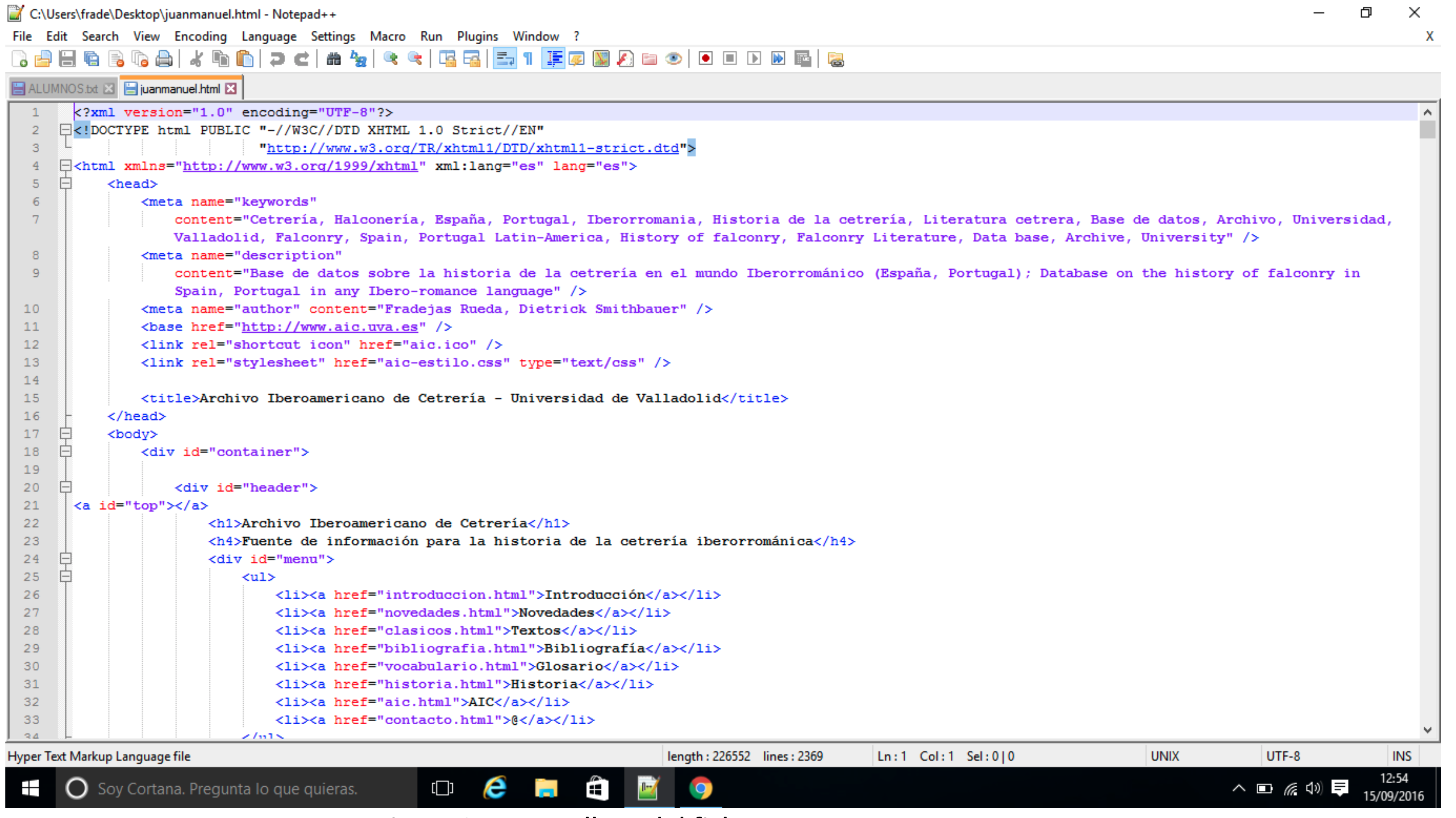
Figura B.2: Pantallazo del código de la página HTML en NotePad++
Tienes que retirarlos, es decir, tienes que dejar tan solo el texto. ¿Cómo lo harías? Pista: tan solo hacen falta 8 símbolos y tres están repetidos. Introduce en Buscar (Find what) la expresión
<[^<>]+>y deja en blanco la casilla Reemplazar con (Replace). Marca la casilla Expresión regular (Grep en Mac) y por último haz clic en Reemplazar todo (Replace all).
En este caso lo que se le ha pedido a la máquina es que busque cualquier secuencia de caracteres (encerrado entre corchetes [ ]) que no (lo expresa el acento circunflejo ^) sean < ni >, es decir, puede ser cualquier símbolo o letra salvo esos dos, que pueden aparecer una o más veces (el signo +) y que esté encerrado entre < y >, por eso le has dicho que no debía de tener < ni >. Tan pronto como hagas clic en reemplazar todo, todas las etiquetes HTML habrán desaparecido.
Para finalizar de preparar este texto bastaría con eliminar los espacios en blanco que han quedado en el comienzo de cada línea, puede haber 1 o más y no sabes si son espacios introducidos con la barra espaciadora, tabuladores, líneas en blanco, etc. En la casilla Buscar (Find) se introduce
^\s+se deja reemplazar en blanco y se hace clic en Reemplazar todo.
En esta ocasión le has indicado a la máquina que busque cualquier secuencia de espacios en blanco (expresado por \s), incluidas las líneas en blanco, que estén al principio de la línea (el acento circunflejo ^; antes viste que ^ valía para negar; ¡doble uso!) y que puede aparecer una o más veces, lo que se indica con el +.
En realidad, no está totalmente limpio. Al principio, y también al final, quedan unas frases y una lista de números. Eso lo puedes considerar como los metadatos del fichero y pueden permanecer (mira el apartado siguiente). Sin embargo, aún queda algo de polvo. Cada cierto número de líneas se encuentra la palabra «Arriba».
Escribe una expresión regular que sirva para eliminarla, pero ten en cuenta que la palabra «arriba» puede aparecer en el texto. Solo te interesa borrar las que se encuentren en una línea aislada.La solución es muy sencilla. Basta con poner en la casilla de búsqueda ^Arriba$ y dejar la casilla de reemplazo en blanco. Esta expresión buscará la palabra Arriba siempre que esté al comienzo de línea ^ y sea la última palabra de la línea $. El problemilla con esto es que deja líneas en blanco que tendrías que borrar con una nueva búsqueda con ^\s+, que borraría todas las líneas en blanco. Pero puedes ahorrarte el paso si en vez de poner $ pones \R (en los ordenadores Windows tiene que ser la secuencia \n\r, mientras que en los Mac / Linux tan solo es \n). En este caso borra la palabra Arriba y el cambio de línea, con lo que borra la línea en blanco.
B.5 Borrar un grupo de líneas
Vamos a complicar un poco la cosa. Vuelve a limpiar el fichero que has bajado de la red y guárdalo en el ordenador. Ábrelo de nuevo y observa que las primeras líneas dicen:
Archivo Iberoamericano de Cetrería - Universidad de Valladolid
Archivo Iberoamericano de Cetrería
Fuente de información para la historia de la cetrería iberorrománica
Introducción
Novedades
Textos
Bibliografía
Glosario
Historia
AIC
@
Textos clásicos
Juan Manuel
Libro de la caza
Introducción
Bibliografía
Texto
prologo
tabla
1
2
3
4
5
6
7
8
9
10
11
12y las últimas:
Edición de José Manuel Fradejas Rueda
Creación / última revisión: 28.05.2013
Editor: José Manuel FRADEJAS RUEDA
© 2006–2017, Archivo Iberoamericano de Cetrería
Universidad de Valladolid
ISSN 1887–5343
Los
contenidos del Archivo Iberoamericano de
Cetreríase publican bajo una licencia Creative Commons
Attribution-NonCommercial 3.0 Unported License.Esos dos bloques de líneas los puedes borrar con sendas expresiones regulares. Son muy breves, pero complicadillas. La primera expresión borrará todo lo que haya desde el principio del fichero hasta la primera ocurrencia del número 12. La segunda borrará todo desde Edición de hasta el final del fichero. En embos casos debes dejar vacía la casilla reemplazo para lograrlo.
La expresión para el primer paso es:
\A(?s).*?12(?-s).*\RLa adecuada para el segundo, hasta el final del fichero es:
^Edición de(?s).*Ha funcionado, ¿verdad? Vamos con la explicación. El metacarácter \A le indica a la máquina de búsqueda que se sitúe en antes del primer carácter del fichero. El modificador (?s) le indica que el siguiente . ha de capturar cualquier carácter, incluido los de fin de línea, los cuales no captura . de por sí. Con esto lo que le estás diciendo a la secuencia .*? es que localice todas las líneas contengan lo que contengan hasta que llegue al primer 12. Si no le pones la ? se comería todo hasta el último 12 que pudiera haber en el fichero. (¡Pruébalo!) El siguiente modificador (?-s) lo que le dice a la máquina es que el siguiente . que vea vuelve a tener en cuenta tan solo los caracteres que no sean de cambio de línea. El último metacarácter \R, como ya te he mostrado, sirve para considerar cualquier secuencia de cambio de línea, con lo que es válida para cualquier máquina, ya sea Windows, Apple o Unix.
La segunda expresión comienza con un ^ porque la palabra que quieres localizar como inicio del patrón ha de ser la primera de la línea en la que comienza lo que quieres borrar. Tras las secuencia de caracteres que te sirven de ancla para el patrón, Edición de, introduces el modificador (?s) que le dice a la máquina de búsqueda que el punto . que hay a continuación sirve para capturar todos los caracteres, sean cuales sean, incluidos los cambios de línea hasta el final del fichero *.
Si ahora revisas el principio y el final del fichero, comprobarás que ha desaparecido todo ese material de una manera ´rapida y relativamente sencilla.
B.6 Conclusión
Como acabas de ver, las expresiones regulares son una poderosa herramienta que puede ahorrarte mucho tiempo. Pero también es muy peligrosa, sobre todo cuando la utilizas para modificar grandes cantidades de ficheros pues, por ejemplo, tanto NotePad++ como BBEdit / Textwrangler permiten buscar y reemplar en ficheros que tengas en un directorio sin tenerlos que abrir uno a uno y efectuar las búsquedas y los reemplazos. Así que un aviso: ten siempre copias de seguridad de los materiales. En milisegundos puedes quedarte sin los datos duramente recolectados y preparados.
Si quieres más información y formación sobre las expresiones regulares, en la red puedes encontrar numerosos tutoriales que explican cómo usarlas. En Wikipedia hay una buena introducción en español https://es.wikipedia.org/wiki/Expresión_regular. Webs de referencia rápida, pero en inglés, son http://www.rexegg.com/regex-quickstart.html y https://www.regular-expressions.info/quickstart.html. También hay un librito, en inglés, que es muy útil; es el de Tony Stubblebine, Regular Expressions. Pocket reference (Sebastopol: O’Reilly, 2007).
