12 Palabras favoritas
12.1 Introducción
Una de las cosas que a primera vista me atrajo del libro de Ben Blatt (2017) fue el título: Navokov’s Favourite Word is Mauve. Mi pregunta era cómo pudo determinar cuál era la palabra predilecta de un autor. Es más, en muchos análisis estilísticos de muchos autores se llega a afirmar que prefieren unos u otros términos. Lo malo de esos estudios es que no razonan ni explican cómo establecen cuáles son esos términos predilectos, a veces es una mera selección manual según el gusto del investigador.
Blatt (2017: 164-176) explica cómo establecer las palabras favoritas de un autor –cinnamon word– y aquellas que repite una y otra vez hasta el punto de que todos nos damos cuenta (Blatt 2017: 172) –nod word– y lo hace con relación al Corpus of Historical American English https://www.english-corpora.org/coha/.
Hay otra manera para establecer cuáles son las palabras características de un texto dentro de un corpus y que puede servir para establecer el tema, por lo que está estrechamente relacionado con el Topic Modeling que has visto en un capítulo anterior. Se trata de un procedimiento que se conoce por las siglas TF-IDF (= term frequency - inverse document frequency) que se obtiene multiplicando dos métricas: cuántas veces aparece una palabra en un documento (TF) y la frecuencia inversa del documento de la palabra en un corpus determinado.
12.2 TF-IDF
La frecuencia de los términos (TF) de un texto se puede calcular de varias maneras. La más sencilla es hacer el recuento de las veces que cada palabra aparece en un texto. Después hay que ajustar la frecuencia, bien en virtud de la longitud del texto, o bien teniendo en cuenta las frecuencias absolutas de las palabras más frecuentes en un texto.
La frecuencia inversa del documento (IDF) de la palabra a lo largo del corpus lo único que quiere decir es cuán rara o cuán común es una palabra dentro de un corpus. Esta métrica se calcula tomando el número total de documentos en el corpus, dividiéndola por el número de documentos que contienen la palabra y calculando el logaritmo. De manera que si la palabra es muy común y aparece en muchos documentos, el resultado estará muy cerca de 0. En cambio, si es muy rara se aproximará a 1.
Para mostar cómo funciona vas a experimentar con los guiones de la serie El Ministerio del Tiempo. Como es de suponer lo primero es preparar el entorno con las librerías básicas
Como los resultados serán números decimales que oscilarán entre 0 y 1 lo más probable es que los presente en notación científica. Para evitarlo se lo indicas a R con
Ahora ya solo te falta cargar el texto de los 34 episodios de las tres primeras temporadas de El Ministerio del Timepo12. Aunque los tienes en la red, en la web de RTVE, son un conjunto de pdf bastante complicados en su disposición, por lo que los he preparado bajo el formato de una gran tabla con cinco columnas: temporada, episodio, titulo, personaje y texto. El valor de temporada es 1, 2 o 3. El de episodio un entero entre 1 y 34. En titulo está guardado el título de cada episodio. Como es de suponer, cuando estén disponibles los guiones de la cuarta temporada, los valores de estas variables cambiarán. En personaje tienes el nombre del personaje que habla en cada momento, y son cerca de 580, un buen elenco, pero de los que solo siete intervienen más de 1000, aunque eso no quiere decir que quien más intervanga (Alonso tiene 1946 intervenciones) sea el que más hable (Salvador, que es el cuarto que más interviene, en 1590 ocasiones, pero es el que más palabras pronuncia, el 11.5 % de todas las empleadas a lo largo de toda la serie). Por último, en la variable texto está lo que cada uno de los personajes dice en cada momento de la serie, es decir, los diálogos. Están excluidos los encabezados de secuencia, las indicaciones de acción, las acotaciones y las notas de transición.
En esta tabla se separó cada una de las columnas con un tabulador, por lo que la has de cargar con la instrucción read_tsv
MdT <- read_tsv("https://raw.githubusercontent.com/7PartidasDigital/AnaText/master/datos/textos/MdT.txt")También podrías haberlo hecho con read_delim(), pero en este caso tendrías que añadir el argumento delim = "\t" para indicarle cuál es el elemento que separa las columnas.
MdT <- read_delim("https://raw.githubusercontent.com/7PartidasDigital/AnaText/master/datos/textos/MdT.txt",
delim = "\t")Con cualquiera de las dos instrucciones lo que responderá la consola será:
## Rows: 18178 Columns: 5
## ── Column specification ─────────────────────────────────────
## Delimiter: "\t"
## chr (3): titulo, personaje, texto
## dbl (2): temporada, episodio
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Tienes, ahora mismo, en el objeto MdT una tabla con cinco variables y 18178 observaciones. Échale una ojeada con
lo que imprimirá la cabecera de la tabla y la información básica de la misma.
## # A tibble: 18,178 × 5
## temporada episodio titulo personaje texto
## <dbl> <dbl> <chr> <chr> <chr>
## 1 1 1 El tiempo es el que es CAPITÁN ¡Atac…
## 2 1 1 El tiempo es el que es ALONSO Porqu…
## 3 1 1 El tiempo es el que es CAPITÁN ¿Tené…
## 4 1 1 El tiempo es el que es ALONSO Si lo…
## 5 1 1 El tiempo es el que es CAPITÁN Mentí…
## 6 1 1 El tiempo es el que es ALONSO Yo nu…
## 7 1 1 El tiempo es el que es CAPITÁN ¡Pren…
## 8 1 1 El tiempo es el que es ALONSO ¡¡Tod…
## 9 1 1 El tiempo es el que es BLANCA ¿Por …
## 10 1 1 El tiempo es el que es ALONSO ¡Como…
## # ℹ 18,168 more rowsComo los títulos de los episodios se repiten una media de 535 veces, aunque tan solo son 34, vas a transformar el tipo de datos de la columna titulos de chr en fct para manejarlos con mayor facilidad. Lo consigues con
Si imprimes la cabecera de la tabla con
podrás ver que la caracterización de la columna titulo ha pasado de <chr>, que viste un poco antes, a <fct>.
## # A tibble: 18,178 × 5
## temporada episodio titulo personaje texto
## <dbl> <dbl> <fct> <chr> <chr>
## 1 1 1 El tiempo es el que es CAPITÁN ¡Atac…
## 2 1 1 El tiempo es el que es ALONSO Porqu…
## 3 1 1 El tiempo es el que es CAPITÁN ¿Tené…
## 4 1 1 El tiempo es el que es ALONSO Si lo…
## 5 1 1 El tiempo es el que es CAPITÁN Mentí…
## 6 1 1 El tiempo es el que es ALONSO Yo nu…
## 7 1 1 El tiempo es el que es CAPITÁN ¡Pren…
## 8 1 1 El tiempo es el que es ALONSO ¡¡Tod…
## 9 1 1 El tiempo es el que es BLANCA ¿Por …
## 10 1 1 El tiempo es el que es ALONSO ¡Como…
## # ℹ 18,168 more rowsTe he dicho hace un momento que tan solo siete personajes tienen más de 1000 intervenciones. Si ejecutas en la consola:
podrás ver quiénes son los más parlanchines y cuántas veces interviene cada uno de ellos.
## # A tibble: 573 × 2
## personaje n
## <chr> <int>
## 1 ALONSO 1946
## 2 AMELIA 1804
## 3 PACINO 1705
## 4 SALVADOR 1590
## 5 JULIÁN 1344
## 6 IRENE 1096
## 7 ERNESTO 1027
## 8 LOLA 551
## 9 ANGUSTIAS 469
## 10 VELÁZQUEZ 191
## # ℹ 563 more rowsComo puedes ver en la primera línea, hay 573 personajes en El Ministerio del Tiempo, pero apenas diez de ellos llevan toda la trama. Casi todos los demás personajes, salvo secundarios recurrentes como Elena y Susana, aparecen en un único episodio. La excepción son Lope de Vega en tres episodios con 102 intervenciones o Cervantes, en dos con 121 intervenciones. Puesto que queremos averiguar cuáles son las palabras características de los personajes principales con respecto al resto, hay que crear una columna en la que todos aquellos que no sean los fijos queden englobados bajo un mismo personaje. Para eso creas una nueva columna en MdT que llamarás personaje2 y lo harás con la función mutate().
MdT <- MdT %>%
mutate(personaje2 = ifelse(
personaje %in% c("PACINO",
"JULIÁN",
"AMELIA",
"ALONSO",
"SALVADOR",
"ERNESTO"),
personaje, "RESTO"))Aquí lo más curioso y novedoso es como conseguir que en la nueva columna aparezcan como RESTO todos aquellos personajes que no quieras considerar como principales. Para ello usarás la función ifelse() dentro de mutate(). Se trata de un evaluador lógico, por lo que si la evaluación es TRUE entonces se ejecuta el primer argumento y si es FALSE el segundo.
En un principio, la columna personaje2 tendrá tantas casillas como filas tenga la tabla, es decir, 18178. Si en la celda correspondiente de personaje aparece cualquiera de los nombres de la lista creada con c("PACINO", "JULIÁN", "AMELIA", "ALONSO", "SALVADOR", "ERNESTO"), entonces la celda de personaje2 tomará el nombre que haya en la celda de personaje, en caso contrario, es decir, si la evaluación es FALSE, entoces tomará el valor RESTO.
Considera la función mutate(personaje2) lo que hace es tomar toda la tabla de MdT, elimina todas las columnas salvo personaje y crea una nueva llamada personaje2 en la que no hay valores, es decir, todas las casillas están en blanco (R podría un NA).
| personaje | personaje2 |
|---|---|
| CAPITÁN | NA |
| ALONSO | NA |
| CAPITÁN | NA |
| ALONSO | NA |
| CAPITÁN | NA |
| ALONSO | NA |
| CAPITÁN | NA |
| ALONSO | NA |
| BLANCA | NA |
| ALONSO | NA |
Lo que la función ifelse() hará es mirar la columna personaje y si aparece alguno de los nombres que has incluido en la lista que has creado, la evaluación será TRUE, por lo que rellenará la casilla correspondiente de personaje2 con el mismo nombre que haya en personaje. Sin embargo, si es diferente a los que le has indicado, la evaluación será FALSE, y por consiguiente rellenará la casilla de personaje2 con el valor RESTO. Así que la columna personaje2 de la tabla anterior se rellanaría de manera parecido a esto:
| personaje | personaje2 |
|---|---|
| CAPITÁN | RESTO |
| ALONSO | ALONSO |
| CAPITÁN | RESTO |
| ALONSO | ALONSO |
| CAPITÁN | RESTO |
| ALONSO | ALONSO |
| CAPITÁN | RESTO |
| ALONSO | ALONSO |
| BLANCA | RESTO |
| ALONSO | ALONSO |
Si en la consola ejecutas esta orden
puedes comprobar que los personajes en personaje2 se han reducido a ocho.
## # A tibble: 7 × 2
## personaje2 n
## <chr> <int>
## 1 RESTO 8762
## 2 ALONSO 1946
## 3 AMELIA 1804
## 4 PACINO 1705
## 5 SALVADOR 1590
## 6 JULIÁN 1344
## 7 ERNESTO 1027Ya tienes preparado el material para hallar las palabras preferidas de cada uno de los siete personajes principales (si quieres añadir alguno de los secundarios recurrentes como Angustias o Velázquez, tan solo tienes que incoporar su nombre a la lista de la cadena que creaste antes con c(), con lo que dejarán de formar parte del conjunto RESTO). Échale una ojeada a la tabla ejecutando en la consola
lo que imprimirá el comienzo de la tabla
## # A tibble: 18,178 × 6
## temporada episodio titulo personaje texto personaje2
## <dbl> <dbl> <fct> <chr> <chr> <chr>
## 1 1 1 El tiempo e… CAPITÁN ¡Ata… RESTO
## 2 1 1 El tiempo e… ALONSO Porq… ALONSO
## 3 1 1 El tiempo e… CAPITÁN ¿Ten… RESTO
## 4 1 1 El tiempo e… ALONSO Si l… ALONSO
## 5 1 1 El tiempo e… CAPITÁN Ment… RESTO
## 6 1 1 El tiempo e… ALONSO Yo n… ALONSO
## 7 1 1 El tiempo e… CAPITÁN ¡Pre… RESTO
## 8 1 1 El tiempo e… ALONSO ¡¡To… ALONSO
## 9 1 1 El tiempo e… BLANCA ¿Por… RESTO
## 10 1 1 El tiempo e… ALONSO ¡Com… ALONSO
## # ℹ 18,168 more rowsEl siguiente paso es dividir todos los diálogos en palabras individuales y asignárselas a cada uno de los personajes de la variable personaje2. El resultado de esta operación lo has de guardar en una tabla que llamarás palabras_personajes. El código es:
palabras_personaje <- MdT %>%
unnest_tokens(palabra, texto) %>%
mutate(palabra = str_extract(palabra, "[[:alpha:]]+")) %>%
count(personaje2, palabra) %>%
ungroup()En la segunda línea de código se ha dividido el texto de MdT en palabras-token y se guardarán en la columna palabra. Como puedes ver en esta tabla intermedia en la que ha desparecido la columna texto puesto que la has convertido en palabra.
## # A tibble: 202,345 × 6
## temporada episodio titulo personaje personaje2 palabra
## <dbl> <dbl> <fct> <chr> <chr> <chr>
## 1 1 1 El tiempo… CAPITÁN RESTO atacas…
## 2 1 1 El tiempo… CAPITÁN RESTO antes
## 3 1 1 El tiempo… CAPITÁN RESTO de
## 4 1 1 El tiempo… CAPITÁN RESTO tiempo
## 5 1 1 El tiempo… CAPITÁN RESTO por
## 6 1 1 El tiempo… CAPITÁN RESTO qué
## 7 1 1 El tiempo… CAPITÁN RESTO lo
## 8 1 1 El tiempo… CAPITÁN RESTO hicist…
## 9 1 1 El tiempo… ALONSO ALONSO porque
## 10 1 1 El tiempo… ALONSO ALONSO vos
## # ℹ 202,335 more rowsLa tercera línea se encarga de borrar los números de una manera un tanto peculiar. Con mutate(palabra = str_extract(palabra, "[[:alpha:]]+")) lo que le estás diciendo es que busque en la columna palabra tan solo las secuencias de caracteres alfabéticos [[:alpha:]]+, los extraiga con str_extract() y los guarde de nuevo en palabra. En la cuarta lo que hace es contar las veces que cada uno de los ocho personajes recogidos en la variable personaje2 pronuncia cada palabra (excluidos ya los números). Además, se eliminará toda la información inútil como son las variables temporada, episodio y titulo, así como la variable original personaje. Con lo que al final tendrás una tabla de 33595 filas y 3 columnas.
## # A tibble: 33,595 × 3
## personaje2 palabra n
## <chr> <chr> <int>
## 1 ALONSO a 532
## 2 ALONSO aaaaaaahhhhhhhhhh 1
## 3 ALONSO aaaaahhhhhhh 1
## 4 ALONSO aaargh 1
## 5 ALONSO abadesa 1
## 6 ALONSO abajo 2
## 7 ALONSO abalanzamos 1
## 8 ALONSO abalanzarnos 1
## 9 ALONSO abandona 1
## 10 ALONSO abandonar 1
## # ℹ 33,585 more rowsVamos a ver cuántas palabras ha pronunciado cada uno de los ocho personajes puesto que es un cálculo que vas a necesitar un poco más adelante. Para tenerlo a mano, vas a crear una nueva tabla llamada total_palabras que lo que hará será extraer los datos de palabras_personaje. Como lo que quieres tener son los totales para cada uno de los ocho personajes que has considerado, tienes que agruparlos puesto que palabras_total tiene todas las palabras pronunciadas por todos los personajes. Desde el “Atacasteis” que dice un Capitán en el primer episodio hasta el “universidades” con que Alonso cierra el episodio 34, aunque aquí están organizadas alfabéticamente por cada personaje, por lo que van de las aes de Alonso hasta la yogurtera que menciona Salvador. Por este motivo, debes usar la función group_by(). Después, en una columna que llamarás total guardarás el resultado de sumar el número de palabras que emite cada uno de ellos. Para logarlo, utilizarás las función summarize() (= resumen), pero le tienes que decir cómo quieres que resuma los datos. En este caso por medio de una suma –sum()– del número –n– de palabras de cada personaje. La instrucción es:
Puede aparecer este aviso en la consola:
## `summarise()` ungrouping output (override with `.groups` argument)pero no tiene mayor importancia.
El resultado de esta expresión lo puedes ver escribiendo en la consola
que imprimirá el resultado.
## # A tibble: 7 × 2
## personaje2 total
## <chr> <int>
## 1 ALONSO 18079
## 2 AMELIA 17859
## 3 ERNESTO 11422
## 4 JULIÁN 13437
## 5 PACINO 18321
## 6 RESTO 100432
## 7 SALVADOR 22795Aunque es fácil ver quién es el personaje más hablador, Salvador con 22795 palabras, porque son pocos datos, puede ser interesante mostrarlo en una gráfica en la que ofrezca el procentaje de cada uno de ellos, con lo que se puede apreciar mucho mejor cuánto habla cada uno de ellos.
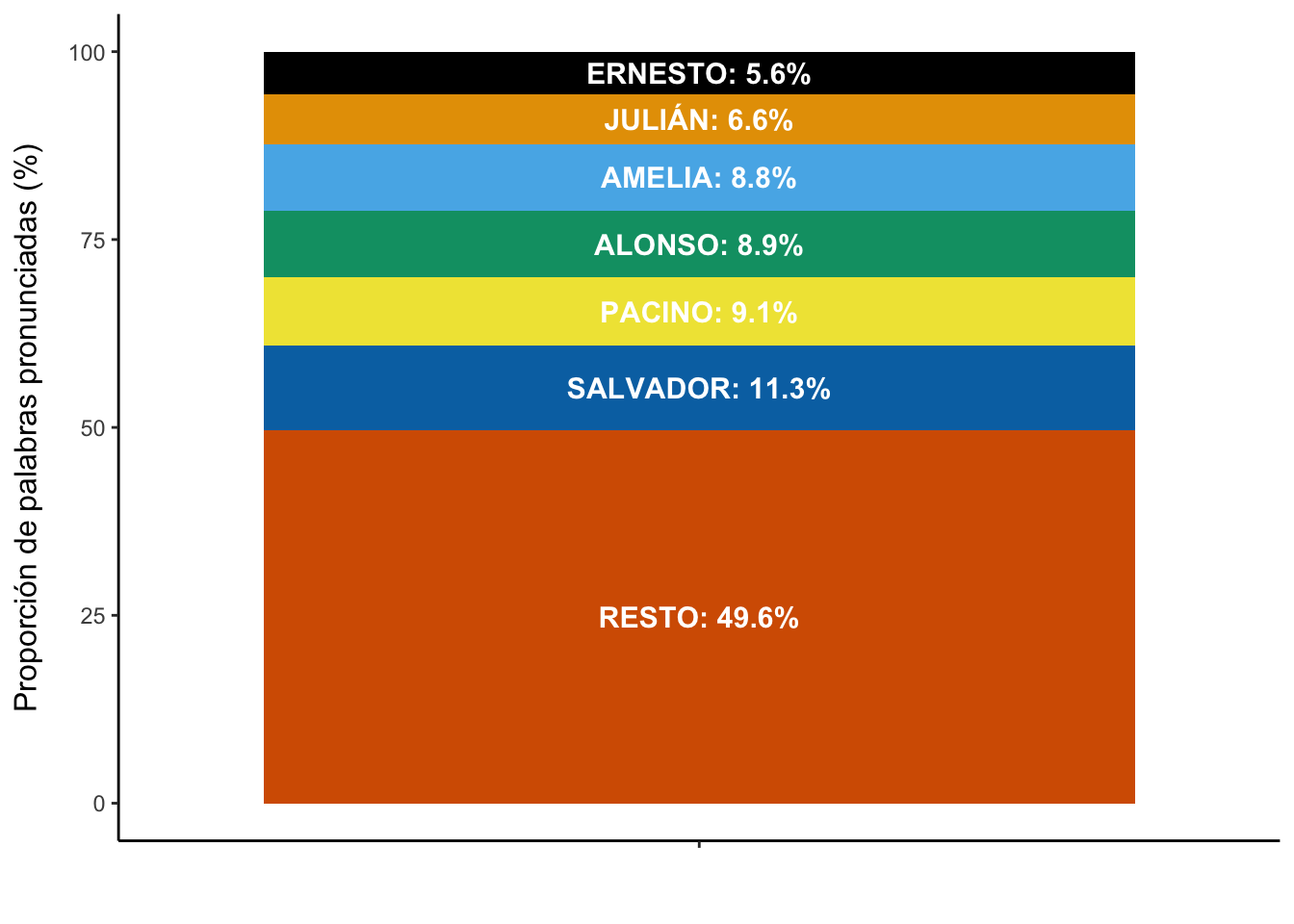
Figura 12.1: Cuánto habla cada unos de los siete personajes principales
Ya estás en disposición de averiguar cuáles son las palabras favoritas de cada uno de los ocho personajes. Para calcularlas y extraerlas lo primero que tienes que hacer es añadir a la tabla palabras_personaje el total de palabras que emplea cada uno de los ocho personajes a los que los has reducido y que tienes en total_palabras. Esa cifra total, que has visto como porcentaje en el gráfico de la figura 12.1, se la has de añadir a cada palabra pronunciada por cada personaje. La forma de conseguirlo es uniendo ambas tablas con la función left_join(). Las dos tienen en común la columna personaje2 y esta es la variable común por medio de la cual se unirán. Tan pronto se ejecute la expresión aparecerá en la consola el aviso ## Joining, by = "personaje2". Eso quiere decir que todo va bien y que ambas tablas se unirán añadiendo al final de cada línea de palabras_personaje el valor total de cada personaje2 tomándolo de total_palabras. La instrucción es
Puedes ver el resultado si escribes en la consola
que imprimirá el comienzo de la tabla.
## # A tibble: 33,595 × 4
## personaje2 palabra n total
## <chr> <chr> <int> <int>
## 1 ALONSO a 532 18079
## 2 ALONSO aaaaaaahhhhhhhhhh 1 18079
## 3 ALONSO aaaaahhhhhhh 1 18079
## 4 ALONSO aaargh 1 18079
## 5 ALONSO abadesa 1 18079
## 6 ALONSO abajo 2 18079
## 7 ALONSO abalanzamos 1 18079
## 8 ALONSO abalanzarnos 1 18079
## 9 ALONSO abandona 1 18079
## 10 ALONSO abandonar 1 18079
## # ℹ 33,585 more rowsSi te fijas, la última columna se llama total y, como solo puedes ver las diez primeras palabras de las usadas por Alonso, la cifra será 18079. Ya tienes todos los elementos para averiguar cuáles son las palabras características de cada uno de los personajes. Para ello necesitas la función bind_tf_idf() que será la encargada de realizar todos los cálculos. No te explico cómo es la fórmula matemática, no merece la pena, tú solo tienes que darle los argumentos pertienentes para que los realice. Son la palabra, el personaje2 y el número de veces que usa cada palabra n. La instrucción es:
Cuando ejecutes la orden anterior no verás nada. Sin embargo, si te fijas en la venta Environment podrás ver que ha aumentado el número de variables a 7 porque ha añadido tres columnas: tf, idf y tf_idf. Échale una ojeada a la cabecera de la tabla ejecutando en la consola
lo que imprimirá
## # A tibble: 33,595 × 7
## personaje2 palabra n total tf idf tf_idf
## <chr> <chr> <int> <int> <dbl> <dbl> <dbl>
## 1 ALONSO a 532 18079 2.94e-2 0 0
## 2 ALONSO aaaaaaahhhhh… 1 18079 5.53e-5 1.95 1.08e-4
## 3 ALONSO aaaaahhhhhhh 1 18079 5.53e-5 0.847 4.69e-5
## 4 ALONSO aaargh 1 18079 5.53e-5 1.95 1.08e-4
## 5 ALONSO abadesa 1 18079 5.53e-5 0.154 8.53e-6
## 6 ALONSO abajo 2 18079 1.11e-4 0 0
## 7 ALONSO abalanzamos 1 18079 5.53e-5 1.95 1.08e-4
## 8 ALONSO abalanzarnos 1 18079 5.53e-5 1.95 1.08e-4
## 9 ALONSO abandona 1 18079 5.53e-5 1.95 1.08e-4
## 10 ALONSO abandonar 1 18079 5.53e-5 1.25 6.93e-5
## # ℹ 33,585 more rowsFíjate que en idf y tf_idf hay ceros. Corresponden a palabras comunes que usan todos los personajes en todos los episodios. Las que se repiten una y otra vez en todos los textos, sean del tipo que sean, y que en algunas ocasiones anteriores hemos borrado ya que lo que interesaban eran las palabras semánticas, no las gramaticales. Por otra parte, si el valor de tf_idf es muy bajo, cerca de 0, es que esa palabra aparece en varios de los personajes (documentos, textos…) que estás analizando. Esto lo que hace es disminuir el peso de las palabras muy comunes de manera que cuanto mayor sea el valor del tf_idf de una palabra, esa palabra la habrán usado menos personajes. Échale una ojeada a las palabras con mayor tf_idf de El Ministerio del Tiempo. Ejecuta en la consola esta orden:
Antes de examinar el resultado te cuento qué es lo que le has pedido a R. Le has dicho que use la tabla palabras_personaje y que tome todas las variables menos total, lo que has conseguido con select(-total). Por último le has pedido que ordene, con arrange(), la tabla por el valor decreciente –desc()– de tf_idf de modo que en la parte superior de la tabla aparezcan los valores más cercanos a 1, o por decirlo de otra manera, más alejados de 0, o más fácil aún: de mayor a menor.
## # A tibble: 33,595 × 6
## personaje2 palabra n tf idf tf_idf
## <chr> <chr> <int> <dbl> <dbl> <dbl>
## 1 AMELIA you 22 0.00123 1.25 0.00154
## 2 ALONSO hideputa 14 0.000774 1.25 0.000970
## 3 ALONSO pardiez 13 0.000719 1.25 0.000901
## 4 ALONSO vos 94 0.00520 0.154 0.000801
## 5 ALONSO decís 14 0.000774 0.847 0.000656
## 6 JULIÁN maite 15 0.00112 0.560 0.000625
## 7 ALONSO vuestra 33 0.00183 0.336 0.000614
## 8 PACINO joder 33 0.00180 0.336 0.000606
## 9 JULIÁN bujía 4 0.000298 1.95 0.000579
## 10 JULIÁN encienda 4 0.000298 1.95 0.000579
## # ℹ 33,585 more rowsDe nuevo, mirar tablas de números es aburridísimo y poco informativo. Veámoslo con un gráfico como el de la figura 12.2:
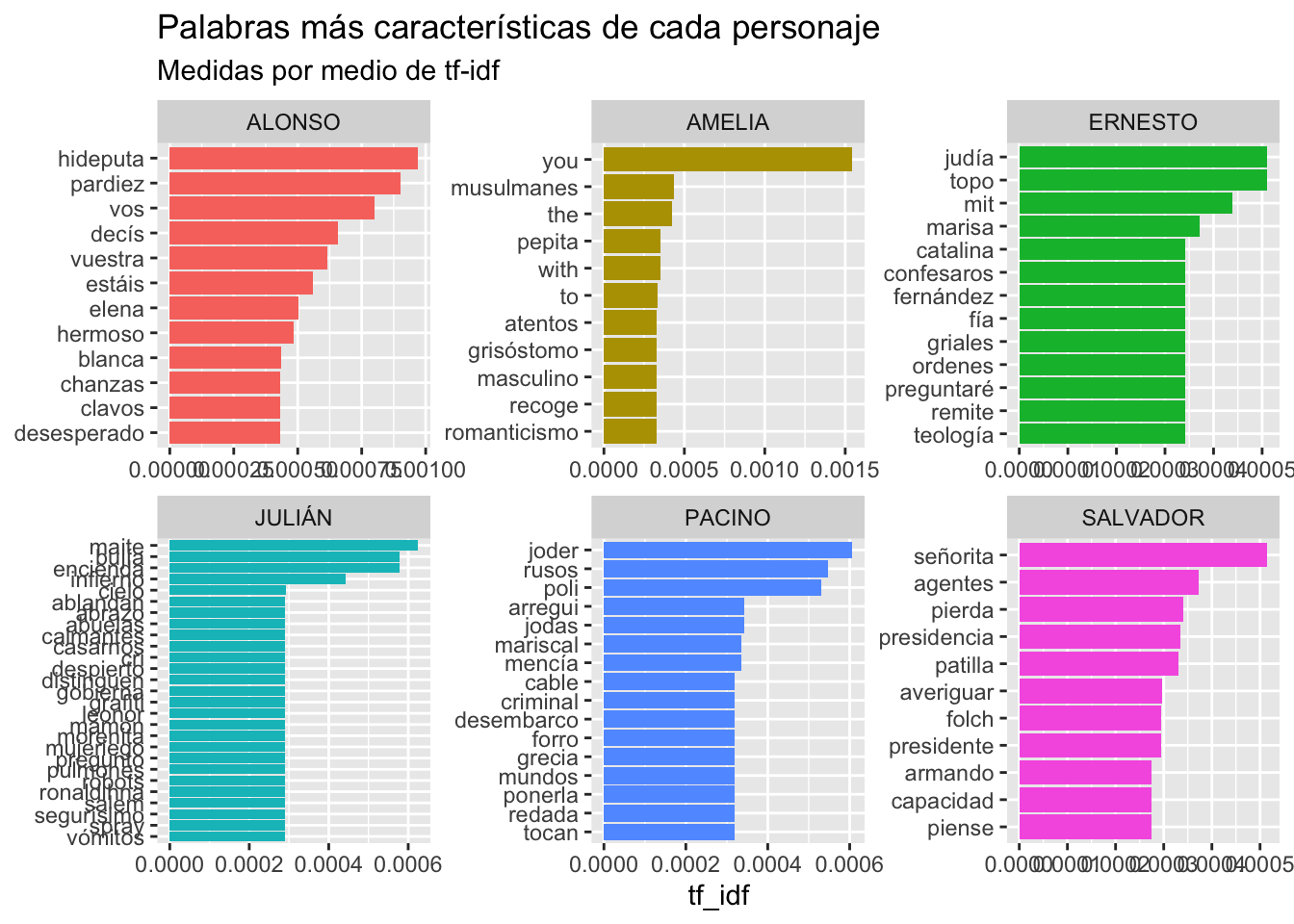
Figura 12.2: Palabras favoritas de cada personaje
top_n(10)).
Que se obtiene con este código. Cópialo en el editor de RStudio, pero no lo ejecutes hasta que hayas leído la explicación.
personaje_dibuja <- palabras_personaje %>%
arrange(desc(tf_idf)) %>%
mutate(palabra = factor(palabra, levels = rev(unique(palabra))))
personaje_dibuja %>%
filter(personaje2 != "RESTO") %>%
group_by(personaje2) %>%
top_n(10) %>%
ungroup() %>%
ggplot(aes(palabra, tf_idf, fill = personaje2)) +
geom_col() +
facet_wrap(~personaje2, scales = "free") +
coord_flip() +
labs(x = "tf-idf",
title = "Palabras más características de cada personaje",
subtitle = "Medidas por medio de tf-idf") +
theme(legend.position = "none",
axis.title.y = element_blank())La primera instrucción lo que hace es crear una nueva tabla llamada personaje_dibuja que extraerá la información de palabras_personaje. En la línea siguiente reordena la tabla de mayor a menor de acuerdo con los valores de tf_idf. En la última línea transforma el tipo de datos de la variable palabra de chr a fct y estable el orden levels() en que deben aparecer, en este caso inverso rev(), pero solo tendrá en cuenta
una única instancia de cada palabra unique(), o por decirlo de otra manera, solo tendrá en cuenta las palabras-tipo no las palabras-token de cada uno de los personajes.
En el segundo bloque es donde se imprimen los seis gráficos, uno por cada personaje con la información que has guardado en personajes_dibuja. Este bloques se divide, a su vez, en dos secciones. La primera que se ocupa de reninar los datos que utilizará y la segunda que es la que realmente dibujará la gráfica y que comienza con la función ggplot().
El primer grupo se ocupa de tener en cuenta tan solo las palabras características de cada uno de los seis personajes principales, por lo que la primero que debes hacer es indicarle que no tenga en cuenta todas las que hayan usado los cerca de 570 personajes restantes que has aglutinado bajo el nombre RESTO. Esto lo consigues con filter(personaje2 != "RESTO"), es decir, tan solo ten en cuenta aquellas observaciones cuyo personaje2 no sea RESTO. Puesto que toda la información está dispersada por la tabla y quieres ver lo de cada uno de los personajes, le dices que los agrupe con group_by(personaje2). Lo siguiente es decidir cuántas palabras quieres que muestre como característica de cada personaje. Para ello usas la función top_n() y entre los paréntesis indicas cuántas quieres que considere. Por último, desactivas la agrupación de los datos, ya no la necesitas. Si echaras una ojeada a la memoria del ordenador podrías ver que las 33595 observaciones de personaje_dibuja se han reducido a tan solo 90. Aquí te presento el comienzo de la tabla interna que se ha creado con este primer grupo de instrucciones y que será la que use ggplot() para dibujar las seis gráficas.
## # A tibble: 90 × 7
## personaje2 palabra n total tf idf tf_idf
## <chr> <fct> <int> <int> <dbl> <dbl> <dbl>
## 1 AMELIA you 22 17859 0.00123 1.25 0.00154
## 2 ALONSO hideputa 14 18079 0.000774 1.25 0.000970
## 3 ALONSO pardiez 13 18079 0.000719 1.25 0.000901
## 4 ALONSO vos 94 18079 0.00520 0.154 0.000801
## 5 ALONSO decís 14 18079 0.000774 0.847 0.000656
## 6 JULIÁN maite 15 13437 0.00112 0.560 0.000625
## 7 ALONSO vuestra 33 18079 0.00183 0.336 0.000614
## 8 PACINO joder 33 18321 0.00180 0.336 0.000606
## 9 JULIÁN bujía 4 13437 0.000298 1.95 0.000579
## 10 JULIÁN encienda 4 13437 0.000298 1.95 0.000579
## # ℹ 80 more rowsEspero que te haya asaltado una pregunta. Si he pedido que solo extraiga las diez palabras más características de cada personaje, y la tabla me dice que hay 90 algo ha fallado, porque diez palabras por personaje son sesenta paalbras en total y aquí hay un tercio más de lo pedido. La respuesta es muy sencilla, quizá ya lo hayas observado en la gráficas. Fíjate en la de Julián, a partir de la sexta, ablandan hasta la última vómitos todas tienen el mismo valor de tf_idf, 0.000290, por lo tanto, todas ellas entran dentro de las 10 características de Julián (las siguientes palabras ya tienen una frecuencia absoluta de 1). Mira ahora las de Amelia; recoge y romanticismo ocupan las posiciones 10 y 11 en la tabla y ambas tienen el mismo valor en el tf_idf, 0.000327. A Alonso le sucede lo mismo, su gráfica ofrece doce palabras, y eso es porque chanzas, clavos y desesperado tienen el mismo valor, 0.000431.
Ya tienes, la explicación, aunque la cosa no mejoraría mucho si redujeras a cinco las palabras que debe tener en cuenta. En este caso Ernesto presentaría las mismas que si le hubieras pedido las diez más características puesto que Catalina aparece en la quinta posición y desde ella en adelante todas tienen el mismo valor: 0.000341, por lo que forman parte de las cinco más característica. Es importante que tengas esto en cuenta cuando interpretes los resultados.
Vamos con la explicación de cómo de traza el gráfico, aunque ya lo has visto una y otra vez en los capítulos anteriores. La línea ggplot toma en cuenta los valores que ha de dibujar, que son lo que haya en palabra y en tf_idf y los colores con los que dibjura cada uno de los valores se corresponde con el valor de personaje2. La siguiente línea indica cuál será el tipo de gráfica que ha de dibujar, en este caso geom_col(), es decir, un gráfico de barras. Puesto que tienes seis personajes y quieres presentar los seis gráficos juntos, en una sola imagen, usar la función facet_wrap(~personaje2, scales = "free"), indicándole cuál debe ser la variable que controle las viñetas y que las escalas deben ser libres, pues no todos personajes ofrecerán los mismos valores.
Creo que ya te lo he dicho alguna vez: fíjate siempre en los valores que se imprimen en los ejes X e Y, pueden parecer lo mismo y llevar a error. En Ernesto y Salvador sobrepasan la marca de 0.0005, en Julián y Pacino la de 0.0006, Amelia sobrepasa la de 0.0015 mientras que la de Alonso no llega a la de 0.00100. No son los mismos valores, aunque visualmente tengan la misma longitud.
Con la función coord_flip() lo que haces es rotar la orientación de los gráficos. Lo usual es que la variable discreta –los valores de palabra– esté en el eje horizontal y la continua –los valores de tf_idf– en el vertical, pero eso haría que la lectura y, por tanto, la interpetación de las gráficas fuera más complicada. de ahí que los rotes.
La línea de la función labs() se ocupa de las leyendas de la parte superior de la gráfica y la última línea se ocupa de no imprimir la leyenda del eje Y, pues ha cambiado de posición debido a coord_flip() y también de una leyenda lateral en la que informaría de qué color corresponde a cada personaje, pero eso ya lo tienes con la banda gris encima de cada gráfica individual.
Puedes añadir otros aspectos estéticos, pero eso los dejo para que práctiques.
RTVE no publicó los guiones para los episodios de la cuarta temporada, por lo que no ha sido posible incorporarlos y analizarlos en este capítulo y dar una visión completa de esta entretenida serie.↩︎