9 Topic Modeling
9.1 Introducción
Sopongamos que en un archivo se ha encontrado un legajo con más de cuatrocientas cincuenta páginas de texto que parecen tratar de pensadores porque al trascribirlas han aparecido recurrentemente los nombres Freud, Voltaire, Chomsky y Maquiavelo y términos como lenguaje, lingüística, política, revolución, sociedad, crítica, análisis, social, historia, príncipe, moral, ideas, psicoanálisis, etc. Tan solo han sido capaces de dibujar una nube de palabras (figura 9.1) y quieren saber si se pueden agrupar por temas porque esos cuatro nombres que aparecen recurrentemente dan la pista de que podría tratarse de cuatro capítulos de una obra en los que se habla de esos autores.

Figura 9.1: Nubes de palabras del legajo
Hay una técnica procedente de la inteligencia artificial (IA), del subcampo del aprendizaje automático (machine learning), que puede ser de gran ayuda para clasificar estos textos. Es el llamado topic modeling, que lo que pretende es identificar, sin la ayuda de ningún diccionario, los temas (tópicos) principales que encierra un texto.
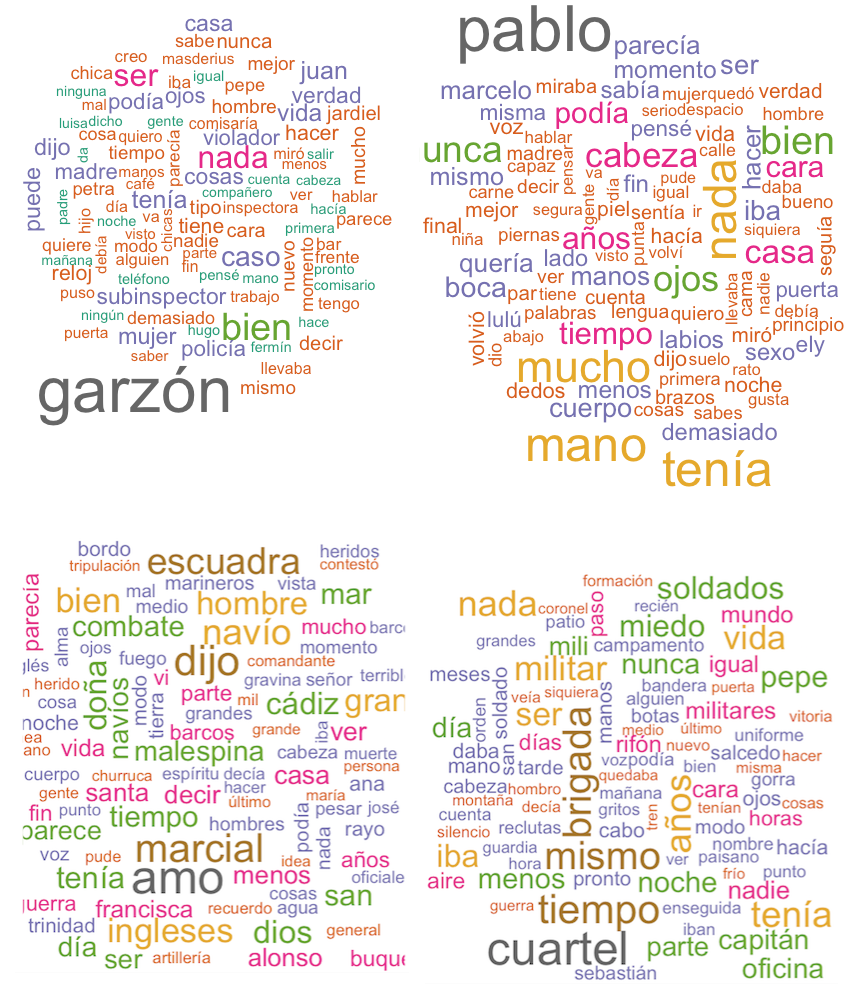
Figura 9.2: Nube de palabras de cuatro novelas españolas
La primera (de arriba a bajo y de izquierda a derecha) es una novela policíaca, como muestra la ocurrencia de términos como comisario, subinspector, policía, caso y que el delito parece ser una violación por la aparición de la palabra violador. En la segunda abundan las referencias a diversas partes del cuerpo como piernas, lengua, brazos, ojos, boca, dedos, cabeza, labios, cara…; estas palabras por sí solas no constituyen un tópico puesto que pueden aparecer en muchos otros tipos de textos; cabeza y ojos, por ejemplo, aparecen en las cuatro nubes. Sin embargo, la ocurrencia de cama y sexo permiten restringir el tema y, podría ser una novela rosa (o erótica). La tercera parece que se trata de una batalla naval, como lo delatan las palabras navío, escuadra, buque, barcos, combate, muerte, guerra, mar, artillería, cañones y marineros, y, además, en ella participan los ingleses. La última parece situarse también en un ambiente militar, pero infinítamente más tranquilo, en la vida de cuartel (capitán, uniforme, reclutas, botas, ejército, militares, sargento, campamento) durante la llamada mili, es decir, el servicio militar obligatorio.
Lo mismo que acabas de hacer para ver de qué tratan esas novelas, pero has tenido que jugar con tu conocimiento del mundo y con un amplio repertorio léxico, puede hacerlo una máquina que no sabe nada de español, o para el caso de ninguna lengua, pues para ella todo son ceros y unos.
Las cuatro novelas procesadas y representadas en las cuatro nuebes de palabras de la figura 9.2 son:
- Ritos de muerte, de Alicia Gimenez-Bartlet,
- Las edades de Lulú, de Almudena Grandes,
- Trafalgar, de Benito Pérez Galdós y
- Ardor guerrero, de Antonio Muñoz Molina.
El proceso matemático que hay tras el modelado de tópicos, como en casi todo lo que estas viendo, es tremendamente complejo, pero el procedimiento, a grandes rasgos es bastante sencillo de entender.
9.2 Topic Modeling
Todo texto presenta un abanico de tópicos y esos tópicos se expresan por medio de palabras, en especial sustantivos, lo único que tiene que hacer la máquina es contar las palabras y ver cuáles coocurren con cuáles, algo que has visto en el capítulo anterior, y después el investigador debe decidir cuáles son los verdaderos tópicos, pues no todos son tan sencillos de decidir como los que te he mostrado en las nubes de la figura 9.2.
Al ejecutar el ordenador un algoritmo de modelado de tópicos, de los que hay varios disponibles –LDA, Mallet–, devuelve dos tipos de datos. Por una parte, informa de qué tópicos existen en la colección de textos y qué palabras los conforman. Por la otra, informa de la proporción que hay de cada tópico en cada texto. En la figura 9.3 te avanzo el resultado de analizar los folios del legajo.
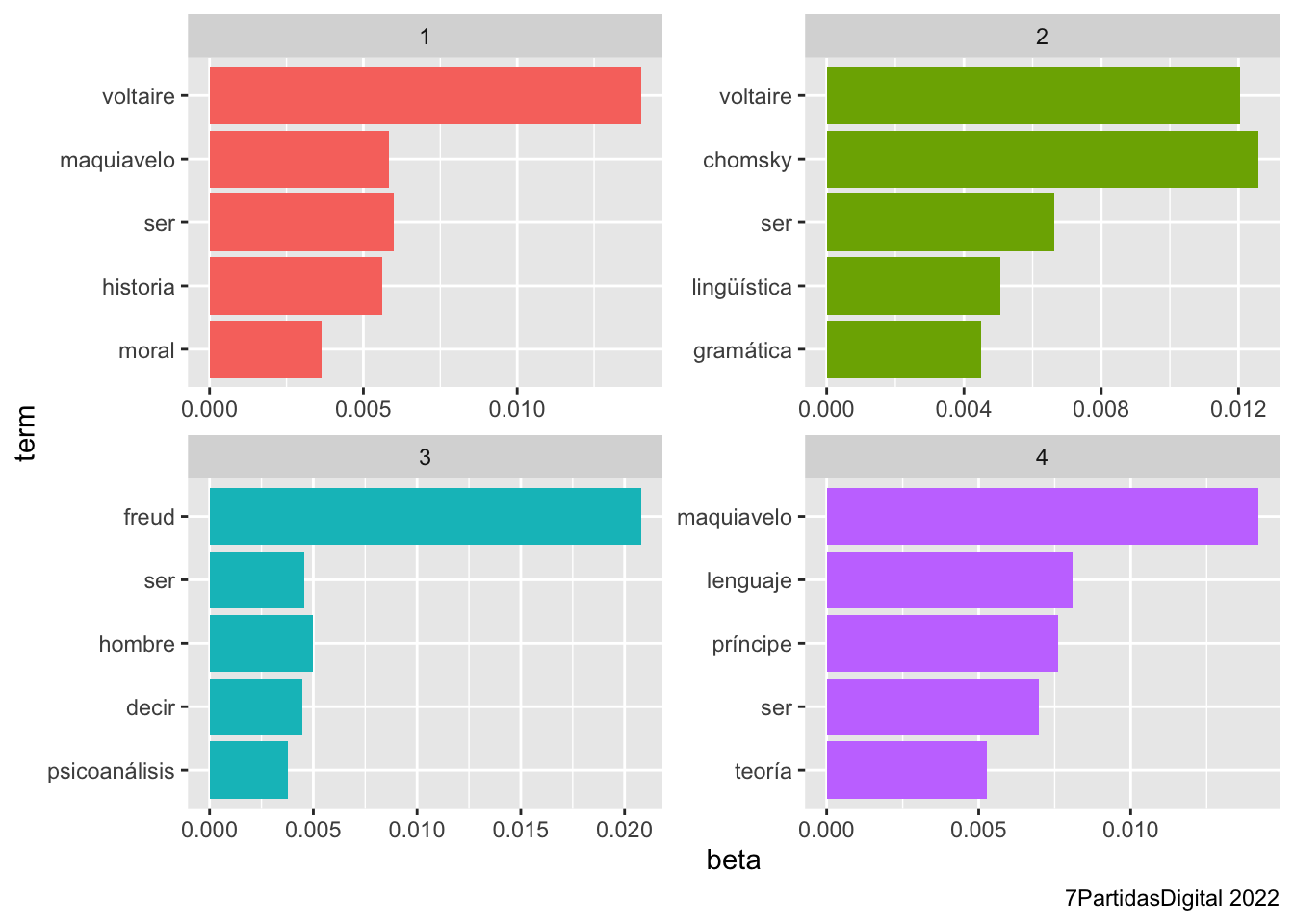
Figura 9.3: Tópicos y palabras que conforman el legajo
9.3 Al teclado
Lo que vas a realizar en adelante es comprobar que el ordenador es capaz de establecer que en esas supuestas 364 páginas proceden de cuatro libros independientes, que bien podrían ser capítulos de un libro extenso sobre pensadores occidentales. Como de antemano sabes cuál ha de ser el resultado, te servirá para ver la bondad del procedimiento. Es enredado en cuanto a qué es lo que hace la máquina en cada momento, pero se puede seguir y replicar con sencillez.
Vas a necesitar tres nuevas librerías {tm}, {topicmodels} y {scales}. Instálalas.
# Recuerda que solo las tienes que instalar la primera vez.
install.packages("tm")
install.packages("topicmodels")
install.packages("scales")mallet, de David Mimmo. Originalmente se escribió en Java, lo que implica que lo puedes utilizar fuera de R (Programming Historian tiene un interesante tutorial en español), pero para usarlo en el entorno de R, que es el objetivo de este libro, requiere instalar {rJava}, lo que puede ser una pesadilla en los ordenadores Apple. Debido a esto y, a que no hace uso del ecosistema tidydata que estamos empleando, prefiero recurrir a {topicmodels}.
library().
Carga librerías {tm}, {topicmodels} y {scales} junto con {tidyverse} y {tidytext}.
Lo siguiente es cargar la lista de palabras vacías para borrar todas las palabras de función que no aportarán nada al establecimiento de los tópicos.
vacias <- read_tsv("https://raw.githubusercontent.com/7PartidasDigital/AnaText/master/datos/diccionarios/vacias.txtAl ejecutar la orden anterior se imprimirá este mensaje
## Rows: 465 Columns: 1
## ── Column specification ─────────────────────────────────────
## Delimiter: "\t"
## chr (1): palabra
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Esto quiere decir que se ha cargado correctamente la tabla vacias y que consta de una sola columna llamada palabra cuyo contendio son caracteres (col_charater()).
Los cuatro textos con los que vas a trabajar son cuatro ensayos sobre Chomsky, Freud, Maquiavelo y Voltaire. Crea un vector con estos nombres y llámalo titulos.
No vas a saber cuál es cuál, para mantener un poco la ficción. Cada uno de los textos que está escondido tras los nombres de fichero filosofo1.txt a filosofo4.txt que tienes en el vector ficheros.
Pero como están en un servidor externo, tienes que indicar la ruta donde los debe buscar.
Lo siguiente es crear la tabla ensayos en la que se guardarán los cuatro textos divididos en páginas.
9.3.1 Bucles for anidados
Lo que sigue es el proceso de carga de los cuatro textos y su subdivisión en páginas, las que, supuestamente, encontraste en el archivo. Para hacerlo, vas a utilizar dos bucles for anidados uno dentro de otro. Esto ya es un poco más complicado, pero ya estás aproximándote al final del libro y creo que merece la pena complicar la cosa un tanto. En la primera parte del bucle, leerás cada uno de los textos; los convertirás en una sola cadena de caracteres, lo cual te permitirá dividirlo en palabras conservando la puntuación, y después podrás repartirlo en secciones de 375 palabras (he calculado que es la media de palabras por página con varias novelas, pero nada te impide usar cualquier otro valor). Cada una de esas secciones es cada una de las casi 370 páginas ficticias que encontraste en el legajo. Después, volverás a unir las palabras en un solo elemento y por último guardarás cada uno de esos trozos (páginas) dentro de ensayos. Numerarás cada uno de ellos y le darás un identificador. Es mucho lo que tienes que hacer. Copia estas líneas de código, pero no las ejecutes hasta que hayas leído la explicación.
for (j in 1:length(ficheros)){
texto.entrada <- read_lines(paste(ruta,
ficheros[j],
sep = ""),
locale = default_locale())
texto.todo <- paste(texto.entrada, collapse = " ")
por.palabras <- strsplit(texto.todo, " ")
texto.palabras <- por.palabras[[1]]
trozos <- split(texto.palabras,
ceiling(seq_along(texto.palabras)/375))
for (i in 1:length(trozos)){
fragmento <- trozos[i]
fragmento.unido <- tibble(texto = paste(unlist(fragmento),
collapse = " "),
titulo = titulos[j],
pagina = i)
ensayos <- bind_rows(ensayos, fragmento.unido)
}
}9.3.2 Explicación del código
El bucle externo es el encargado de leer los textos y dividirlos en segmentos de 375 palabras que conformarán cada uno de los folios que encontraste. Este está regido por la longitud del vector ficheros –length(ficheros)– y la variable de control es j.
En la primera línea leerá un texto ficheros[j] y lo guardará en texto.entrada.
Una vez que tienes en texto.entrada uno de los ficheros, en la siguiente línea lo que haces es guardar en texto.todo una copia del fichero que acabas de leer, pero en una sola cadena de caracteres. Para hacerlo le has dicho que pegue con paste() todos los elementos que haya en texto.entrada y que el pegamento sea un espacio en blanco. Como no se trata de separar piezas, sino de unir, usas el atributo collapse = " ", con un espacio en blanco entre las comillas.
A continuación, lo vas a dividir en palabras sueltas y lo vas a guardar en por.palabras. Es lo mismo que has hecho, y volverás hacer, con unnest_tokens(). Pero esta vez solo lo vas a dividir sin tocar para nada cada una de las palabras, lo que conservará, además, todos los signos de puntuación y la distinción de entre mayúsculas y minúsculas. La función de dividir un vector la realiza la función strsplit (string split = ‘dividir cadena’), y para que sepa dónde están los márgenes, le indicas, entre comillas, que es un espacio en blanco.
Esta función crea una lista, que son difíciles de manejar, por lo que tienes que extraer a un vector de caracteres el contenido de la lista por.palabras, pero de una manera un tanto peculiar, con el doble corchete [[]]. Como solo tiene un vector, le dices que lo extraiga con por.palabras[[1]] y que lo guarde en texto.palabras. Ahora tienes que dividirlo en secciones –trozos– de 375 palabras. Sé que es de locos lo que estás haciendo. Unir, cortar, dividir… y aún te falta volverlo a unir.
Para dividir texto.palabras en trozos utilizarás la función split (= ‘dividir’). Esta requiere saber qué vector es el que ha de dividir, primer argumento, y cómo debe dividirlo, segundo argumento. El primero lo tienes claro, es texto.palabras. El segundo es un cálculo un tanto curioso, pero muy elemental. Le pides que cuente cuantos elementos tiene el vector que quieres dividir –texto.palabras– con seq_along() y que lo divida entre 375, que es el número de palabras que quieres contemplar para cada página. Como la probabilidad de que dé un número exacto de porciones de 375 es remoto, con ceiling() lo que haces el indicarle, que lo que quede, el resto, lo meta en el último trozo, sin importar si son 375 o 25 palabras. Por ejemplo, el último texto tiene 38 690 palabras, si lo divides entre 375 el resultado sería 103.1733, con ceiling() lo que haces es redondear al alza, por lo que ceiling(37690/375) dará como resultado 104 y tendrás una página 104 en la que guardará el resto. Si quisieras redondear a la baja usarías la función floor(). Ejecuta en la consola
## [1] 103.1733## [1] 103## [1] 104El resultado de todo esto es que en trozos tienes una lista con tantos vectores como se hayan calculado con ceiling() y que corresponde a cada una de las páginas en las que has dividido el texto que has leído. Ya has acabado con la primera parte del bucle. Tómate un descanso.
Vamos con el segundo bucle, el anidado cuyo número de iteraciones está controlado por la longitud de la lista trozos que has conseguido en el bucle exterior y cuya variable de control es i (¡cuidado! no las enredes), en la que vuelves a unir las palabras de cada trozo en una página que vas a guardar en ensayos.
En cada iteración de i, extraerás un vector de trozos y lo guardarás en fragmento. En la siguiente línea convertirás la lista –unlist()– que has sacado de trozos en una cadena de caracteres con paste(unlist(fragmento), collapse = " ")). Sí, ya sé que es de locos. Unir, cortar, unir… ¡vaya rollo!
Lo que acabas de unir, lo guardarás en la columna texto de fragmento.unido, que es una tabla provisional en la que crearás cada una de las páginas de cada uno de los textos. La información que tendrá cada tabla es el texto, el identificador con titulo y el número de pagina. Fíjate bien que el número de pagina es el valor de i, es decir, el número de trozo, mientras que el identificador que guardarás en titulo es el contenido j del vector titulos, es decir, el título lo controla el bucle externo ya que es el único que sabe cuántas vueltas dará, porque es igual al número de ficheros leídos y que tienes guardado en el vector ficheros. Para que veas cuántas vueltas dará ejecuta en la consola
el resultado será
## [1] 4La última línea del bucle es una vieja conocida. Lo que hace es añadir a la tabla ensayos que creaste antes de comenzar el bucle cada uno de los trozos reunidos, es decir, cada una de las páginas que encontraste en aquel polvoriento legajo. Ahora procederás a borrar todos los objetos intermedios que has creado para dividir los textos en páginas. Podrías haberlo hecho a mano, pero te habría llevado mucho tiempo.
Ya puedes ejecutar el doble bucle. Sitúate en la primer línea del bloque y pulsa control (cmd en Mac) e intro. Tardará un poco en ejecutarse. Al final tendrás la pestaña Environment llena de objetos. Tan solo te interesa conservar dos: ensayos y vacias Así que ejecuta en la consola
rm(ficheros, titulos, trozos, fragmento,
fragmento.unido, ruta, texto.entrada,
texto.palabras, texto.todo, por.palabras, i, j)Ahora solo debe haber en Environment dos objetos: ensayos y vacias. Es decir, una tabla con todas las páginas y otra con las palabras vacías que borrarás para hallar los tópicos que puede haber en estos textos y ver si el ordenador es capaz de unir las páginas (no digo ordenar, digo juntar, temáticamente).
ensayos es una tabla de 364 observaciones (filas) y tres variables (columnas): texto, titulo y pagina en las que has guardado todas las páginas del famoso legajo. La columna titulo la he añadido para que sepas después si el sistema ha funcionado o no, podría funcionar sin ello, pero para aprender es mejor incorporar esa columna. El primer paso, como de costumbre, es dividirlo en palabras-token y guardarlas en una tabla que llamarás por_pagina_palabras. Pero para saber de qué folio es cada palabra, vas a crear una clave, que guardarás en la columna titulo_pagina. Esta clave se crea uniendo con unite() los valores de titulo y pagina.
por_pagina_palabras <- ensayos %>%
unite(titulo_pagina, titulo, pagina) %>%
unnest_tokens(palabra, texto)El resultado de lo anterior lo que puedes ver si escribes en la consola
Las diez primeras líneas del resultado tienen que ser
## # A tibble: 135,905 × 2
## titulo_pagina palabra
## <chr> <chr>
## 1 Chomsky_1 introducción
## 2 Chomsky_1 noam
## 3 Chomsky_1 chomsky
## 4 Chomsky_1 avram
## 5 Chomsky_1 noam
## 6 Chomsky_1 chomsky
## 7 Chomsky_1 es
## 8 Chomsky_1 uno
## 9 Chomsky_1 de
## 10 Chomsky_1 los
## # ℹ 135,895 more rowsComo puedes ver, se trata de una tabla con 135905 palabras identificadas cada una por el título y el número de la página. Como te he dicho, podría bastar con el número de página, pero para comprobar el resultado le he añadido el nombre del pensador que se analiza.
Échale ahora una ojeada a las palabras-tipo más frecuentes con
## # A tibble: 16,220 × 2
## palabra n
## <chr> <int>
## 1 de 8187
## 2 la 5623
## 3 que 4641
## 4 el 3761
## 5 en 3747
## 6 y 3564
## 7 a 2924
## 8 los 2122
## 9 un 1715
## 10 una 1589
## # ℹ 16,210 more rowsAlgo absolutamente decepcionante. En algunos análisis, como has visto, y como verás, son interesantes las palabras gramaticales, pero en otros son un estorbo porque introducen un ruido indeseado. Así que hay que borrarlas con anti_join(). Vas a crear una nueva lista de palabras sin esas palabras molestas y la guardarás en una nueva tabla que llamarás palabras_conteo. En esta tabla, además de la palabra y la clave titulo_pagina, guardarás el número de veces que aparece cada una de ellas en cada página en la columna (variable) n. Lo consigues con
palabra_conteo <- por_pagina_palabras %>%
anti_join(vacias) %>%
count(titulo_pagina, palabra, sort = TRUE) %>%
ungroup()Recuerda que aparecerá un mensaje informándote de que la función anti_join() ha usado la variable común palabra.
## Joining with `by = join_by(palabra)`Puedes ver cuántas palabras de valor, que están recogidas en la columna (variable) palabra, hay en cada folio del legajo (cada unos de ellos está identificado con titulo_numero) y cuál es su frecuencia n con
lo que imprimirá el comienzo de una larga tabla.
## # A tibble: 55,301 × 3
## titulo_pagina palabra n
## <chr> <chr> <int>
## 1 Chomsky_33 lenguaje 15
## 2 Chomsky_59 estructura 14
## 3 Chomsky_32 lenguaje 13
## 4 Chomsky_56 adecuación 13
## 5 Maquiavelo_72 ser 12
## 6 Chomsky_38 lenguaje 11
## 7 Chomsky_39 lingüística 11
## 8 Freud_59 edipo 11
## 9 Maquiavelo_94 moral 11
## 10 Voltaire_21 voltaire 11
## # ℹ 55,291 more rows9.3.3 Document Term Matrix
Lo que tienes es una tabla con un término por documento en cada fila. Sin embargo, el paquete {topicmodels} utiliza otro tipo de estructura, la llamada Document-Term Matrix (DTM) procedente del paquete {tm}. No te voy a introducir en las sutilezas de esta matriz, pero de una forma sencilla es una gran tabla en la que en cada fila hay un documento y en cada columna hay una palabra. Considera estas sencillas frases:
F1 Hace mucho frío
F2 Hace mucho calor
F3 Hace mucho tiempoSi las convertimos en una Document-Term Matrix tendría el aspecto de la tabla 9.1.
| Hace | mucho | frio | calor | tiempo | |
|---|---|---|---|---|---|
| F1 | 1 | 1 | 1 | 0 | 0 |
| F2 | 1 | 1 | 0 | 1 | 0 |
| F3 | 1 | 1 | 0 | 0 | 1 |
Esta matriz te muestra qué documento (frases en este caso: F1, F2, F3) tiene qué palabras y cuántas veces.
La forma de obtener este tipo de matriz, que es con la que opera {topicmodels}, es con la función cast_dtm() del paquete {tidytext}, del ecosistema tidydata que estás utilizando. Este nuevo objeto matriz lo vas a llamar paginas_dtm, así tienes claro qué tipo de objeto es. Es una orden muy simple. La función cast_dtm() solo necesita saber de qué objeto ha de extraer los datos, en este caso palabras_conteo, y cuáles son las variables que ha de recuperar: la referencia del documento titulo_pagina, las palabras palabra y las frecuencias n, de ahí que crearas la tabla palabras_conteo. Transformarla en una DTM se consigue con
Para revisar el resultado, ejectuta en la consola
que te ofrecerá este mensaje:
## <<DocumentTermMatrix (documents: 364, terms: 15901)>>
## Non-/sparse entries: 55301/5732663
## Sparsity : 99%
## Maximal term length: 20
## Weighting : term frequency (tf)La primera línea informa de que en paginas_dtm hay 364 documentos (páginas en tu caso) y que hay 15 900 términos diferentes en total. En definitiva, lo que tienes es una tabla con 5 732 358 celdas cuyo valor puede ser 0, no aparece en el documento, o un valor superior a 0 (los informáticos dicen non-zero), por lo que en la segunda línea te informa de que 5 732 358 celdas tienen como valor 0 y tan solo 55 242 tiene un valor mayor que 0, lo que supone que el 99 % de las filas (tercera línea) tienen como valor 0. La cuarta línea te dice que la palabra más larga tiene 20 caracteres y que la forma de considerar los términos es por medio de su frecuencia (term frquency o tf).
9.4 Latent Dirichlet Allocation
Ahora estás listo para usar el paquete {topicmodels} y construir un modelo LDA (Latent Dirichlet allocation). Pero antes, conviene que tengas una ligera noción de como funciona el modelo LDA y quién lo creó, para lo que me baso en un post de José Calvo sobre el modelado de tópicos.
El autor más influyente sobre topic modeling es sin duda David Blei, quien, en un artículo de 2012 titulado «Probabilistic Topic Models», propuso un modelo sobre topic modeling llamado Latent Dirichlet allocation. Desde entonces este modelo es el más utilizado. La imagen de la figura 9.4 se utiliza en casi cualquier presentación sobre topic modeling.
](imagenes/09-Topic-LDA.png)
Figura 9.4: Topic Modeling según la visión de Blei
En el artículo en el que Blei presenta LDA, define topic como «a distribution over a fixed vocabulary» y su punto de partida es intentar recrear de manera inversa el modelo teórico por el que los textos se generan. Según él, los autores tienen a su disposición un conjunto delimitado y cerrado de temas o topicos (en la figura anterior son las listas de palabras con fondos de diferentes colores), cada uno de esos topicos contiene palabras (algunas más importantes para el topico, otras menos), y el autor va sacando palabras de los diferentes topics para escribir su texto (en la parte derecha de la imagen superior, algunas palabras tienen fondos de diferentes colores señalando su pertenencia al topic). Para rehacer de manera inversa ese proceso generativo hipotético, Blei realiza los siguientes pasos teóricos:
- Selecciona aleatoriamente una distribución de los tópicos
- Para cada palabra del documento
- Selecciona aleatoriamente un tópico de la distribución de tópicos del paso 1.
- Selecciona aleatoriamente una palabra de la distribución correspondiente del vocabulario.
Como puedes observar, el adverbio aleatoriamente está en todos los pasos. Como es de esperar, esto provoca que cada vez que utilices el topic modeling sobre un corpus, los resultados muestren cierta variación, es decir, pueden ofrecer resultados semejantes pero no idénticos.
Quizás ahora mismo estés pensando:
- los textos no se generan así
- no entiendo eso de «a distribution over a fixed vocabulary»
- ¿cómo puede ser que todos los pasos sean aleatorios?
Si estás pensando eso, ¡enhorabuena!, es el momento de maravillarte de que un método tan ilógico y oscuro funcione tan bien como para extraer que chomsky, lenguaje, lingüística, teoría y gramática están relacionados (échale una ojeada a los gráficos de barras de la figura 9.3).
9.4.1 Construir el modelo LDA
El modelado de tópicos en gran medida se puede resumir en dos puntos:
- Todo documento es una mezcla de tópicos.
- Cada tópico es una mezcla de palabras.
El LDA es un modelo matemático que sirve para estimar estos dos puntos a la vez: localizar la mezcla de palabras que se asocia con cada tópico y, a la vez, determinar la mezcla de tópicos que sirven para describir cada documento.
Para establecer el modelo se utiliza la función LDA() de la librería topicmodels que requiere tres argumentos: el objeto sobre el que se construirá el modelo –paginas_dtm–, el número de tópicos –k– y un tercer argumento –control = list()– que sirve para hacer el modelo predecible. El resultado de este cálculo lo guardarás en paginas_lda. La línea de código es
El valor de k se ha establecido porque partes del conocimiento previo de que hay cuatro pensadores (filosofo1 a filosofo4), pero la verdad es que en este tipo de análisis hay que juguetear con los posibles valores. Con seed = 1234 dentro list() lo que se logra es un punto de comienzo fijo para el proceso de iteración aleatoria. Si no se hiciera así, cada vez que se ejecutara el script se estimarían modelos ligeramente diferentes.
Una vez ejecutada la orden anterior, el resultado lo puedes ver con
No será muy excitante, incluso será impenetrable e inescrutable.
## A LDA_VEM topic model with 4 topics.Esto lo que quiere decir es que se ha creado un modelo con cuatro tópicos y que ha utilizado el algoritmo VEM (= Variational Expectation Maximization), de lo cual vamos a pasar porque las matemáticas en las que se basan son realmente enredadas. Si quieres echarles una ojeada, en este enlace tienes el manual de {topicmodels}.
Lo cierto es que ya tienes el modelo de tópicos construido, pero hay que extraerlo de paginas_lda para que sea compatible con el ecosistema tidydata que estás usando. Lo primero que hay que ver es la probabilidad de las palabras que hay en cada tópico. De nuevo, las cuestiones matemáticas son complejas, por lo que me limitaré a ir dando los pasos y explicando qué es lo que se hace en cada uno de ellos.
Lo primero es calcular la probabilidad de que una palabra pertenezca uno u otro tópico, pero lo quieres en el formato que ya conoces, por lo que hay que convertirlo con la función tidy() que construye una tabla (tibble) que resume todos los hallazgos estadísticos del modelo. Esas matemáticas son incomprensibles para el común de los mortales, pero realizan la magia que necesitas.
Cuando ejecutes en la consola
obtendrás una vieja conocida: el comienzo de una larga tabla.
## # A tibble: 63,604 × 3
## topic term beta
## <int> <chr> <dbl>
## 1 1 lenguaje 2.14e- 4
## 2 2 lenguaje 4.03e- 3
## 3 3 lenguaje 1.13e- 3
## 4 4 lenguaje 8.10e- 3
## 5 1 estructura 4.84e-26
## 6 2 estructura 8.64e- 4
## 7 3 estructura 3.59e- 3
## 8 4 estructura 5.05e- 4
## 9 1 adecuación 6.80e-26
## 10 2 adecuación 9.83e- 4
## # ℹ 63,594 more rowsEsta tabla tiene tres columnas. La primera, topic, indica el número de tópico; la segunda ofrece las palabras –term– que aparecen en el conjunto de datos y, por último, la columna beta informa de la probabilidad de que el término haya sido generado por el tópico. Cuanto más cerca esté un valor de 1, tanto más probable es que una palabra –term– sea parte del tópico –topic–. Pero… te lo ha presentado en notación científica que, si bien es cómoda entre los matemáticos, al resto de la humanidad le cuesta un poco.
Vas a ver los cinco primeros términos más probables para cada tópico, pero para que puedas verlo con números más fáciles, ejecuta en la consola esta orden
que hará que en la mayoría los casos los números muy pequeños se impriman con todos los ceros pertinentes, aunque ya te he dado una buena pista de cómo solucionar el problema, si es que lo es. Como te decía, vas a ver los cinco primeros términos más probables para cada tópico y los vas a guardar en una tabla llamada terminos_frecuentes.
terminos_frecuentes <- paginas_lda_td %>%
group_by(topic) %>%
top_n(5, beta) %>%
ungroup() %>%
arrange(topic, -beta)Lo que acabas de hacer ha sido extraer los datos de paginas_lda_td, agrupándolos –group_by()– por topic (tópico). Le pides que solo extraiga los cinco más probables para cada tópico top_n(), lo cual viene determinado por el valor de beta. Que los desagrupe –ungroup()– y ordene –arrange()– los tópicos de mayor a menor probabilidad, de ahí el argumento -beta. El resultado lo puedes ver con
que imprirá esta tabla
## # A tibble: 20 × 3
## topic term beta
## <int> <chr> <dbl>
## 1 1 voltaire 0.0140
## 2 1 ser 0.00600
## 3 1 maquiavelo 0.00584
## 4 1 historia 0.00561
## 5 1 moral 0.00363
## 6 2 chomsky 0.0126
## 7 2 voltaire 0.0120
## 8 2 ser 0.00663
## 9 2 lingüística 0.00505
## 10 2 gramática 0.00449
## 11 3 freud 0.0208
## 12 3 hombre 0.00498
## 13 3 ser 0.00457
## 14 3 decir 0.00448
## 15 3 psicoanálisis 0.00378
## 16 4 maquiavelo 0.0142
## 17 4 lenguaje 0.00810
## 18 4 príncipe 0.00763
## 19 4 ser 0.00697
## 20 4 teoría 0.00526Una simple ojeada a la tabla puede permitirte establecer que el tópico 1 tiene que ver con Voltarie, que el 2 con Freud, el 3 con Maquiavelo y el 4 con Chomsky. No solo porque aparezcan los nombres de estos cuatro pensadores en cada uno de ellos, sino por algunos de los términos. De hecho, en el tópico 4 todos han podido ser generados por un texto que hable de Chomsky; los términos príncipe, política y secretario del tópico 3 se pueden asociar con Maquiavelo; psicoanálisis del tópico 2 con Freud, etc. Sin embargo, es más fácil ver estos datos con una gráfica en la que puedes observar a simple vista los cinco términos (term) y la probabilidad más alta (beta) de que hayan sido generados por cada uno de los cuatro tópicos.
La gráfica de la figura 9.5 se consigue con estas líneas de código, que a estas alturas ya deben serte claras.
terminos_frecuentes %>%
mutate(term = reorder(term, beta)) %>%
ggplot(aes(term, beta, fill = factor(topic))) +
geom_col(show.legend = FALSE) +
facet_wrap(~ topic, scales = "free") +
coord_flip()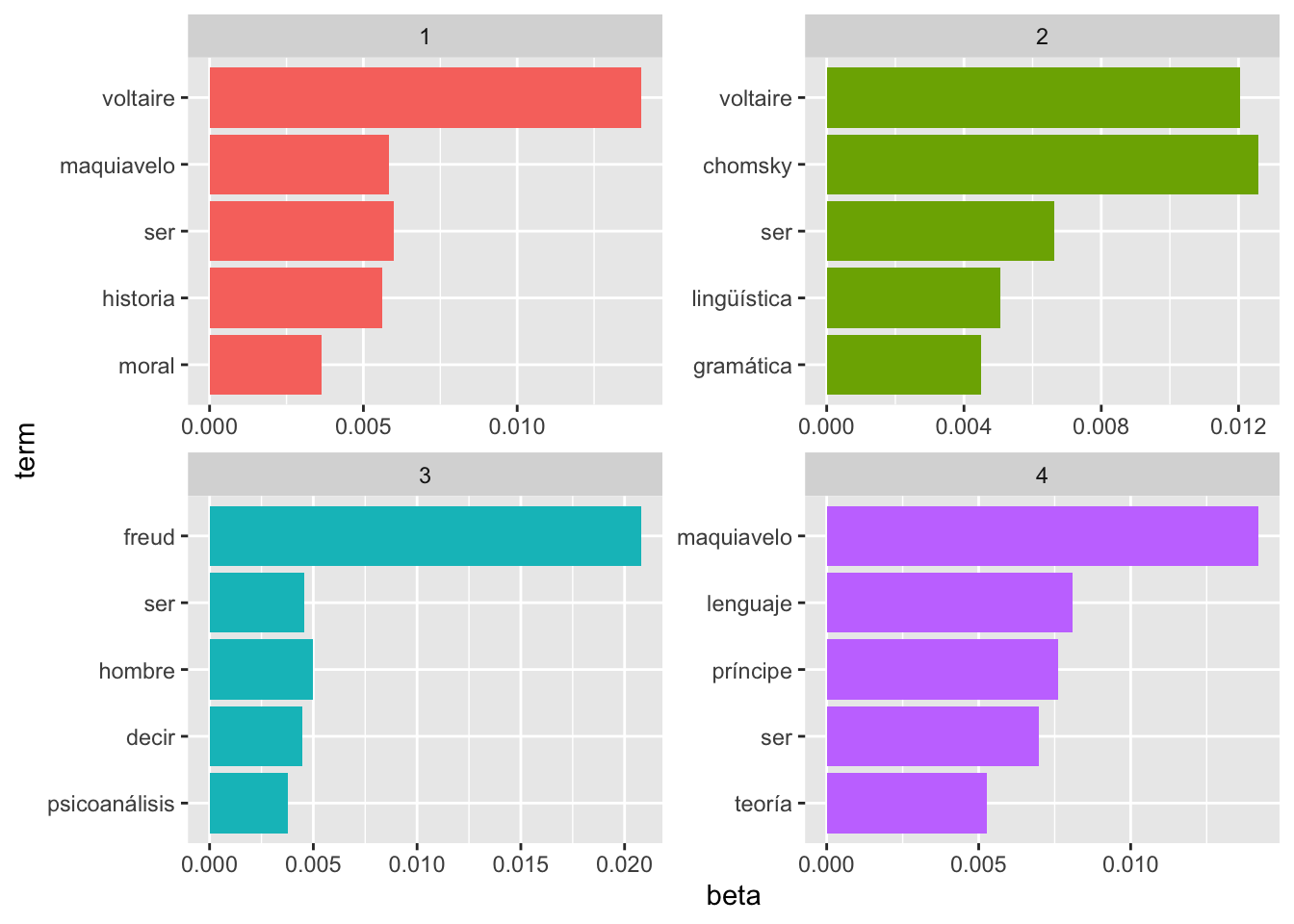
Figura 9.5: Tópicos y palabras que conforman el legajo
Un punto importante en todo este proceso es que la función LDA() no etiqueta, es decir, no identifica cada uno de los tópicos. Son sencillamente los tópicos 1, 2, 3 y 4. A partir de esto, puedes inferir que están asociados con cada uno de los textos. Pero ten en cuenta que es una mera inferencia personal.
9.4.2 Clasificación por documento
Cada uno de los folios del supuesto legajo es un documento. Por lo tanto, es hora de conocer qué tópicos se asocian con cada folio (documento). La pregunta es ¿podrías agrupar los folios que hablan de cada uno de los filósofos y crear cuatro montones? No estoy diciendo que los ordene secuencialmente, tan solo que los apile. Las máquinas pueden hacer muchas cosas, pero no tantas.
Hace un rato usaste la función tidy() para calcular la probabilidad de que un término procediera de un tópico u otro. Ahora la vuelves a emplear para calcular la probabilidad de que una página participe de uno u otro tópico y puedas establecer si es sobre uno u otro pensador. La función es prácticamente la misma, lo único que cambia es el valor del argumento matrix, que pasa a ser gamma.
Puedes examinar el contenido de esta nueva tabla con
lo que imprimirá este resultado
## # A tibble: 1,456 × 3
## document topic gamma
## <chr> <int> <dbl>
## 1 Chomsky_33 1 0.000144
## 2 Chomsky_59 1 0.000141
## 3 Chomsky_32 1 0.000143
## 4 Chomsky_56 1 0.000130
## 5 Maquiavelo_72 1 0.000133
## 6 Chomsky_38 1 0.000145
## 7 Chomsky_39 1 0.000151
## 8 Freud_59 1 0.000139
## 9 Maquiavelo_94 1 1.000
## 10 Voltaire_21 1 0.000145
## # ℹ 1,446 more rowsPuedes ver que, entre las 10 primeras páginas (document) de las 1456 que constituyen el corpus, la única que tienen una probabilidad de 1 (puede ser 1 –altísima– o 0 –bajísima–) de que esas páginas procedan del tópico 1, es Voltaire_21 mientras que las demás están bastante alejadas. Es el momento de ver cuántas páginas de cada filósofo están dentro del tópico que ha establecido el modelo. Es algo que puedes ver con un gráfico, que es mucho más cómodo que una larguísima tabla de números.
9.4.3 Gráfico de los tópicos
Pero antes de poder trazar el gráfico tienes que separar los nombres de las páginas para poder etiquetar los tópicos con los nombres de los filósofos y no con el indescifrable 1, 2, 3 y 4. Lo consigues con
paginas_lda_gamma <- paginas_lda_gamma %>%
separate(document,
c("titulo", "pagina"),
sep = "_", convert = TRUE)Lo que le estás diciendo a R es que en la misma tabla paginas_lda_gamma separe en dos columnas nuevas –titulo y pagina– el contenido de la columna document y que la frontera entre los dos elementos es un guion bajo sep="_". El contenido de paginas_lda_gamma es semejante al que has visto en la tabla de resultados anterior, solo que esta vez ha desaparecido la columna document y en su lugar están titulo, que contiene el nombre del pensador, y pagina, que recoge el número de la misma. Lo puedes ver si ejecutas en la consola
que mostrará el comienzo de la tabla
## # A tibble: 1,456 × 4
## titulo pagina topic gamma
## <chr> <int> <int> <dbl>
## 1 Chomsky 33 1 0.000144
## 2 Chomsky 59 1 0.000141
## 3 Chomsky 32 1 0.000143
## 4 Chomsky 56 1 0.000130
## 5 Maquiavelo 72 1 0.000133
## 6 Chomsky 38 1 0.000145
## 7 Chomsky 39 1 0.000151
## 8 Freud 59 1 0.000139
## 9 Maquiavelo 94 1 1.000
## 10 Voltaire 21 1 0.000145
## # ℹ 1,446 more rowsDe nuevo, leer largas tablas de números es muy poco iluminador, por lo que hay que ofrecer los datos visualmente, por medio de un histograma o gráfica de barras. Para ello usas esta orden de ggplot()
ggplot(paginas_lda_gamma, aes(gamma, fill = factor(topic))) +
geom_histogram() +
facet_wrap(~ titulo, nrow = 2)Al ejecutarlo aparecerá en la consola el siguiente mensaje. No tienes que preocuparte de nada. Es un mero aviso de R. En el panel Plots se dibujará la gráfica de la figura 9.6.
## `stat_bin()` using `bins = 30`. Pick better value with
## `binwidth`.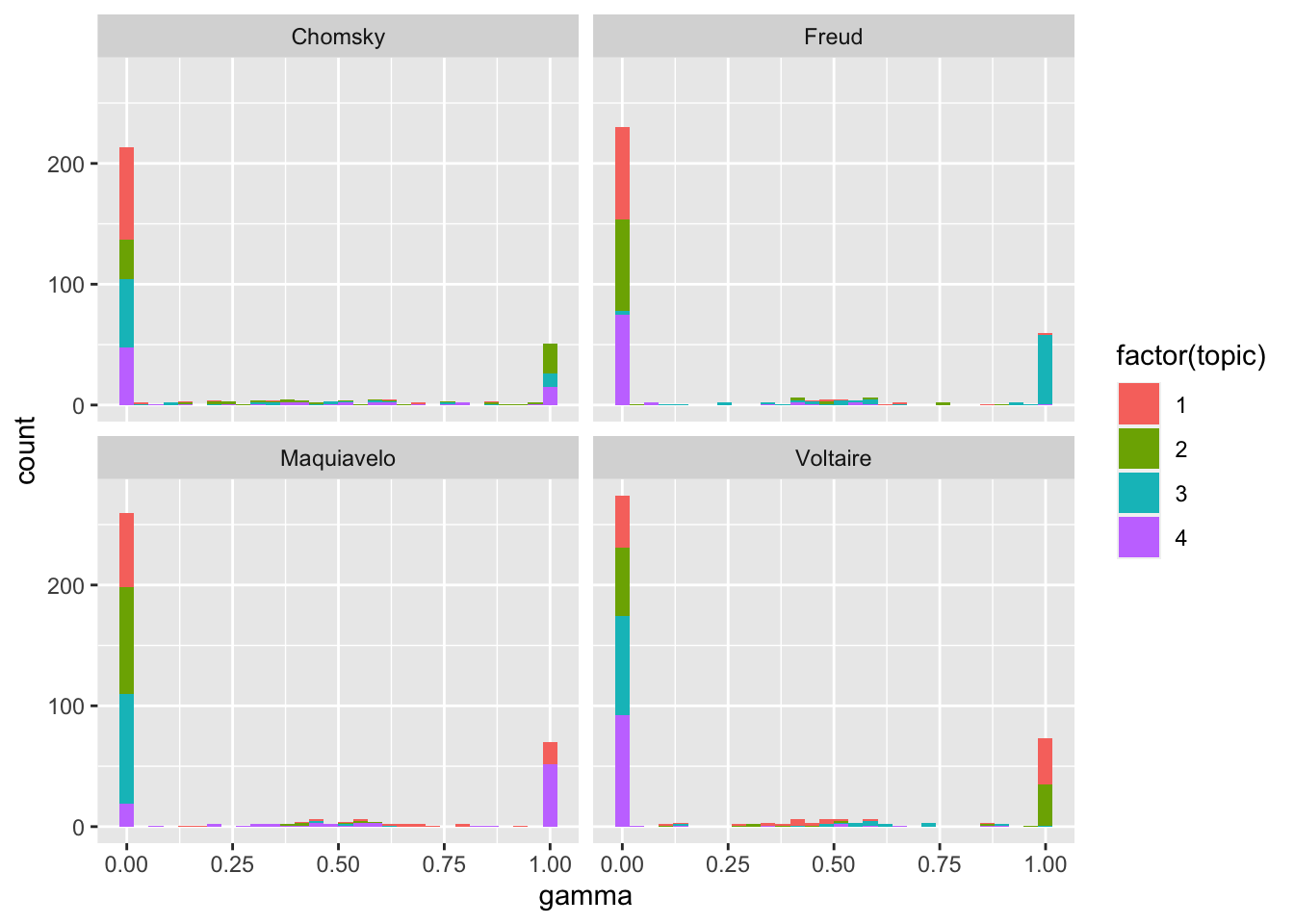
Figura 9.6: Asociación de páginas y tópicos
Como puedes ver en la figura 9.6, en todos los casos la mayoría de las páginas se asocian con un único tópico. Voltaire es el que más páginas tienen problemas de asignación, aunque la mayor parte de los problemas son en realidad una baja estimación (probabilidad) de que las páginas sean del tópico 1 sean de un texto sobre Voltaire. Pero hay numerosas páginas que tienen sus pequeños problemas de asociación con uno u otro tópico. Puedes averiguar qué tópico se asocia mejor con qué página con top_n(), lo cual que ofrecerá la clasificación otorgada a esa página. Copia el siguiente bloque de código y ejecútalo.
paginas_clasificaciones <- paginas_lda_gamma %>%
group_by(titulo, pagina) %>%
top_n(1, gamma) %>%
ungroup() %>%
arrange(gamma)Lo que has creado es una nueva tabla llamada paginas_clasificaciones con los datos de paginas_lda_gamma. Primero agrupas los datos por titulo y pagina con group_by(); le pides que seleccione la máxima clasificación para cada página con top_n() de acuerdo con el cálculo de gamma; que deshaga la agrupación con ungroup() porque ya no tiene interés; y que, por último, reorganice con la función arrange() los resultados de acuerdo con el valor de gamma. Para ver los resultados de toda estas instrucciones, ejecuta en la consola
que imprimirá el comienzo de la tabla
## # A tibble: 364 × 4
## titulo pagina topic gamma
## <chr> <int> <int> <dbl>
## 1 Chomsky 20 2 0.348
## 2 Voltaire 20 4 0.357
## 3 Chomsky 72 2 0.438
## 4 Maquiavelo 24 1 0.500
## 5 Maquiavelo 67 2 0.501
## 6 Voltaire 92 4 0.503
## 7 Chomsky 47 3 0.513
## 8 Voltaire 19 1 0.514
## 9 Freud 77 3 0.514
## 10 Maquiavelo 21 3 0.517
## # ℹ 354 more rowsAhora puedes establecer el tópico de consenso para cada pensador, es decir, el tópico más común para cada una de sus páginas y ver cuáles son las páginas que se han clasificado erróneamente. Para ello necesitas crear una nueva tabla con los tópicos de cada pensador que llamarás topico_pensador. Es muy parecido al tipo de clasificación que lograste en el paso anterior, solo que esta vez creas una nueva columna con transmute() llamada consenso que combina los valores de titulo y topic. Esto te permitirá ver, textualmente, lo que viste gráficamente. Esta confirmación la consigues con
topico_pensador <- paginas_clasificaciones %>%
count(titulo, topic) %>%
group_by(titulo) %>%
top_n(1, n) %>%
ungroup() %>%
transmute(consenso = titulo, topic)Una vez procesado lo anterior, puedes ver el resultado en la consola con
lo que te presentará esta tabla
## # A tibble: 4 × 2
## consenso topic
## <chr> <int>
## 1 Chomsky 2
## 2 Freud 3
## 3 Maquiavelo 4
## 4 Voltaire 1Es decir, el tópico 2 corresponde a Chomsky, el 4 a Maquiavelo, el 3 a Freud y el 1 a Voltaire.
Puedes ver cuáles son las páginas erróneamente asignadas con
paginas_clasificaciones %>%
inner_join(topico_pensador, by = "topic") %>%
filter(titulo != consenso)La orden anterior lo que hace es extraer de paginas_clasificaciones aquellas páginas que el modelo no asignó correctamente. Para ello, añadirá con inner_join() la columna consenso de topico_pensador por medio del valor de la columna topic y después extraerá con filter() todas aquellas filas en las que titulo y consenso no sean iguales !=. El resultado es
## # A tibble: 155 × 5
## titulo pagina topic gamma consenso
## <chr> <int> <int> <dbl> <chr>
## 1 Voltaire 20 4 0.357 Maquiavelo
## 2 Maquiavelo 24 1 0.500 Voltaire
## 3 Maquiavelo 67 2 0.501 Chomsky
## 4 Voltaire 92 4 0.503 Maquiavelo
## 5 Chomsky 47 3 0.513 Freud
## 6 Maquiavelo 21 3 0.517 Freud
## 7 Voltaire 28 3 0.519 Freud
## 8 Voltaire 48 2 0.520 Chomsky
## 9 Freud 78 1 0.521 Voltaire
## 10 Chomsky 14 4 0.522 Maquiavelo
## # ℹ 145 more rowsHay 54 páginas que el modelo no fue capaz de asignar correctamente. Quizá sea un pequeño fracaso, hay casi un error del 15 %. Pero ten en cuenta que la máquina no sabe nada de filosofía ni quiénes eran estos pensadores. Recuerda que lo que has usado ha sido un sistema no supervisado, es decir, has dejado a la máquina que tome todas las decisiones. Por lo tanto, no está tan mal.
9.4.4 Asignaciones por palabras
Uno de los pasos que da LDA es asignar cada una de las palabras de cada documento, página en tu caso, a un tópico. Por lo tanto, cuantas más palabras de una página sean asignadas a un tópico, el peso (gamma) será mayor para establecer la clasificación. Puedes averiguar qué palabras de cada página asignó el algoritmo a cada tópico.
De nuevo tienes que extraer datos de un objeto peculiar paginas_lda. Para ello usarás la función augment(), es similar a la tidy() que usaste antes, pero esta vez lo que ocurrirá es que utilizará el modelo para añadir información a los datos originales que tienes guardados en paginas_dtm, aquella enorme matriz que creaste y cuyo contenido era una grandísima tabla de 364 filas y 15 900 columnas, es decir, 5 732 358 casillas. Empieza por crear la tabla de las asignaciones.
Una vez creada, revisa su contenido con
que te ofrecerá este resultado
## # A tibble: 55,301 × 4
## document term count .topic
## <chr> <chr> <dbl> <dbl>
## 1 Chomsky_33 lenguaje 15 4
## 2 Chomsky_59 lenguaje 5 3
## 3 Chomsky_32 lenguaje 13 4
## 4 Chomsky_56 lenguaje 1 2
## 5 Chomsky_38 lenguaje 11 4
## 6 Chomsky_39 lenguaje 8 4
## 7 Chomsky_25 lenguaje 5 4
## 8 Chomsky_26 lenguaje 5 4
## 9 Chomsky_31 lenguaje 1 4
## 10 Chomsky_34 lenguaje 10 4
## # ℹ 55,291 more rowsEsta nueva tabla contiene el recuento de los términos de cada página y ha añadido una nueva columna, .topic, que indica al tópico a que se ha asignado la palabra (term) dentro de cada página (document). Una vez que tienes esta tabla, puedes combinarla con la tabla de consenso que creaste en topico_pensador para ver qué palabras son las que no ha logrado asignar correctamente:
asignaciones <- asignaciones %>%
separate(document, c("titulo",
"pagina"),
convert = TRUE) %>%
inner_join(topico_pensador,
by = c(".topic" = "topic"))Revisa el resultado con
que te imprimirá este comienzo de tabla
## # A tibble: 55,301 × 6
## titulo pagina term count .topic consenso
## <chr> <int> <chr> <dbl> <dbl> <chr>
## 1 Chomsky 33 lenguaje 15 4 Maquiavelo
## 2 Chomsky 59 lenguaje 5 3 Freud
## 3 Chomsky 32 lenguaje 13 4 Maquiavelo
## 4 Chomsky 56 lenguaje 1 2 Chomsky
## 5 Chomsky 38 lenguaje 11 4 Maquiavelo
## 6 Chomsky 39 lenguaje 8 4 Maquiavelo
## 7 Chomsky 25 lenguaje 5 4 Maquiavelo
## 8 Chomsky 26 lenguaje 5 4 Maquiavelo
## 9 Chomsky 31 lenguaje 1 4 Maquiavelo
## 10 Chomsky 34 lenguaje 10 4 Maquiavelo
## # ℹ 55,291 more rowsLo que en realidad has conseguido es separar el nombre del pensador y el número de la página, algo que ya hiciste hace rato, y has añadido la columna consenso basándote en el valor de topic. Con estos datos puedes dibujar una matriz de confusión, una gráfica interesante que permite visualizar con rapidez qué tal funcionó el modelo (figura 9.7).
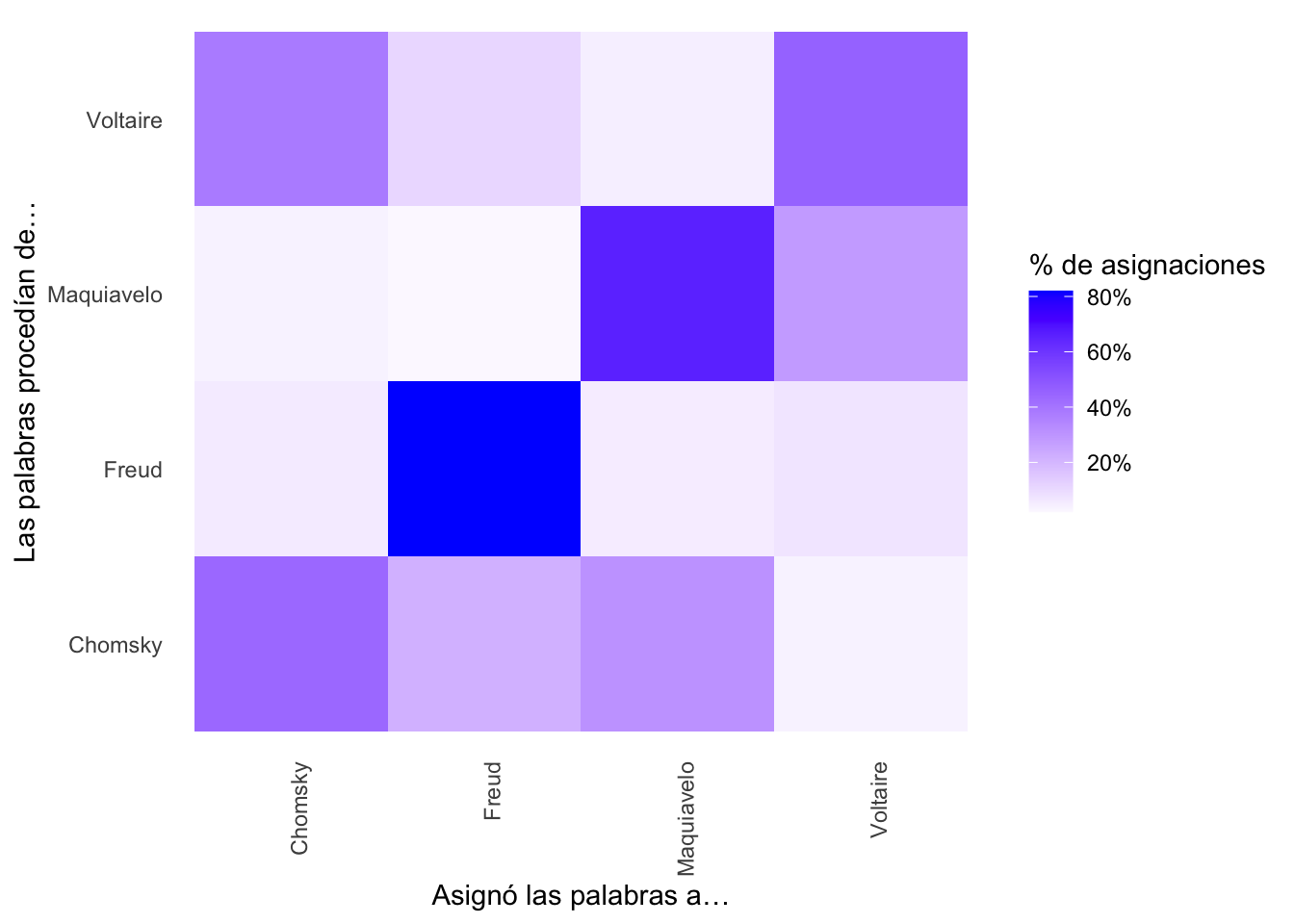
Figura 9.7: Matriz de confusión de los folios del legajo
Como de costumbre, la orden para dibujarla es compleja, pero bastante clara a estas alturas.
asignaciones %>%
count(titulo, consenso, wt = count) %>%
group_by(titulo) %>%
mutate(porcentaje = n / sum(n)) %>%
ggplot(aes(consenso, titulo, fill = porcentaje)) +
geom_tile() +
scale_fill_gradient2(high = "blue", label = percent_format()) +
theme_minimal() +
theme(axis.text.x = element_text(angle = 90, hjust = 1),
panel.grid = element_blank()) +
labs(x = "Asignó las palabras a…",
y = "Las palabras procedían de…",
fill = "% de asignaciones")Como puedes ver en el gráfico de la figura 9.7, la mayoría de las palabras referidas a Chomsky, Maquiavelo y Freud están correctamente asignadas. Es Voltaire el que concentra el mayor número de palabras equivocadas. ¿Cuáles son esas palabras? Puedes hallarlas con facilidad. Tan solo tienes que localizar en asignaciones qué palabras no coinciden en el titulo y el consenso
El resultado es una tabla con 22579 términos. Échale una ojeada ejecutando en la consola
lo que imprirá en la consola
## # A tibble: 22,579 × 6
## titulo pagina term count .topic consenso
## <chr> <int> <chr> <dbl> <dbl> <chr>
## 1 Chomsky 33 lenguaje 15 4 Maquiavelo
## 2 Chomsky 59 lenguaje 5 3 Freud
## 3 Chomsky 32 lenguaje 13 4 Maquiavelo
## 4 Chomsky 38 lenguaje 11 4 Maquiavelo
## 5 Chomsky 39 lenguaje 8 4 Maquiavelo
## 6 Chomsky 25 lenguaje 5 4 Maquiavelo
## 7 Chomsky 26 lenguaje 5 4 Maquiavelo
## 8 Chomsky 31 lenguaje 1 4 Maquiavelo
## 9 Chomsky 34 lenguaje 10 4 Maquiavelo
## 10 Chomsky 27 lenguaje 2 4 Maquiavelo
## # ℹ 22,569 more rowsComo puedes, hay una serie de palabra que a menudo las ha asignado a Chomsky y Maquiavelo, aunque también aparecen en Voltaire. Por otra parte, lenguaje y estructura son palabras que el modelo ha asignado a Chomsky porque son mucho más corrientes entre las páginas sobre Chomsky, lo que se puede confirmar con una simple revisión del conteo de las palabras como este
palabras_equivocadas %>%
count(titulo, consenso, term, wt = count) %>%
ungroup() %>%
arrange(desc(n))que te ofrecerá una tabla como esta
## # A tibble: 14,972 × 4
## titulo consenso term n
## <chr> <chr> <chr> <dbl>
## 1 Voltaire Chomsky voltaire 171
## 2 Chomsky Maquiavelo lenguaje 149
## 3 Maquiavelo Voltaire maquiavelo 77
## 4 Chomsky Freud frase 66
## 5 Chomsky Maquiavelo teoría 65
## 6 Chomsky Maquiavelo lingüística 64
## 7 Chomsky Freud estructura 55
## 8 Chomsky Maquiavelo chomsky 55
## 9 Chomsky Maquiavelo mente 53
## 10 Chomsky Freud gramática 46
## # ℹ 14,962 more rowsTen en cuenta que el modelo es estocástico e iterativo, es decir, aleatorio y repetitivo, por lo cual no debe sorprenderte que tenga problemas cuando un tópico aparece en varios textos (documentos) a la vez.
9.5 Limitaciones del topic modeling
Según C. Bail el topic modeling se han convertido en una herramienta estándar dentro del análisis de texto cuantitativo por muchas razones. Para este investigador, el modelado de tópicos puede ser mucho más útil que los análisis basados en la frecuencia de palabras simples o en diccionarios, aunque depende de cada caso concreto. El modelado de tópicos tiende a producir los mejores resultados cuando se aplica a textos que no son demasiado cortos, y aquellos que tienen una estructura consistente, como es caso de textos literarios o ensayísticos.
Pero, al mismo tiempo, el topic modeling tiene una serie de limitaciones. Para comenzar, el mismo término topic es equívoco y, por el momento, el topic modeling no puede ofrecer una clasificación de los textos altamente refinada. Por otra parte, el modelado de tópicos puede servir para ofrecer una interpretación errada del significado de un texto. Estas herramientas es mejor considerarlas como ayudas a la lectura. Los resultados de un modelado de tópicos no deben ser interpretados en demasía a menos que el investigador tenga una fuerte base teórica acerca de los tópicos de un corpus dado o si ha validado cuidadosamente los resultados, tanto cuantitativa como cualitativamente.
9.6 Práctica
Esta manera de abordar el topic modeling está basada y desarrollada en el modelo presentado por Robinson y Silge. Estos usan cuatro obras literarias extensas: 20.000 leguas de viaje submarino, Grandes esperanzas, La guerra de los mundos y Orgullo y prejuicio, evidentemente en inglés. Buscaron cuatro obras de temática muy dispar para minimizar los fallos. Te propongo que reescribas las porciones adecuadas del script que hay a lo largo de las explicaciones precedentes para que puedas analizar estas cuatro obras que las puedes bajar del repositorio del proyecto. Puesto que no se trata de dividir en páginas sino en capítulos, te ofrezco el comienzo del script hasta la división en capítulos.
# Carga las librerías
library(tidyverse)
library(tidytext)
library(tm)
library(topicmodels)
library(scales)
# Evita la notación científica
options(scipen=999)
# Carga la lista de palabras vacías
vacias <- read_tsv("https://raw.githubusercontent.com/7PartidasDigital/AnaText/master/datos/diccionarios/vacias.txt")
# Los textos los lees desde un repositorio externo
ruta <- "https://raw.githubusercontent.com/7PartidasDigital/AnaText/master/datos/textos/"
# Localiza los textos
titulos <- c("20000 leguas de viaje submarino",
"Grandes esperanzas",
"La guerra de los mundos",
"Orgullo y Prejuicio")
ficheros <- c("20000LeguasViajeSubmarino.txt",
"GrandesEsperanzas.txt",
"LaGuerraDeLosMundos.txt",
"OrgulloPrejuicio.txt")
# Crea la tabla en que guardará todo los textos
novelas <- tibble(texto = character(),
titulo = character())
# Lee los textos
for (i in 1:length(titulos)) {
texto <- read_lines(paste(ruta,
ficheros[i],
sep = ""))
temporal <- tibble(texto = texto,
titulo = titulos[i])
novelas <- bind_rows(novelas, temporal)
}
# Los divide por capítulos
por_capitulo <- novelas %>%
group_by(titulo) %>%
mutate(capitulo = cumsum(str_detect(texto,
regex("^cap[í|i]tulo ",
ignore_case = TRUE)))) %>%
ungroup() %>%
filter(capitulo > 0)
# Una mirada al resultado parcial…
por_capitulo
# Aquí sigues tú…Los tres gráficos que has de obtener se deben parecer a los que tienes a continuación.
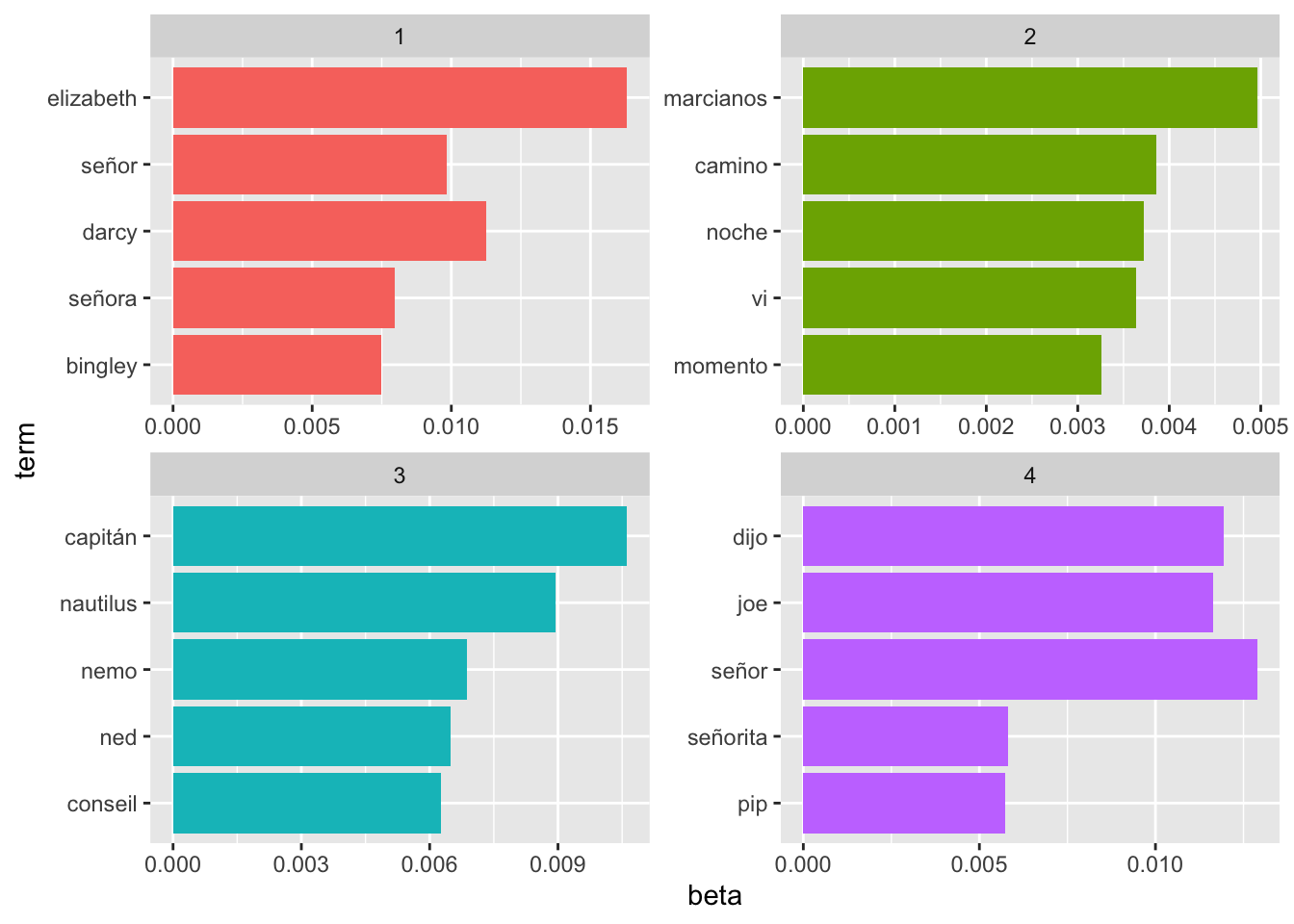
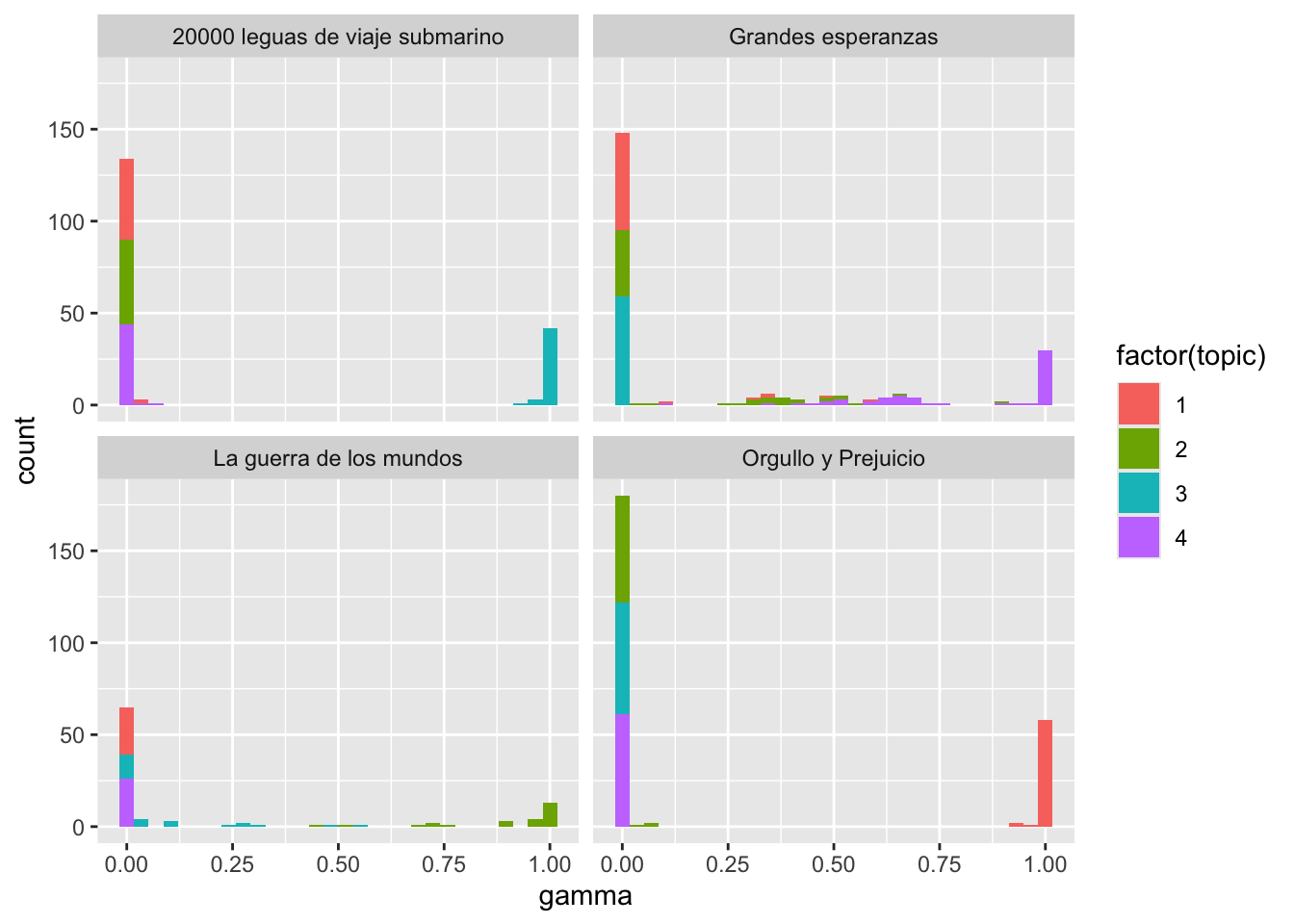
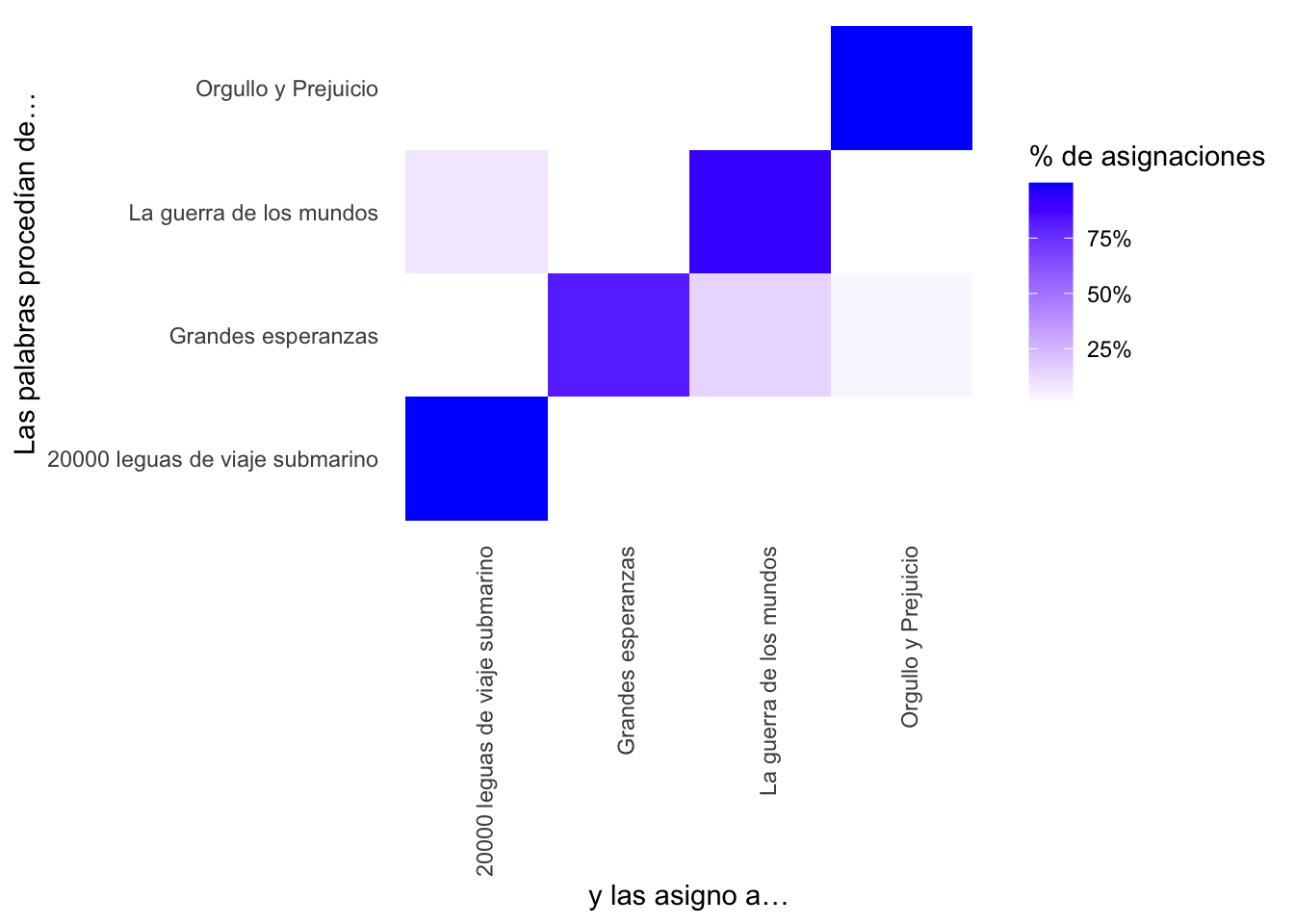
¿Qué conclusiones extraes de las tres gráfica anteriores?
