10 Análisis de atribución de autoría
10.1 Introducción
La estilometría, como ya indiqué, es el análisis estadístico de los textos literarios. Sin embargo, para muchos se ha convertido en un sinónimo de los análisis de atribución de autoría, que es uno de los problemas filológicos que más tinta hace correr y que se remonta a una vieja discusión académica: la llamada Shakespeare authorship question, o lo que es lo mismo: si Shakespeare escribió Shakespeare. Es un debate que surgió a mediados del siglo XIX y cuenta con cuatro candidatos básicos:
- Edward de Vere, 17º Conde de Oxford
- Francis Bacon
- Christopher Marlowe y
- William Stanley, 6º Conde de Derby.

Figura 10.1: Los cuatro personajes que ha sido propuestos como auténticos autores. Fuente: Wikipedia
La primera aproximación al problema fue la de Mendenhall, reflejada en su artículo «A Mechanical solution of a literary problem». La solución mecánica consistió en contar las letras de cada una de las palabras de las obras de Shakespeare y comparar la longitud de las palabras de las obras atribuidas a Shakespeare con los sospechosos habituales.
El procedimiento era muy sencillo: una persona leía una palabra, contaba el número de letras y lo anunciaba en voz alta; otra apretaba el botón adecuado (uno para cada número) en una máquina registradora construida al efecto. Procedieron así a lo largo de dos millones de palabras (400 000 eran de Shakespeare). La conclusión a la que llegaron era que la longitud de palabra más usual en Shakespeare era de cuatro letras, «a thing never met with before» (Mendenhall 1901, 102).
El laborioso procedimiento de Mendenhall debió influir para que nadie se ocupara de los problemas de estilometría hasta principios de la década de 1960 con el llamado caso de los Federalist Papers.
10.1.1 Los Federalist Papers

Figura 10.2: Portada de la recopilación de los artículos. Fuente: Wikipedia
Los Federalist Papers es una serie de 85 ensayos publicados anónimamente, bajo el seudónimo Publius, para persuadir a los norteamericanos de que ratificaran la nueva constitución. Se sabe que los escribieron Alexander Hamilton, James Madison y John Jay. Sin embargo, doce de ellos los reclamaban como propios Hamilton y Madison. La solución vino de la mano de dos estadistas norteamericanos, Mosteller y Wallace (1964). Estos, basándose en la frecuencia de uso de palabras gramaticales (function words) como discriminadores de estilo, establecieron la autoría de cada uno de los doce ensayos disputados. Así, pudieron ver, por ejemplo, que la preposición upon aparecía 3.24 veces por cada 1 000 palabras en los escritos de Hamilton frente a 0.23 en los de Madison. En cambio, este prefería la palabra whilst frente while, que era la favorecida por Hamilton (0.47) pero inexistente en Hamilton (0), y, por el contrario, Hamilton usaba enough (0.59) frente a la ausencia en Madison (0).
disputados, Hamilton, Jay y Madison. En realidad son textos planos descargados de Project Gutenberg.
Esto llevó a la constatación de que pueden ser mucho más interesantes las palabras gramaticales (Halleleeck), las function words, las que borrábamos al considerarlas vacías, que las semánticas para establecer la huella lingüística de un autor porque las gramaticales no dependen del contexto, del tema ni del género y, además, las palabras gramaticales se usan de manera inconsciente, con lo que son más capaces de atrapar las selecciones estilísticas de los diferentes autores, aunque se puede jugar con muchos otros marcadores de estilo como la longitud de palabras, de las oraciones, las palabras gramaticales, distribución de letras, colocaciones, etc.
10.1.2 Casos de autoría de un verano pasado
El verano de 2018 fue prolífico en el planteamiento de problemas de autoría. Hubo dos casos: uno en España y otro en Estados Unidos.
El 5 de septiembre el The New York Times publicó un artículo de opinión titulado «I’m Part of the Resistence Inside the Trump Administration». El problema fue que, por primera vez en la historia, esta cabecera norteamericana publicaba un artículo de opinión anónimo. La consecuencia inmediata fue que una legión de comentaristas se lanzó a la caza del posible autor. Algunos vieron que se usaba la palabra lodestar y por ese simple dato se le atribuyó al vicepresidente Mike Pence. Otros, con otros rasgos, siempre léxicos, se lo han atribuido a otros cargos de la administración Trump. Es muy difícil saber quién pudo ser el autor: el elenco de candidatos es amplio y obtener muestras de escritos de todos ellos es misión imposible. La solución que han tomado algunos analistas ha sido extraer datos de los tuits de todo ese personal, pero no es una solución válida (Robinson, Kearney, o Misra; estos tres hicieron los análisis con R).
Una semana más tarde se montó un gran revuelo cuando Albert Rivera puso en duda la legitimidad de la tesis del presidente del Gobierno, Pedro Sánchez. Primero que estaba plagiada, después que no la había escrito él, sino un negro (cfr. DLE, acepción 17), incluso llegaron a ponerle nombre. Estoy seguro de que la tesis defendida por Sánchez Castejón fue escrita por el mismo autor que la serie de artículos que bajo su nombre se han publicado en El País (figura 10.3). Otra cuestión es si el Sánchez Castejón que firma esos textos es el mismo Sánchez Castejón que es presidente del Gobierno. Pero ese es un problema para el que la estilometría no tiene solución alguna.
](https://pbs.twimg.com/media/DnEVitZXsAA8p7E?format=jpg&name=900x900)
Figura 10.3: Árbol de consenso de la tesis y artículos de Sánchez Castejón y candidatos propuestos con el paquete stylo. Fuente: Twitter
En las Navidades de 2018 el suplemento La otra crónica, encarte del periódico El Mundo, publicó (29.12.18) un artículo en el que se especulaba que Álvaro Durántez era «uno de los hombres del discurso del rey». Un análisis de grupos permitió ver que Durántez no puede ser el autor de ninguno de los discursos navideños de Felipe VI (figura 10.4).
. Fuente: [Twitter](https://twitter.com/JMFradeRue/status/1079467205467746305)](https://pbs.twimg.com/media/DvsJUvrXcAAt2Dw?format=jpg&name=900x900)
Figura 10.4: Árbol de consenso de los mensajes de Navidad de 2012-2018 y varios artículos de Durántez. El conjunto inferior son los discursos reales; el superior algunos artículos publicados por Durántez y cosechados en Dialnet. Fuente: Twitter
El inicio del verano de 2019 también fue interesante desde el punto de vista de la atribución de autoría. A mediados de junio, Rosa Navarro Durán, publicó en El Cultural un artículo en el que establecía que María de Zayas no existió y era el heterónimo de Alonso de Castillo Solórzano. De nuevo, un análisis de grupos permitió ver cuán errada era la propuesta, como lo muestra el árbol de consenso de la figura 10.5.
](https://pbs.twimg.com/media/D9-axpoW4AA1_dZ?format=jpg&name=medium)
Figura 10.5: Árbol de consenso de las obras de María de Zayas, Castillo Solórzano, Lope de Vega, Miguel de Cervantes, Mariana de Carvajal y Juan Pérez de Montalbán con el paquete stylo. Fuente: Twitter
10.2 Un experimento de atribución
En ocasiones anteriores enseñaba, partiendo del libro de Matthew L. Jockers (2014), a programar en R un script que permitía determinar si un texto era o no de un autor. Jockers lo hacía con una serie de novelistas norteamericanos, pero adapté su script para usarlo con textos españoles, por lo que seleccioné un conjunto de dieciocho novelas del siglo XIX-XX:
- 2 de Valera
- 3 de Acevedo Díaz
- 3 de Pardo Bazán
- 4 de Pereda
- 6 de Pérez Galdós
A estos añadí un texto que etiqueté anonimo.xml. El fichero anonimo contiene el primer Episodio Nacional de Benito Pérez Galdós: Trafalgar. La idea era ver si el algoritmo podía establecer la probable identidad del autor del texto anónimo agrupándolo, naturalmente, con su autor: Pérez Galdós.

Figura 10.6: Dendrograma de las novelas españolas según el script de Jockers (2014)
El dendrograma de la figura 10.6 es la representación gráfica del resultado de los cálculos que ha realizado el script y que han servido para detectar la señal de autoría, y lo ha hecho basándose en las palabras más frecuentes (MFW = most frquent words) de cada autor. Estas resultan ser las palabras gramaticales. Puedes ver que el texto anonimo.xml se encuentra, como era de esperar (pues partíamos del conocimiento previo), entre los de Galdós.
En un ensayo más amplio (Fradejas Rueda 2016) incluí la novela Cabo de Trafalgar y otras tres novelas más de Arturo Pérez-Reverte –El Asedio, El Húsar y Hombres buenos– por el sencillo hecho de que pretendía ver si al analizar dos de ellas, una de Pérez-Reverte y otra de Pérez Galdós, que tratan el mismo tema, la batalla naval de Trafalgar, podía provocar un problema de atribución. No lo hubo.
El dendrograma de la figura 10.7 lo demuestra: todas las obras de Pérez-Reverte forman un núcleo compacto y están muy alejadas de las de Pérez Galdós. Además, he complicado un poco más la cosa añadiendo cuatro obras de Valle-Inclán.

Figura 10.7: Dendrograma de las novelas españolas del XIX-XX y las de Pérez-Reverte y Valle-Inclán aplicando el script de Jockers (2014)
10.2.1 Análisis de grupos
El análisis de grupos (cluster analysis) es una técnica estadística que sirve para agrupar un conjunto de elementos, observaciones, en dos o más grupos de manera que los que se encuentran en un grupo (cluster) son mucho más semejantes entre ellos que los que se encuentran en otros grupos. El análisis de grupos lo que hace es maximizar las semejanzas a la vez que maximiza las diferencias que pueda haber entre los grupos, los cuales son desconocidos inicialmente.
Dentro de los varios algoritmos que se emplean para este tipo de análisis se encuentra el análisis jerárquico. Comienza considerando cada caso como un grupo separado, es decir, hay tantos grupos como casos, en nuestro caso textos. A continuación los combina secuencialmente, por lo que va reduciendo los grupos en cada paso del análisis hasta que al final solo queda un grupo. Este tipo de análisis se representa mejor por medio de un diagrama arbóreo, como los mostrados en las figuras 10.6 y 10.7, que se llama dendrograma.
Como de costumbre, los cálculos matemáticos que hay detrás de este tipo de análisis es complejo. Además, no hay una única fórmula y cada una tiene sus ventajas e inconvenientes. En el análisis de la autoría de anonimo.xml he usado la distancia euclídea, pero hay otras como la Delta, que es una de las más usadas en los problemas de autoría.
10.3 La librería {stylo}
Existe un paquete de R, llamado {stylo}, que puede hacer todo esto sin tenerte que preocupar de escribir un largo y complejo script. Vas a probarlo con los mismos textos. Sigue las instrucciones que hay a continuación.
{stylo}, debes instalar una porción de software que Apple ya no incorpora de serie en sus ordenadores. Para ello, ve a www.xquartz.org, descarga e instala el programa XQuartz. Si tu ordenador tienes un sistema operativo anterior a macOS 10.8 descarga e instalda esta versión (https://dl.bintray.com/xquartz/downloads/XQuartz-2.7.11.dmg). Si es macOS10.9 o posterior utlizada la versión 2.8.1 (https://github.com/XQuartz/XQuartz/releases/download/XQuartz-2.8.1/XQuartz-2.8.1.dmg). Una vez instalado … Vuelve a arrancar RStudio para que lo reconozca.
Lo primero de todo es instalar el paquete {stylo} con
10.3.1 Descargar el corpus de trabajo
Ahora has de descargar los ficheros de texto que están en el repositorio de 7PartidasDigital y los vas a guardar en un directorio de nueva creación que llamarás corpus. El directorio se crea con
No verás respuesta alguna. Puedes comprobar que se ha creado mirando la ventana Files. Ahí ha tenido que aparecer el directorio.
El vector ficheros contiene el nombre de todos los ficheros que vas a bajar del repositorio. He introducido un cambio de línea tras cada uno de ellos para que visualmente sea más claro y no se pierdan por el margen derecho.
ficheros <- c("Acevedo1.txt",
"Acevedo2.txt",
"Acevedo3.txt",
"anonimo.txt",
"Galdos1.txt",
"Galdos2.txt",
"Galdos3.txt",
"Galdos4.txt",
"Galdos5.txt",
"Galdos6.txt",
"Galdos7.txt",
"Pereda1.txt",
"Pereda2.txt",
"Pereda3.txt",
"Pereda4.txt",
"Valera1.txt",
"Valera2.txt",
"ValleInclan1.txt",
"ValleInclan2.txt",
"ValleInclan3.txt")Puesto que está en un repositorio externo, debes tener toda la url del sitio. La guardas en ruta.
Para bajarlo lo mejor es un bucle for que leerá cada uno de los ficheros y los grabará en el directorio que acabas de crear.
10.3.2 Explicación del código
Aunque ya lo sabes de ocasiones anteriores, te explico qué es lo que hace este bucle, en el que hay una interesante novedad. El número de veces que se ejecutará el bucle está determinado por la longitud length() de ficheros. Guardará en lee el fichero que lea con read_lines del repositorio externo. Para ello unirá con paste el contenido de ruta y el cambiante contenido de ficheros[i], que tiene el nombre exacto de cada uno de los ficheros que has de bajar. Como no te hace falta indicar ningún separador, el argumento está vacío sep = "". El último argumento de read_lines, locale = locale(), es el que se encarga de que las letras con diacríticos no se conviertan en cosas extrañas en las máquinas que corran con Windows.
La función write_lines es la responsable de grabar en el directorio corpus cada uno de los ficheros que bajes. Para eso, une la ruta "datos/corpus/" al nombre del fichero que contiene en cada vuelta ficheros[i] y los juntas sin nada entre ellos con sep = "".
Las funciones read_lines(), write_lines() y default_locale() no son funciones de la instalación básica de R, sino que forman parte de la librería {readr} que forma parte de la macrolibrería tidyverse. Como se trata de usar tan solo tres funciones de las varias centenas que constituyen el paquete {tidyverse}, las has invocado sin tener que cargarla. De esta manera evitas recargar la memoria del ordenador con algo que no vas a usar realmente.
La forma de usar funciones de una librería que tienes instalada en el ordenador, pero que no quieres cargar porque solo vas a usar dos o tres funciones, es anteponiendo el nombre de la librería al de la función y separar ambos elementos con dos secuencias de dos puntos ::. Fíjate que he escrito readr::write_lines(), read::default_locale() y readr::write_lines.
readLines() y writeLines(). El resultado habría sido el mismo, pero ha sido una manera de enseñarte un truco de programación.
Tras unos minutos, todo depende de tu ordenador y de tu conexión a internet, tendrás los veinte ficheros en el directorio corpus. Compruébalo con
La respuesta debe ser
## [1] "Acevedo1.txt" "Acevedo2.txt" "Acevedo3.txt" "anonimo.txt" "Galdos1.txt"
## [6] "Galdos2.txt" "Galdos3.txt" "Galdos4.txt" "Galdos5.txt" "Galdos6.txt"
## [11] "Galdos7.txt" "Pereda1.txt" "Pereda2.txt" "Pereda3.txt" "Pereda4.txt"
## [16] "Valera1.txt" "Valera2.txt" "ValleInclan1.txt" "ValleInclan2.txt" "ValleInclan3.txt"Si es así, ya tienes el material para utilizar el paquete stylo.
10.4 stylo en funcionamiento
Ya tienes el material recolectado para hacer el análisis. Antes de continuar quiero recordarte que una de las peculiaridades de {stylo} es que el directorio en el que buscará los datos se ha de llamar corpus y, además, tiene que estar dentro del directorio de trabajo. Si no lo haces así, provocará un error. Aunque ya lo has debido de hacer, pues te lo he dicho al principio de este capítulo, lo primero de todo es cambiar el directorio de trabajo a datos puesto que es ahí donde tienes los ficheros que acabas de bajar.
cuentapalabras variará dependiendo de la máquina. Así que si te es más sencillo, usa el menú superior de RStudio para cambiar el directorio de trabajo. Te recuerdo la sencuencia: Session > Set Working Directory > Choose Directory; localiza el subdirectorio datos y selecciónalo como directorio de trabajo haciendo clic sobre Open.
Carga la librería. Le llevará un ratito, tras lo cual aparecerá un mensaje de aviso sobre la conveniencia de citar correctamente el paquete.
##
## ### stylo version: 0.7.4 ###
##
## If you plan to cite this software (please do!), use the following reference:
## Eder, M., Rybicki, J. and Kestemont, M. (2016). Stylometry with R:
## a package for computational text analysis. R Journal 8(1): 107-121.
## <https://journal.r-project.org/archive/2016/RJ-2016-007/index.html>
##
## To get full BibTeX entry, type: citation("stylo")Ahora invoca la función
Una vez que hayas pulsado intro, en la consola de RStudio aparecerá el aviso
using current directory...tras lo cual se abrirá una ventana como la de la figura 10.8. Es posible que esté escondida detrás de la ventana de RStudio. La gran ventaja, en esta ocasión, es que no tienes que programar nada, aunque puedes hacerlo (más abajo te muestro cómo), tan solo pinchar unos pocos botones en la ventana que tiene cinco pestañas. Por defecto comienza en la llamada INPUT & LANGUAGE (el nombre aparece en gris claro).
Figura 10.8: Ventana INPUT & LANGUAGE de {stylo}
En esta solo tienes que marcar las casillas adecuadas. Como los ficheros que tienes en corpus están en texto plano, asegúrate que la casilla plain text tiene un punto negro. Lo siguiente es establecer la lengua. Como los textos son españoles, marca Spanish y, por último, la casilla Native Encoding.
Haz clic en la pestaña STATISTICS y selecciona Euclidean (figura 10.9); el botón Cluster Analysis estará seleccionado por defecto. No pulses el botón OK aún.
Figura 10.9: Ventana STATISTICS de {stylo}
Haz clic sobre la pestaña FEATURES y comprueba que en las tres primeras casillas de la línea que comienza MFW SETTINGS diga en todas ellas 100 (figura 10.10). No vas a usar más palabras por ahora.
Figura 10.10: Ventana STATISTICS de {stylo}. Selección de las 100 MFW
Tan pronto hayas hecho clic sobre OK toda la acción se traslada a la consola. Cargará los textos; los dividirá en tokens y te informará de que ha leído 20 textos y de que hay 1 881 014 tokens. Procesará los textos, es decir, calculará las frecuencias, y las combinará en una tabla y al cabo de unos segundos aparecerá en la ventana el dendrograma (figura 10.11). En esta ocasión aparecerá horizontal, pero podrías cambiarlo en la pestaña OUTPUT.
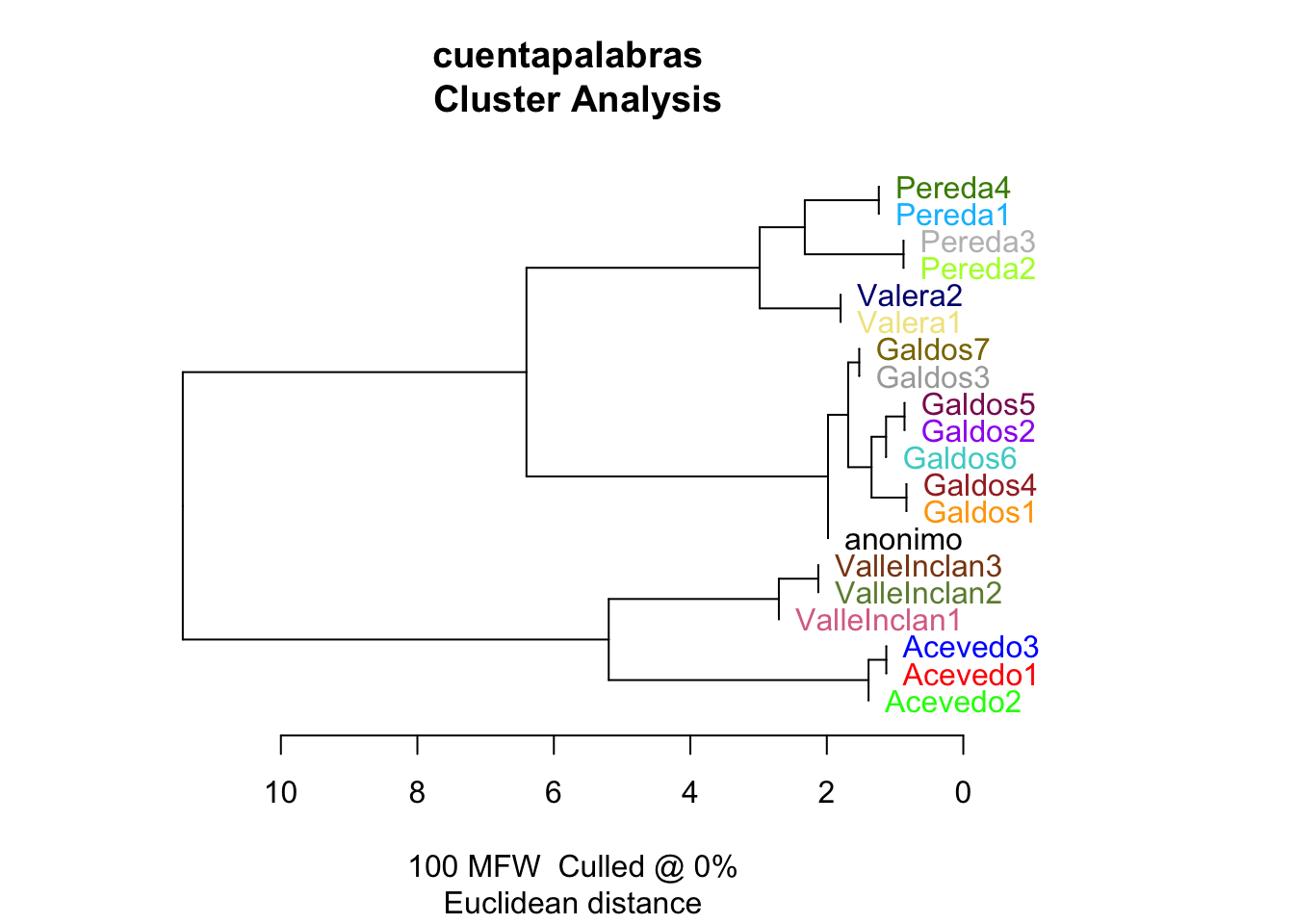
Figura 10.11: Dendrograma de las novelas con {stylo}
En el directorio de trabajo, cuentapalabras/datos, habrán aparecido cuatro ficheros que no tenías al comenzar. Los genera stylo() durante el proceso de análisis:
stylo_config.txtwordlist.txttable_with-frequnecies.txtdatos_CA_100_MFWs_Culled_0__Euclidean_EDGES.csv
En stylo_config.txt tienes toda la configuración que has usado en el análisis. En wordlist.txt está la lista de las palabras que ha considerado en el análisis. El fichero table_with-frequnecies.txt contiene una enorme tabla en la que aparece la frecuencia de aparición de cada palabra en cada uno de los textos considerados en el análisis. Por último, tienes el fichero datos_CA_100_MFWs_Culled_0__Euclidean_EDGES.csv. No tienes que preocuparte de esos ficheros, por ahora. Quizá, más adelante, cuando profundices en los resultados y quieras ir más allá en el uso de stylo() sea interesante revisarlos y usarlos e incluso pedirle que genere otros como la tabla de distancias.
10.4.1 Árbol de consenso
El paquete tiene muchas más posibilidades. Una de ellas es la de crear un árbol de consenso en vez de un sencillo dendrograma. El árbol de consenso es el resultado gráfico de trazar varios dendrogramas como el que acabas de ver y que corresponde a los mismos textos que has analizado hace un momento. El procedimiento con la librería stylo es muy sencillo. No tienes que salir de RStudio. Tan solo volver a invocar la librería
y cambiar unas pocas selecciones. Ve a la pestaña FEATURES e incrementa el valor de Maximum a 1000. En la pestaña STATISTICS tienes que marcar el botón que hay debajo de Consensus Tree. Cuando hagas clic en OK, stylo() calculará diez dendrogramas que después combinará en uno solo, en un árbol de consenso, que es el que tienes en la figura 10.12.
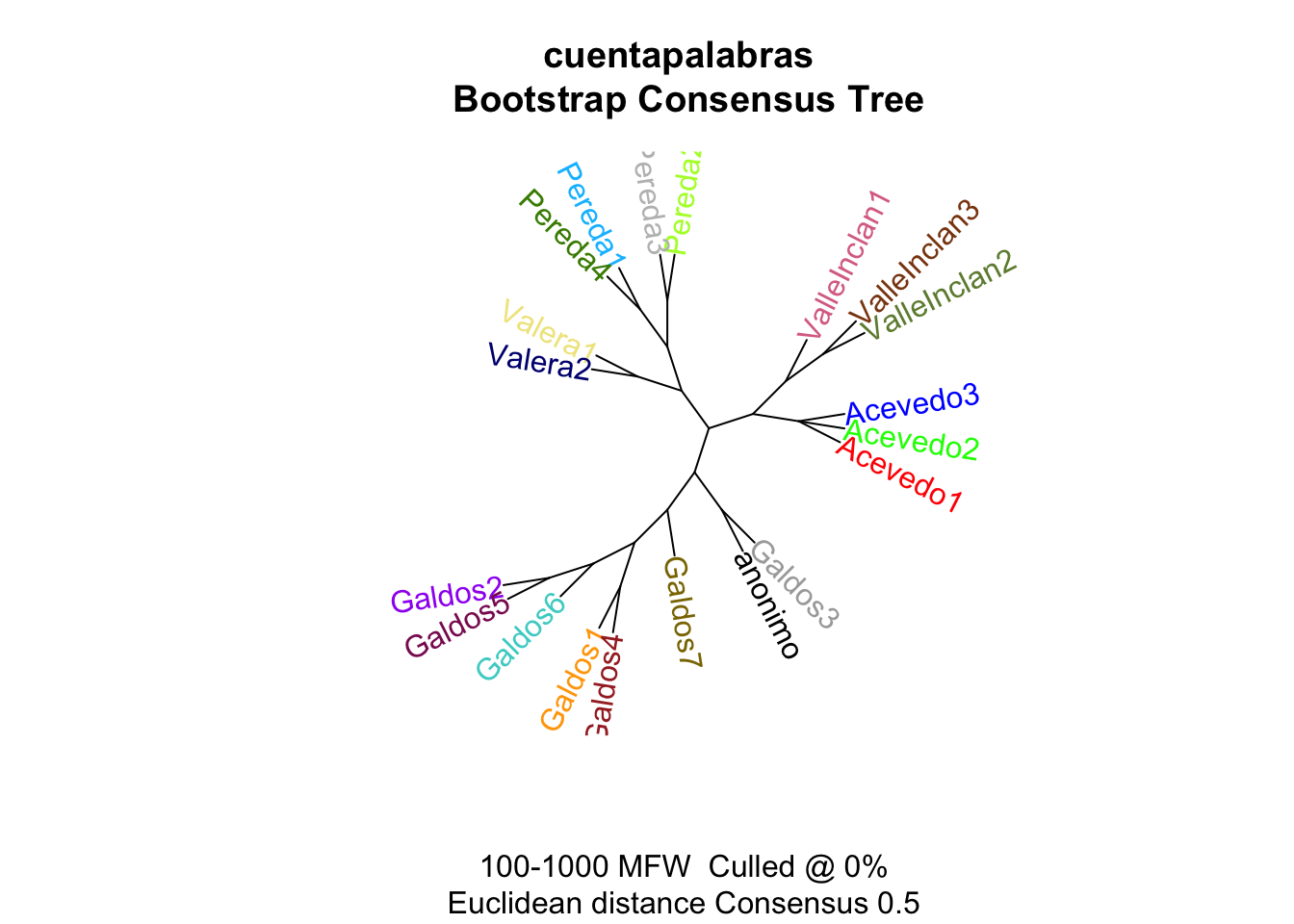
Figura 10.12: Árbol de consenso de los mismos textos
10.5 stylo y la Edad Media
Uno de los problemas que plantean muchos textos es si todo el texto es de un mismo autor o ha habido colaboraciones. Quien dice colaboraciones, puede hablar de fuentes, de copia de otras obras que se han integrado en otras. El análisis con stylo() puede permitir ver si hay dos o más estilos dentro de una misma obra. No dará la respuesta final, tan solo pistas.
A continuación, vas a analizar dos obras medievales para tratar de responder a dos cuestiones muy sencillas. En los textos preliminares de la Celestina se afirma que el autor encontró un esbozo que adoptó con cambios y que constituye el primer acto de su texto. ¿Es cierto o es un caso más del tópico del manuscrito hallado?
La segunda, sabemos que una parte del Libro de la caza de las aves de Pero López de Ayala es traducción de un texto portugués ligeramente anterior. ¿Será capaz stylo() de detectar ambos estilos? Algunos ensayos sobre el uso de stylocon textos medievales castellanos los puedes ver en Fradejas Rueda (2019, 2021).
10.5.1 Dividir un texto en capítulos
Para responder ambas preguntas lo primero es obtener en texto de ambas obras y dividirlo en autos o capítulos, según corresponda, y grabarlos en el disco duro para que después stylo los pueda analizar. Ambos los tienes en el repositorio del proyecto, con lo que los tendrás que bajar con R. Es muy sencillo. Primero te ofrezco el script para preparar el texto de Celestina y después el del Libro de la caza de las aves de Pero López de Ayala10. Hay pequeñas variantes que te explicaré, pero la parte principal es la misma para cualquier otro texto. Antes de nada, establece cuentapalabras como el directorio de trabajo, pues en la sección anterior tuviste que establecer como directorio de trabajo datos para que stylo() pudiera utilizar la carpeta corpus. Corta y pega en editor de RStudio el código que hay a continuación, pero no lo ejecutes hasta que no leas todas las explicaciones.
texto <- readLines("https://raw.githubusercontent.com/7PartidasDigital/AnaText/master/datos/textos/celestina.txt",
encoding = "UTF-8")
dir.create("datos/celestina")
posicion_capitulo <- grep("^ACTO", texto)
texto <- c(texto,"FIN")
ultima_posicion <- length(texto)
posicion_capitulo <- c(posicion_capitulo, ultima_posicion)
for(x in 1:length(posicion_capitulo)){
if(x != length(posicion_capitulo)){
inicio <- posicion_capitulo[x]+1
fin <- posicion_capitulo[x+1]-1
capitulo <- texto[inicio:fin]
capitulo <- gsub("^ARGUMENTO .*$",
"", capitulo,
perl = T)
capitulo <- gsub("^[[:upper:]]+\\.[-–—] ",
"", capitulo,
perl = T)
write(capitulo, paste("datos/celestina/",
"CELESTINA",
"-",
formatC(x, width = 2, flag = 0),
".txt",
sep = ""))
}
}10.5.2 Explicación del código
Para esta parte harás uso de funciones del paquete básico de R. Lo primero de todo es descargar el texto con readLines() y almacenarlo en un vector de caracteres que llamarás texto. Para leerlo solo necesitas saber el nombre, en este caso la url, del fichero. He añadido el argumento encoding = "UTF-8" para que los que usan Windows no tengan problemas con las letras que llevan tildes.
texto <- readLines("https://raw.githubusercontent.com/7PartidasDigital/AnaText/master/datos/textos/celestina.txt",
encoding = "UTF-8")Comprueba que has descargado el texto. Ejecuta en la consola
La respuesta tienen que ser los seis primeros elementos del vector texto.
## [1] "ACTO 1"
## [2] "ARGUMENTO Argumento del primer auto desta comedia. Melibea Calisto .ENtrando Calisto vna huerta empos de vn falcon suyo fallo y a Melibea de cuyo amor preso començole de hablar: de la qual rigorosamente despedido: fue para su casa muy sangustiado. hablo con vn criado suyo llamado sempronio. el qual despues de muchas razones le endereço a vna vieja llamada celestina: en cuya casa tenia el mesmo criado vna enamorada llamada elicia: la qual viniendo sempronio a casa de celestina con el negocio de su amo tenia a otro consigo llamado crito: al qual escondieron. Entre tanto que sempronio esta negociando con celestina: calisto esta razonando con otro criado suyo por nombre parmeno: el qual razonamiento dura fasta que llega Sempronio e celestina a casa de calisto. Parmeno fue conoscido de celestina: la qual mucho le dize de los fechos e conoscimiento de su madre induziendole a amor e concordia de sempronio. Calisto Parmeno Sempronio Celestina ."
## [3] "CALISTO.– EN esto veo Melibea la grandeza de dios."
## [4] "MELIBEA.– En que calisto."
## [5] "CALISTO.– En dar poder a natura que de tan perfeta hermosura te dotasse: e fazer a mi inmerito tanta merced que ver te alcançasse: e en tan conueniente lugar que mi secreto dolor manifestar te pudiesse. sin duda encomparablemente es mayor tal galardon que el seruicio: sacrificio: deuocion e obras pias que por este lugar alcançar tengo yo a dios ofrescido. Ni otro poder mi voluntad humana puede complir. quien vido en esta vida cuerpo glorificado de ningun hombre como agora el mio. Por cierto los gloriosos sanctos que se deleytan en la vision diuina no gozan mas que yo agora en el acatamiento tuyo. Mas o triste que en esto deferimos: que ellos puramente se glorifican sin temor de caer de tal bienauenturança: e yo misto me alegro con recelo del esquiuo tormento que tu absencia me ha de causar."
## [6] "MELIBEA.– Por grand premio tienes esto calisto."La funciónhead() imprime siempre la cabecera del objeto de R que se trate. Si quieres imprimir los seis últimos, debes emplear tail().
El siguiente paso es crear el directorio en el que se guardarán los ficheros que se crearán al dividir el texto. Ya has usado un poco antes la función dir.create(). Entre los paréntesis y entre comillas se pone el nombre, o el nombre y la ruta, del directorio que se quiere crear. Puesto que lo que vas a fragmentar es la Celestina qué mejor nombre para el directorio que celestina. Pero como lo tienes que guardar dentro de la carpeta datos, el nombre del directorio debe incluir la ruta. En este caso datos/celestina. La línea de código es
El texto de Celestina está divido en 16 actos. En el fichero que has descargado, cada acto comienza con la palabra ACTO y un número. Recordarás que te he dicho varias veces que los vectores tienen un índice para cada elemento; es el numerito que se imprime entre corchetes cuando se imprime en la consola el contenido de un vector. En nuestro caso, cada elemento suele ser un párrafo, de ahí que el vector texto en el que has guardado el texto que acabas de descargar diga que tiene 1170 y que el primer elemento sea ACTO 1. Por lo tanto, lo que hay que hacer es buscar los índices de cada párrafo que comienza por ACTO. Ya has usado la función gsub() para hacer cambios, ahora usarás grep() para localizar los elementos en los que está el patrón que buscas, ^ACTO, es decir, aquellos elementos que comiencen por ACTO, de ahí el ^, y que guarde el número de índice en posicion_capitulo. Esto funcionará porque grep() solo tienes dos posibles respuestas: TRUE si un elemento comienza por ACTO y FALSE si comienza por cualquier otra cosa. Si es TRUE lo que hace, por consiguiente, es guardar el número índice de ese elemento en posicion_capitulo.
Tan pronto ejecutes esta línea de código, tendrás un vector de caracteres llamado posición_capitulo con dieciséis elementos. Échale una ojeada al resultado ejecutando en la consola
Como puedes ver es una lista de números.
## [1] 1 276 308 343 450 477 585 678 758 819 891 940 1069 1109 1147 1167Para comprobar que realmente apunta los lugares donde comienza cada acto, ejecuta en la consola
el resultado será
## [1] "ACTO 1" "ACTO 2" "ACTO 3" "ACTO 4" "ACTO 5" "ACTO 6" "ACTO 7" "ACTO 8" "ACTO 9" "ACTO 10"
## [11] "ACTO 11" "ACTO 12" "ACTO 13" "ACTO 14" "ACTO 15" "ACTO 16"Aunque a buen seguro sabrás que es lo que ha sucedido te lo explico. Le has pedido a R que imprima el contenido de todos los elementos de texto cuyo índice está recogido en el vector posicion_capitulo.
Por lo tanto, el vector posicion_capitulo contiene los índices de apuntan a los elementos del objeto texto en los que se cumplió el patrón de búsqueda ^ACTO. Ahora tienes que pensar una manera de agrupar todas las líneas de texto que aparecen entre cada una de esas posiciones, es decir, las porciones de texto que constituyen cada acto en Celestina.
Parece sencillo, pero tienes un pequeño problema: no tienes todavía algo que marque el fin de cada acto, tan solo conoces el comienzo. Para obtener el fin puedes limitarte a restar 1 a la posición de cada uno de los lugares donde dice ACTO. Para abreviar, si el acto 13 comienza en la posición 1069, entonces sabrás que el acto 12 finaliza en 1069 – 1, o lo que es lo mismo, en la posición 1068.
Pero hay un pequeño fallo en esta técnica. Funciona bien excepto para el último acto, pues no hay nada más allá. La solución más sencilla es añadir una línea al objeto texto e incorporar la posición de esta nueva línea al vector posicion_capitulo. Revisa de nuevo el contenido de este vector con
el resultado será una secuencia de números.
## [1] 1 276 308 343 450 477 585 678 758 819 891 940 1069 1109 1147 1167Ahora añade al vector texto con la función c() un nuevo elemento cuyo contenido sea FIN.
Ahora guarda en la variable ultima_posicion la posición de este último elemento con length(texto).
Añádela a posicion_capitulo con
Si examinas ahora el contenido de posicion_capitulo
verás que el último elemento es 1171, y no 1167. Esta nueva posición corresponde al recién añadido FIN.
## [1] 1 276 308 343 450 477 585 678 758 819 891 940 1069 1109 1147 1167El truco está en ver cómo extraer el texto, es decir, el contenido real de cada acto que aparece entre cada uno de esos marcadores de acto (o de capítulo). Para esto vas a dar un paso más en programación. Ya aprendiste y dominas el uso de los bucles for, pero ahora le añadirás una pequeña complicación. Una condición.
10.5.3 El condicional if
Ya sabes como funcionan los bucles for: ejecutará las líneas de código que hay dentro de él hasta el momento en que la variable de control, en este caso x, sea igual a la longitud de posicion_capitulo. Mientras que x sea igual o menor que length(posicion_capitulo), es decir, mientras que no llegue a 16, irá extrayendo de texto las líneas correspondientes a cada acto de Celestina (dentro de un poco te cuento cómo lo hace).
Inmediatamente incluyes la condición if. Esta función, al igual que los bucles for, encierran las líneas que se ejecutarán bajo la condición entre llaves { }. if permite establecer una condición que se evaluará como verdadera (TRUE) o falsa (FALSE). Si la condición es TRUE, entonces se ejecutará el código que hay a continuación de la llave. Viene a ser algo así como si le dijeras: mientras que la condición sea verdadera, da vueltas. La condición en este caso es que no sea igual != a la longitud del vector. El motivo por el cual hay que establecer esta condición es porque no hay texto tras el último elemento de posicion_capitulo. No quieres que el bucle siga ejecutándose una vez haya llegado al final.
Asumiendo que se cumple la condición establecida en la orden if, se avanza a la siguiente línea. En este momento el programa captura el título del acto que se localiza en texto por medio del valor almacenado en posicion_capitulo. Como sabes, el inicio de cada Acto se encuentra en el valor del elemento x del vector texto. Guarda este valor en la variable inicio.
Ahora debes indicar dónde acaba el texto del acto y guardarlo en la variable fin.
Lo que sucede aquí es un tanto más sutil. En vez de añadir 1 al valor de la posición x del vector posicion_capitulo, lo que tienes que hacer es añadir 1 a x debido a su valor como índice. Sin embargo, en vez de extraer el valor del elemento x del vector, el programa recogerá el valor del elemento que hay en la siguiente posición a la de x en el vector. Puede parecer confuso. Mira la tabla 10.1, trata de asemejarse a lo que sería el vector posicion_capitulo y su contenido, que es una secuencia de 17 números que indican en qué posición se encuentra la indicación de dónde comienza un acto (o capítulo, depende del tipo de obra).
| índice | valor | contenido |
|---|---|---|
| 1 | 1 | ACTO 1 |
| 2 | 276 | ACTO 2 |
| 3 | 308 | ACTO 3 |
| 4 | 343 | ACTO 4 |
| 5 | 450 | ACTO 5 |
| 6 | 477 | ACTO 6 |
| 7 | 585 | ACTO 7 |
| 8 | 678 | ACTO 8 |
| 9 | 758 | ACTO 9 |
| 10 | 819 | ACTO 10 |
| 11 | 891 | ACTO 11 |
| 12 | 940 | ACTO 12 |
| 13 | 1069 | ACTO 13 |
| 14 | 1109 | ACTO 14 |
| 15 | 1147 | ACTO 15 |
| 16 | 1167 | ACTO 16 |
| 17 | 1071 | FIN |
Cuando x == 1, el valor contenido en posicion_capitulo[x] será 1 porque 1 es el primer valor almacenado en el vector. Cuando x == x + 1, en este caso 2, R tomará el valor almacenado en la segunda posición de posicion_capitulo, es decir, 276. En la siguiente vuelta x contendrá 2 de manera que [x+1] será 3 y el resultado será 308, que corresponde al tercer valor conservado en el vector posicion_capitulo[x+1] tomará el siguiente elemento del vector, y el valor que haya en ese lugar corresponderá a la posición donde comienza un nuevo capítulo. Puesto que no quieres obtener la indicación de Acto ni del número correspondiente del acto siguiente, tienes que restar 1 a ese valor para obtener el número del párrafo de texto que hay justo antes del comienzo de un nuevo acto. Así, pues, resta 1 del valor que haya en [x + 1] - 1.
Ahora ya sabes dónde comienza y finaliza el texto de cada acto. Lo tienes almacenado en las variables inicio y fin, con lo que ahora solo te falta extraer el texto y guardarlo en un nuevo vector que llamarás capitulo. Para hacerlo solo tienes que extraer de texto los elementos que haya entre inicio y fin incluidos. Lo cual se hace con esta expresión
10.5.4 Dos pequeños problemas
Celestina presenta al inicio de cada acto un pequeño resumen de lo que tratará. Eso no existía en la edición original, por lo que han averiguado los investigadores, sino que es un añadido posterior. Puesto que lo que quieres establecer es la posibilidad de que el autor de los actos 2 a 16 sea el mismo que el del primero, entonces no te interesa procesar texto que sabes de antemano que no es del posible autor, sea quien sea este. Por lo tanto, hay que eliminar esa parte de texto con
Esta línea lo que hace es localizar dentro del vector capitulo un elemento que comience (de ahí el acento circunflejo) con el literal ARGUMENTO, al que le debe seguir un espacio en blanco y todo lo que pueda haber a continuación .* hasta el final $ del elemento. Una vez localizado, lo que tiene que hacer es borrarlo. De ahí que el segundo argumento sea "".
La línea siguiente lo que hace es eliminar los nombres de los personajes que preceda a cada intervención. En el fichero aparecen escritos en mayúsculas seguidos de un punto y una raya, como indican las normas ortográficas de la RAE. Esto te ofrece un patrón perfecto para diseñar una regla de expresión regular. Lo que quieres es borrar los nombres de los personajes que comiencen cada parlamento, por lo tanto es algo que está al comienzo de cada elemento, así que se usa el acento circunflejo ^; son palabras que están en mayúsculas y como cabe la posibilidad de que haya letras con tilde, para evitar cualquier fallo, usa la clase [[:upper:]] que tendrá en cuenta cualquier letra mayúscula, tenga o no tenga diacríticos, y como los nombres tienen más de una letra, le pones un +. Además, quieres quitar de en medio el punto, la raya y el espacio que hay antes de la primera palabra de cada parlamento. Entre los corchetes finales están las tres posibilidades que pueden aparecer como raya: el guion, la resta y la raya, propiamente dicha. Es más fácil copiar la línea que explicarla. ¿Verdad?
Ya solo falta grabar en el disco duro el fichero. Como es un vector de caracteres, la mejor orden es writeLines(). Solo requiere dos argumentos: el vector que ha de guardar y el nombre del fichero. El primer argumento es capitulo, que es el vector en el que se ha ido guardando el texto de cada acto en cada vuelta del bucle. El nombre del fichero parece muy complicado, pero se trata de construir, para cada acto, un nombre diferente que presente el patrón CELESTINA_n.txt donde n es un número consecutivo entre 1 y 16. La construcción de este nombre de fichero la harás con paste(), tienes que indicar la ruta datos/celestina/, añadirle el nombre del fichero CELESTINA con el número del auto, que es el valor de x, y por último la extensión .txt. Todos esos elementos los unes con el argumento sep = "", sin nada entre las comillas, pues no hace falta ninguna cosa.
Lo que te habrá sorprendido es la expresión formatC(x, width = 2, flag = 0). Esta lo que hace es construir el número con dos dígitos. Del 10 al 16 no hay problema, pero entre 1 y 9 hay que anteponer un 0 para evitar que los ficheros se desordenen porque los ordenadores contemplan los nombres de los ficheros como secuencias de caracteres y no ordenan los números como números sino como caracteres. Para conseguir esos ceros se utiliza la función formatC().
El primer argumento es de donde sacará el número que ha de formatear, en este caso de x. El segundo argumento, width, indica cuántos caracteres tendrá como máximo, en este caso 2: 01, 02, 03, 04, 05, 06, 07, 08, 09, 10, 11, 12, 13, 14, 15 y 16, y cuál es el elemento que se utilizará de relleno, en este caso 0, que se indica con el argumento flag =.
Comprueba ahora si hay 16 ficheros llamados CELESTINA_nn.txt en el directorio cuentapalabras/datos/celestina. Si están los 16 ficheros, enhorabuena, lo has conseguido. Has aprendido a dividir un texto largo en varios ficheros.
Ahora solo te falta descargar el fichero del Libro de la caza de las aves, pero te lo voy a dejar como práctica.
10.6 Prácticas
10.6.1 Práctica 1
El fichero del Libro de la caza de las aves se encuentra en el mismo repositorio que en el caso anterior. La url es https://raw.githubusercontent.com/7PartidasDigital/AnaText/master/datos/textos/LCA_PLA.txt. Debes crear un nuevo directorio para guardar los ficheros que se crearán. Llámalo AYALA. Deberás nombrar los ficheros de salida como AYALA_nn.txt. La mayor dificultad reside en el hecho de que el Libro de la caza de las aves está dividido en capítulos identificados con la palabra Capítulo y el número correspondiente en números romanos. Pero también tiene una sección llamada Prólogo, por lo que hay que darle al script la posibilidad de que busque como marca de capítulo además de Capítulo la palabra Prólogo. Modifica el script anterior para que puedas trocearlo. ¡Ah! Una buena noticia. No te hacen falta las líneas de gsub(). Por cierto, los siete primeros elementos (líneas o párrafos) del fichero que bajarás son los metadatos del fichero. Debes eliminarlos porque no puedes procesarlos al no ser parte del texto. Por lo tanto, cuando cargues el fichero, verás que el objeto texto tiene 257 elementos y deberá quedar reducido a 250; el primero dice "Archivo Iberoamericano de Cetrería", tiene que ser "Prólogo". Es algo que debes hacer inmediatamente después de cargar el texto. De otro modo habrá errores.
ayala_00.txt, el primer argumento de formatC tiene que ser x-1.
10.6.2 Práctica 2
Una vez tengas en tu ordenador los textos de Celestina y del Libro de la caza de las aves divididos en capítulos, analízalos con {stylo}. Ten en cuenta que tendrás que renombrar sucesivamente los directorios. Recuerda que {stylo} tiene que tener el material de trabajo en un subdirectorio del directorio de trabajo que se llame corpus. El resultado debe ser dos dendrogramas como los de las figuras 10.13 y 10.14.
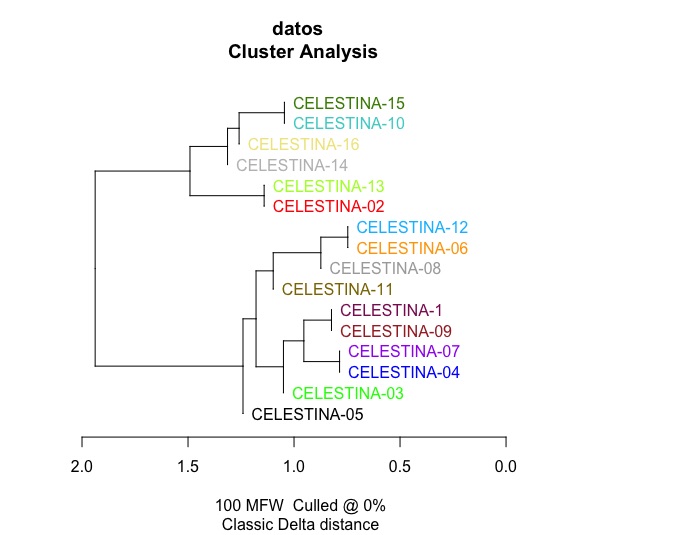
Figura 10.13: Dendrograma de Celestina
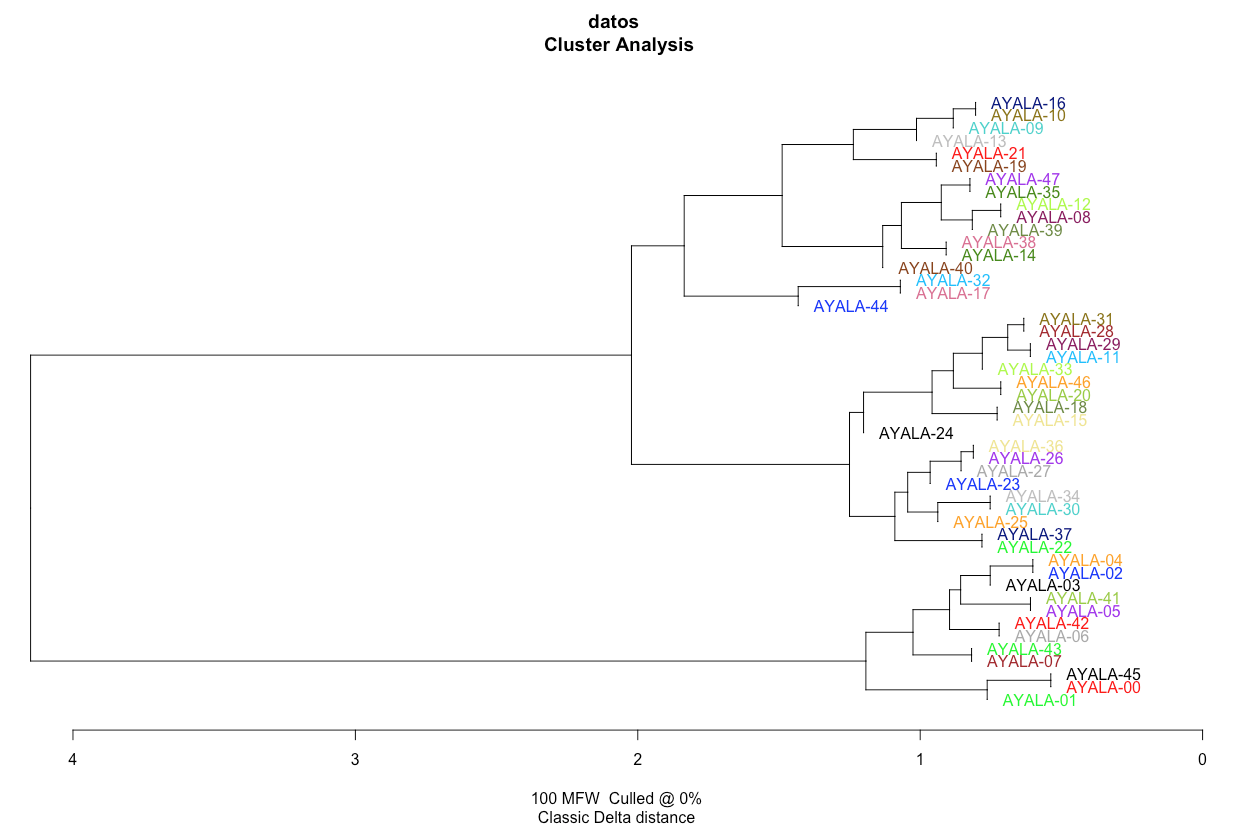
Figura 10.14: Dendrograma de Libro de la caza de las aves
¿Qué conclusiones puedes extraer? En el caso de Celestina es evidente que el autor del auto 1 es el mismo que el de la gran mayoría de los otros autos. En el caso de Ayala se ve que hay dos estilos diferentes muy definidos y viene dado por la enorme longitud de las ramas que los unen. Viene a decir, porque no tengo más remedio que unirlos, pero la porción inferior nada tiene que ver con la superior.
10.6.3 Práctica 3
Se supone que en cuentapalabras/datos tienes un subdirectorio con un buen conjunto de textos. Los que has recoleccionado y has estado analizando en los capítulos anteriores. Sí, los tienes en mensajes. Haz un análisis y trata de averiguar cuántos autores tienen los mensajes de Navidad de la Casa Real.
Prueba también con los de los discursos de investidura, puede ser interesante ver qué sale.
10.7 Conclusión
{stylo} puede ser útil para ver si el estilo de un autor cambia a lo largo del tiempo. En unos análisis sobre un pequeño corpus de novelas rosas de Corín Tellado, publicadas entre 1949 y 1990, el resultado fue muy interesante, puesto que, como se puede ver en la 10.15, lo dividió en tres grandes grupos que vienen a coincidir con los tres grandes etapas en las que la crítica (González García 1998; Carmona González 2002; Andreu 2010) suele dividir su producción, y que se corresponden con cambios de editorial (Bruguera (1946-1964) — Rollán (1965-1972) — Bruguera (1973-1990)). Sin embargo, hay pequeños fallos en el resultado. Son las novelas marcadas con barritas azules. Los fallos pueden deberse a que los datos editoriales (metadatos) son erróneos, y que las fechas que le he atribuido a cada uno de los textos no sean las fechas reales de la publicación original. Sea lo que fuere, lo cierto que es {stylo} se puede utilizar para algo más que discernir autorías.
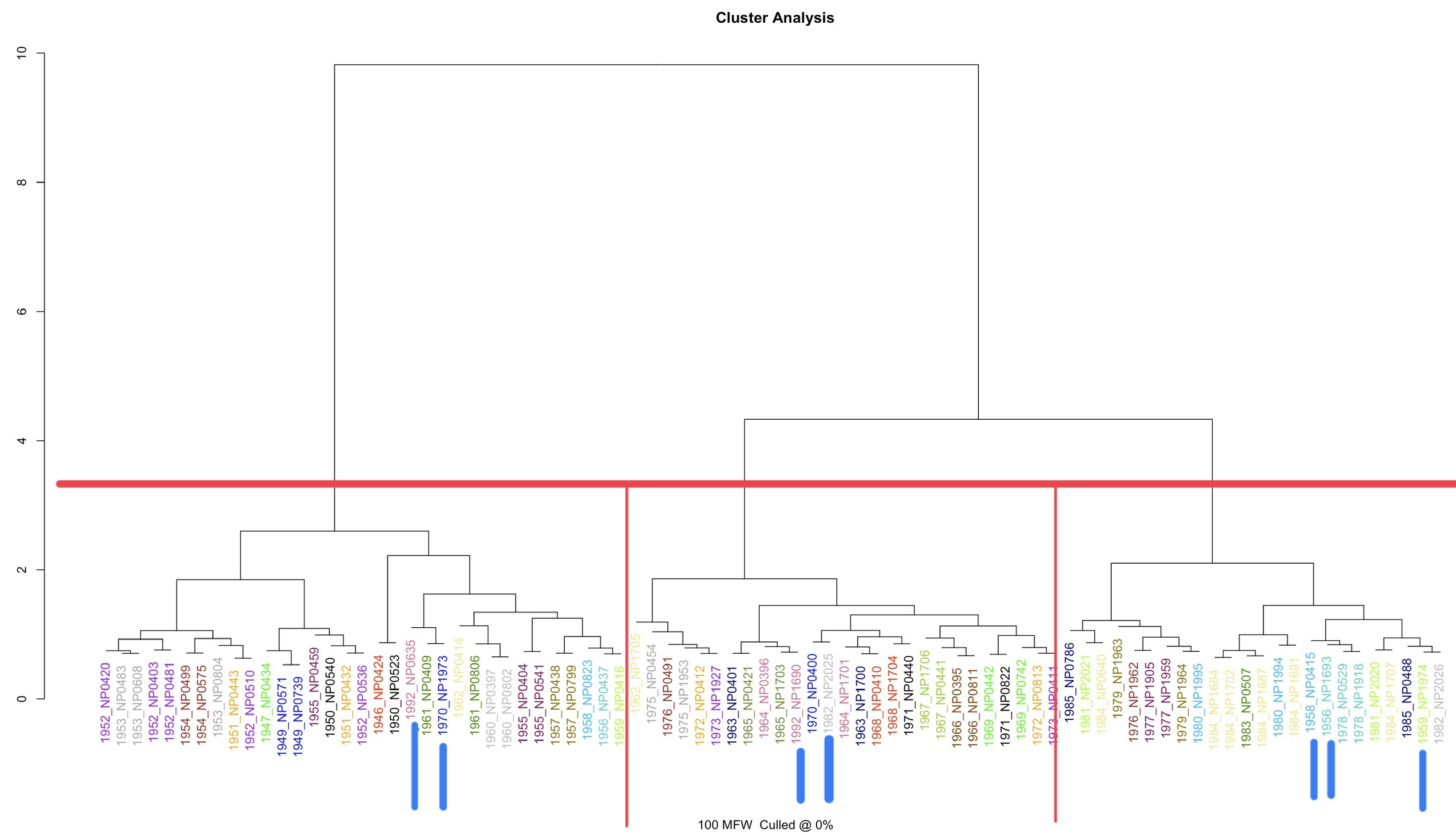
Figura 10.15: Dendrograma de un conjunto de novelas de Corín Tellado (1946-1992)
El paquete {stylo} tiene muchas más posibilidades de análisis. Te he enseñado a usar las mínimas y a preparar los materiales y te he mencionado, al final, que puede servir incluso para discernir etapas dentro de la producción de una autora. Solo tu curiosidad es el límite a lo que puedes estudiar con esta librería. Las instrucciones completas, aunque en inglés, las tienes en el sitio web del grupo Computational Stylistics y en la red puedes encontrar numeros artículos que hacen uso de esta libería. El más curioso, por el momento, es el de Peñarrubia Navarro (2021), que la ha utilizado para un análisis geolingüístico.

Este script es una adaptación del publicado por Jockers 2014.↩︎