14 Mapas con R. Un poco de geografía lingüística
14.1 Introducción
Hacer mapas con R es relativamente sencillo. Con apenas dos instrucciones se puede dibujar un mapa de España (excluye las Islas Canarias, aunque se podrían dibujar) como el de la figura 14.1.
Figura 14.1: Mapa de España dibujado con {ggplot2}
El mapa de de la figura 14.1 se ha dibujado con estas sencillas líneas de código:
Esto tan elemental puede ser útil para muchas cosas. Veamos un caso práctico muy sencillo. En el proyecto 7PartidasDigital hemos localizado varias bibliotecas de España en las que se conserva, al menos, un manuscrito de las Siete Partidas. Queríamos dibujar un mapa con la localización de todas estas ciudades y poder actualizarla con facilidad si localizábamos algún nuevo testimonio.
Es muy sencillo hacerlo. Comenzamos creando una tabla con las tres informaciones básicas: la ciudad y las coordenadas (longitud y latitud). El punto de partida era crear un vector de caracteres con los nombres de las localidades.
ciudad <- c("Madrid", "Toledo", "Valladolid",
"León", "Barcelona", "Oviedo", "Vitoria",
"Valencia", "Córdoba", "El Escorial")El siguiente paso era averiguar las coordenadas geográficas para ubicar en el mapa cada uno de estos sitios. Para ese primer intento las buscamos en internet puesto que no eran muchas. Una vez encontradas se creó un vector numérico para las latitudes lat y otro para las longitudes lon.
# Latitudes
lat <- c(40.418889, 39.866667, 41.651981, 42.598889, 41.3825,
43.3625, 42.846667, 39.466667, 37.883333, 40.58175)
# Longitudes
lon <- c(-3.691944, -4.033333, -4.728561, -5.566944, 2.176944,
-5.850278, -2.673056, -0.375, -4.766667, -4.126417)El paso anterior, localizar las coordenadas se puede automatizar con la librería {georeference} de José Luis Losada, la cual construiría la tabla con los lugares y las coordenadas, pero no te ahorra el vector inicial ciudad, sin él no podría operar.
Sin embargo, dos vectores de enteros y otro de caracteres no es lo que ggplot() utiliza para ubicar en el mapa los lugares. Por lo que procedía construir una tabla con toda la información. La llamamos, no podía ser menos, bibliotecas y tenía tres variables (columnas) –ciudad, lat y lon– y diez observaciones, una por cada una de las ciudades que hay recogido en el vector ciudad. Para unir estos tres vectores y constuir una tabla usamos la función tibble().
La matriz que se crea tendrá el aspecto de la tabla que hay a continuación.
| ciudad | lat | lon |
|---|---|---|
| Madrid | 40.41889 | -3.691944 |
| Toledo | 39.86667 | -4.033333 |
| Valladolid | 41.65198 | -4.728561 |
| León | 42.59889 | -5.566944 |
| Barcelona | 41.38250 | 2.176944 |
| Oviedo | 43.36250 | -5.850278 |
| Vitoria | 42.84667 | -2.673056 |
| Valencia | 39.46667 | -0.375000 |
| Córdoba | 37.88333 | -4.766667 |
| El Escorial | 40.58175 | -4.126417 |
Una vez con toda la información recogida en una tabla, tan solo queda dibujar el mapa y situar las diez ciudades, como puedes ver en la figura 14.2.
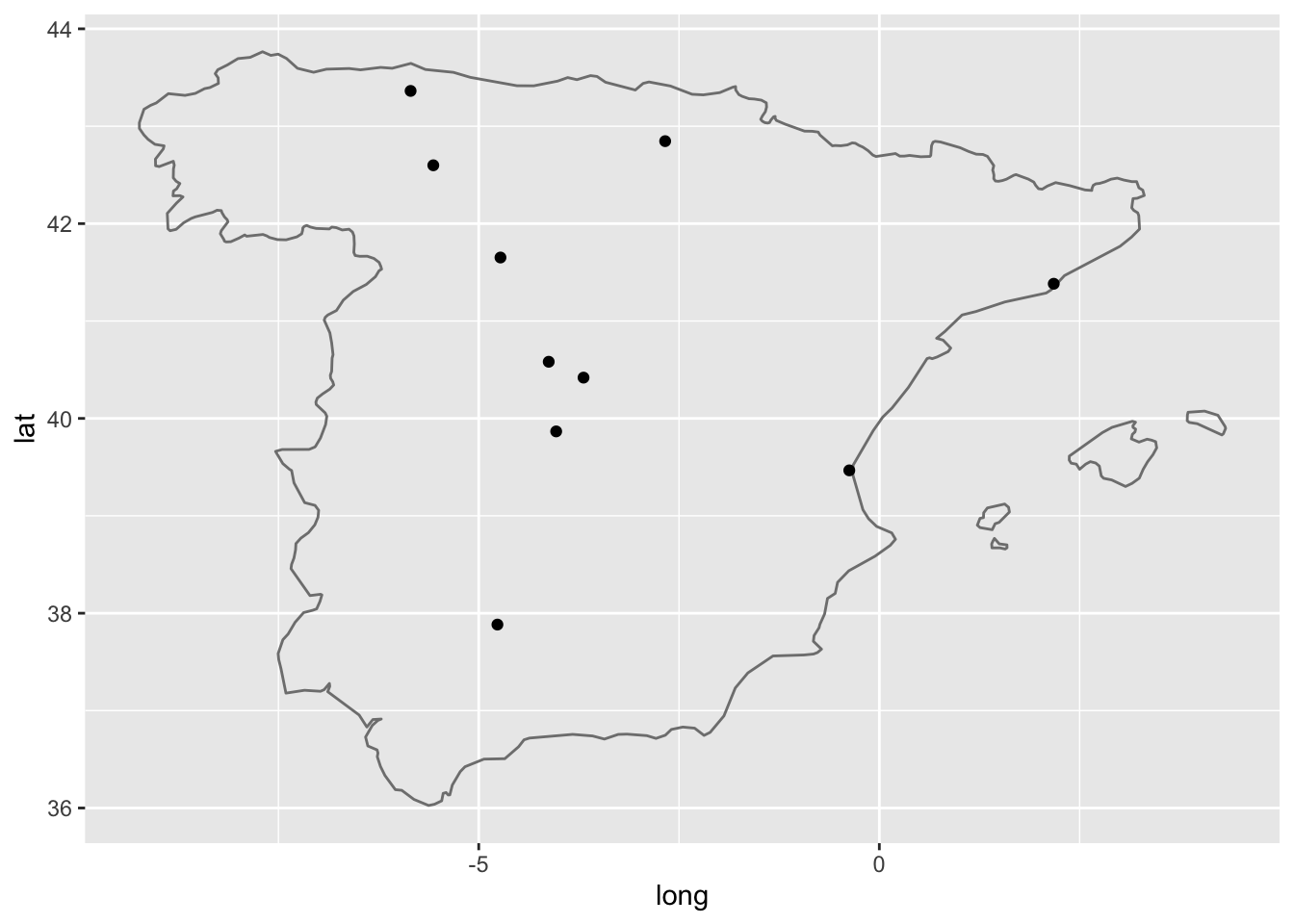
Figura 14.2: Lugares de España donde hay un manuscrito de las Siete Partidas
Tan solo hay que añadir a ggplot() la función geom_point() con los atributos necesarios para dibujar un punto para ubicar en el mapa cada uno de los lugares. Este es el código:
Lo primero que hicimos fue indicarle a geom_point dónde ha de buscar los datos. Los tiene en la tabla bibliotecas. Y con la función aes() le indicamos que en el eje x había de situar las longitudes y en el eje y las latitudes.
A partir de aquí se pueden complicar las cosas para embellecer un poco el mapa. Cambiar el aspecto de los puntos, el color, el tamaño. He menciconado an varias ocasiones que se puede complicar cuanto se desee y se esté dispuesto para dejarlo más bonito. En la figura 14.3 lo que he hecho ha sido poner el nombre del lugar en vez de un sencillo punto.
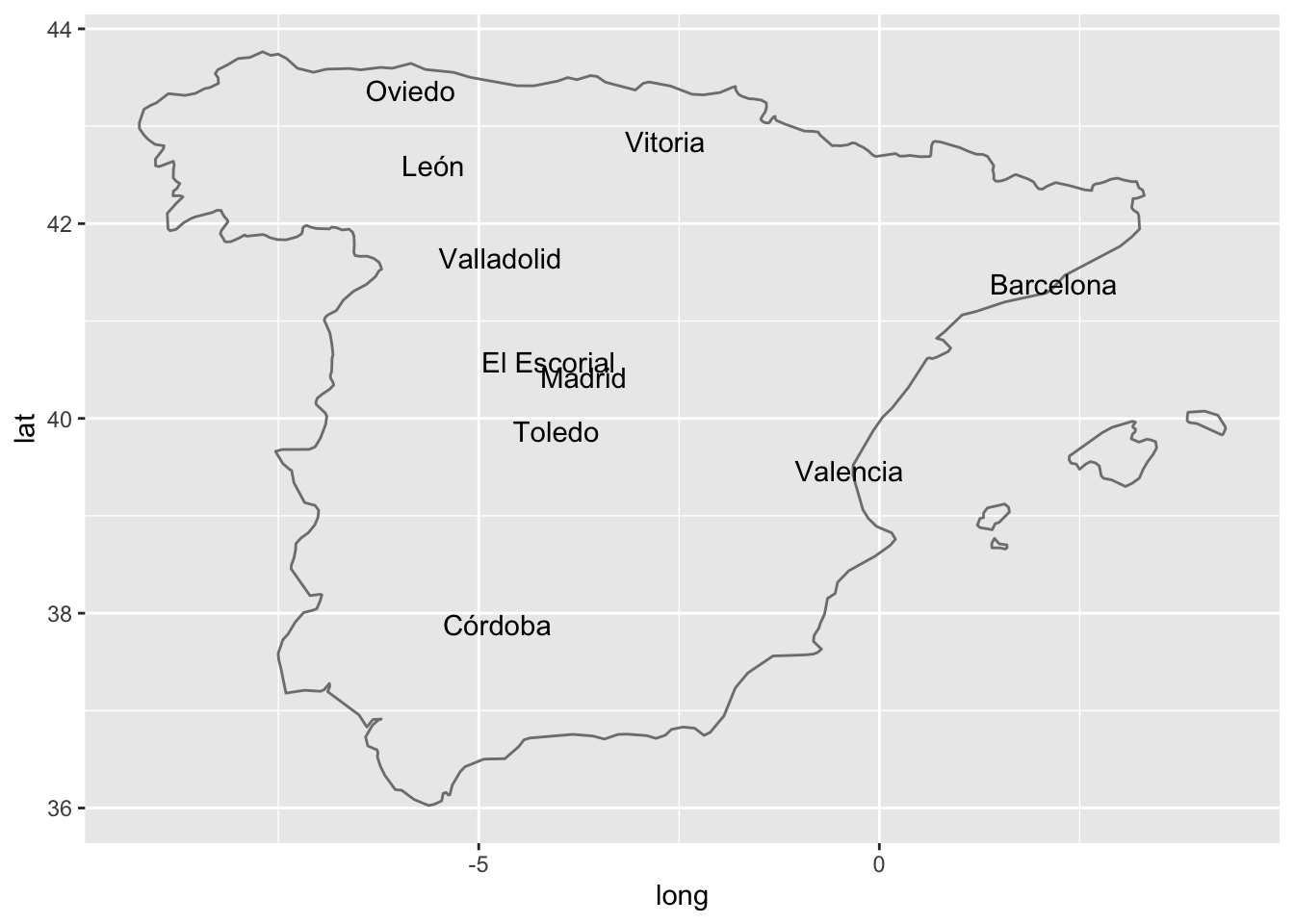
Figura 14.3: Ciudades de España donde hay un manuscrito de las Siete Partidas
Estas son las líneas de código con las que lo hicimos:
ggplot() +
borders("world", "spain") +
geom_text(data = bibliotecas,
aes(x = lon, y = lat),
label = ciudad)Como puedes ver, dibujar el mapa en sí es muy sencillo. Lo complicado es la obtención y preparación de los datos que se quieran representar en ellos.
14.2 Un poco de geografía lingüística
En un curso de Lingüística Románica en la Universidad de Valladolid, al explicar de la situación lingüística de la península Ibérica, nos enfrentábamos con el problema, entre otros, de las fronteras lingüísticas entre las diversas variedades románicas peninsulares. Uno de los ejemplos más claros y mejor estudiados es el de la frontera entre el castellano y el catalán en Aragón. Una frontera lingüística que no coincide con la frontera política entre Aragón y Cataluña. Para verlo con detalle usábamos el Atlas Lingüístico y Etnográfico de Aragón, Navarra y La Rioja de Manuel Alvar (1979-1983). Dentro de los muchos mapas que tiene este atlas lingüístico localicé entre ellos uno que pudiera ofrecer datos claros para trazar la frontera entre ambas variedades románicas. Elegí el mapa 289 que recoge las respuestas a la pregunta sobre una planta: el hinojo.

Figura 14.4: Mapa 289 del ALEARN
Este hoja del ALEARN (figura 14.4) permite ver varios rasgos que pueden servir para trazar la frontera entre el catalán y el castellano. El étimo de este fitónimo es la voz latina FOENICŬLUM, la cual permite observar dos rasgos muy claros, además de presentar algunos problemas lingüísticos más. Los dos rasgos claros son los resultados de F- inicial latina y del grupo interno -KL-. La F- se conserva en catalán mientras que en castellano evoluciona a una h- gráfica, sin valor fonético. El grupo -KL-, por su parte, llega hasta una /x/ en castellano y se queda (si aceptamos que es un paso intermedio hasta los resultados más radicales como los del castellano) en /ʎ/ en catalán.
Los atlas lingüísticos realizan sus encuestas en una serie de puntos que los investigadores determinan en la fase inicial del proyecto. Una vez decididos los lugares, les asigna un identificador. En el caso de los atlas regionales españoles es un código alfanumérico que consiste en las iniciales de las antiguas matrículas de automóviles y (M = Madrid, B = Barcelona, LO = Logroño, Z = Zaragoza, TE = Teruel, etc.) y una secuencia numérica según una retícula que divide cada provincia en seis rectángulos (Z100, Z101, Z102 … Z600, Z601, Z602).
Entre los primeros mapas de todos los atlas hay siempre uno en el que se presenta la identificación de los puntos de encuesta junto con los códigos alfanuméricos que se les ha asignado. Por lo tanto, el primer paso es crear una tabla, como la que hay a continuación, con dos variables con el código identificativo, que llamaremos id, y el nombre del lugar, que designaremos poblacion. Tan solo son las diez primeras líneas.
| id | poblacion |
|---|---|
| HU100 | Sallent de Gállego |
| HU101 | Ansó |
| HU102 | Echo |
| HU103 | Canfranc |
| HU104 | Aragüés del Puerto |
| HU105 | Berdún |
| HU106 | Broto |
| HU107 | Jaca |
| HU108 | Bailo |
| HU109 | Yebra de Basa |
id y poblacion– y después relleno, pacientemente, cada una de las casillas con los datos pertienentes. Así me aseguro de que todo está en su columna correspondiente.
El siguiente paso es incorporar a la tabla las coordenadas geográficas de cada punto de encuesta. Se puede hacer a mano, buscando en internet cada localidad. Se puede recurrir a las tablas que existen en varios lugares y que se pueden descargar, como por ejemplo la que hay en html creada por alguien en un sitio llamado Bussines Intelligence o desde el Nomenclator Geográfico Básico de España, buscarlas manualmente en internet (Wikipedia es un sitio muy interesante para localizar y extraer datos, siempre y cuando no sean grandes cantidades) o con el paquete {georeference}.
Ninguno de los sistemas está exento de problemas. Algunos de los que me he encontrado al prepararar los materiales han sido el cambio de los nombres oficiales, pequeños problemas ortográficos, el que hay más de un sitio que se llama de la misma forma en puntos muy alejados entre sí, etc. Para este ensayo los busqué a mano con la ayuda de GoogleMaps. Llevó un rato, pero mereció la pena.
Al final de este paso la tabla tiene este aspecto (de nuevo son solo los diez primeros puntos del ALEARN, que es lo que estoy usando en este capítulo).
| atlas | provincia | id | poblacion | latitud | longitud |
|---|---|---|---|---|---|
| ALEARN | Huesca | HU100 | Sallent de Gállego | 42.77204 | -0.3347842 |
| ALEARN | Huesca | HU101 | Ansó | 42.75754 | -0.8281171 |
| ALEARN | Huesca | HU102 | Echo | 42.73889 | -0.7502780 |
| ALEARN | Huesca | HU103 | Canfranc | 42.71557 | -0.5256487 |
| ALEARN | Huesca | HU104 | Aragüés del Puerto | 42.70673 | -0.6700809 |
| ALEARN | Huesca | HU105 | Berdún | 42.60333 | -0.8586110 |
| ALEARN | Huesca | HU106 | Broto | 42.60481 | -0.1235453 |
| ALEARN | Huesca | HU107 | Jaca | 42.57101 | -0.5494531 |
| ALEARN | Huesca | HU108 | Bailo | 42.51000 | -0.8113827 |
| ALEARN | Huesca | HU109 | Yebra de Basa | 42.48631 | -0.2820295 |
El siguiente paso es crear las columnas con los datos. Aquí entra en juego qué es lo que quieres manejar. Yo lo reduje a dos rasgos básicos que designé con las etiquetas F_inicial y cl_inter. Lo que hice fue marcar en cada columna el resultado que encontré en cada lugar de encuesta, como puedes ver en la siguiente tabla (diez primeros puntos de la provincia de Huesca).
| atlas | provincia | id | poblacion | latitud | longitud | F_inicial | cl_inter |
|---|---|---|---|---|---|---|---|
| ALEARN | Huesca | HU100 | Sallent de Gállego | 42.77204 | -0.3347842 | θ | x |
| ALEARN | Huesca | HU101 | Ansó | 42.75754 | -0.8281171 | θ | ʎ |
| ALEARN | Huesca | HU102 | Echo | 42.73889 | -0.7502780 | θ | ʎ |
| ALEARN | Huesca | HU103 | Canfranc | 42.71557 | -0.5256487 | ø | x |
| ALEARN | Huesca | HU104 | Aragüés del Puerto | 42.70673 | -0.6700809 | x | x |
| ALEARN | Huesca | HU105 | Berdún | 42.60333 | -0.8586110 | θ | x |
| ALEARN | Huesca | HU106 | Broto | 42.60481 | -0.1235453 | θ | x |
| ALEARN | Huesca | HU107 | Jaca | 42.57101 | -0.5494531 | θ | x |
| ALEARN | Huesca | HU108 | Bailo | 42.51000 | -0.8113827 | NA | NA |
| ALEARN | Huesca | HU109 | Yebra de Basa | 42.48631 | -0.2820295 | θ | x |
Fíjate que la columna F_inicial tiene los siguientes valores: ø (cero fonético; lo usual en castellano) y dos resultados peculiares –x (velar), θ (interdental)– y uno raro –NA– cuando no hay respuesta (en el listado que te he mostrado no hay casos de f, pero te asguro que sí los hay; lo verás un poco más adelante). En la variable cl_inter tienes como resultados: x (velar; el esperable en castellano), ʎ (lateral; el esperable en catalán) y NA, cuando no hay respuesta del informante.
NA o deja la casilla de la obsrvación en blanco porque es lo que R entenderá como falta de valor. Si hay otra cosa, R puede interpetarlo de manera inesperada.
Vas a representarla sobre el mapa para ver la distribución. Tienes todos los elementos: cómo dibujar el mapa, lo has visto en las primeras líneas, y la tabla que has construido. Lo que se pretende es que al final consigas un mapa como el de la figura 5, que corresponde a la distribución de los resultados de F- inicial.
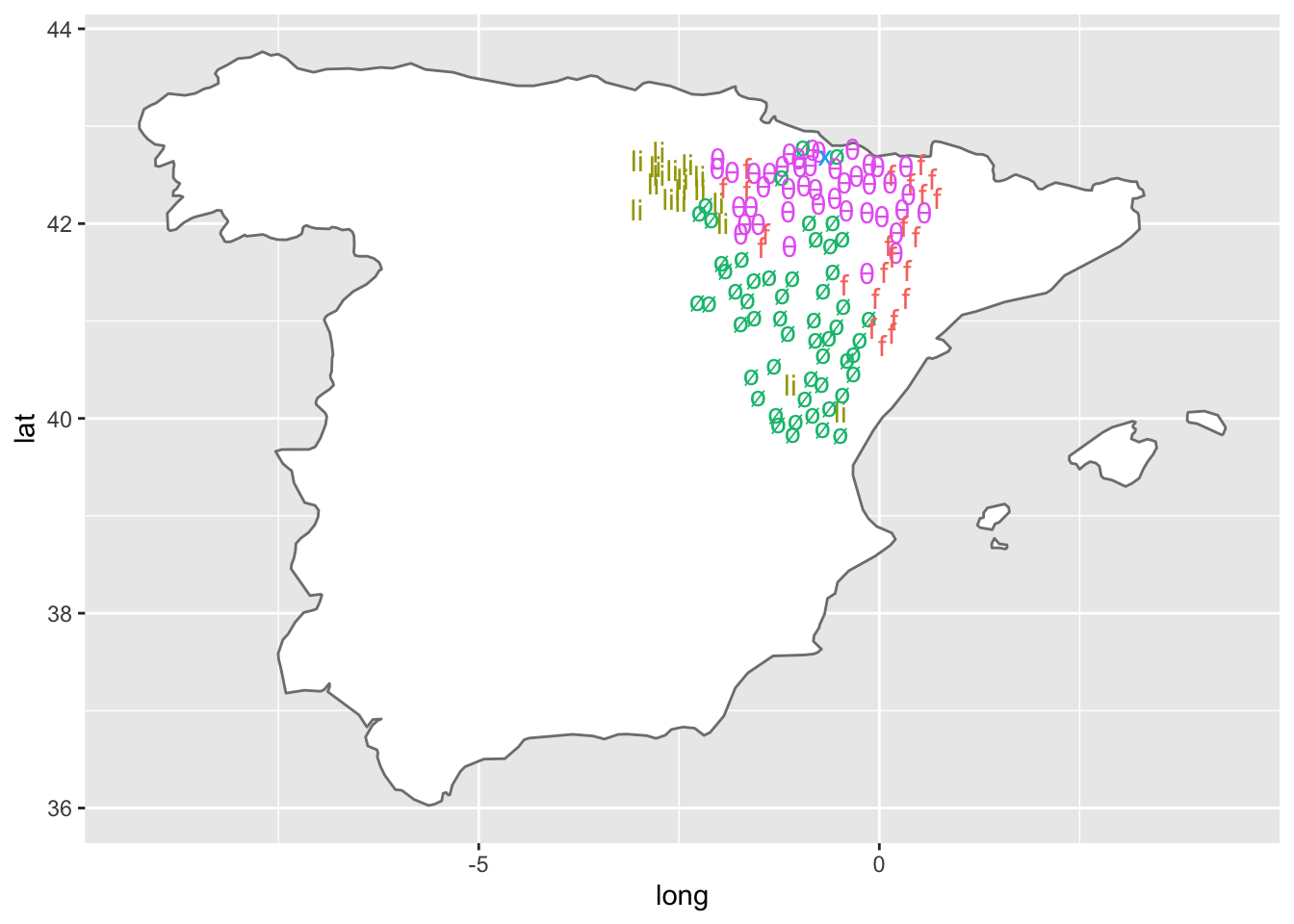
Figura 14.5: Figura 5. Los resultados de F-
El otro mapa que has de obtener es el que cartografía los resultados del grupo -KL- (figura 6) .
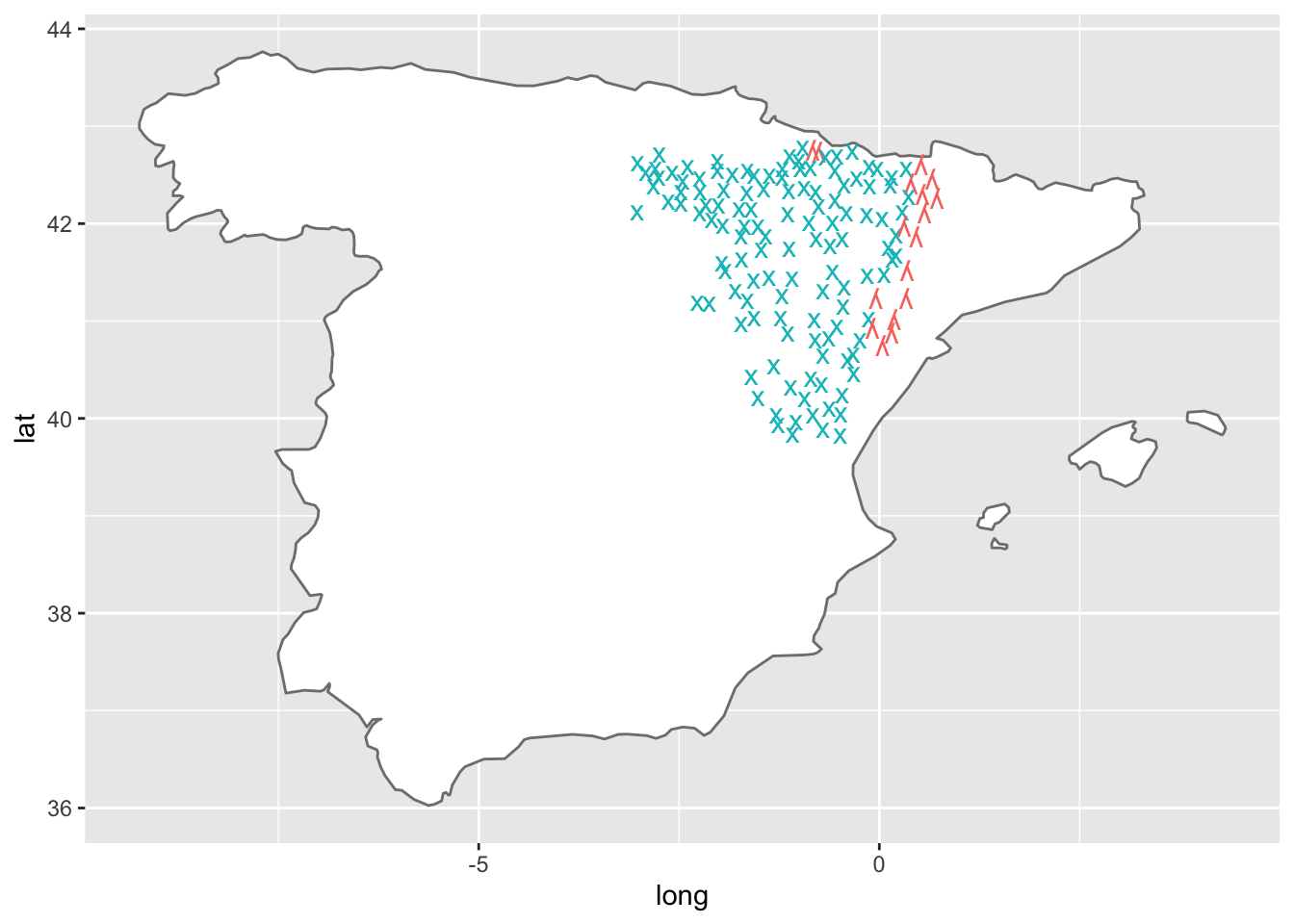
Figura 14.6: Figura 6. Los resultados de -KL-
Analiza un momento los dos mapas. Podrás observar que se ven ciertos patrones. En el mapa de -KL- (figura 6) la gran mayoría de los puntos presenta como resultado la fricativa velar /x/, pero en la banda oriental hay una serie de puntos, de norte a sur, en los que el resultado es la lateral palatal /ʎ/. Si observas el mapa que dibuja los resultados de F- incial (figura 5) verás que hay cuatro grupos de resultados. En la misma franja oriental, de norte a sur, abundan los casos de conservación de /f/, y que lo que predomina el resultado de cero fonético, típico castellano, pero hay unas zonas compactas con dos resultados peculiares: /θ/ y /li/.
Este último resultado es fácil de explicar, se trata de un caso de fusión del artículo el y la primera sílaba de hinojo. Gráficamente podría representarse como l’inojo, por lo que podría considerarse como un caso de F- > ø. Los encuestadores oyeron claremente li y lo anotaron en los cuadernos de encuesta, es un dato que en algún momento puede ser interesante. Con muy poco esfuerzo, podrías representarlos en el mapa como casos de ø, con lo que el patrón del resultado de F- inicial en castellano queda más claro, como puedes ver en el mapa de la figura 7.
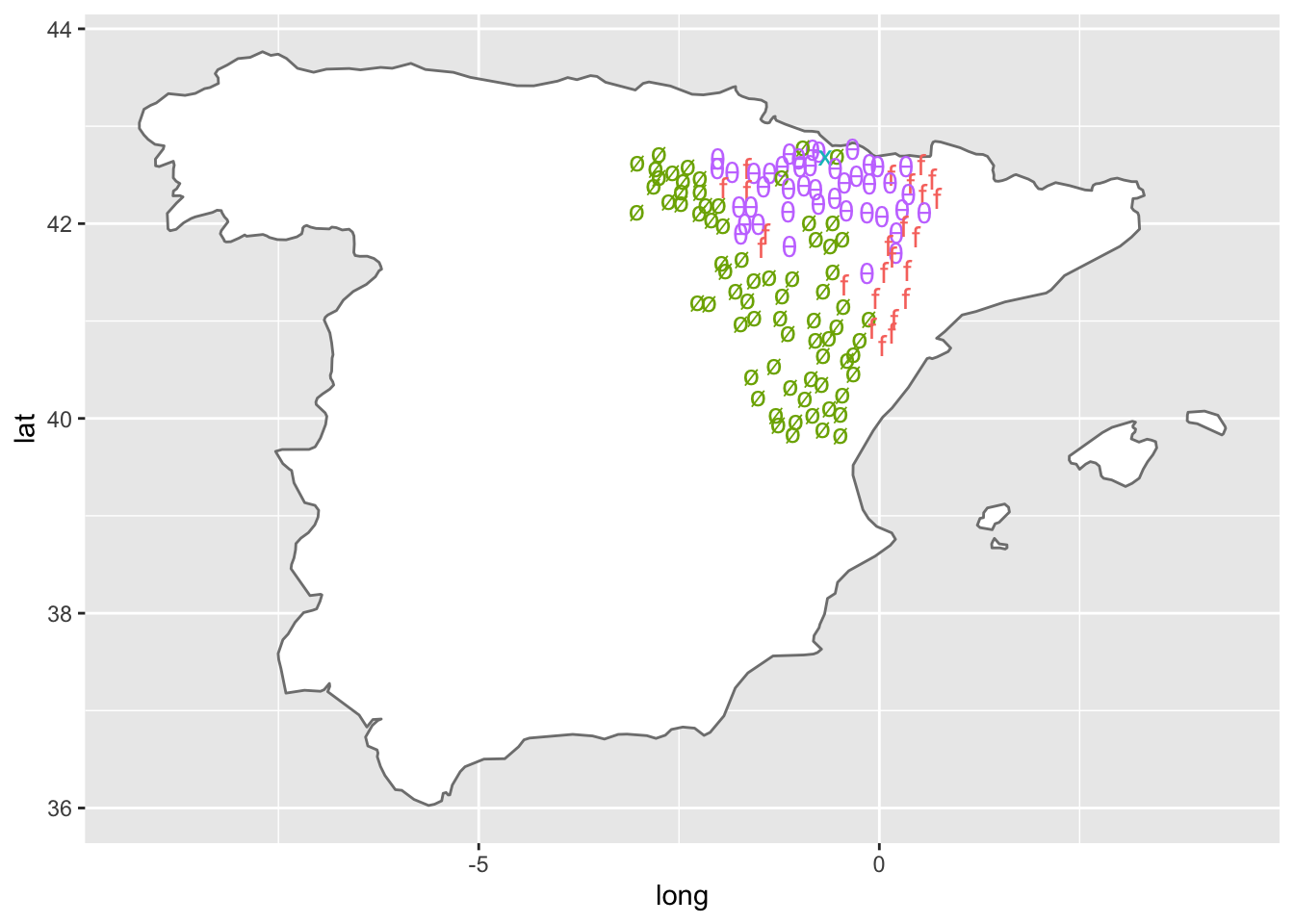
Figura 14.7: Figura 7. Simplificado los casos de li a ø
Ahora que están más claros los resultados, en la banda occidental se observan algunos casos de f conservada que parecen constituir un cierto patrón. No se puede ir más allá porque el mapa subyacente sobre el que has representado los datos es poco preciso y no ofrece los límites políticos, que pueden ser interesantes. Se puede conseguir, pero hay que complicar un poco la cuestión, que es lo que harás en la sección siguiente, pero antes veamos el código para dibujar los mapas anteriores.
library(tidyverse)
datos <- read_tsv("https://raw.githubusercontent.com/7PartidasDigital/AnaText/master/datos/geolinguistic/hinojo_alearn.txt")
datos$F_inicial <- gsub("li", "ø", datos$F_inicial)
ggplot() +
borders("world", "spain", fill = "white") +
geom_text(data = datos,
aes(x=longitud,
y=latitud,
label = F_inicial,
colour = F_inicial),
size = 4) +
theme(legend.position = "none")14.2.1 Explicación del código
Como es usual, lo primero es cargar las librerías necesarias. En este caso basta con {tidyverse}. El siguiente paso es obtener los datos, y los vas a leer del repositorio de 7partidasDigital con read_tsv(). Al hacerlo, te informará del tipo de datos y cómo se llama cada una de las variables. Copia en el editor de RStudio esta línea y ejecútala.
datos <- read_tsv("https://raw.githubusercontent.com/7PartidasDigital/AnaText/master/datos/geolinguistic/hinojo_alearn.txt")## Rows: 179 Columns: 8
## ── Column specification ────────────────────────────────────────────────────────────────────────────────
## Delimiter: "\t"
## chr (6): atlas, provincia, poblacion, id, F_inicial, cl_inter
## dbl (2): latitud, longitud
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.read_tsv), el tipo y nombre de cada una de las columnas. Por último te dice qué has de hacer para que no vuelva a imprimir esa información.
Lo que has hecho ha sido guardar en la tabla datos la información de un fichero tsv que contiene ocho columnas y 179 líneas. Estás acostumbrado a ver el contenido de estas tablas escribiendo el nombre del objeto, en este caso datos, y ejecutándolo en la consola.
## # A tibble: 179 × 8
## atlas provincia poblacion latitud longitud id F_inicial cl_inter
## <chr> <chr> <chr> <dbl> <dbl> <chr> <chr> <chr>
## 1 ALEARN Burgos Bugedo 42.6 -3.02 BU400 li x
## 2 ALEARN Burgos Bugedo 42.7 -2.75 BU400 li x
## 3 ALEARN Castellón Arañuel 40.1 -0.482 CS300 li x
## 4 ALEARN Castellón Segorbe 39.9 -0.485 CS301 ø x
## 5 ALEARN Castellón Bejís 39.9 -0.704 CS302 ø x
## 6 ALEARN Cuenca Valdemeca 40.2 -1.74 CU200 <NA> <NA>
## 7 ALEARN Cuenca Santa Cruz de Moya 40.0 -1.26 CU400 ø x
## 8 ALEARN Guadalajara Tortuera 41.0 -1.80 GU200 <NA> <NA>
## 9 ALEARN Guadalajara Orea 41 -1.73 GU400 ø x
## 10 ALEARN Huesca Sallent de Gállego 42.8 -0.335 HU100 θ x
## # ℹ 169 more rowsOtra forma de verlo, es con glimpse(), que permite ver el nombre de todas las columnas, el tipo de datos que contiene cada una y los primeros valores (observaciones). Puede ser muy interesante cuando tengas tablas con muchas columnas (variables).
## Rows: 179
## Columns: 8
## $ atlas <chr> "ALEARN", "ALEARN", "ALEARN", "ALEARN", "ALEARN", "ALEARN", "ALEARN", "ALEARN", "ALE…
## $ provincia <chr> "Burgos", "Burgos", "Castellón", "Castellón", "Castellón", "Cuenca", "Cuenca", "Guad…
## $ poblacion <chr> "Bugedo", "Bugedo", "Arañuel", "Segorbe", "Bejís", "Valdemeca", "Santa Cruz de Moya"…
## $ latitud <dbl> 42.64917, 42.73472, 40.07110, 39.85328, 39.91087, 40.22374, 39.95631, 40.97150, 41.0…
## $ longitud <dbl> -3.0177780, -2.7472220, -0.4817952, -0.4849939, -0.7038683, -1.7410870, -1.2588730, …
## $ id <chr> "BU400", "BU400", "CS300", "CS301", "CS302", "CU200", "CU400", "GU200", "GU400", "HU…
## $ F_inicial <chr> "li", "li", "li", "ø", "ø", NA, "ø", NA, "ø", "θ", "θ", "θ", "ø", "x", "θ", "θ", "θ"…
## $ cl_inter <chr> "x", "x", "x", "x", "x", NA, "x", NA, "x", "x", "ʎ", "ʎ", "x", "x", "x", "x", "x", N…El siguiente grupo de instrucciones lo que hace es dibujar el mapa y los datos correspondientes. Tan solo te va a representar los resultados de F_inicial (figura 14.8).
ggplot() +
borders("world", "spain", fill = "white") +
geom_text(data = datos,
aes(x=longitud,
y=latitud,
label = F_inicial,
colour = F_inicial),
size = 4) +
theme(legend.position = "none")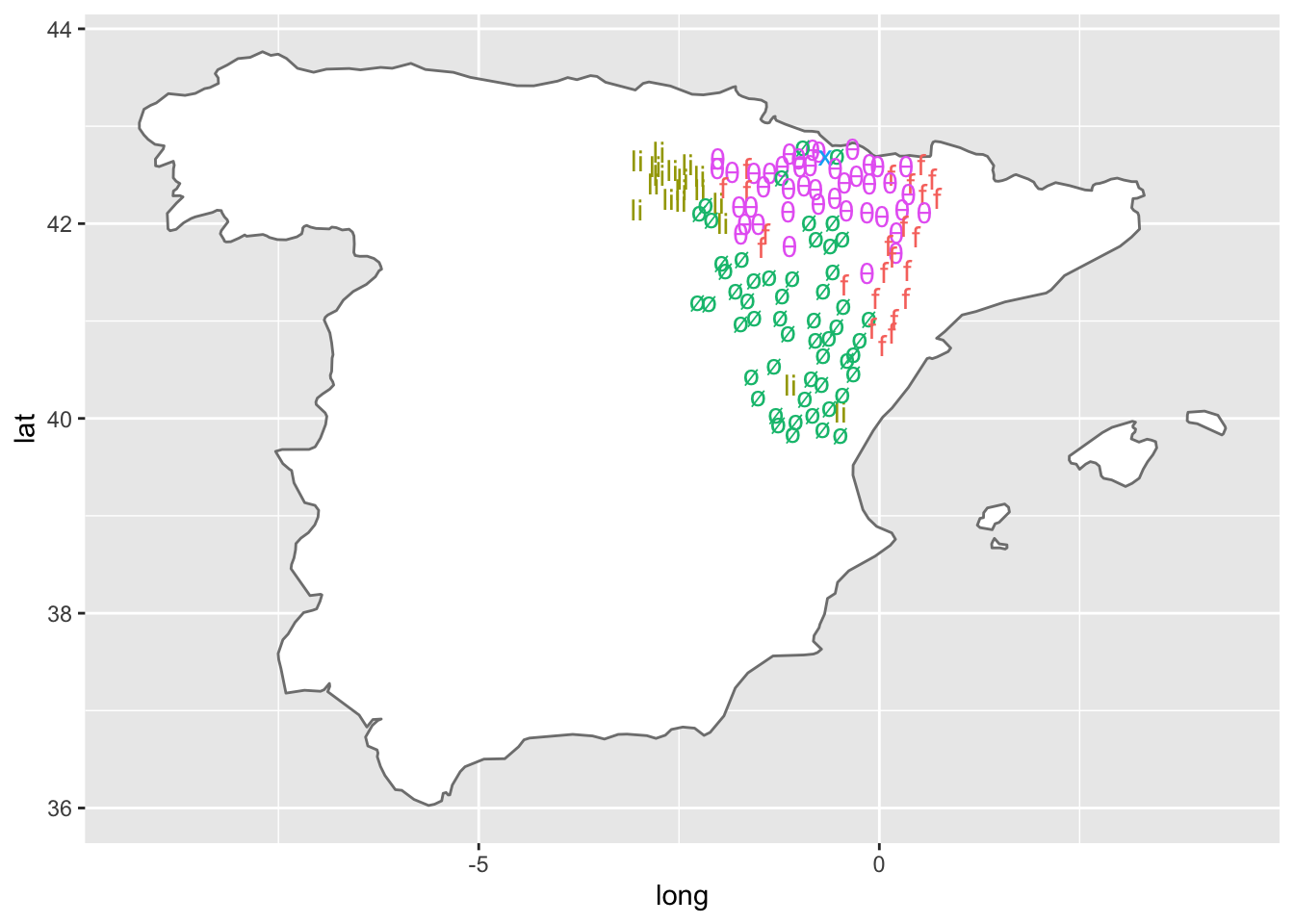
Figura 14.8: Los resultados de F- en el ALEARN
La instrucción básica es ggplot(), todo lo demás es lo que dibuja el mapa. Recuerda que las distintas funciones que se encadenan en ggplot() con un signo de adición + al final de cada instrucción.
borders() se ocupa de dibujar el perfil de mapa y solo requiere dos argumentos: mapa general en el que se basará "world" y si solo quieres un país, el nombre del país que quieres dibujar, en este caso "spain".
Vas a juguetear un poco antes de seguir. Ejecuta en la consola
En la ventana Plots habrá aparecido un mapamundi como el de la figura 14.9.
Figura 14.9: Mapamundi dibujado con ggplot
Para dibujar tan solo el contorno de España, añades el nombre tras el argumento "world", "spain" . Si quieres dibujar más de un país, lo único que tienes que hacer es poner en el segundo argumento una concatenación de nombres con c(). Para dibujar un mapa de todos los países europeos de lengua románica como en el mapa de la figura 14.10.
Figura 14.10: La Europa románica
La instrucción para conseguirlo es:
ggplot() +
borders("world", c("spain", "portugal", "andorra",
"france", "italy", "belgium",
"switzerland", "romania"))Ya solo queda situar en el mapa los datos que tienes en la tabla datos. La instrucción es
geom_text(data = datos,
aes(x=longitud,
y=latitud,
label = F_inicial,
colour = F_inicial),
size = 4)Como acabo de decir, se ocupa de situar en el mapa de España los datos que tienes guardados en la tabla datos, y le indicas con aes() dónde ha de situar cada uno de ellos. Así, en el eje x irá la longitud, en el eje y la latitud. Con label= F_inicial le ordenas que en cada uno de estos puntos determinados por la longitud y la latitud escriba el contenido de la variable F_inicial y con colour = F_inicial le dices que para cada dato diferente que pueda haber en F_inicial emplee un color distinto (hará que el mapa sea más legible; prueba imprimirlo sin colour = F_inicial). La última instrucción size = determina el tamaño de las letras o símbolos que se vayan a representar.
Podrías acabar aquí, pero esto imprimiría en el margen derecho una leyenda horrible que no necesitas, como puedes ver en la figura 14.11.
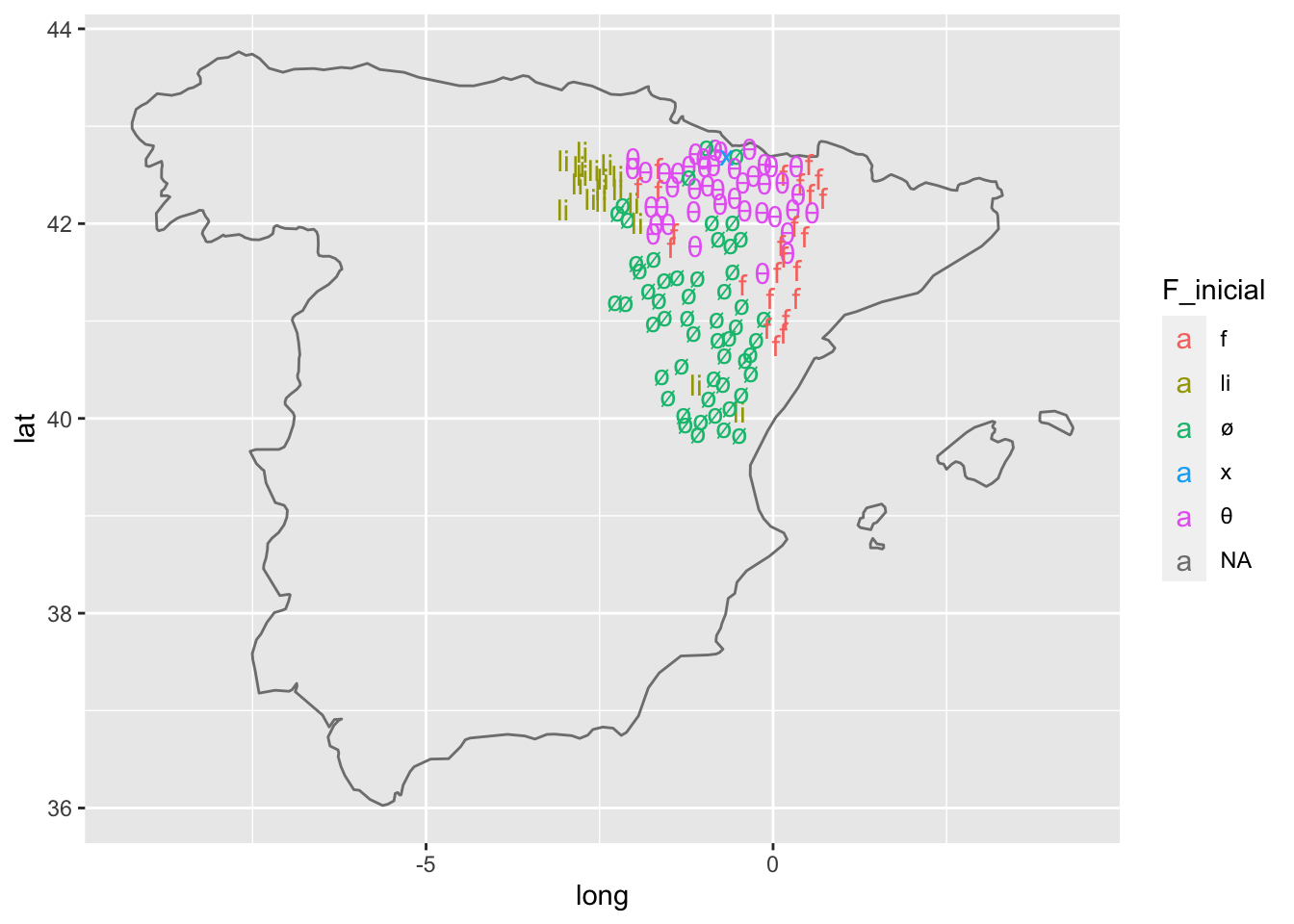
Figura 14.11: Mapa con leyenda explicativa en el margen
Para evitar que se imprima, usarás, en último lugar la instrucción:
que encadenarás a lo anterior con un signo de adición al final de size = 4) +.
Se pueden hacer más cosas como eliminar el fondo gris y las marcas de coordenadas; se puede cambiar el color del interior del mapa; añadir títulos y subtítulos o pie de firma. Todo depende de para qué vayas a usar el mapa después. Este mapita que con el que estamos jugueteando podrías dibujarlo como el de la figura 14.12 para incorporarlo a un trabajo o una transparencia.
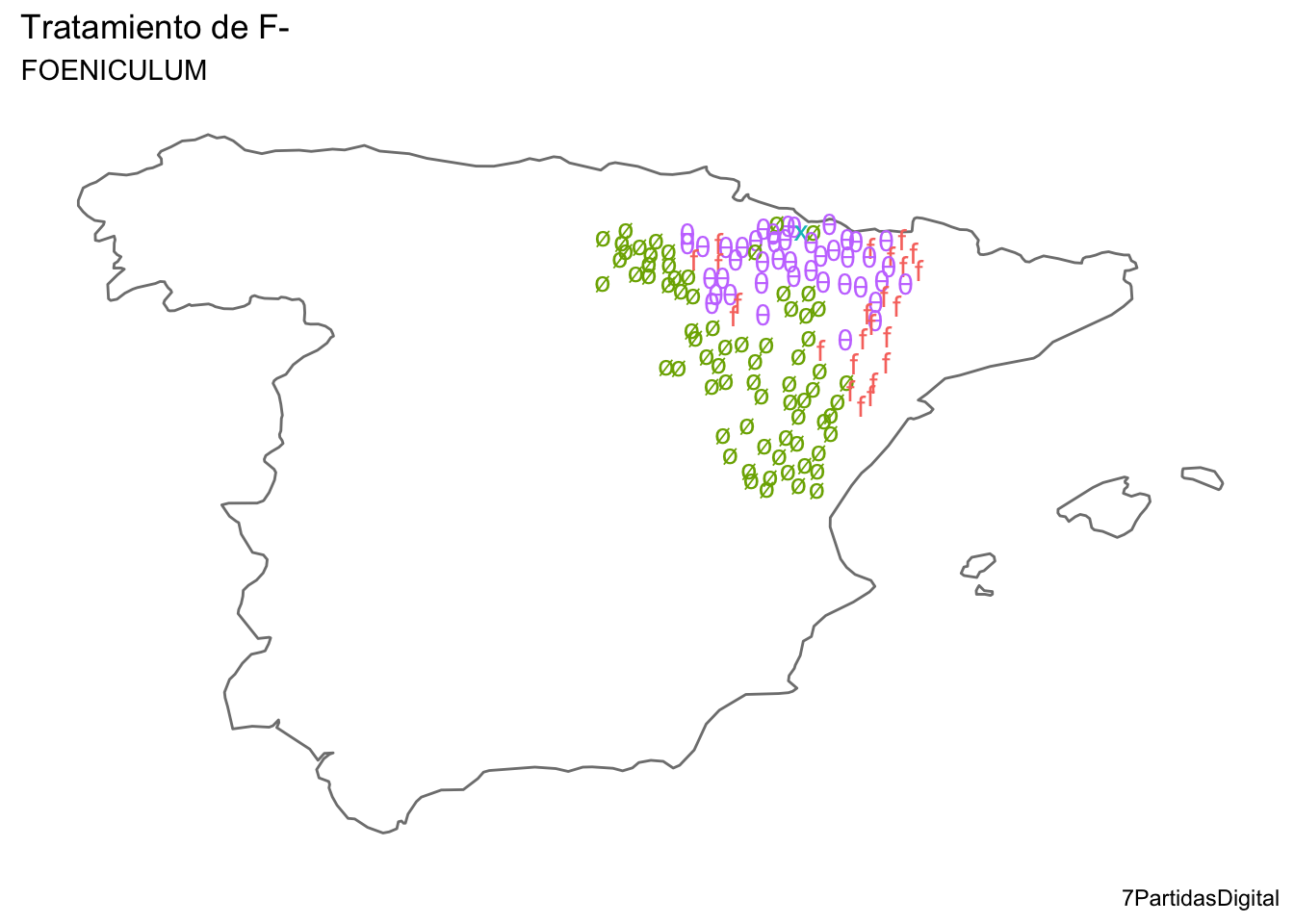
Figura 14.12: Mapa mejorado para su utilización en otro medio
