6 Comparar léxicos
6.1 Introducción
En los capítulos anteriores has visto el corpus de los mensajes navideños en su conjunto. Ahora vas a realizar un análisis comparativo. Vas a comparar el léxico de los discursos de ambos reyes. Pero antes, debes regenerar todos los objetos que necesitas, es decir, cargar los textos y dividirlos en palabras. Si, como se te recomendaba en el capítulo anterior, guardaste en codigo el script que fuiste creando, es el momento de volver a cargarlo y ejecutarlo. Pero si lo prefieres, corta y pega todo el código que hay a continuación y ejecútalo.
# Carga las librerías
library(tidyverse)
library(tidytext)
# Ahora cargará todos los ficheros de los mensajes
ficheros <- list.files(path ="datos/mensajes",
pattern = "\\d+")
anno <- gsub("\\.txt",
"",
ficheros, perl = T)
mensajes <- tibble(anno = character(),
parrafo = numeric(),
texto = character())
for (i in 1:length(ficheros)){
discurso <- readLines(paste("datos/mensajes",
ficheros[i],
sep = "/"))
temporal <- tibble(anno = anno[i],
parrafo = seq_along(discurso),
texto = discurso)
mensajes <- bind_rows(mensajes,
temporal)
}
# Regenera la tabla general con todas las palabras
mensajes_palabras <- mensajes %>%
unnest_tokens(palabra, texto)
# Crea la tabla con todas las palabras y calcula frecuencias
mensajes_frecuencias <- mensajes_palabras %>%
count(palabra, sort = T) %>%
mutate(relativa = n / sum(n))
# Borra objetos que no sirven y que son temporales
rm(temporal, discurso, i)
# Borra palabras vacías
vacias <- read_tsv("https://tinyurl.com/7PartidasVacias")
mensajes_vaciado <- mensajes_palabras %>%
anti_join(vacias)
# Continua aquíSabes que entre 1975 y 2013 reinó Juan Carlos I y que desde 2014 lo hace Felipe VI. Podrías usar estos datos para agrupar la información, pero también puedes crear una nueva variable con el nombre del rey y así manejar tan solo dos variables categóricas: Juan Carlos I y Felipe VI, en vez de las length(list.files("datos/mensajes")) que supone cada año y agruparlas por rey. Copia las líneas de código que hay en la caja siguiente en el editor de RStudio, pero no las ejecutes hasta que hayas leído las explicaciones
mensajes_vaciado <- mensajes_vaciado %>%
mutate(rey = anno) %>%
mutate(rey = ifelse(rey %in% as.character(c(1975:2013)),
"Juan Carlos I",
"Felipe VI"))El primer paso es crear, con la función mutate() la columna (variable) rey y para ello duplicas la columna anno. Esta tendrá como valor los distintos año de cada discurso, por lo que tenemos un sistema sencillo para sustituirlo por los nombres de cada uno de los dos reyes.
Para conseguirlo, cambiarás los números que hay en rey por los nombres, pero de manera condicionada. El cambio lo haces de nuevo con mutate(). Para ello se usa la función ifelse() que lo que hace es comprobar si el valor que hay en la columna rey está en el rango 1975-2013, que son los años de reinado de Juan Carlos I. Si lo están, se cambia el valor por Juan Carlos I y si no se cumple la condición, es decir, que el año es 2014 o superior, entonces el valor se convertirá en Felipe VI.
Para crear este rango construyes un vector con los valores que necesitas con la función c(), que ya has visto. Pero como tienen que ser caracteres y no números, tienes que encerrarlo en la función as.character().
Con el operador %in% lo que se hace es comprobar si se cumple la condición. En caso de que sea verdadera (TRUE) las celdas que tengan un año en el rango 1975-2013 cambian su valor por Juan Carlos I. Si es falsa (FALSE), entonces tomará el valor Felipe VI.
Para que veas cómo funciona el operador %in%, ejecuta estas líneas en la consola:
Lo que va hacer es comprobar si en el vector t existe el valor que hay guardado en v1.
como sí existe, la respuesta es
## [1] TRUESi ahora ejecutas en la consola
La respuesta será
## [1] FALSEya que 101 no figura entre los valores de v2.
La expresión para cambiar los valores de la columna nueva, podrías escribirlos invirtiendo los términos.
mensajes_vaciado <- mensajes_vaciado %>%
mutate(rey = anno) %>%
mutate(rey = ifelse(rey %in% as.character(c(2014:2023)),
"Felipe VI",
"Juan Carlos I"))Lo que hace en este caso es localizar las celdas en las que haya un año del rango 2014-2023 y cambiar su valor por Felipe VI, y en todas las demás, es decir, en las que no se cumple la condición Juan Carlos I.
Ya has añadido la columna con los reyes, con lo que ahora podrás comparar el uso léxico en cada uno de los reinados. Vas a extraer las diez palabras más comunes de cada uno de los dos reyes. Toda la información la tienes en mensajes_vaciado, tan solo tienes que agrupar los mensajes por rey, contar las palabras y extraer las diez más frecuentes. Lo puedes conseguir con
Cuando ejecutes la orden anterior aparecerá en la consola
## # A tibble: 20 × 3
## # Groups: rey [2]
## rey palabra n
## <chr> <chr> <int>
## 1 Juan Carlos I españa 280
## 2 Juan Carlos I españoles 186
## 3 Juan Carlos I año 147
## 4 Juan Carlos I paz 136
## 5 Juan Carlos I sociedad 125
## 6 Juan Carlos I debemos 112
## 7 Juan Carlos I futuro 109
## 8 Felipe VI españa 92
## 9 Juan Carlos I esfuerzo 87
## 10 Juan Carlos I familia 84
## 11 Juan Carlos I libertad 81
## 12 Felipe VI sociedad 54
## 13 Felipe VI debemos 51
## 14 Felipe VI convivencia 48
## 15 Felipe VI españoles 46
## 16 Felipe VI futuro 45
## 17 Felipe VI gran 41
## 18 Felipe VI hoy 39
## 19 Felipe VI país 39
## 20 Felipe VI tenemos 39aunque antes de imprimir el resultado te habrá avisado de que la selección de los datos se ha hecho por medio de la columna n, que es la que contiene las frecuencias de aparición, que es lo que le has pedido que tenga en cuenta con la instrucción top_n(10).
## Selecting by nEl resultado que ha impreso presenta los datos de las diez palabras más frecuentes de cada rey, de ahí que la segunda línea de la tabla diga Groups: rey [2]. Si no hubieras introducido esta línea solo te habría ofrecido las diez primeras líneas para el rey Juan Carlos I. Puedes observar que España es la top de ambos monarcas, y que españoles ha bajado a la sexta posición en Felipe VI. En este han aparecido dos palabras, convivencia e historia, que no están entre las top de Juan Carlos I. Pero ver tablas es poco iluminador. Es más fácil hacer la comparación por medio de gráficos de barras paralelos como el de la figura 6.1.
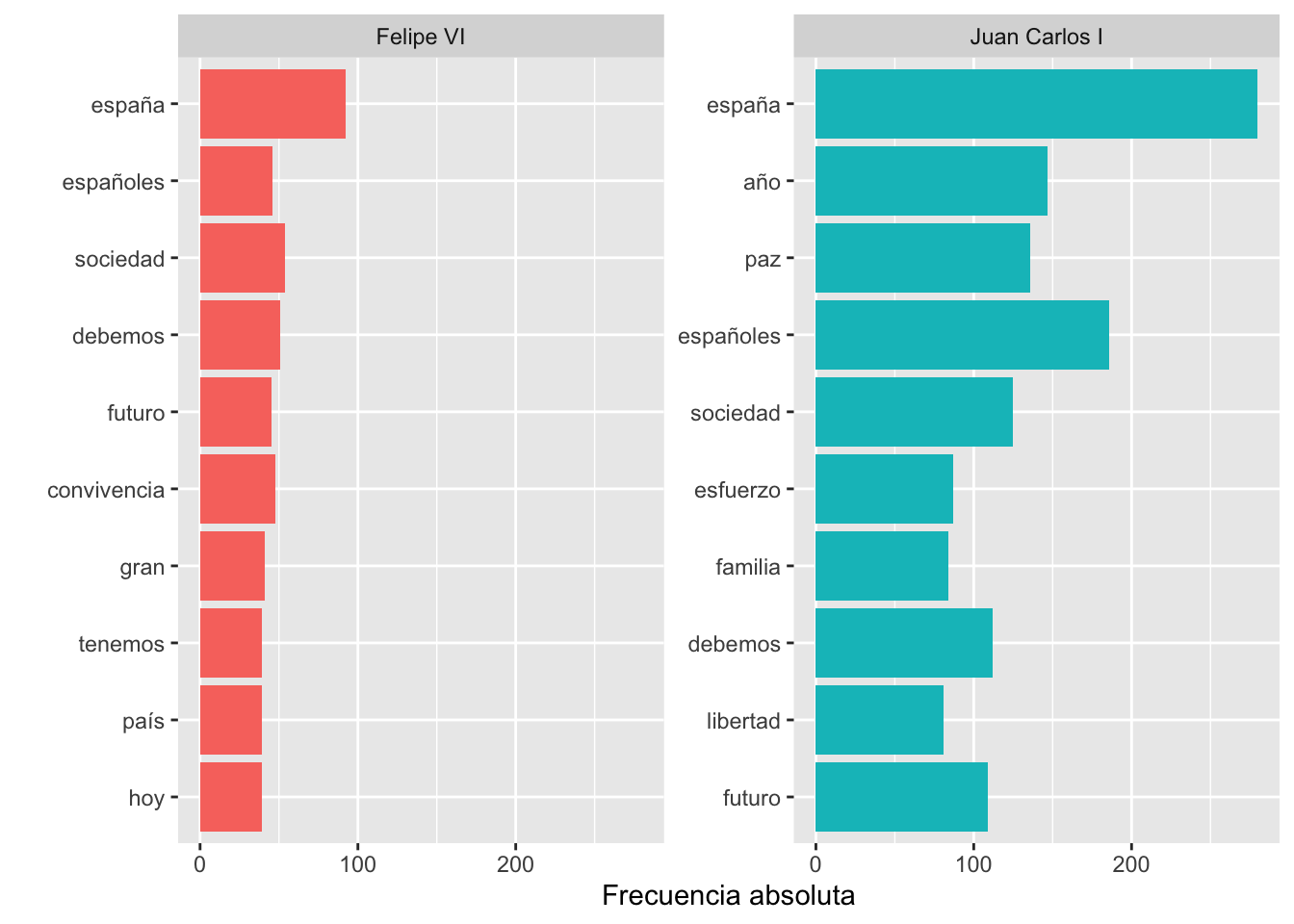
Figura 6.1: Las 10 palabras más frecuentes en ambos monarcas
Para conseguirlo has de añadir tras top_n(10) el bloque de código que hay en la siguiente caja, pero antes de hacerlo escribe en esta última línea %>% e introduce un intro.
ggplot(aes(reorder(palabra, n),
n,
fill = rey)) +
geom_bar(stat = "identity") +
facet_wrap(~rey,
scales = "free_y") +
labs(x = "",
y = "Frecuencia absoluta") +
coord_flip() +
theme(legend.position="none")La línea de labs() supongo que la habrás aprendido al hacer una de las prácticas del capítulo anterior, pero te recuerdo qué es lo que hace: se ocupa de cambiar las leyendas que aparecen en los ejes X e Y de la gráfica. Como en el eje X se imprimirán las palabras, no hace falta poner leyenda alguna, pero sí en el eje Y. La única novedad con respecto a los gráficos que has dibujado con anterioridad es facet_wrap(). Esta es muy interesante y útil cuando se quiere comparar gráficas con los datos de dos o más variables puesto que permite dibujarlas unas junto a otras. Lo único que necesita saber R es la fuente de los datos, ~rey. El argumento scales = "", tiene un valor por defecto, que es fixed, pero puede ser "free_y" como en el ejemplo anterior, "free_x" o "free".
top_n() a 30 y con el valor por defecto para scales().
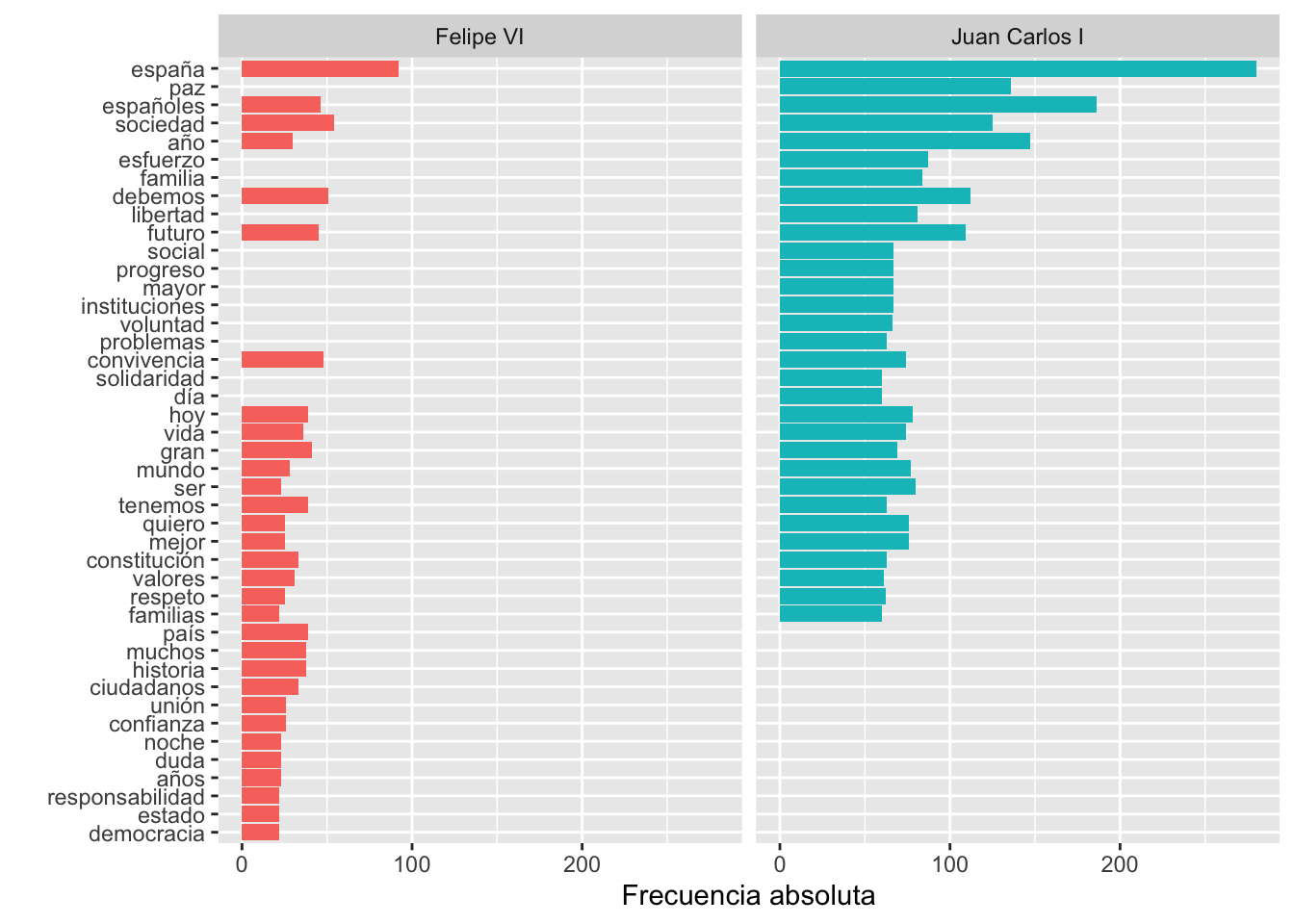
Figura 6.2: Las 30 palabras más frecuentes en ambos monarcas con el valor por defecto para scales()
Las líneas en las que no hay barra, como puedes suponer, indica que son palabras que no existen en los discursos de uno u otro rey.
También puedes ver cuáles son las palabras más frecuentes en cada discurso del rey Felipe (figura 6.3).
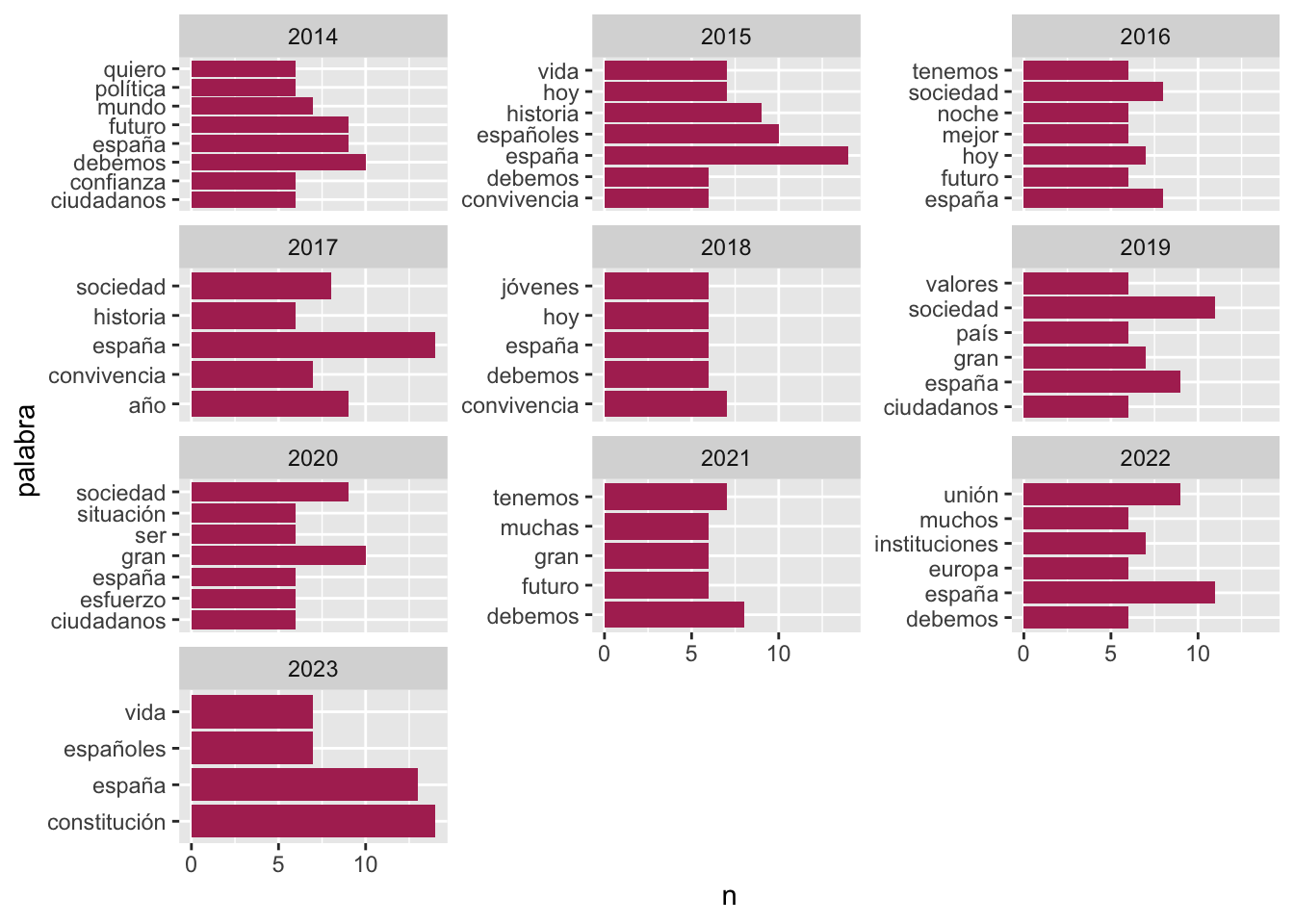
Figura 6.3: Las palabras más frecuentes en los discursos de Felipe VI
La gráfica de la figura 6.3 se consigue con dos grupos de instrucciones. El primero crea la tabla con los datos y el segundo se ocupa de dibujar la gráfica.
mensaje_anno <- mensajes_vaciado %>%
select(rey, anno, palabra) %>%
group_by(anno) %>%
count(palabra, sort =T) %>%
ungroup()El código anterior crea una nueva tabla que se llamará mensaje_anno con tres variables procedentes de mensajes_vaciado: rey, anno y palabra. Estas se seleccionan con la función select(). Hay, sin embargo, un pequeño problema: ha seleccionado todas las filas, incluidas las del rey Juan Carlos, por lo que tienes que eliminarlas. Esto se puede hacer con filter(). Como tan solo te interesan los discursos del rey Felipe, el primer argumento es el nombre de la columna que ha de usar; en este caso rey. Pero tan solo te interesa extraer aquellas cuyo valor sea Felipe VI. Para expresar la igualdad se usan dos iguales seguidos ==. Podrías expresarlo de otra manera: filter(rey != "Juan Carlos I"), es decir, selecciona todas aquellas filas en las que no aparezca Juan Carlos I, es decir, que sea distinto !=. Ya te dije que muchas cosas se pueden hacer en R de más de una manera.
El bloque de código mejorado para crear mensaje_anno es
mensaje_anno <- mensajes_vaciado %>%
select(rey, anno, palabra) %>%
filter(rey == "Felipe VI") %>%
group_by(anno) %>%
count(palabra, sort =T) %>%
ungroup()Ya tienes en mensaje_anno toda la información sobre los discursos de Felipe VI. Pero aún no has hecho las cuentas. Como quieres contar separadamente las palabras de cada uno de los años, se lo tienes que indicar a R con group_by(anno). A continuación, cuentas las palabras y, por último, deshaces la agrupación anual, puesto que ya no sirve para nada.
El segundo bloque, como te he indicado, se ocupa de dibujar la gráfica. Cópialo y pégalo en el editor de RStudio, pero no lo ejecutes hasta que hayas leído la explicación que le sigue.
mensaje_anno %>%
filter(n > 5) %>%
ggplot(aes(x = palabra,
y = n)) +
geom_col(fill = "aquamarine") +
coord_flip() +
facet_wrap(~ anno,
ncol = 3,
scales = "free_y")mensaje_anno están todas las palabras, pero como no quieres representarlas todas en una gráfica, sería horrible, tienes que tomar una decisión: el número mínimo de ocurrencias e indicárselo a R. Esto lo consigues con la función filter(). Ahí puedes establecer el número de ocurrencias n que debe considerar. Yo he puesto > 5, es decir, imprime en cada gráfica todas aquellas palabras cuya frecuencia de aparición sea mayor de 5. Juega tú con varios valores y extrae tus conclusiones. Haz lo mismo con el literal de fill = "", que es el responsable de los colores de las barras.
6.2 Comparar la frecuencia del léxico
6.2.1 Introducción
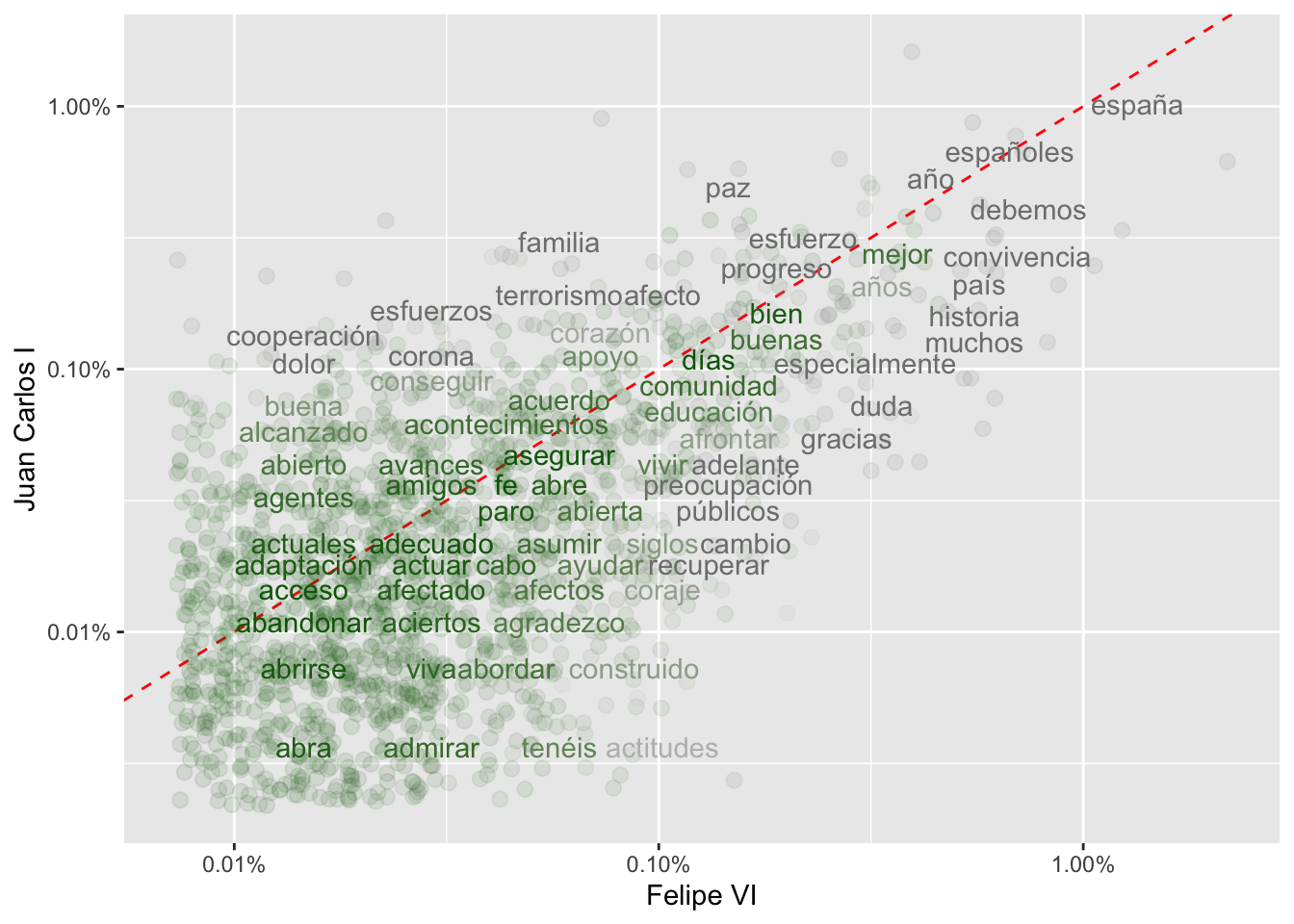
Figura 6.4: Las palabras más frecuentes en los discursos de ambos monarcas según las frecuencias
El gráfico de la figura 6.4 representa la comparación de la frecuencia de las palabras usadas por Juan Carlos I frente a las de Felipe VI. Las que están por encima de la línea son palabras que tienen una frecuencia de ocurrencia mayor en los discursos del rey Juan Carlos, mientras que las que están en la parte inferior lo son más en los de Felipe VI. Cuanto más próximas estén a la línea más semejante es la frecuencia de aparición en ambos conjuntos. Así, por ejemplo, España, españoles y año son palabras de muy alta frecuencia en ambos reyes mientras que acuerdos y construir aparecen con la misma frecuencia en ambos, pero en el parte baja, es decir, con poca frecuencia. Por otra parte, cuanto más alejadas estén de la línea, son palabras más frecuentes en un conjunto que en el otro. Por ejemplo, actitudes es más abundante en los discursos de Felipe VI (2 ocurrencias en 2016 y 1 en 2018) que en los de su padre (1 sola vez en 2010), mientras que justicia abunda en los de Juan Carlos I (54 ocurrencias a lo largo de los años, frente a una sola en Felipe VI, en 2017).
6.2.2 Preparar el entorno
El código para dibujar la gráfica de la figura 6.4 te lo presento y explico a continuación. Gran parte de él ya te es conocido, con lo que solo explicaré lo nuevo. Arranca una nueva sesión de RStudio, así te aseguras de que no hay nada escondido de una ejecución anterior.
Como de costumbre, lo primero es cargar las librerías básicas.
A continuación, lee los nombres de los ficheros de cada uno de los mensajes
y creas el vector anno que contendrá las fechas
aunque también lo podrías hacer con
En esta ocasión necesitas los nombres de los reyes. Podrías hacerlo por las fechas, pero es un poco más complicado. Lo siguiente es crear un vector con los nombres de los reyes. Tiene que estar 39 veces Juan Carlos I y diez Felipe VI. El primer paso es crear un vector para cada rey: JCI y FVI. Como lo que quieres es repetir varias veces el nombre en cada uno de ellos, lo único que tienes que hacer es usar la función rep() –repetir– que requiere dos argumentos: lo que quieres repetir y el número de veces que lo quieres repetir. Como este será el contenido de una futura columna (variable) llamada rey que contendrá el nombre los dos, creas un nuevo vector uniendo los dos anteriores con la función c(). Aquí el orden es fundamental, primero JCI y después FVI.
aunque también lo puedes hacer con la expresión condensada
con lo que te ahorras el crear dos vectores, JCI y FVI, que no usarás de nuevo.
El siguiente paso es generar la tabla en la que guardarás todos los mensajes y la lectura de los ficheros. La única novedad es que añades la variable (columna) rey. Como puedes suponer, el bucle for leerá secuencialmente el nombre de cada uno de ellos, como los años.
mensajes <- tibble(anno = character(),
rey = character(),
parrafo = numeric(),
texto = character())
for (i in 1:length(ficheros)){
discurso <- readLines(paste("datos/mensajes",
ficheros[i],
sep = "/"))
temporal <- tibble(anno = anno[i],
rey = rey[i],
parrafo = seq_along(discurso),
texto = discurso)
mensajes <- bind_rows(mensajes, temporal)
}A continuación, creas dos nuevas tablas, una por cada rey: FVI y JCI. Cada una de estas tablas solo va a contener el texto, no te interesan ni los años ni ningún otro dato. Quizá digas… el nombre del rey. No, no es necesario ya que lo tienes en el nombre del objeto en el que vas a guardar los textos JCI y FVI.
FVI <- mensajes %>%
filter(rey == "Felipe VI") %>%
select(texto)
JCI <- mensajes %>%
filter(rey == "Juan Carlos I") %>%
select(texto)rey, vas a reutilizar el nombre de dos objetos que ya no te serán necesarios: JCI y FVI. Si usaste el segundo método, los creas por primera vez.
Los datos los extraerás de mensajes con la función select(), pero de cada uno de los reyes con filter(). El orden de las funciones es vital: primero se filtra (filter) el rey, y después se selecciona (select) el texto.
Si quieres te puedes deshacer de los objetos que ya no vas a utilizar con
Carga ahora la lista de palabras vacías.
Si no lo tienes guardardada en el disco duro (te expliqué cómo hacerlo en el capítulo anterior), usa esta otra orden, que lo leerá desde el repositorio externo del proyecto.
En cualquiera de los dos casos te responderá
## Rows: 465 Columns: 1
## ── Column specification ────────────────────────────────────────────────────────────────────────────────
## Delimiter: "\t"
## chr (1): palabra
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.En el capítulo anterior usaste read_csv para cargar la lista de palabras vacías. Los ficheros csv son tablas en las que los diferentes valores están separados por comas, de ahí el csv (= comma separated values). En esta ocasión, aunque es el mismo fichero, he usado read_tsv, en este caso se trataría de una tabla cuyos valores están separados por tabuladores, de ahí el tsv (= tab separated values).
tsv porque su contenido son textos y como estos pueden contener comas se podrían provocar errores. Sin embargo, en el caso de los ficheros de texto separados por comas (csv), el contenido textual tendría que estar encerrado entre comillas. Esto último supone otro pequeño problema puesto que en los textos puede haber citas y expresiones entrecomilladas, con lo que habría que solucionar este nuevo problemilla (no lo es tanto en español si no utilizamos las comillas rectas " sino las tipográficas, tanto «» como “”. Todos estos problemas se pueden solucionar, pero cualquier solución es un poco más compleja que separar los valores con tabuladores.
A continuación, divide los discursos de ambos monarcas en palabras y borra las palabras vacías.
Una vez que hayas ejecutado ambas órdenes, en la consola se habrá impreso el mensaje
## Joining with `by = join_by(palabra)`Tan solo te informa de que la variable común por medio de la que has borrado las palabras vacías es palabra.
6.2.3 Calcular las frecuencias
Establecer cuáles son las palabras más frecuentes en uno y otro rey es cuestión de calcular las frecuencias, pero tienes que hacerlo por porcentajes, de otro modo no podrías comparar los discursos de ambos reyes, pues uno tiene 39 discursos y el otro tan solo diez, por lo que para evitar este problema se usan las frecuencias relativas o porcentajes. Para hacerlo vas a crear una nueva tabla en la que solo tendrás las palabras, también borrarás los números ya que aparecen muchas veces, por lo general son los años (1975…2023), pero hay otros.
FVI_porcentaje <- FVI_palabras %>%
mutate(palabra = str_extract(palabra, "\\D+")) %>%
count(palabra) %>%
transmute(palabra, Felipe = n / sum(n), rey = "Felipe VI")
JCI_porcentaje <- JCI_palabras %>%
mutate(palabra = str_extract(palabra, "\\D+")) %>%
count(palabra) %>%
transmute(palabra, JuanCarlos = n / sum(n), rey = "Juan Carlos I")Para ello usarás la función mutate() y le dirás que conserve en palabra todo aquello que no sean dígitos. Para conservar solo las palabras usarás la función str_extract() que emplea las expresiones regulares. Esta función necesita saber el nombre de la variable que ha de manejar y el patrón que ha de utilizar. La variable va en primer lugar, la expresión regular en segundo. Como lo que quieres es conservar lo que no sean números, usarás el patrón \\D+ que lo que hace es tomar todo aquello que no sean números. Podrías indicarlo de otra manera, con [[:alpha:]]+ que solo tomaría las palabras. De nuevo, te recuerdo que con R las cosas se pueden hacer de más de una manera.
En el siguiente paso cuentas las palabras con count(). Y en el tercero conservas la variable palabra, creas la columna con la frecuencia, pero la identificarán con el nombre del rey correspondiente –JuanCarlos y Felipe– y por último creas una nueva variable –rey– con el nombre del rey. Pero como no quieres conservar la variable n, que es la que almacena las frecuencias absolutas, utilizas transmute() en vez de mutate() porque transmute() solo conserva las variables que se crean y aquellas que se le indican que debe conservar de la tabla de origen.
Solo queda un último paso antes de poder dibujar el gráfico: unir ambas tablas en una sola, en reyes_frecuencias, y lo consigues con esta orden
Primero guardas en reyes_frecuencias el contenido de FVI_porcentaje. Después le pides que incorpore JCI_porcentaje, pero de una manera especial en la que el elemento clave es la variable palabra. Puesto que en JCI_porcentaje habrá palabras que no estén en FVI_porcentaje y en este habrá palabras que no estén en aquel, R lo remediará incluyendo en esas casillas que no existe con NA (= not available ‛no disponible’), por eso usas la función left_join(). Échale una ojeada la tabla. Para hacerlo, ejecuta en la consola
La respuesta será
## # A tibble: 2,324 × 5
## palabra Felipe rey.x JuanCarlos rey.y
## <chr> <dbl> <chr> <dbl> <chr>
## 1 abandonar 0.000146 Felipe VI 0.000130 Juan Carlos I
## 2 abdicación 0.000146 Felipe VI NA <NA>
## 3 abierta 0.000729 Felipe VI 0.000348 Juan Carlos I
## 4 abierto 0.000146 Felipe VI 0.000522 Juan Carlos I
## 5 abiertos 0.000292 Felipe VI NA <NA>
## 6 abnegación 0.000292 Felipe VI 0.000130 Juan Carlos I
## 7 abordar 0.000438 Felipe VI 0.0000870 Juan Carlos I
## 8 abra 0.000146 Felipe VI 0.0000435 Juan Carlos I
## 9 abre 0.000583 Felipe VI 0.000435 Juan Carlos I
## 10 abrirme 0.000146 Felipe VI NA <NA>
## # ℹ 2,314 more rowsTan solo te muestra las diez primeras de las 2324 palabras. Fíjate que abdicación, abiertos y abrirme son palabras que utiliza Felipe VI, pero no Juan Carlos I, por eso en la casilla correspondiente de la columna JuanCarlos (y rey.y) aparece NA. Ya estás en disposición de dibujar la gráfica, pero necesitas una librería especial para poder dibujarla ya que si no los datos se perderían en la gráfica. La librería que necesitas es {scales}. Instálala en tu ordenador
y cárgala.
6.2.4 Dibujar la gráfica comparativa
Ya estás en disposición de dibujarla; el resultado será la gráfica de la figura 6.5. Es una instrucción compleja. Te acuerdas que te lo dije, que podía ser complicado. Aquí tienes un buen ejemplo. Te explico qué hace en cada línea. Ten cuidado con los paréntesis, las comas y los mases cuando copies el código.
ggplot(data = reyes_frecuencias,
mapping = aes(x = Felipe,
y = JuanCarlos,
color = abs(JuanCarlos - Felipe))) +
geom_abline(color = "red",
lty = 2) +
geom_jitter(alpha = 0.1,
size = 2.5,
width = 0.3,
height = 0.3) +
geom_text(aes(label = palabra),
check_overlap = T,
vjust = 1.5) +
scale_x_log10(labels = percent_format()) +
scale_y_log10(labels = percent_format()) +
scale_color_gradient(limits = c(0, 0.001),
low = "darkgreen",
high = "gray") +
facet_wrap(~ rey.x,
ncol = 2) +
theme(legend.position="none") +
labs(y = "Juan Carlos I",
x = "Felipe VI")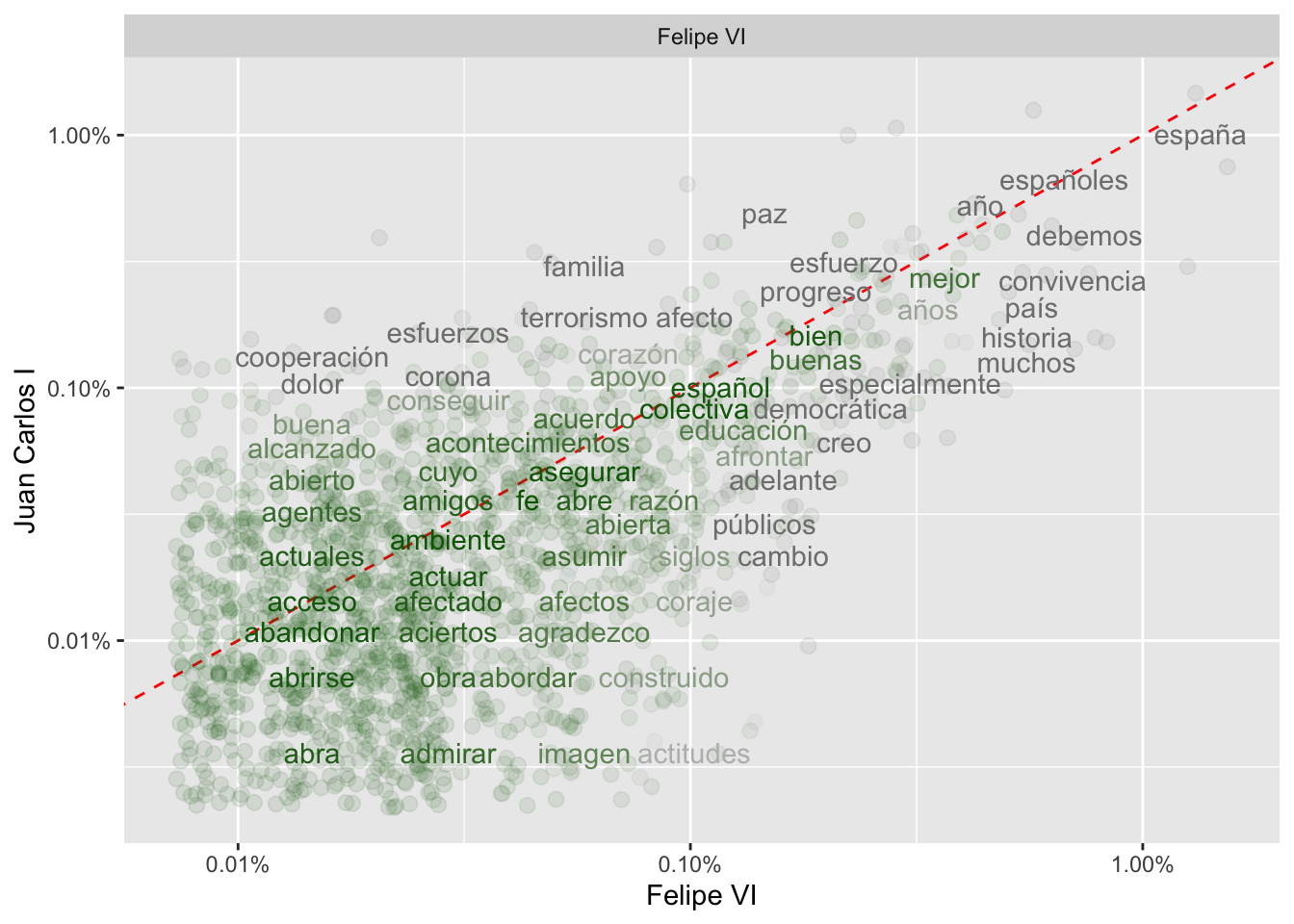
Figura 6.5: Las palabras más frecuentes en los discursos de ambos monarcas según las frecuencias
Como ya sabes, para trazar cualquier gráfico empleas la función ggplot(). Recuerda que las diferentes instrucciones de ggplot se encadenan con el signo +, así que cada vez que lo introduzcas pulsa intro. También lo he hecho tras cada coma en los argumentos para que puedas leer el código con comodidad, pero no es necesario. Esta primera línea indica con data = de dónde tomarás los datos, en este caso de reyes_frecuencias; de ese objeto tomará tan solo los datos de las variables Felipe y JuanCarlos mientras que el argumento color = se ocupa del color de los puntos, pero aquí es una curiosa fórmula a base de restar los valores de Felipe a JuanCarlos y tomarlo como un valor absoluto –abs–, sin tener en cuenta su signo.
La función geom_abline() dibujará la línea que separa ambos conjuntos de datos (ya usaste geom_hline() para dibujar la media y la mediana) capítulos atrás. Los argumentos indican el color y lty = el tipo de línea (figura 6.6). geom_jitter() es el responsable de que el color de los puntos sean más o menos oscuros, pues depende de los valores de x e y. alpha define la transparencia (1 = opaco), size es el tamaño, y width y height indican cómo se dispersarán los puntos en el gráfico. geom_text() se encarga de imprimir en el gráfico las etiquetas (label) pertinentes, en este caso se trata de los valores de palabra. El argumento check_overlap = T evita que las palabras muy próximas se sobreimpriman una sobre otras y conviertan el gráfico en ilegible (pruébalo; borra este argumento y vuelve a imprimir el gráfico. Ilegible, ¿verdad?). El último, vjust es la justificación vertical de la etiqueta. Es decir, pequeñeces para que la gráfica quede más bonita y legible.
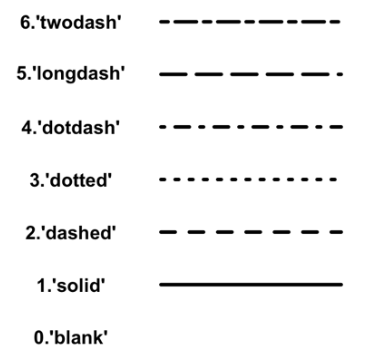
Figura 6.6: Figura 6. Posibles valores de lty
Las dos líneas siguientes, cuyas funciones comienzan con scale_ y acaban con _log10, son un truco para que la gráfica sea comprensible al comparar valores que cubren una amplia gama. Lo que hace es pedirle que trate los ejes x e y en escala logarítmica.
scale_color_gradient() se ocupa de la escala de los colores de los puntos y de las etiquetas dentro del gráfico y oscila entre dos límites marcados por high y low, donde pones los colores entre los que variará (juguetea cambiando los colores).
scale_, así no se ejecutarán. Ejecuta el código y comprueba la diferencia entre usar y no usar la escala logarítmica.
La dos últimas líneas, creo que ya te son conocidas. theme() es la responsable de que no se imprima una leyenda explicativa y labs() se ocupa de las etiquetas de los ejes, e incluso, recuerda, puede servirte para poner títulos, subtítulos y avisos.
Cuando ejecutes el código anterior, se habrá impreso en la consola un mensaje de aviso con dos líneas cuyo tenor es parecido a este
Warning messages:
1: Removed 391 rows containing missing values (geom_point).
2: Removed 392 rows containing missing values (geom_text).R te avisa de que hay un número de líneas en las que no hay valores. Son los NA de palabras como abdicación, abiertos, y abrirme que viste al echarle una ojeada a reyes_frecuencias.
Pero fíjate que en la parte superior del gráfico (figura 6.5) hay una banda gris que dice Felipe VI. Es información redundante porque la tienes en el eje horizontal. Puedes eleminarla si añades en la penúltima línea strip.text.x = element_blank(). Esa línea debe ser idéntica a esta
Es algo meramente estético, pero si lo haces así, el gráfico quedará mucho más elegante, como puedes ver en la figura 6.7.
ggplot(data = reyes_frecuencias,
mapping = aes(x = Felipe,
y = JuanCarlos,
color = abs(JuanCarlos - Felipe))) +
geom_abline(color = "red", lty = 2) +
geom_jitter(alpha = 0.1, size = 2.5, width = 0.3, height = 0.3) +
geom_text(aes(label = palabra), check_overlap = T, vjust = 1.5) +
scale_x_log10(labels = percent_format()) +
scale_y_log10(labels = percent_format()) +
scale_color_gradient(limits = c(0, 0.001),
low = "darkgreen",
high = "gray") +
facet_wrap(~ rey.x, ncol = 2) +
theme(legend.position="none", strip.text.x = element_blank()) +
labs(y = "Juan Carlos I", x = "Felipe VI")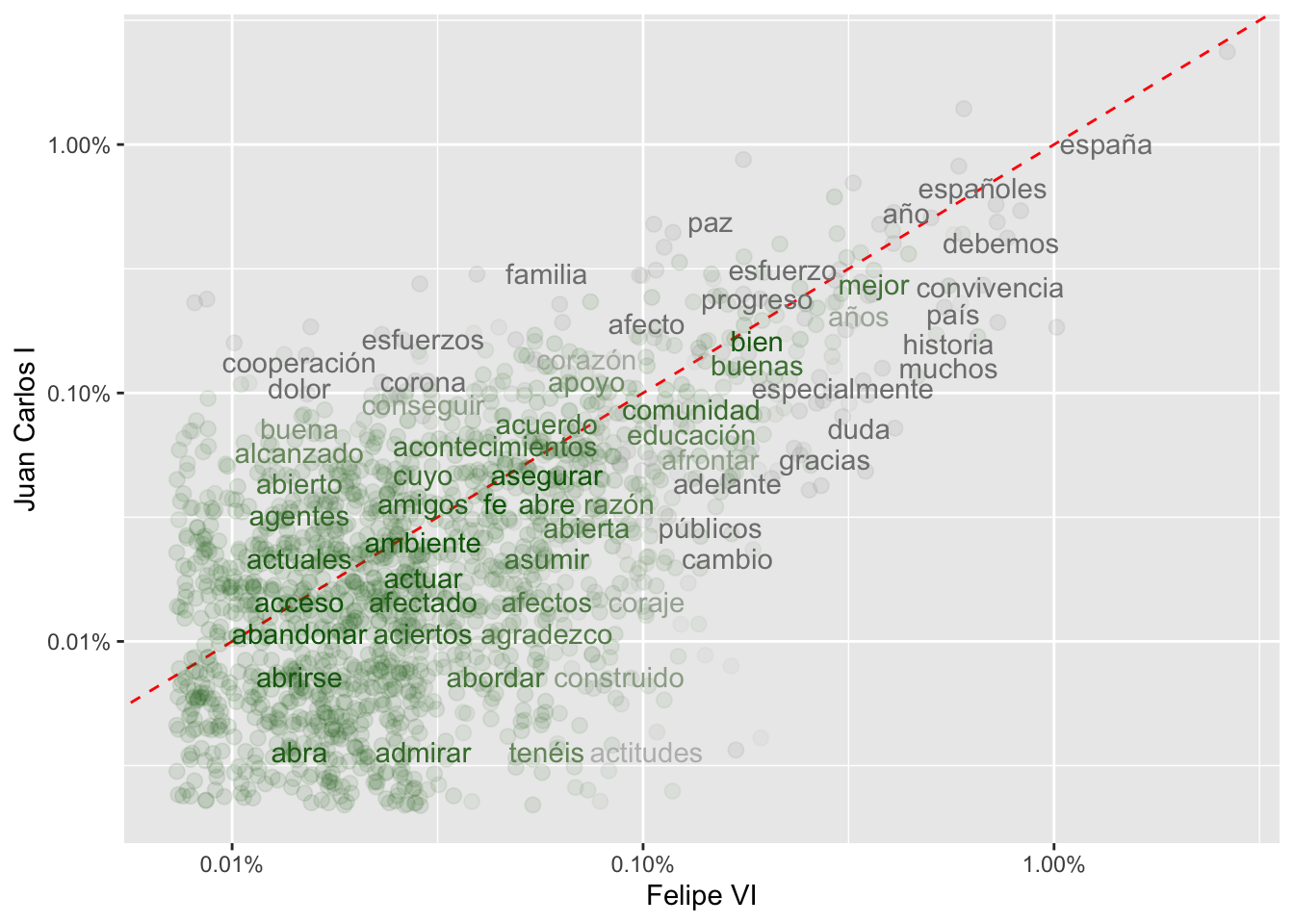
Figura 6.7: Las palabras más frecuentes en los discursos de ambos monarcas según las frecuencias
Ahora tiene un aspecto mejor.
