11 Análisis de sentimientos aplicado a la literatura
11.1 La forma de las historias
11.1.1 Introducción
El análisis de sentimientos, también llamado minería de opinión, es en una serie de técnicas informáticas que se utilizan para clasificar automáticamente un texto con un sentimiento positivo o negativo (Pang y Lee 2008) e incluso con alguna de las emociones básicas (Plutchik 1980). Si ya es difícil conseguir que dos personas se pongan de acuerdo acerca de si un texto es más o menos positivo, más o menos negativo, puesto que pueden influir aspectos culturales y la experiencia anterior de cada uno de ellos, mucho más difícil es que un ordenador pueda establecerlo, pues para una máquina un texto cualquiera es una mera secuencia de ceros y unos. A pesar de ello, un ejército de ingenieros, de estadistas y algún que otro lingüista están invirtiendo cantidades ingentes de tiempo y recursos para conseguirlo, pues sus clientes pueden ganar o perder mucho dinero si no son capaces de adaptarse con prontitud ante la reacción del público ante una campaña de publicidad o la mala acogida de un producto, por ejemplo.
En la actualidad hay dos aproximaciones: la del aprendizaje automático (machine learning) que consiste en entrenar un clasificador usando un algoritmo de aprendizaje supervisado a partir de una colección de textos anotados, donde cada texto habitualmente se representa como una bolsa de palabras (BoP o BoW = bag of words) o secuencia de palabras (n-grams), en combinación con otro tipo de características semánticas que intentan modelar la estructura sintáctica de las frases, la intensificación, la negación, la subjetividad o la ironía.
El otro modo es el enfoque semántico. Este se caracteriza por el uso de diccionarios de términos o lexicones en los que cada palabra está marcada con una orientación semántica de polaridad u opinión. Estos sistemas, por lo general, lo que hacen es preprocesar el texto, para lo que lo dividen en palabras, pero como hay muchas que no tienen ningún valor, las palabras gramaticales (artículos, conjunciones, preposiciones…), las eliminan comparando los textos contra una lista de palabras vacías (stopwords), y luego se ve si las palabras existen en el lexicón y qué valor de polaridad se les ha dado y, por medio de sumar y restar los valores positivos y negativos llega a establecerse una valencia para el sentimiento de un texto.
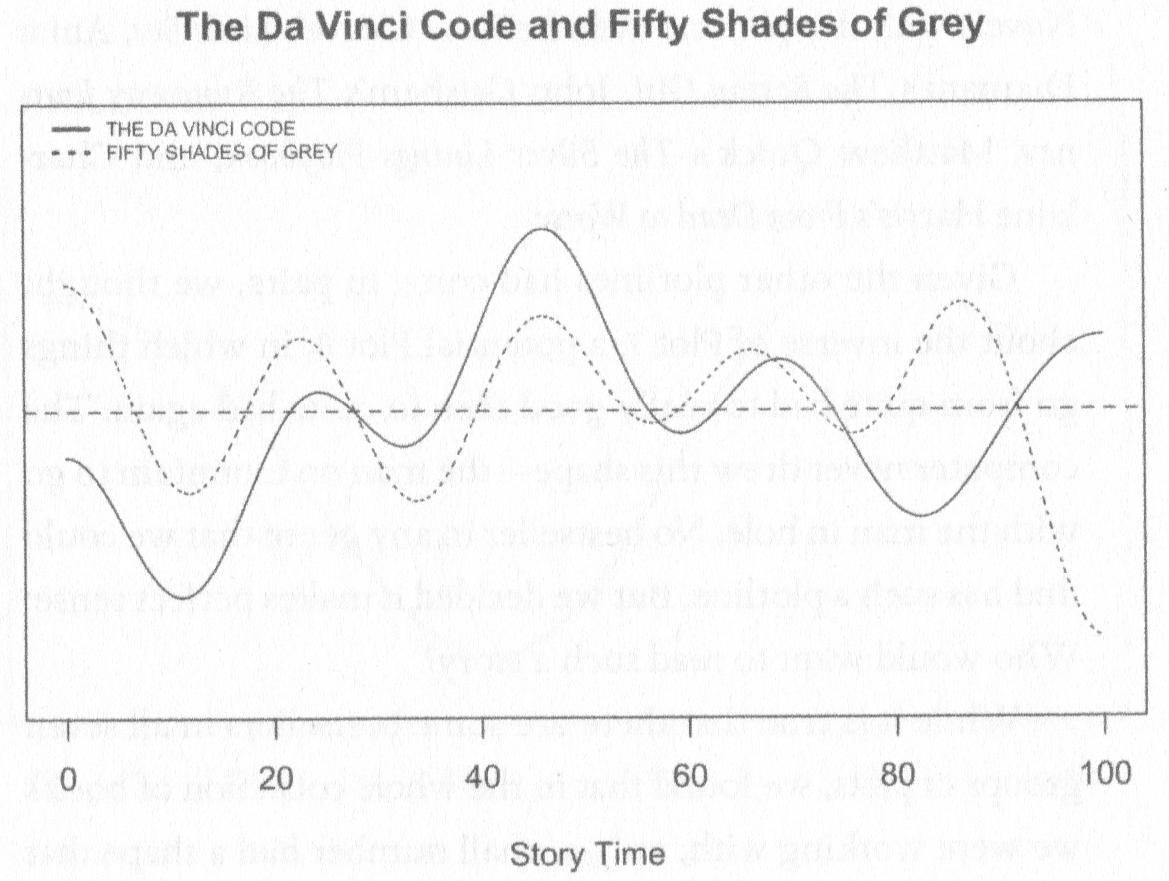
Figura 11.1: Trayectorias de The Da Vinci Code y Fifty Shades of Grey según los análisis de Archer & Jockers (2016: 106)
11.2 Análisis de sentimientos en español
El sistema que te voy a presentar de análisis no es perfecto. Se basa en contar en el texto que se examina cuántas palabras tienen un valor positivo y cuántas lo tienen negativo y con eso se establece una valencia que puede ser positiva o negativa (si es cero es neutra). No tiene en cuenta los modificadores que pueden cambiar totalmente el sentido de una frase. Una oración como La película no estuvo mal sería negativa porque no tiene en cuenta que el no cambia el sentido de mal y le daría un valor positivo. Y lo mismo cabría decir de Eso no estuvo bien. Sería positiva para la máquina porque solo contemplaría bien, positivo, pero el no lo cambia en algo negativo. Esto puede ser un problema cuando se examinan textos muy breves, como tweets o reseñas de sitios como TripAdvisor o Booking o de crítica de cine y novelas, pero para textos más complejos, como son los literarios no supone un problema (Mohammad 2011: 106). Además, se puede mejorar la técnica con el uso de bigramas y coocurrencias.
11.2.1 Preparar el entorno
Hasta donde sabemos, en español no se ha aplicado el análisis de sentimientos a textos literarios por el sencillo hecho de que no hay diccionarios disponibles ni investigadores interesados en el tema. Sin embargo, en 7PartidasDigital hemos adaptado (traducido) al español los que tiene la librería {tidytext} que estás utilizando en este libro y creado otro que designamos uva.
Te voy a mostrar cómo hacer un análisis de sentimientos aplicado a textos literarios, aunque será muy básico. Todo el material que necesitas lo puedes cargar desde el repositorio del proyecto, así no habrá problemas con las letras que lleven diacríticos, un auténtico martirio en Windows.
Como de costumbre, inicia una nueva sesión de RStudio y carga las librerías básicas.
Recuerda que al cargarse la librería {tidyverse} aparecerán varios los mensajes de los que no tienes que preocuparte, son meramente informativos.
El siguiente paso es cargar el diccionario que vas a usar. Se encuentra en un repositorio externo y lo tienes que cargar con
sentimientos <- read_tsv("https://raw.githubusercontent.com/7PartidasDigital/AnaText/master/datos/diccionarios/sentimientos_2.txt",
col_types = "cccn",
locale = default_locale())Esta orden necesita una pequeña explicación. La función read_tsv() permite leer una tabla cuyas columnas están separadas por tabuladores (tab separated values). El primer argumento es el fichero que contiene los datos. Con el argumento col_types le indicas que tipo de datos tiene cada una de las columnas de la tabla. Las tres primeras son caracteres, de ahí las tres c, la última tiene valores numéricos, por lo que le tienes que indicar n. El último argumento, locale = default_locale() es el responsable de que los ordenadores Windows no tengan problemas para leer las letras con diacríticos.
Examina la tabla sentimientos. Escribe en la consola
Aparecerá el comienzo de una gran tabla, de 15446 líneas y cuatro columnas
## # A tibble: 15,446 × 4
## palabra sentimiento lexicon valor
## <chr> <chr> <chr> <dbl>
## 1 ábaco confianza nrc NA
## 2 abad confianza nrc NA
## 3 abanderar negativo nrc NA
## 4 abandonado ira nrc NA
## 5 abandonado miedo nrc NA
## 6 abandonado negativo nrc NA
## 7 abandonado tristeza nrc NA
## 8 abandonar miedo nrc NA
## 9 abandonar negativo nrc NA
## 10 abandonar tristeza nrc NA
## # ℹ 15,436 more rowsSe trata de la versión reducida del diccionario de sentimientos que he desarrollado para usarlo con el paquete {tidytext}. Es una tabla que tiene cuatro columnas: palabra, sentimiento, lexicon y valor. En realidad, hay tres diccionarios diferentes construidos de manera diferente y con diferente número de palabras.
AFINN de Finn Årup Nielsen, bing de Bing Liu y colaboradores y nrc de Saif Mohammad and Peter Turney. Hay un cuarto, syuzhet, de Matthew L. Jockers, que forma parte de la librería para R syuzhet. Volveré sobre este más adelante.
La columna palabra contiene las diferentes palabras de cada uno de los diccionarios (el nombre de cada uno de ellos está recogido en la columna lexicon y puede ser nrc, afinn y bing). La columna valor es siempre NA para nrc y bing, y un valor numérico entre -5 y +5 para afinn. En cambio, afinn tiene siempre un valor NA en la columna sentimiento, mientras que en bing puede ser negativo o positivo y en nrc uno de estos diez valores: positivo, negativo, ira, miedo, tristeza, disgusto, asombro, confianza, alegría, premonición. Algunas palabras pueden tener en nrc varios valores, pero siempre relacionados. Fíjate en el cuadro anterior, abandonar está marcado como miedo, negativo y tristeza.
A continuación has de cargar una pequeña modificación de una de las funciones de {tidytext}. Lo tienes que hacer con source. Lo que hace esta orden es leer un script e interpretarlo como una función diseñada por el usuario. Cuando lo cargues, aparecerá en el la ventana Environment una división que dirá Functions y dentro de ella aparecerá get_sentiments. Esta es la función modificada para burlar la que trae {tidytext} de serie.
get_sentiments.R. Utiliza los que trae de serie la librería {tidytext}. Es decir, ignora los pasos anteriores.
{tidytext} se publicó en julio de 2019 una nueva versión, la 0.2.2 (pero ya va por la 0.2.5), que incorpora algunos cambios y mejoras, entre ellas que los diccionarios de sentimientos y de palabras vacías se hallan en una librería externa, {textdata}, que se instala automáticamente cuando se instala por primera vez {tidytext}.
11.2.2 Cargar los textos
Ya tienes los dos elementos que necesitarás siempre que quieras hacer el análisis de sentimientos de un texto en español. Ahora tan solo tienes que cargar los textos. Vas a usar las diez entregas de la primera serie de los Episodios Nacionales de Benito Pérez Galdós.
En esta ocasión no puedes usar un bucle for ya que te interesa mantener identificado cada uno de los episodios. Así que no hay otra que cargarlos uno a uno:
trafalgar <- read_lines("https://raw.githubusercontent.com/7PartidasDigital/AnaText/master/datos/episodios/01_EN-01-01-Trafalgar.txt",
locale = default_locale())
carlos4 <- read_lines("https://raw.githubusercontent.com/7PartidasDigital/AnaText/master/datos/episodios/02_EN-01-02-La_Corte_de_Carlos_IV.txt",
locale = default_locale())
trafalgar <- read_lines("https://raw.githubusercontent.com/7PartidasDigital/AnaText/master/datos/episodios/01_EN-01-01-Trafalgar.txt",
locale = default_locale())
marzo_mayo <- read_lines("https://raw.githubusercontent.com/7PartidasDigital/AnaText/master/datos/episodios/03_EN-01-03-El_19_de_Marzo_y_el_2_de_Mayo.txt",
locale = default_locale())
bailen <- read_lines("https://raw.githubusercontent.com/7PartidasDigital/AnaText/master/datos/episodios/04_EN-01-04-Bailen.txt",
locale = default_locale())
napoleon <- read_lines("https://raw.githubusercontent.com/7PartidasDigital/AnaText/master/datos/episodios/05_EN-01-05-Napoleon_en_Chamartin.txt",
locale = default_locale())
zaragoza <- read_lines("https://raw.githubusercontent.com/7PartidasDigital/AnaText/master/datos/episodios/06_EN-01-06-Zaragoza.txt",
locale = default_locale())
gerona <- read_lines("https://raw.githubusercontent.com/7PartidasDigital/AnaText/master/datos/episodios/07_EN-01-07-Gerona.txt",
locale = default_locale())
cadiz <- read_lines("https://raw.githubusercontent.com/7PartidasDigital/AnaText/master/datos/episodios/08_EN-01-08-Cadiz.txt",
locale = default_locale())
empecinado <- read_lines("https://raw.githubusercontent.com/7PartidasDigital/AnaText/master/datos/episodios/09_EN-01-09-Juan_Martin_El_Empecinado.txt",
locale = default_locale())
arapiles <- read_lines("https://raw.githubusercontent.com/7PartidasDigital/AnaText/master/datos/episodios/10_EN-01-10-La_Batalla_de_los_Arapiles.txt",
locale = default_locale())Cuando hayas acabado la carga, la ventana Global Environment tiene que tener un aspecto idéntico al de la figura 11.2.
Figura 11.2: Aspecto de la ventana Global Enviroment una vez cargados el diccionario sentimientos, los diez episodios y la función get_sentiments
Los textos que acabas de cargar están ligeramente preparados. Se han unido todos los párrafos y cada elemento de cada uno de los vectores contiene un capítulo. Podrías haber cargando los textos sin modificar, pero habría exigido hacerlo, y eso habría complicado la explicación y quiero que te centres en el análisis de sentimientos.
El siguente paso es crear un vector de caracteres con el título de cada entrega. Llámalo titulos. Créalo en el orden cronológico de publicación, así el análisis será mucho más interesante. Recuerda que las máquinas tienen la tendencia a presentar las palabras en orden alfabético. Fíjate que cargaste los episodios en orden cronológico, pero en Global Environment los tienes en orden alfabético.
titulos <- c("Trafalgar",
"La Corte de Carlos IV",
"El 19 de Marzo y el 2 de Mayo",
"Bailen",
"Napoleon en Chamartin",
"Zaragoza",
"Gerona",
"Cadiz",
"Juan Martin El Empecinado",
"La Batalla de los Arapiles")intro tras cada coma ,. RStudio se ha encargado de sangrarlo, pero puedes ponerlo en una sola línea.
Lo siguiente es crear una lista, llamada libros, con todos los textos en el orden de publicación. Se crea con la función list() y cada uno de los elementos de la lista es cada uno de los vectores de caracteres que tienen el texto de cada Episodio Nacional.
libros <- list(trafalgar,
carlos4,
marzo_mayo,
bailen,
napoleon,
zaragoza,
gerona,
cadiz,
empecinado,
arapiles)Ahora has de crear una gran tabla, que llamarás serie, con todos los textos, con los títulos, los números de capítulo de cada una de ellos y con los textos divididos en palabras-token, es decir, todas convertidas en letras minúsculas y sin ningún signo de puntuación. Como es una labor que se ha de llevar a cabo con un bucle for, lo primero es inicializar la tabla en la que se almacenarán todos los textos, a la que llamarás serie.
y a continuación el bucle con el que se creará una enorme tabla con cada una de las entregas de los diez primeros Episodios nacionales.
11.2.3 Explicación del código
Aunque ya es un viejo conocido, te explico qué hace en cada línea de cada iteración. El controlador de vueltas es la longitud de titulos. Podrías usar length(titulos), y también seq_along(), lo que equivale a decir: sigue dando vueltas mientras que haya elementos en titulos. En la primera línea, guardará en limpio el número de los capítulos –capitulo– y el texto de cada capitulo que haya en libros[[i]], donde es i es uno de los diez posibles, de manera que, por ejemplo, libros[[1]] es Trafalgar, el cual tiene 17 capítulos. El contenido de limpio en esta primera línea del bucle es (no lo podrás ver en la consola)
## # A tibble: 17 x 2
## capitulo texto
## <int> <chr>
## 1 1 "Se me permitirá que antes de referir el gran suceso…
## 2 2 "En uno de los primeros días de Octubre de aquel año…
## 3 3 "D. Alonso Gutiérrez de Cisniega pertenecía a una an…
## 4 4 "«Señor Marcial –dijo ésta con redoblado furor: –si …
## 5 5 "Para oponerse a la insensata determinación de su ma…
## 6 6 "Recuerdo muy bien que al día siguiente de los pesco…
## 7 7 "A la mañana siguiente se me preparaba una gran sorp…
## 8 8 "No puedo describir el entusiasmo que despertó en mi…
## 9 9 "Octubre era el mes, y 18 el día. De esta fecha no m…
## 10 10 "Al amanecer del día 20, el viento soplaba con mucha…
## # ... with 7 more rowsLa siguiente línea lo que hace es dividir el texto del libro en palabras-token. Con lo que el contenido de limpio ahora es en una tabla con el número de capítulo y cada una de las palabras del libro[[i]].
## # A tibble: 51,303 x 2
## capitulo palabra
## <int> <chr>
## 1 1 se
## 2 1 me
## 3 1 permitirá
## 4 1 que
## 5 1 antes
## 6 1 de
## 7 1 referir
## 8 1 el
## 9 1 gran
## 10 1 suceso
## # ... with 51,293 more rowsEn la siguiente, la función mutate() crea una nueva columna llamada libro, que contendrá el título del episodio y lo extraerá del vector titulos.
## # A tibble: 51,303 x 3
## capitulo palabra libro
## <int> <chr> <chr>
## 1 1 se Trafalgar
## 2 1 me Trafalgar
## 3 1 permitirá Trafalgar
## 4 1 que Trafalgar
## 5 1 antes Trafalgar
## 6 1 de Trafalgar
## 7 1 referir Trafalgar
## 8 1 el Trafalgar
## 9 1 gran Trafalgar
## 10 1 suceso Trafalgar
## # ... with 51,293 more rowsDespués la función select() se encargará de crear la tabla intermedia definitiva, que tendrá las tres columnas del paso anterior, pero reorganizadas: libro, que guardará el título; capitulo, que contendrá el número de cada capítulo; y en palabra almacenará cada una de las palabras-token que constituyen cada capítulo.
## # A tibble: 51,303 x 3
## libro capitulo palabra
## <chr> <int> <chr>
## 1 Trafalgar 1 se
## 2 Trafalgar 1 me
## 3 Trafalgar 1 permitirá
## 4 Trafalgar 1 que
## 5 Trafalgar 1 antes
## 6 Trafalgar 1 de
## 7 Trafalgar 1 referir
## 8 Trafalgar 1 el
## 9 Trafalgar 1 gran
## 10 Trafalgar 1 suceso
## # ... with 51,293 more rowsComo en este caso tienes diez entregas, la última línea del bucle se encarga de añadir a la tabla serie, que creaste antes de comenzarlo, cada una de las diez tablas intermedias que se han ido generando secuencialmente en limpio. Al final, tienes las diez novelas divididas en palabras-token con indicación del titulo y del capitulo en el que aparecen. Es más, podrías leer las diez novelas leyendo la columna palabra, pues aún mantiene el orden del texto original, solo ha perdido los signos de puntuación y las mayúsculas. Es una tabla bastante grande, tiene 685888 palabras-token. Si te has leído los diez primeros Episodios ya sabes cuántas palabras tienen en total.
## # A tibble: 685,888 × 3
## libro capitulo palabra
## <chr> <int> <chr>
## 1 Trafalgar 1 se
## 2 Trafalgar 1 me
## 3 Trafalgar 1 permitirá
## 4 Trafalgar 1 que
## 5 Trafalgar 1 antes
## 6 Trafalgar 1 de
## 7 Trafalgar 1 referir
## 8 Trafalgar 1 el
## 9 Trafalgar 1 gran
## 10 Trafalgar 1 suceso
## # ℹ 685,878 more rows11.2.4 Convertir en factores
El último paso previo es convertir la columna de los títulos –libro– en un factor (<fct>). La tabla, como acabas de ver, tiene 685888 líneas, pero en la columna libro solo tienes diez posibles valores: el título de cada entrega. Manejar diez valores es más sencillo que casi 700 000 que se repiten tan solo diez veces. Los factores es la manera de hacerlo, por lo que vas a reducir esos 685888 valores a tan solo diez. Hay varias maneras de hacerlo. La más sencilla es indicándole a R qué columna de la tabla serie quieres convertir en factores. Ya lo has visto hace tiempo, usas el signo $ para referirte a un columna determinada de una tabla, de modo que serie$libro solo tendrá en cuenta la columna libro de la tabla serie. La forma de convertir la columna en un factor es con la función factor() que requiere saber qué es lo que debe convertir en factor y qué niveles debe tener –levels– y cómo ordenarlos –rev()–, pues los factores se ordenan por defecto alfabéticamente.
## [1] "Bailen" "Cadiz"
## [3] "El 19 de Marzo y el 2 de Mayo" "Gerona"
## [5] "Juan Martin El Empecinado" "La Batalla de los Arapiles"
## [7] "La Corte de Carlos IV" "Napoleon en Chamartin"
## [9] "Trafalgar" "Zaragoza"y te interesa mantener el orden de publicación, aunque para complicar la cosa un poco será inverso, del más moderno al más antiguo. La orden es
con lo que los títulos de la serie irán desde el más moderno –La batalla de Arapiles– al más antiguo –Trafalgar–.
## [1] "La Batalla de los Arapiles" "Juan Martin El Empecinado"
## [3] "Cadiz" "Gerona" "Zaragoza" "Napoleon en Chamartin"
## [7] "Bailen" "El 19 de Marzo y el 2 de Mayo"
## [9] "La Corte de Carlos IV" "Trafalgar"11.3 Primeros análisis
Ya tienes el material preparado. Una enorme tabla en la que están todas las palabras de las diez primeras novelas de los episodios galdosianos. Es más, las sigues teniendo en el orden de lectura. Puedes comprobarlo con serie$palabra[1:50]. Si escribes esto en la consola
se imprimirán en la pantalla las 50 [1:50] primeras palabras de la columna palabra del objeto serie.
## [1] "se" "me" "permitirá" "que" "antes" "de" "referir"
## [8] "el" "gran" "suceso" "de" "que" "fui" "testigo"
## [15] "diga" "algunas" "palabras" "sobre" "mi" "infancia" "explicando"
## [22] "por" "qué" "extraña" "manera" "me" "llevaron" "los"
## [29] "azares" "de" "la" "vida" "a" "presenciar" "la"
## [36] "terrible" "catástrofe" "de" "nuestra" "marina" "al" "hablar"
## [43] "de" "mi" "nacimiento" "no" "imitaré" "a" "la"
## [50] "mayor"Pero esto no dice nada. No te has tomado todo este trabajo para leer de mala manera el texto. Sin embargo, antes de continuar es necesario que sepas el motivo por el cuál no se ha reorganizado el texto: a lo largo de estos análisis te interesará el tiempo narrativo, es decir, ver cómo progresa el relato y cómo cambia la carga emocional del texto.
Lo primero que vas a ver es cuántas palabras positivas y cuántas negativas hay en toda esta primera serie de los Episodios nacionales. Vas a utilizar el diccionario nrc. La ventaja de este es que, además de palabras positivas y negativas, indicará las palabras que transmiten alguna de las ocho emociones básicas. El código es
serie %>%
right_join(get_sentiments("nrc")) %>%
filter(!is.na(sentimiento)) %>%
count(sentimiento, sort = TRUE)Tan pronto como se ejecute la orden aparecerán dos avisos y el resultado.
## Warning in data(sentimientos, package = NULL, envir = environment()): data set 'sentimientos' not found## Joining with `by = join_by(palabra)`## Warning in right_join(., get_sentiments("nrc")): Detected an unexpected many-to-many relationship between `x` and `y`.
## ℹ Row 17 of `x` matches multiple rows in `y`.
## ℹ Row 5842 of `y` matches multiple rows in `x`.
## ℹ If a many-to-many relationship is expected, set `relationship = "many-to-many"` to silence this
## warning.## # A tibble: 10 × 2
## sentimiento n
## <chr> <int>
## 1 positivo 34107
## 2 negativo 26809
## 3 confianza 20648
## 4 miedo 17546
## 5 premonición 15539
## 6 tristeza 14857
## 7 ira 12974
## 8 alegría 12307
## 9 disgusto 10395
## 10 asombro 7857La primera caja tras la del código imprime un Warning. No hay ningún problema. Este aviso te saldrá siempre que uses este sistema en español. Se debe a que ha buscado en la librería de {tidytext} los datos de sentimientos, y allí no los ha podido localizar porque no están ya que el paquete original no contempla la posibilidad de que se pueda hacer análisis de sentimiento en ninguna otra lengua que no sea el inglés. Sin embargo, los cargaste desde el fichero al principio en sentimientos y los tienes en Global Enviroment, por lo que el sistema seguirá funcionado. Tan solo te avisa de algo no ha ido como esperaba que fuera. En adelante no te mostraré este aviso, pero ten por seguro que a ti te saldrá.
La segunda caja informa de que la función rigth_join() se ha ejecutado con la variable palabra porque es la única variable –columna– que tienen en común serie y sentimiento. Siempre que uses las funciones _join aparecerá este aviso. En adelante tampoco te mostraré este aviso, pero a ti te aparecerá en la consola.
La tercera caja es el resultado final.
Lo que ha hecho el fragmento de código ha sido tomar el contenido del diccionario nrc y ver si la palabra se encuentra entre las palabras de serie. Si serie no tiene esa palabra, la añade, provisionalmente, a la tabla, e indica que no la hay con NA, tanto en libro como en capitulo, e incorpora a la derecha una nueva columna (rigth_join) con el sentimiento que esa palabra tenga marcado en nrc. El contenido, tras ejecutar la segunda línea –right_join(get_sentiments("nrc"))–, de la tabla provisional que no puedes ver porque es interna.
## # A tibble: 174,367 x 4
## libro capitulo palabra sentimiento
## 1 NA NA ábaco confianza
## 2 Trafalgar 11 abad confianza
## 3 Napoleon en Chamartin 9 abad confianza
## 4 Napoleon en Chamartin 22 abad confianza
## 5 Napoleon en Chamartin 22 abad confianza
## 6 Napoleon en Chamartin 23 abad confianza
## 7 NA NA abanderar negativo
## 8 Trafalgar 1 abandonado ira
## 9 Trafalgar 12 abandonado ira
## 10 Trafalgar 15 abandonado ira
## … with 174,357 more rowsLa línea de filter() lo que le dice es que solo tome aquellas filas cuyo contenido en la columna sentimiento sea diferente de NA –!is.na–. La última línea, count() cuenta cuántas veces aparece cada uno de los sentimientos en la columna sentimiento y las ordena de mayor a menor de acuerdo con el número de ocurrencias –sort = TRUE–. El resultado con el diccionario nrc lo has visto un poco antes.
Si cambias el argumento de get_sentiments() de nrc a bing
serie %>%
right_join(get_sentiments("bing")) %>%
filter(!is.na(sentimiento)) %>%
count(sentimiento, sort = TRUE)el resultado será una tabla de 2 por 2 que te informará, tan solo, de cuántas palabras positivas y cuántas negativas hay en todo el corpus. (Te habrá salido el Warning y el aviso de Joining).
## # A tibble: 2 × 2
## sentimiento n
## <chr> <int>
## 1 negativo 17122
## 2 positivo 10475Si lo comparas con los resultados de nrc, bing es muy pobre. nrc fue capaz de detectar 34 107 palabras positivas y 26 809 negativas. Esto se debe a que la versión del diccionario bing aquí implementada es mucho más pobre.
11.3.1 Visualización de los resultados
En varias ocasiones he mencionado que no se ha reorganizado el texto de los diez episodios porque un aspecto fundamental de este análisis en textos literarios es ver como evaluciona la valoración del sentimiento a lo largo de la trayectoria narrativa de cada uno de ellos. La mejor manera de verlo es por medio de una gráfica que genera este fragmento de código (la explicación está un poco más adelante).
serie %>%
group_by(libro) %>%
mutate(recuento_palabras = 1:n(),
indice = recuento_palabras %/% 500 + 1) %>%
inner_join(get_sentiments("nrc")) %>%
count(libro, indice = indice , sentimiento) %>%
ungroup() %>%
spread(sentimiento, n, fill = 0) %>%
mutate(sentimiento = positivo - negativo, libro = factor(libro, levels = titulos)) %>%
ggplot(aes(indice, sentimiento, fill = libro)) +
geom_bar(stat = "identity", show.legend = FALSE) +
facet_wrap(~ libro, ncol = 2, scales = "free_x")Al ejecutarse se imprimirá en la ventana Plots el gráfico de la figura 11.3.
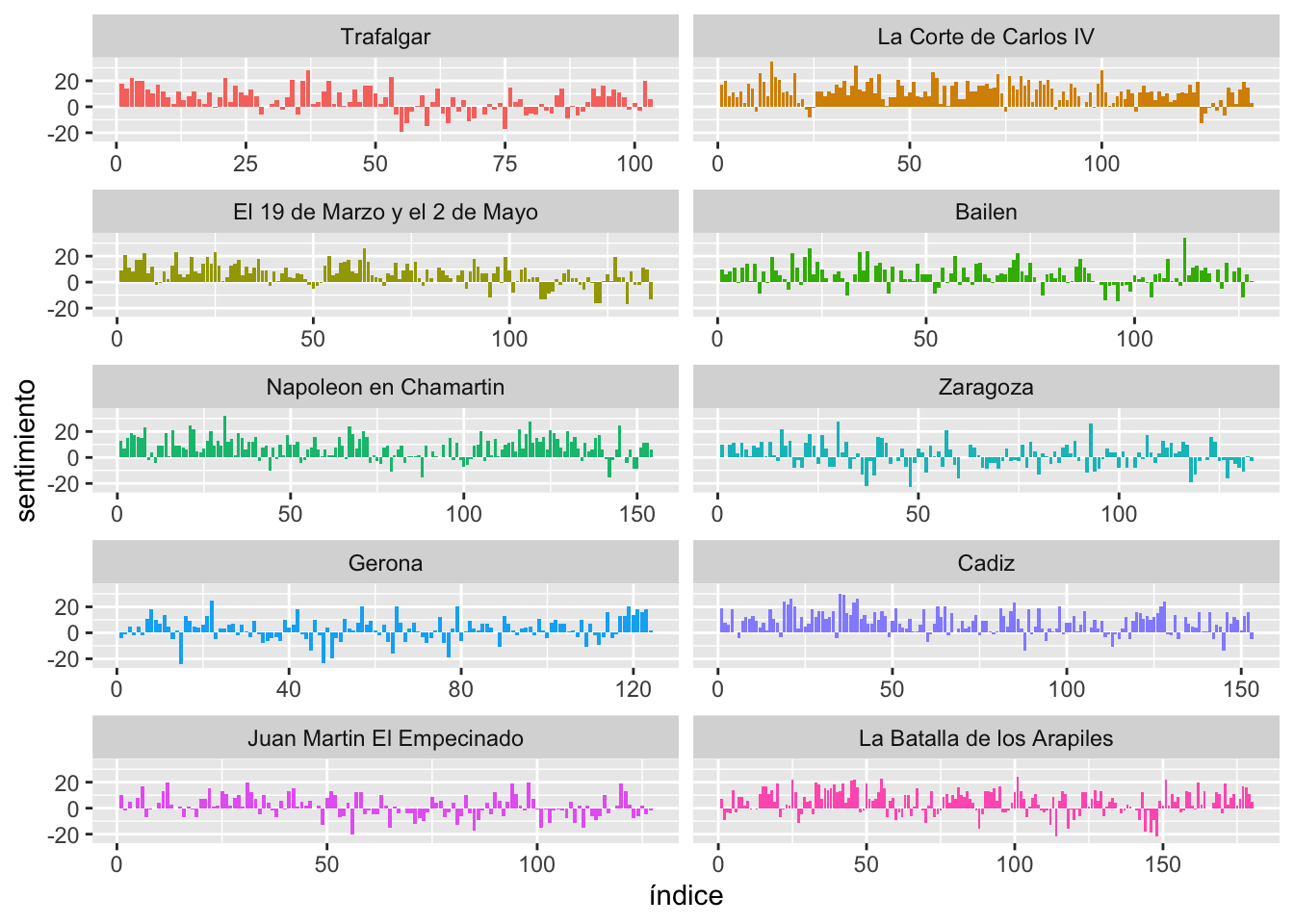
Figura 11.3: Trayectoria y valencia emocional de la primera serie de los Episodios Nacionales
En el eje vertical tienes la valencia emocional de los diez primeros episodios. Como es de suponer, los valores positivos corresponden a sentimientos positivos y los negativos a los negativos. El valor del eje horizontal indica el número de la página, establecida en secuencias consecutivas de 500 palabras, por lo que puedes ver cómo varía la carga emocional según progresa el texto.
11.3.2 Explicación del código
Ahora vamos a ver qué es lo que sucede en cada paso hasta llegar al gráfico de la figura 11.3. Lo primero es agrupar los datos, que están recogidos en serie, de cada uno de los Episodios, porque quieres establecer la carga o valencia emotiva de cada uno de los libros, no de la serie como un todo, por lo tanto, has de usar group_by(libro). Este primer paso crea una tabla intermedia invisible, como la que hay a continuación, en la que se informa de que la agrupación de la variable libro es de 10.
## # A tibble: 685,889 x 3
## # Groups: libro [10]
## libro capitulo palabra
## <fct> <int> <chr>
## 1 Trafalgar 1 se
## 2 Trafalgar 1 me
## 3 Trafalgar 1 permitirá
## 4 Trafalgar 1 que
## 5 Trafalgar 1 antes
## 6 Trafalgar 1 de
## 7 Trafalgar 1 referir
## 8 Trafalgar 1 el
## 9 Trafalgar 1 gran
## 10 Trafalgar 1 suceso
## # … with 685,879 more rowsEn el siguiente creas, con mutate(), dos nuevas columnas: recuento_palabras e indice. La variable recuento_palabras lo único que hace es numerar una tras otra todas y cada una de las palabras de cada libro, y lo hace de 1 al valor de n() en cada libro. En la segunda parte de esta línea crea la columna indice en la que lo que hace es dividir el texto en segmentos de 500 palabras. Ya has usado otras técnicas en otros capítulos anteriores. Esta es una más. Así, de la palabra 1 a la 500, el índice es 1, de la 501 a la 1000, el índice es 2 y así sucesivamente hasta llegar al final. La forma de crear este índice es por medio de una división entera, cuyo operador es %/%.
La última entrega de la serie –La batalla de Arapiles–, por ejemplo, tiene 89 629 palabras-token, si las divides en grupos de 500, el resultado sería 179.258 fragmentos, pero como no quieres perder ese .258 restante de palabras (son 129 palabras), le dices que quieres que la división sea exacta, pero como sospechas de que habrá un resto, le indicas que añada 1 al índice para marcar las palabras de ese resto. Esto ya lo has hecho antes, pero de otra forma, con la función ceiling(). Prueba cualquiera de las dos líneas siguientes en la consola.
Cualquiera de las dos ofrecerá el resultado
## [1] 180El resultado intermedio de la función mutate(), que no verás en la consola, es
## # A tibble: 685,889 x 5
## # Groups: libro [10]
## libro capitulo palabra recuento_palabras indice
## <fct> <int> <chr> <int> <dbl>
## 1 Trafalgar 1 se 1 1
## 2 Trafalgar 1 me 2 1
## 3 Trafalgar 1 permitirá 3 1
## 4 Trafalgar 1 que 4 1
## 5 Trafalgar 1 antes 5 1
## 6 Trafalgar 1 de 6 1
## 7 Trafalgar 1 referir 7 1
## 8 Trafalgar 1 el 8 1
## 9 Trafalgar 1 gran 9 1
## 10 Trafalgar 1 suceso 10 1
## # … with 685,879 more rowsmientras que las seis últimas líneas de la enorme tabla serían
## 685884 La Batalla de los Arapiles 39 sin 89624 180
## 685885 La Batalla de los Arapiles 39 nada 89625 180
## 685886 La Batalla de los Arapiles 39 y 89626 180
## 685887 La Batalla de los Arapiles 39 lo 89627 180
## 685888 La Batalla de los Arapiles 39 tuvo 89628 180
## 685889 La Batalla de los Arapiles 39 todo 89629 180En los dos recuadros anteriores tienes, por un lado, las diez primeras palabras de Trafalgar, que se encuentran en el primer capítulo y forman el primer grupo de 500 palabras de esa entrega (podríamos decir que en la primera página). En el segundo recuadro tienes las seis últimas palabras de La batalla de Arapiles, que son las palabras 685 884 a 685 889, que se encuentran en el capítulo 39 y forman el grupo (es decir, la página) 180 de esa novela.
En la siguiente línea lee el diccionario de sentimientos nrc y añade la columna sentimiento con los distintos valores que puede tener. De nuevo es un estadio interno que no es visible, pero te muestro el aspecto que tiene para que veas cómo procede el sistema.
## # A tibble: 170,065 x 6
## # Groups: libro [10]
## libro capitulo palabra recuento_palabras indice sentimiento
## <fct> <int> <chr> <int> <dbl> <chr>
## 1 Trafalgar 1 testigo 14 1 confianza
## 2 Trafalgar 1 palabras 17 1 ira
## 3 Trafalgar 1 palabras 17 1 negativo
## 4 Trafalgar 1 infancia 20 1 alegría
## 5 Trafalgar 1 infancia 20 1 positivo
## 6 Trafalgar 1 terrible 36 1 disgusto
## 7 Trafalgar 1 terrible 36 1 ira
## 8 Trafalgar 1 terrible 36 1 miedo
## 9 Trafalgar 1 terrible 36 1 negativo
## 10 Trafalgar 1 terrible 36 1 premonición
## # … with 170,055 more rowsTodas las palabras son del capítulo primero, de la primera página y tan solo las palabras 14, 17, 20 y 36 ha obtenido una valencia (valor de la columna sentimiento). El siguiente paso es contar cuántas palabras de cada emoción hay en cada página (el número de indice). La tabla interna es
## # A tibble: 13,738 x 4
## # Groups: libro [10]
## libro indice sentimiento n
## <fct> <dbl> <chr> <int>
## 1 La Batalla de los Arapiles 1 alegría 11
## 2 La Batalla de los Arapiles 1 asombro 9
## 3 La Batalla de los Arapiles 1 confianza 13
## 4 La Batalla de los Arapiles 1 disgusto 11
## 5 La Batalla de los Arapiles 1 ira 7
## 6 La Batalla de los Arapiles 1 miedo 16
## 7 La Batalla de los Arapiles 1 negativo 17
## 8 La Batalla de los Arapiles 1 positivo 24
## 9 La Batalla de los Arapiles 1 premonición 12
## 10 La Batalla de los Arapiles 1 tristeza 15
## # … with 13,728 more rowsPuedes ver que en la página 1 (indice) de La batallas de Arapiles hay 24 palabras positivas y 17 negativas y, puedes ver, además, cuántas palabras hay que denotan alegría, confianza, disgusto, ira, miedo, premonición y tristeza. Puesto que ya has realizado los cálculos para cada libro, tienes que deshacerte del grupo con ungroup().
La siguiente línea –spread(sentimiento, n, fill = 0)– lo que hace es crear una tabla en la que se resumen y recopilan los valores –n– de cada uno de los sentimientos –sentimiento– para cada página –indice– de cada una de las entregas de la serie –libro–. Puesto que puede haber sitios en los que no haya palabras para un sentimiento determinado y evitar que R introduzca un NA, que es el valor que asigna por defecto cuando faltan valores, usas el argumento fill = 0. De esta manera te aseguras de que después podrás hacer las operaciones matemáticas necesarias. El aspecto interno de esta tabla, que de nuevo no es visible, es el que puedes ver en la figura 11.4.
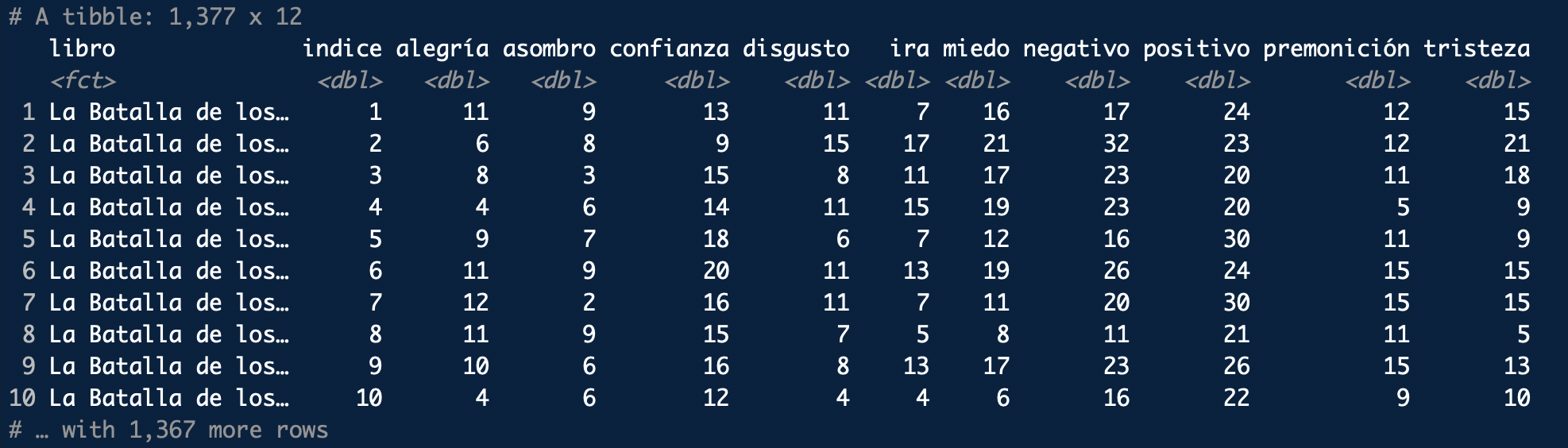
Figura 11.4: Aspecto interno de la tabla provisional
Ahora vas a realizar unos cálculos con los que establecerás la valencia emocional de cada página. Lo harás restando a las palabras positivas –positivo– las negativas –negativo– y las vas a guardar en la columna sentimiento. Además, vas a reorganizar los títulos –libro– por orden de publicación –levels = titulos–. El aspecto de la tabla interna final, que pasará a ggplot() para dibujar la gráfica, es la que puedes ver en la figura 11.5.
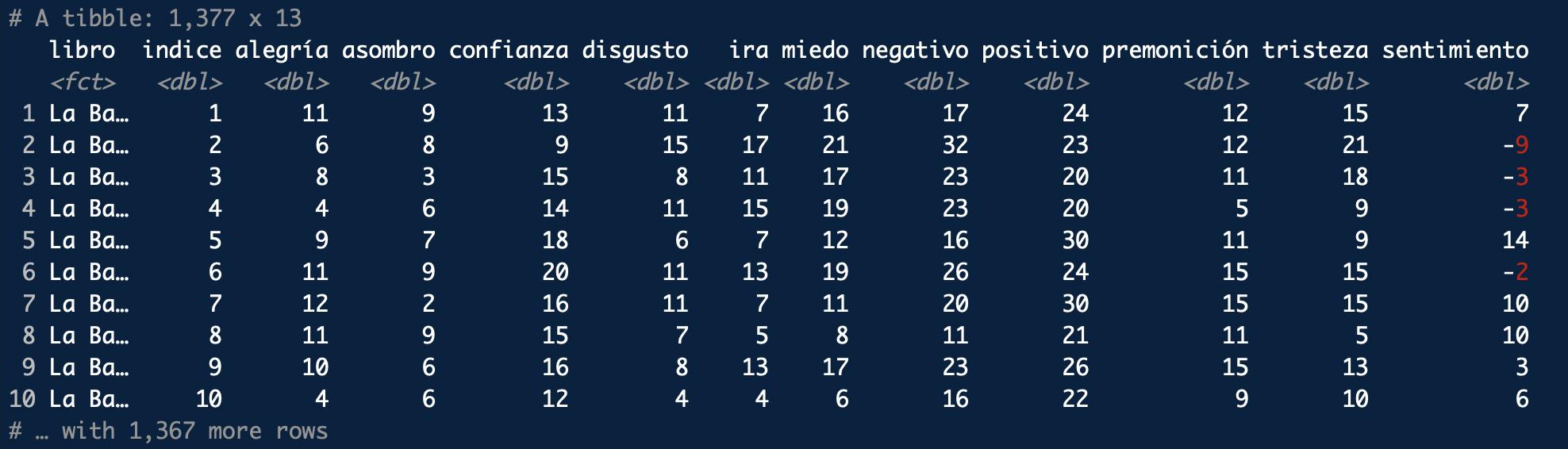
Figura 11.5: Aspecto interno de la tabla final que usará ggplot()
Ya tienes los datos preparados para dibujar la gráfica. Puesto que lo que ofrece la tabla anterior son las diez primeras páginas de La batalla de Arapiles, entresaco el gráfico que acabará dibujando para este episodio (figura 11.6). Fíjate que las páginas 2, 3, 4 y 6 tienen una valencia negativa, lo que se refleja en la gráfica con barras descendentes, mientras que las paginas 1, 5, 7, 8, 9 y 10 son todas positivas, por lo que las barras son ascendentes.
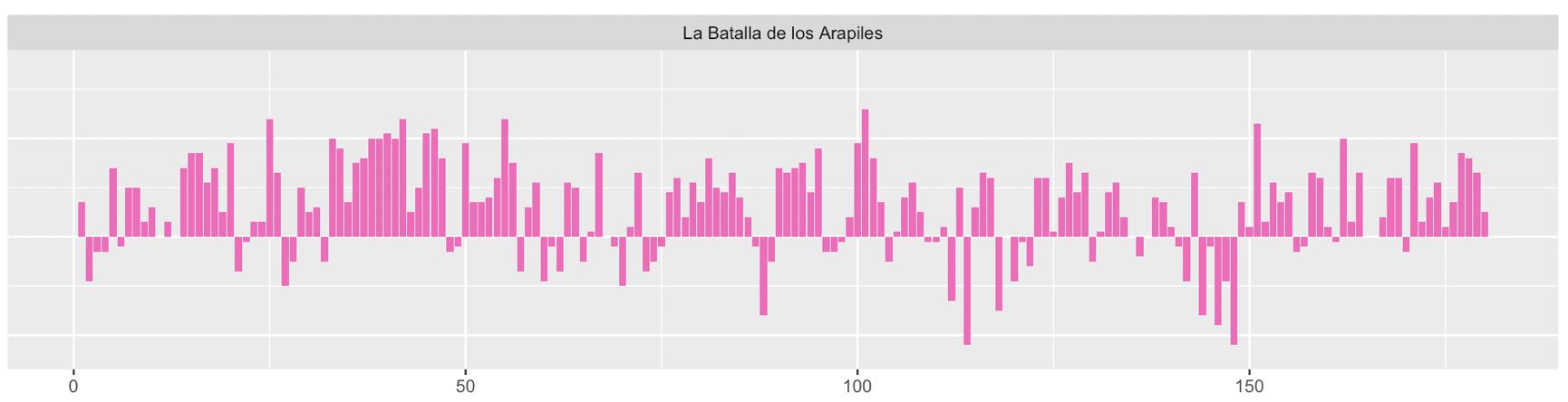
Figura 11.6: Evolución del sentimiento en La batalla de Arapiles
El dibujo la gráfica para cada uno de los diez episodios se encargaron las tres últimas líneas de esta larga orden
serie %>%
. . . . . %>%
ggplot(aes(indice, sentimiento, fill = libro)) +
geom_bar(stat = "identity", show.legend = FALSE) +
facet_wrap(~ libro, ncol = 2, scales = "free_x")La primera línea de la orden de ggplot() selecciona los valores que va a utilizar para dibujar la gráfica: indice, que lo tendrás en el eje horizontal, y que corresponde a cada una de las páginas, con lo que puedes ver el tiempo narrativo; y sentimiento que es el valor que tendrás en el eje vertical. El tercer argumento, fill = libro, coloreará las barras de acuerdo con el valor de libro, es decir, establecerá diez colores. Si no lo haces así, te ofrecerá una gráfica en blanco y negro (figura 11.7).
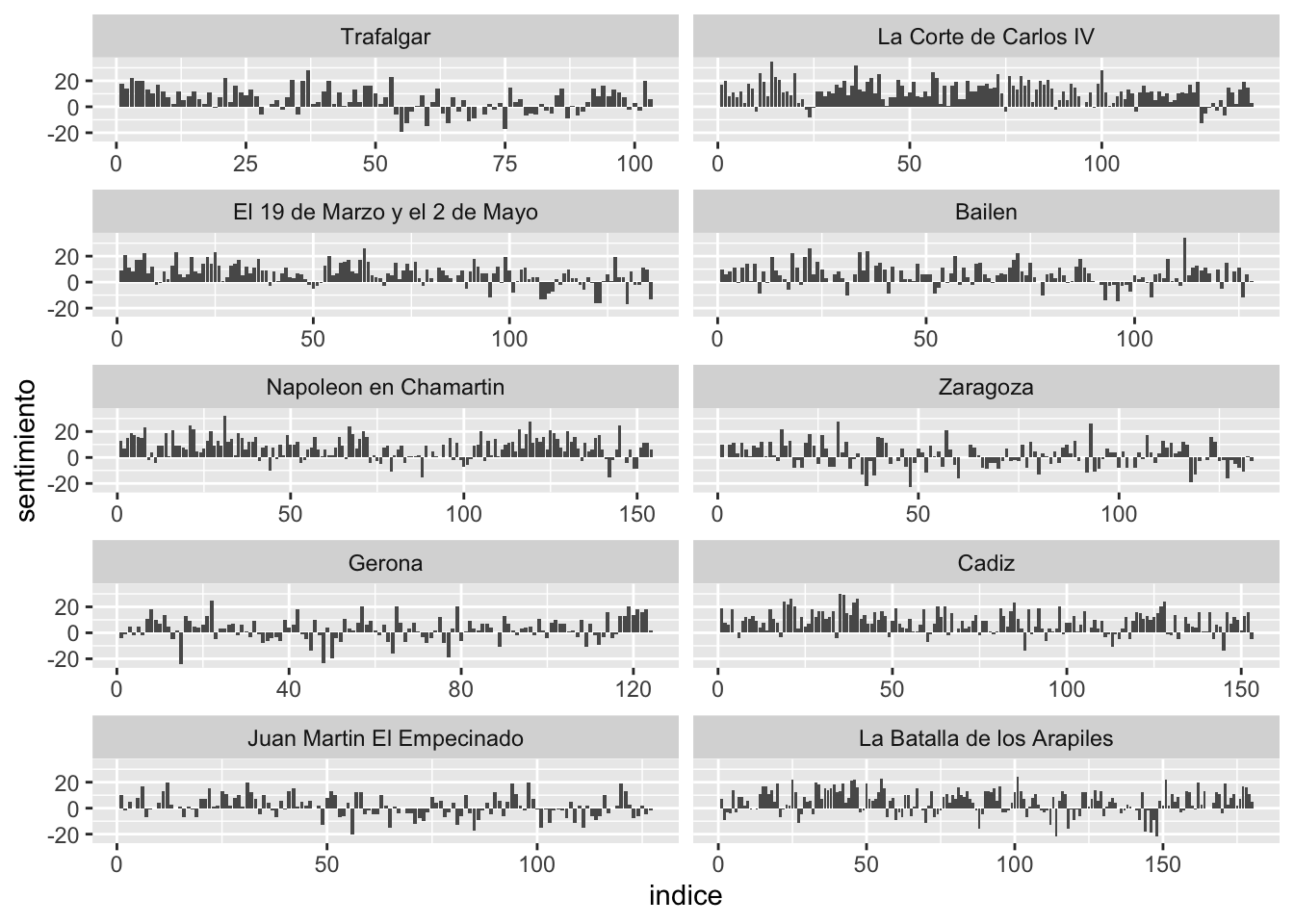
Figura 11.7: Gráfica de la trayectoria y valencia emocional sin el argumento fill = libro
La función geom_bar() ya es una vieja conocida, por lo que no creo que tenga que explicarte casi nada. El argumento stat = "identity" establece que la altura de las barras equivalga al valor de sentimiento; mientras que show.legend = FALSE evita que se imprima en el margen derecho una leyenda explicativa como la que puedes ver en la imagen de la figura 11.8. Es información redundante porque la ofreces en la banda gris que hay encima de cada gráfica.
Figura 11.8: Gráfica de la trayectoria y valencia emocional con el valor por defecto del argumento show.legend
La última línea es la que se encarga de montar en una sola gráfica los diez gráficos y así podrás comparar los resultados con mayor facilidad. El último argumento scales = "free_x" es para que se estrechen aquellas gráficas cuyos valores del eje horizontal vayan más allá del que ofrezca el menor número de valores. En este caso, Trafalgar tiene menos páginas que La batalla de Arapiles, que tiene más de 175 (en realidad 180). Por eso, cuando leas gráficas, fíjate con mucho detalle en los valores que haya impresos en ambos ejes. Si no lo haces puedes obtener una idea equivocada de los resultados.
11.3.3 Unos resultados más
Te estarás preguntando, pero cuáles son las palabras que más contribuyen al sentimiento de la serie. Lo vas a averiguar con el diccionario bing, aunque es un poco más pobre. Todo se reduce a establecer qué palabras son las que se consideran positivas y cuáles negativas. Ya lo has hecho antes. Así que reutiliza un poco de código:
recuenta_palabras_bing <- serie %>%
inner_join(get_sentiments("bing")) %>%
count(palabra, sentimiento, sort = TRUE)Esta orden creará una tabla llamada recuenta_palabras_bing con tres columnas: palabra, sentimiento y n. En la primera tendrás las palabras, en la segunda si la considera positiva o negativa y en la última el número de veces que aparece cada una de ellas. Puedes ver el resultado, tan solo el comienzo, si escribes en la consola
que responderá con la parte inicial de la tabla
## # A tibble: 1,596 × 3
## palabra sentimiento n
## <chr> <chr> <int>
## 1 mal negativo 402
## 2 duda negativo 329
## 3 preciso positivo 288
## 4 pobre negativo 267
## 5 puesto negativo 252
## 6 muerte negativo 242
## 7 ay negativo 237
## 8 enemigo negativo 213
## 9 miedo negativo 211
## 10 ruido negativo 188
## # ℹ 1,586 more rowsApenas puedes apreciar los resultados, puesto que presenta, a causa de la frecuencia de aparición, las cuatro primeras palabras positivas y las seis negativas. Ya sabes cómo puedes ofrecerlo de manera gráfica como puedes ver en la figura 11.9.
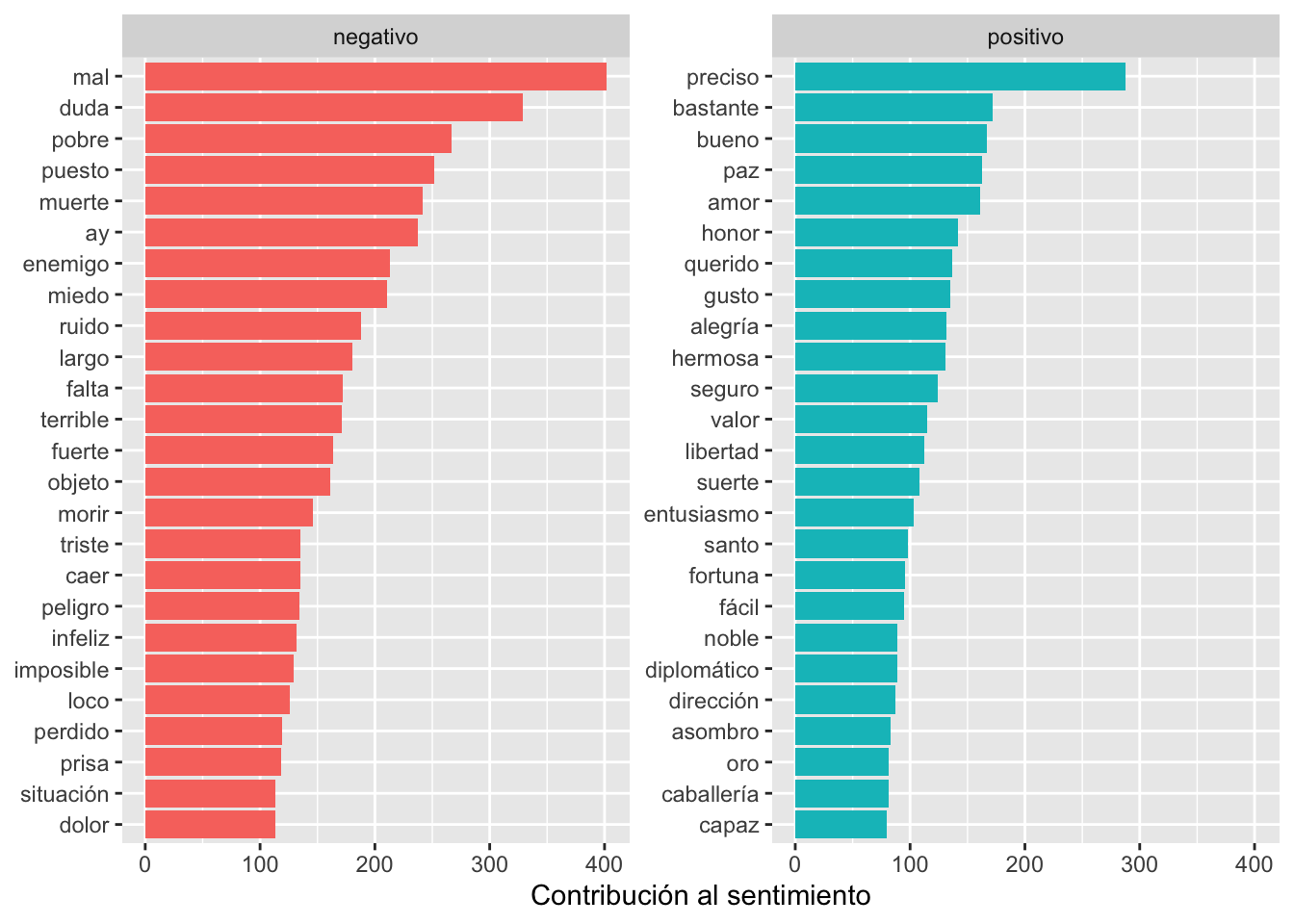
Figura 11.9: Gráfica de la de las 25 palabras positivas y negativas más frecuentes
que se consiguen con unas pocas líneas de código.
recuenta_palabras_bing %>%
group_by(sentimiento) %>%
top_n(25) %>%
ggplot(aes(reorder(palabra, n), n, fill = sentimiento)) +
geom_bar(stat = "identity", show.legend = FALSE) +
facet_wrap(~sentimiento, scales = "free_y") +
labs(y = "Contribución al sentimiento", x = NULL) +
coord_flip()Creo que a estas alturas no necesitas que te explique qué sucede en cada línea.
11.4 La librería {syuzhet}
Las gráficas que respresentan las evolución sentimental de cada uno de los Episodios Nacionales no permite ver cuál es la línea (curva) de la trayectoria de la historia de cada una ella. La manera de verlo es con una gráfica como la de la gráfica de la figura 1. He analizado con el sistema que te mostraré más adelante una de las dos novelas que Archer & Jockers (2016) procesaron para trazar esa gráfica. Tienes ambas a continuación, la publicada por Archer & Jockers (2016) (figura 11.10) y la que yo he obtenido (figura 11.11). Podrás ver que las curvas son semejantes.
Figura 11.10: Trayectorias de The Da Vinci Code y Fifty Shades of Grey según los análisis de Archer & Jockers (2016: 106)
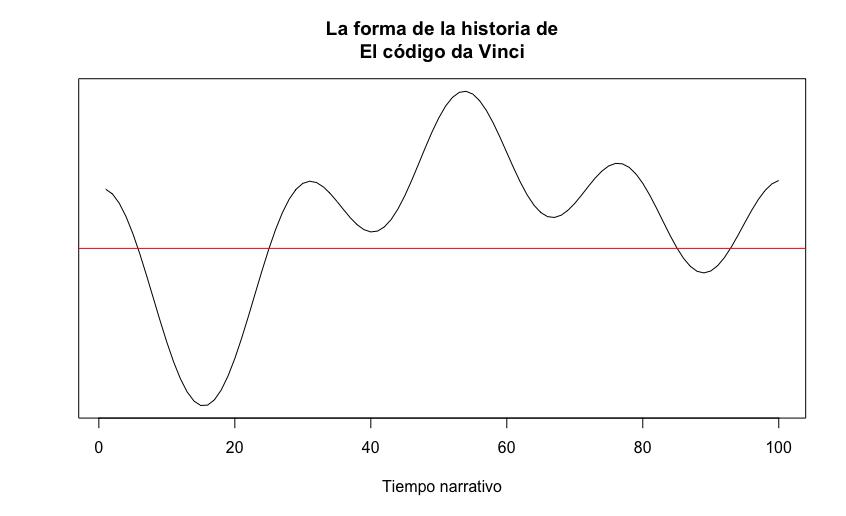
Figura 11.11: Trayectoria de El código da Vinci en español
Evidentemente no pueden ser totalmente iguales las líneas de ambas gráficas por el sencillo hecho de que Archer y Jockers utilizan un diccionario de valencias totalmente diferente al utilizado por mí en este análisis. Lo importante es la similitud de trazos.
11.4.1 Los cuatro jinetes del Apocalipsis
En lo que resta de este capítulo te voy a mostrar cómo hacerlo con una novela de Vicente Blasco Ibáñez: Los cuatro jinetes del Apocalipsis.
Cierra y reinicia RStudio, es para asegurarte de que no hay nada que pueda provocar un error de ejecución, e instala la librería {syuzhet} con
{syuzhet}.
Cargas las tres liberías que vas a usar.
##
## Attaching package: 'syuzhet'## The following object is masked from 'package:scales':
##
## rescaleEl siguiente paso es cargar el diccionario y la función get_sentiments.R:
sentimientos <- read_tsv("https://raw.githubusercontent.com/7PartidasDigital/AnaText/master/datos/diccionarios/sentimientos_2.txt",
col_types = "cccn",
locale = default_locale())
source("https://raw.githubusercontent.com/7PartidasDigital/R-LINHD-18/master/get_sentiments.R")Ahora has de cargar el texto de la novela que quieras analizar. En el repositorio de 7PartidasDigital tienes tres novelas de tres autores españoles muy interesantes:
- Los jinetes del Apocalipsis de Vicente Blasco Ibáñez (
cuatro_jinetes_apocalipsis.txt) - Los pazos de Ulla de Emilia Pardo Bazán (
pazos_ulloa.txt) - La Regenta de Leopoldo Alas Clarín (
LaRegenta.txt).
La instrucción para cargar el texto es
texto_entrada <- read_lines("https://raw.githubusercontent.com/7PartidasDigital/AnaText/master/datos/textos/cuatro_jinetes_apocalipsis.txt",
locale = default_locale())Si quieres analizar cualquiera de las otras tres novelas, tan solo tienes que cambiar en la orden anterior el título de la obra.
Habrá aparecido en Global Enviroment el objeto texto_entrada y te informará de que es un Large character que tiene 2105 elements y que ocupa 933.7 Kb. Si tienes esta información, la carga ha sido correcta. Pero vas a comprobarlo. Escribe en la consola
Esta orden habrá impreso los seis primeros elementos del vector texto_entrada.
## [1] "Vicente Blasco Ibáñez" "Los cuatro jinetes del Apocalipsis"
## [3] "1916" ""
## [5] "PRIMERA PARTE" "— I —"Para ver los seis últimos, basta con
## [1] "René se hallaba al pie del montículo. Varias veces le miró, luego de contemplar las sepulturas, como si estableciese una relación entre su marido y aquellos muertos. ¡Y él había expuesto su existencia en combates iguales á éste!..."
## [2] "—¡Y tú, pobrecito mío —continuó en alta voz—, podías estar á estas horas debajo de un montón de tierra con una cruz de palo, lo mismo que tantos infelices!..."
## [3] "El subteniente sonrió con melancolía. Así era."
## [4] "—Ven, sube —dijo Chichí imperiosamente—. Quiero decirte una cosa."
## [5] "Al tenerle cerca le echó los brazos al cuello, lo apretó contra las magnolias ocultas de su pecho, que exhalaban un perfume de vida y de amor, le besó rabiosamente en la boca, le mordió, sin acordarse ya de su hermano, sin ver á los dos viejos, que lloraban abajo queriendo morir... y sus faldas, libres al viento, moldearon la soberbia curva de unas caderas de ánfora."
## [6] "FIN"Ahora tienes que convertirlo en una tibble para poder dividirlo en palabras-token y hacer los primeros cálculos. Llamarás a esta primera tabla texto_analizar.
Lo que acabas de hacer es convertir en una tibble() lo que tenías en texto_entrada y le has indicado que la variable (columna) se llame texto. El resultado lo puedes ver con
Cuando pulses intro se imprimirá en la consola el comienzo de la tabla.
## # A tibble: 2,105 × 1
## texto
## <chr>
## 1 "Vicente Blasco Ibáñez"
## 2 "Los cuatro jinetes del Apocalipsis"
## 3 "1916"
## 4 ""
## 5 "PRIMERA PARTE"
## 6 "— I —"
## 7 "En el jardín de la Capilla Expiatoria"
## 8 "Debían encontrarse á las cinco de la tarde en el pequeño jardín de la Capilla Expiatoria, pero Juli…
## 9 "Habían transcurrido cinco meses desde las últimas entrevistas en este square que ofrece á las parej…
## 10 "Luego, Julio había hecho un viaje á Buenos Aires, encontrando en el otro hemisferio las últimas son…
## # ℹ 2,095 more rows
Figura 11.12: Evolución de a y á a través del tiempo según Google N-gram
Figura 11.13: Evolución de fue y fué a través del tiempo según Google N-gram
Una vez lo has convertido en una tabla, en la que cada fila es un párrafo, el siguiente paso es dividirlo en palabras-token –palabra–; crear un índice que equivaldrá a una página –pagina– de texto de un libro impreso; establecer qué palabras son positivas, cuáles negativas e incluso marcar aquellas que tengan una carga emotiva; recontarlas –sentimiento– y generar una tabla interna con la valencia para cada página. Por último, transformar los números de la columna negativo en números negativos. El código para hacer todo esto es
texto_analizar <- texto_analizar %>%
unnest_tokens(palabra, texto) %>%
mutate(pagina = (1:n()) %/% 400 + 1) %>%
inner_join(get_sentiments("nrc")) %>%
count(sentimiento, pagina = pagina) %>%
spread(sentimiento, n, fill = 0) %>%
mutate(negativo = negativo*-1)Al final tendrás en texto_analizar una tabla que puedes ver con
lo que imprimirá en la consola el comienzo de una tabla de 329 líneas y 11 columnas. Cada línea es una página y cada columna el valor sentimental y emotivo de cada una de ellas.
## # A tibble: 329 × 11
## pagina alegría asombro confianza disgusto ira miedo negativo positivo premonición tristeza
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 11 7 9 2 2 1 -13 18 14 4
## 2 2 7 8 12 5 6 8 -11 20 14 5
## 3 3 6 1 3 1 6 9 -10 13 7 6
## 4 4 11 3 12 3 6 8 -14 22 13 9
## 5 5 8 2 11 3 4 2 -10 27 6 4
## 6 6 7 6 14 2 11 9 -15 22 7 4
## 7 7 6 9 12 8 13 14 -18 22 9 9
## 8 8 11 6 13 2 6 8 -11 16 10 5
## 9 9 13 10 19 2 3 4 -8 28 11 5
## 10 10 8 12 9 3 11 13 -23 28 17 8
## # ℹ 319 more rows11.4.2 Explicación del código
Con la línea unnest_tokens(palabra, texto) divides el texto en palabras-token y se mantienen en el mismo orden que en el texto. Recuerda que las mayúsculas se pasan a minúsculas y los signos de puntuación se eliminan. (El resultado que te presento no lo puedes ver, es interno.)
## # A tibble: 131,337 x 1
## palabra
## <chr>
## 1 vicente
## 2 blasco
## 3 ibáñez
## 4 los
## 5 cuatro
## 6 jinetes
## 7 del
## 8 apocalipsis
## 9 1916
## 10 primera
## # ... with 131,327 more rowsCon mutate(pagina = (1:n()) %/% 400 + 1) se crea la numeración de pagina. Esta vez consideramos que son tan solo 400 palabras por página. Tú puedes decidir la longitud que mejor te convenga, pero a la hora de comunicar los resultados, debes informar de cuántas palabras conforman cada página.
## # A tibble: 131,337 x 2
## palabra pagina
## <chr> <dbl>
## 1 vicente 1
## 2 blasco 1
## 3 ibáñez 1
## 4 los 1
## 5 cuatro 1
## 6 jinetes 1
## 7 del 1
## 8 apocalipsis 1
## 9 1916 1
## 10 primera 1
## # ... with 131,327 more rowsCon inner_join(get_sentiments("nrc")) se agrega la columna con el sentimiento que tiene cada cada palabra (si es que está en el diccionario).
## # A tibble: 37,021 x 3
## palabra pagina sentimiento
## <chr> <dbl> <chr>
## 1 jardín 1 alegría
## 2 jardín 1 positivo
## 3 tarde 1 negativo
## 4 tarde 1 tristeza
## 5 pequeño 1 negativo
## 6 jardín 1 alegría
## 7 jardín 1 positivo
## 8 impaciencia 1 negativo
## 9 cita 1 asombro
## 10 cita 1 negativo
## # ... with 37,011 more rowsCon count(sentimiento, pagina = pagina) calculas –n– cuántas palabras de cada sentimiento o emoción –sentimiento– hay en cada página –pagina–.
## # A tibble: 3,283 x 3
## sentimiento pagina n
## <chr> <dbl> <int>
## 1 alegría 1 11
## 2 alegría 2 7
## 3 alegría 3 6
## 4 alegría 4 11
## 5 alegría 5 8
## 6 alegría 6 7
## 7 alegría 7 6
## 8 alegría 8 11
## 9 alegría 9 13
## 10 alegría 10 8
## # ... with 3,273 more rowsCon spread(sentimiento, n, fill = 0) lo que haces en convertir en 0 aquellas casillas en las que hay NA, de otro modo no podrás hacer los cálculos. Y, finalmente, con mutate(negativo = negativo*-1) conviertes la variable negativo en números negativos.
11.4.3 Representación gráfica
Antes de poder representar gráficamente el resultado, tienes que calcular la puntuación para cada página. Es una operación sencilla: se trata de sumar a los valores de la variable positivo a los de negativo y quedarte con una tabla con el valor final, recopilado en la variable sentimiento, para cada página. El código es
puntuacion <- texto_analizar %>%
mutate(sentimiento = positivo+negativo) %>%
select(pagina, sentimiento)El resultado lo puedes ver tecleando en la consola
Esta es la cabecera de la tabla con los resultados:
## # A tibble: 329 × 2
## pagina sentimiento
## <dbl> <dbl>
## 1 1 5
## 2 2 9
## 3 3 3
## 4 4 8
## 5 5 17
## 6 6 7
## 7 7 4
## 8 8 5
## 9 9 20
## 10 10 5
## # ℹ 319 more rowsAhora puedes representarlo gráficamente. Leer tablas de números no suele ser muy ilustrativo. El siguiente código
ggplot(data = puntuacion, aes(x = pagina, y = sentimiento)) +
geom_bar(stat = "identity", color = "midnightblue") +
theme_minimal() +
ylab("Sentimiento") +
xlab("Tiempo narrativo") +
ggtitle(expression(paste("Sentimiento en ",
italic("Los cuatro jinetes del Apocalipsis")))) +
theme(legend.justification=c(0.91,0), legend.position=c(1, 0))dibujará una gráfica de barras (figura 11.14).
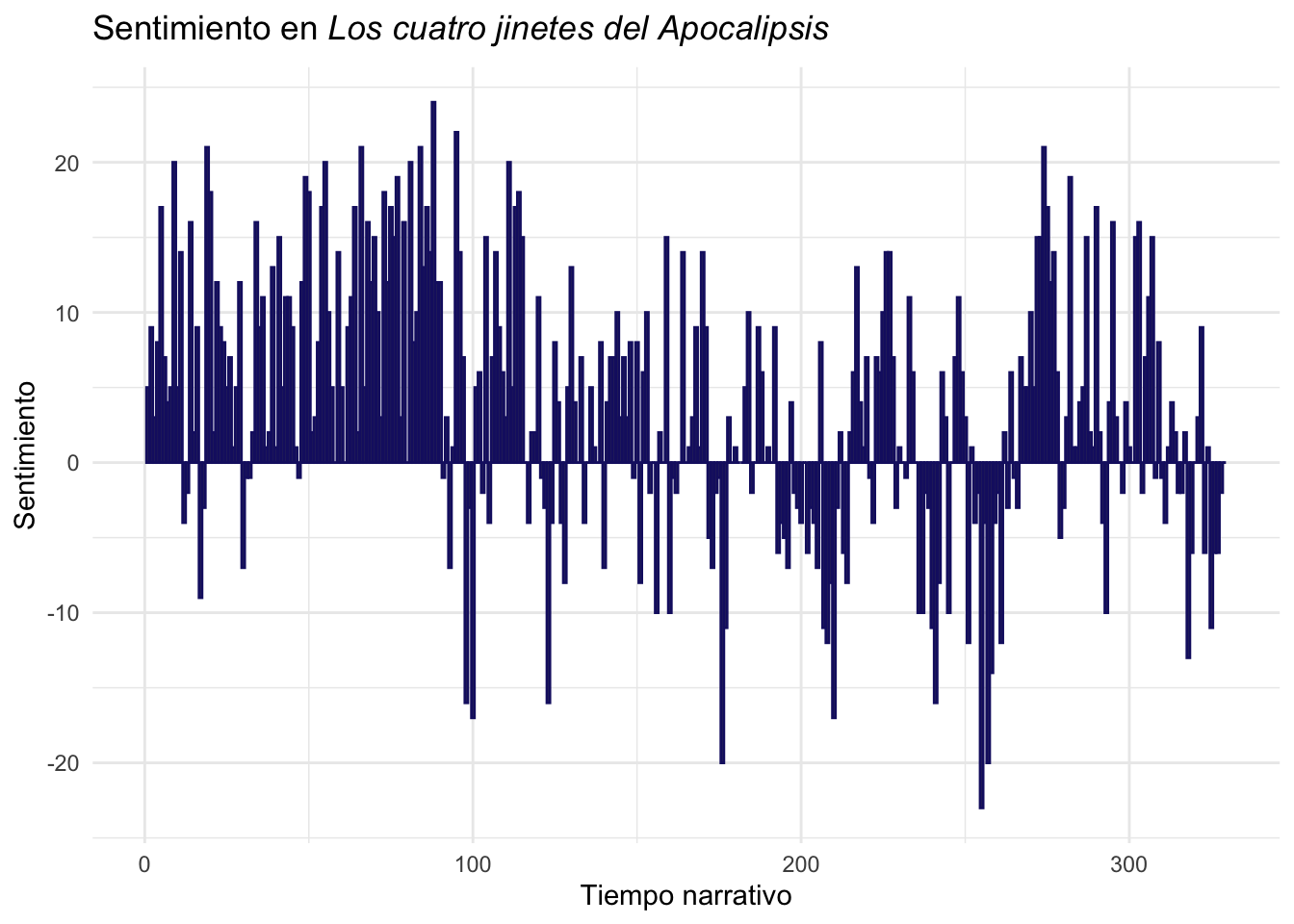
Figura 11.14: Sentimiento en Los cuatro jinetes del Apocalipsis
No creo que haya que explicar qué hace en cada línea esta expresión de ggplot(). Todo lo que contiene lo has visto en otras ocasiones.
Cada barra equivale a una página con lo que puedes ver qué partes de la novela son más positivas y cuáles menos. Ten en cuenta que el resultado depende en gran medida de la riqueza del diccionario, cuantas más palabras tenga, más fino y preciso será el análisis. Sin embargo, no queda claro, hay mucho ruido y no puedes ver con nitidez la curva de la línea por la que se transita la narración. Aquí es donde entra la magia del paquete syuzhet, del que solo vas a utilizar una función get_dct_transform() que necesita saber de donde obtener los datos, en tu caso de puntaucion$sentimiento y una serie de argumentos bastante crípticos, porque el autor del paquete no los explica suficientemente. Este es el código por medio del que actúa get_dct_transform():
texto_trans <- get_dct_transform(puntuacion$sentimiento,
low_pass_size = 10,
#x_reverse_len = nrow(puntuacion),
scale_range = TRUE)Aquí lo que aplica es una transformación matemática empleada para transformar, valga la redundancia, entre el dominio del tiempo (o espacial) y el dominio de la frecuencia que se conoce como Transformada de Fourier. Las matemáticas que hay detrás son de infarto, salvo para quien tenga un excelente dominio de este ámbito. Sin embargo, el programador de la librería nos excusa de las matemáticas y nos ofrece la magia del resultado. Toma los valores que has guardado en puntuacion y realiza los cálculos. El más importante es el low_pass_size, por defecto está programado como 5, he constatado que variando los valores el mejor parece ser 10. Los resultados los ofrecerá en un rango ente -1 y 1, de ahí el argumento scale_range = TRUE. El argumento x_reverse_len tiene por valor por defecto 100, y lo que hace es presentar el resultado en una escala de 0 a 100. Quizá sea un poco más complejo después ver a qué parte del texto se refiere, por lo que si se indica que use como valor el número de páginas nrow(puntuacion), entonces es más sencillo seguir la pista de dónde se produce cada cambio en el texto, como se puede ver en la gráfica de la figura 11.15.
El resultado de esta función es un vector de números. Ejecuta en la consola
Se imprimirá en la consola todo el contenido del vector. Es una larga lista de valores positivos y negativos.
## [1] 0.412685662 0.395886416 0.364010514 0.320357555 0.269524722 0.217016063 0.168772002
## [8] 0.130657134 0.107947771 0.104860866 0.124162748 0.166889859 0.232204825 0.317400489
## [15] 0.418052834 0.528311837 0.641308372 0.749646002 0.845939691 0.923359680 0.976138258
## [22] 1.000000000 0.992481981 0.953119072 0.883479971 0.787051295 0.668978911 0.535686826
## [29] 0.394403432 0.252632049 0.117606882 -0.004223556 -0.107645889 -0.189030047 -0.246550228
## [36] -0.280262906 -0.292037571 -0.285347585 -0.264939554 -0.236409161 -0.205718593 -0.178695087
## [43] -0.160551252 -0.155465728 -0.166257497 -0.194179293 -0.238845598 -0.298299619 -0.369212162
## [50] -0.447194496 -0.527197976 -0.603966105 -0.672500509 -0.728501187 -0.768743659 -0.791360901
## [57] -0.796005942 -0.783880960 -0.757629924 -0.721103284 -0.679014081 -0.636514089 -0.598725652
## [64] -0.570268898 -0.554824907 -0.554772847 -0.570933453 -0.602442784 -0.646769720 -0.699878922
## [71] -0.756528965 -0.810683980 -0.856007405 -0.886399065 -0.896532496 -0.882348511 -0.841463599
## [78] -0.773457739 -0.680015121 -0.564902389 -0.433781632 -0.293868285 -0.153456518 -0.021345515
## [85] 0.093791637 0.184049416 0.242893056 0.265676866 0.250036769 0.196125106 0.106667170
## [92] -0.013167848 -0.156074985 -0.313080649 -0.474136624 -0.628798984 -0.766943286 -0.879464331
## [99] -0.958909589 -1.000000000Tienes los datos que corresponde a cada página, y aunque se puede barruntar a que porción del texto corresponde, ggplot() necesita saberlo con precisión, por lo que has de crear una nueva tabla que informe a ggplot() de a qué página, o segmento, corresponde qué valor. Para conseguirlo debes usar esta expresión
que lo que hace orden es convertir texto_trans en una tibble con dos columnas: pagina y ft. pagina se rellena con el número de la página a la que corresponde cada valor de ft, que es el resultado obtenido por los cálculos de la función get_dct_transform(), por lo que basta con un simple seq_along(texto_trans), que lo que hace es rellenar las casillas de pagina con un número consecutivo que va desde 1 hasta la cantidad total de elementos (líneas) que haya en ft. El resultado lo puedes ver con
que imprimirá los mismo resultados de antes, pero cada valor ft está perfectamente identificado a qué página pertenece pagina.
## # A tibble: 100 × 2
## pagina ft
## <int> <dbl>
## 1 1 0.413
## 2 2 0.396
## 3 3 0.364
## 4 4 0.320
## 5 5 0.270
## 6 6 0.217
## 7 7 0.169
## 8 8 0.131
## 9 9 0.108
## 10 10 0.105
## # ℹ 90 more rowsAhora estás en disposición de dibujar la gráfica. Para ello necesitas esta pequeña sección de código de ggplot()
ggplot(texto_trans, aes(x = pagina, y = ft)) +
geom_bar(stat = "identity", alpha = 0.8,
color = "aquamarine3", fill = "aquamarine3") +
theme_minimal() +
labs(x = "Tiempo narrativo",
y = "Transformación Valorada del Sentimiento") +
ggtitle(expression(paste("Forma de la historia de ",
italic("Los cuatro jinetes del Apocalipsis"))))que dibujará esta gráfica de la figura 11.15.
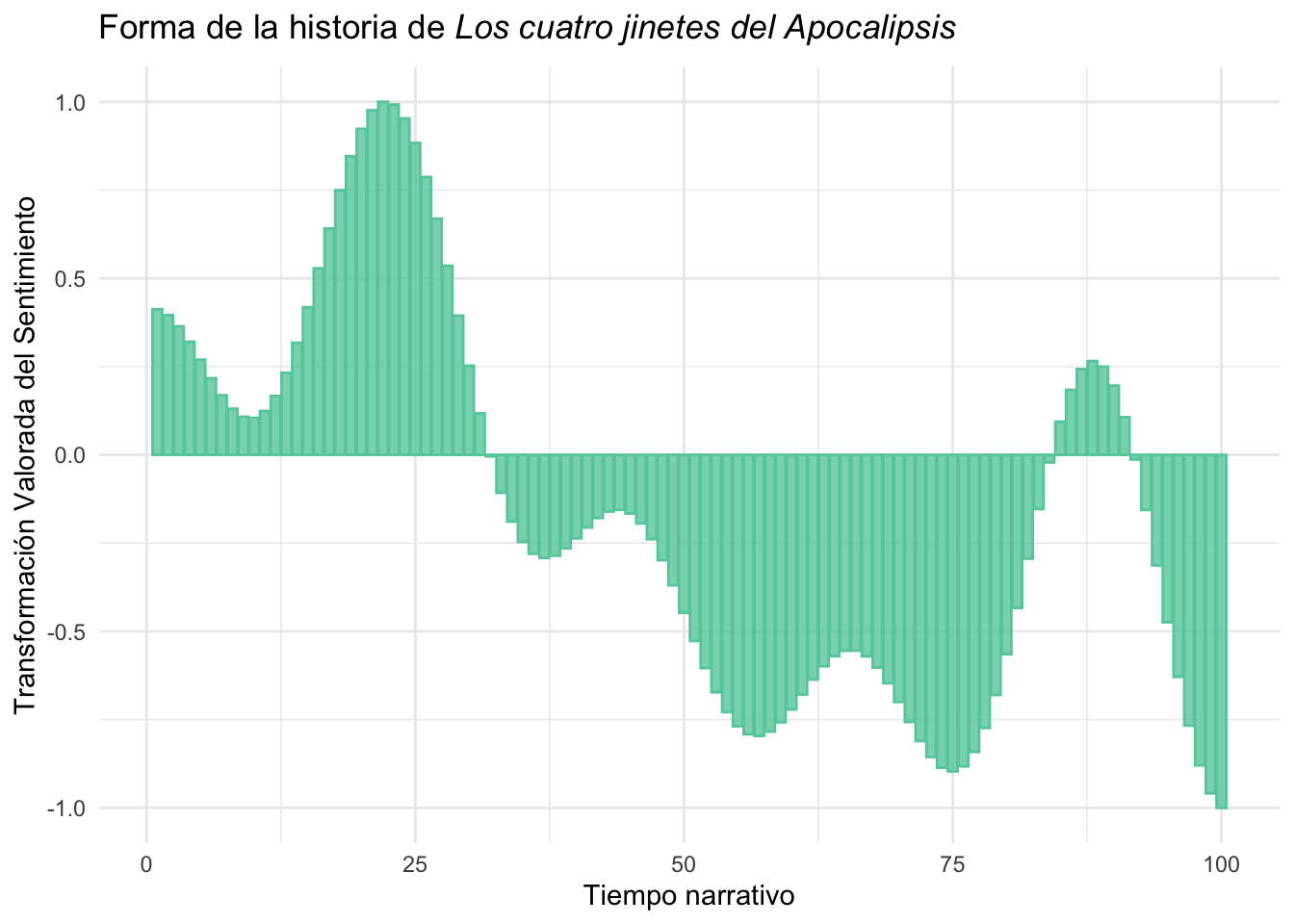
Figura 11.15: Forma de la historia de Los cuatro jinetes del Apocalipsis
Creo que todo lo que hace esta orden de ggplot() ya lo sabes porque lo has visto en los capítulos anteriores. Lo único raro esta vez es el contenido de ggtitle(). Aquí he querido que el título de la obra esté en cursiva, como mandan los cánones. Para conseguirlo hay que complicar la cosa con la función expression(), y lo que pretende es unir una primera parte “Forma de la historia de” y el título en cursiva, de ahí que use paste() para unirlos, y antes del título use italic().
Pero a veces, quizá sea mejor una sencilla gráfica de líneas que se obtiene con la función plot() básica de R (figura 11.16). El código para obtenerla es
plot(texto_trans,
type = "l",
yaxt = 'n',
ylab = "",
xlab = "Tiempo narrativo",
main = "La forma de la historia:\nLos cuatro jinetes del Apocalipsis")
abline(h = 0.0, col = "red")que dibujará una gráfica más sencilla, pero con la misma información.
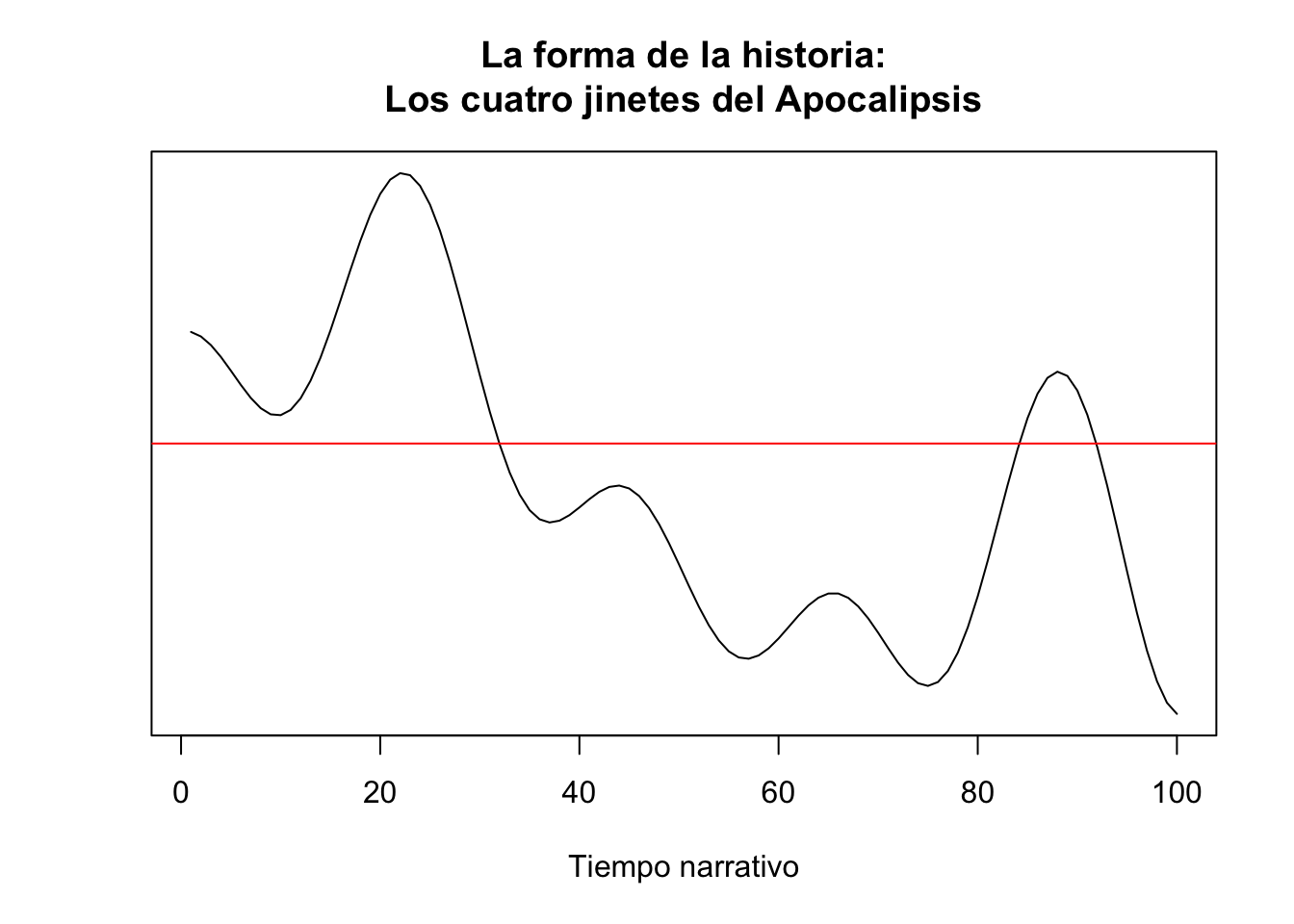
Figura 11.16: Forma de la historia de Los cuatro jinetes del Apocalipsis
Es muy sencilla. La función plot() es la responsable de dibujar la gráfica. El primer argumento es el lugar de donde ha de obtener los datos, en este caso texto_trans. El argumento type ="l" determina que dibuje una línea fina (hay otras posibilidades, échale una ojeada a la ayuda de plot). Los argumentos yaxt='n' y ylab="" evitan que se imprima información en el eje vertical (cuestión estética). Prueba a reimprimir el gráfico sin estos dos argumentos. xlab= sirve para darle una etiqueta más clara al eje horizontal (si no lo hubiera puesto había impreso pagina, que es el nombre de la variable, también habría sido clara, pero no tan emocionante). El argumento main ="" sirve para poner el nombre principal del gráfico. Verás que al final de la línea hay un \n, eso lo que le indica que es que lo siguiente lo imprima en una nueva línea.
La última instrucción abline() sirve para trazar una línea horizontal, de ahí el argumento h =. El valor 0.0 le indica que debe trazarla en el punto donde se encuentre el valor 0.0 (no lo puedes ver porque le has dicho que no lo imprima con yaxt='n'). El último argumento, col = "red", creo que es evidente: selecciona el color de la línea11.

El procedimiento propugnado por Jockers y que he mostrado en esta sección ha sido invalidado en gran medida por los trabajos de Swafford (2015), quizá esto explique que no haya habido mejoras en la librería
{syuzhet}desde 2017.↩︎