5 Palabras vacías
5.1 Introducción
Cuando cargaste y dividiste en palabras-token y palabras-tipo el capítulo Primer análisis de texto, y cuando en la segunda parte del capítulo Avance en el análisis textual leíste todos los mensajes y los dividiste, pudiste comprobar que la mayoría de las palabras que constituyen los mensajes de Navidad, en realidad cualquier otro texto, son muy poco informativas porque son preposiciones, artículos, conjunciones… como puedes observar en la gráfica 5.1.
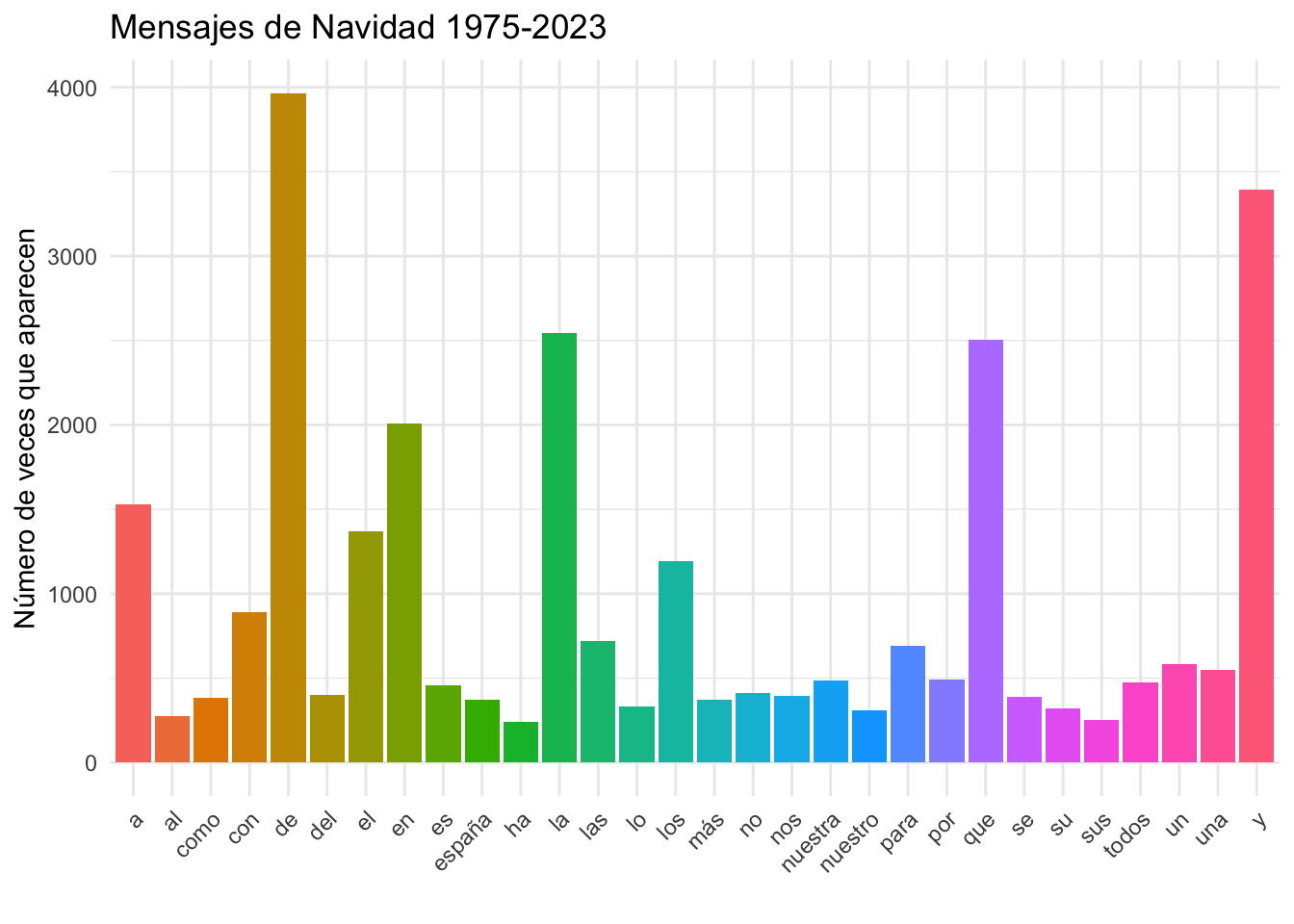
Figura 5.1: Las treinta palabras más frecuentes en los mensajes de Navidad
Es más, entre las 30 palabras más frecuentes de los mensajes de Navidad, que suponen el 43.38 % de las palabras-token, aunque apenas son el 0.47 % de las palabras-tipo de este corpus, tan solo son de interés semántico: España (en la posición 23 con 359 ocurrencias) y españoles (en la posición 30 con 225 apariciones), y son esperables puesto que son un mensaje que dirige el rey de España a toda la sociedad (sociedad en la posición 37 con 178 ocurrencias) española la tarde de Nochebuena de cada año (año en la posición 38 y con 175 apariciones).
A este tipo de palabras de altísima frecuencia, pero nulo valor semántico, que suelen coincidir con las llamadas palabras gramaticales, en el ámbito de la informática se las considera palabras vacías o huecas (ellos usan el término inglés stopwords). Por lo general las eliminan porque no les son útiles. Puesto que lo que te interesa en este momento es procesar las palabras con significado léxico hay borrarlas. Más adelante verás que las palabras vacías, las palabras gramaticales son la clave para resolver algunos problemas textuales (cf. Análisis de atribución de autoría).
5.2 Preparar el entorno
Quizá hayas estado cacharreando con RStudio y es posible que el Environment esté un poco desordenado e, incluso, es posible que hayas cargado alguna librería que no recuerdas y que te puede dar problemas. Mi recomendación, ya lo hice al principio del capítulo anterior, es que cierres RStudio y lo arranques de nuevo. Así te aseguras de que está todo en orden.
Ahora tienes que cargar los ficheros y regenerar los objetos que creaste en el capítulo anterior. Corta y pega en el editor de RStudio el bloque de código que hay a continuación.
# Carga las librerías
library(tidyverse)
library(tidytext)
# Cargará todos los ficheros de los mensajes
ficheros <- list.files(path ="datos/mensajes", pattern = "\\d+")
anno <- gsub("\\.txt", "", ficheros, perl = T)
mensajes <- tibble(anno = character(),
parrafo = numeric(),
texto = character())
for (i in 1:length(ficheros)){
discurso <- readLines(paste("datos/mensajes",
ficheros[i],
sep = "/"))
temporal <- tibble(anno = anno[i],
parrafo = seq_along(discurso),
texto = discurso)
mensajes <- bind_rows(mensajes, temporal)
}
# Regenera la tabla general con todas las palabras
mensajes_palabras <- mensajes %>%
unnest_tokens(palabra, texto)
# Crea la tabla con todas las palabras y calcula frecuencias
mensajes_frecuencias <- mensajes_palabras %>%
count(palabra, sort = T) %>%
mutate(relativa = n / sum(n))
# Borra objetos que no sirven y que son temporales
rm(temporal,discurso,i)
# Continúa desde aquí…# para recordarte qué hace cada bloque de código. Las explicaciones están en los capítulos precedentes.
Guárdalo en el directorio codigo y, por último, ejecútalo. La mejor manera es que sitúes el cursor en la línea en que se cargará tidyverse y vayas haciendo clic en el botón →Run del editor de RStudio, o selecciona todo con control A y ejecútalo con control intro (cmd en MacOS).
La última línea, la que dice rm() ( = remove = ‘borra’) lo que hace es borrar los objetos temporal, discurso y la variable de control i. No las necesitarás más y, aunque tu ordenador tendrá mucha memoria, es mejor tener el Environment algo aseado. Sé cuidadoso cuando utilices esta función porque una vez borrado un objeto ya no puede recuperarse, tendrías que regenerarlo.
Comprueba que todo ha ido bien revisando la pestaña Environment. Tienen que estar las tablas mensajes, mensajes_frecuencias y mensajes_palabras en la caja titulada Data. En la de Values tienen que estar los objetos annoy ficheros. Si es así, todo ha ido bien y tienes todo el material que necesitas para continuar.
5.3 Palabras vacías
En la red hay muchas listas de palabras vacías. No hay una válida para todo, por lo que cada analista ha de utilizar la que mejor le vaya para cada análisis. Por ejemplo, si quisieras analizar novelas publicadas en el siglo XIX te encontrarías con la sorpresa de que las que existen nunca borrarían las preposiciones y conjunciones que solían llevar tilde (á, ó, é, ú), algunas palabras que durante mucho tiempo han llevado tilde sin necesitarla (fué, fuí) y alguna otra. Pero no es el caso, por lo que, por el momento, puedes trabajar con la que trae de serie el paquete tidytext.
Para hacer más clara las cosas, vas a extraer la lista de palabras vacías que tiene tidytext y la vas a guardar en un objeto que llamarás vacias. Para hacerlo usarás la función get_stopwords() y como argumento le dirás que quieres las del español "es". La expresión es
Revisa ahora el contendido ejecutando en la consola esta orden
que imprimirá el comienzo de la tabla que contine la lista de las palabras vacías que tiene tidytext de serie.
## # A tibble: 308 × 2
## word lexicon
## <chr> <chr>
## 1 de snowball
## 2 la snowball
## 3 que snowball
## 4 el snowball
## 5 en snowball
## 6 y snowball
## 7 a snowball
## 8 los snowball
## 9 del snowball
## 10 se snowball
## # ℹ 298 more rowsTienes una tabla de 308 líneas y dos columnas. Cada línea tiene dos datos: una palabra española de muy alta frecuencia y la palabra snowball que indica la procedencia de la lista de palabras vacías: el proyecto Snowball. Es una información que no te interesa. El problemilla para nosotros es el nombre de la columna word.
5.3.1 La función rename()
Todos los lenguajes de programación, incluido R, están escritos en inglés, es decir, todas las funciones, órdenes, comandos, etc. están en esa lengua y no se pueden cambiar. Sin embargo, podemos nombrar las variables y los objetos como queramos.
En R, ya lo he dicho antes, solo hay dos restricciones serias a la hora de dar nombre a los objetos y las variables: nunca pueden empezar por un número. 1992_palabras no es válida, pero sí lo es palabras_1992. La otra es que no puede usar los signos matemáticos +, -, *, /) ni algunos otros símbolos como $ o #.
Ya lo has podido comprobar en los capítulos anteriores. Para hacerlo más claro, utilizo el español para dar nombre a las variables y objetos, pero sin letras con tildes, por lo que a veces las escribo en latín.
Cuando has dividido los textos de los mensajes en palabras, has identificado la columna que las almacena con el nombre palabra, pero las funciones del paquete tidytext emplea word. Podríamos haber identificado las columnas (variables) con los términos ingleses, pero ofuscaría un poco la explicación porque habría que dedicar algo de tiempo a dilucidar si es una función (siempre en inglés) o un objeto o una variable que has creado tú. Como vienen en inglés, y queremos mantener algo de orden, tenemos que cambiarlos al español. Es sencillo. Copia en el editor estas líneas.
Lo que acabas de pedirle a R es que cambie el nombre de la columna word a palabra. Para hacerlo, siempre se pone primero el nuevo nombre y después el término que se quiere cambiar. Una vez ejecutes lo anterior puedes comprobar que todo ha ido bien si ejecutas en la consola
Deberá imprimirse el comienzo de la tabla vacias.
## # A tibble: 308 × 2
## palabra lexicon
## <chr> <chr>
## 1 de snowball
## 2 la snowball
## 3 que snowball
## 4 el snowball
## 5 en snowball
## 6 y snowball
## 7 a snowball
## 8 los snowball
## 9 del snowball
## 10 se snowball
## # ℹ 298 more rowsFíjate que ahora la segunda línea dice palabra y lexicon, mientras que hace un momento decía word y lexicon. Un problema tonto resuelto en un segundo.
5.3.2 La función anti_join()
Una vez resuelto el asunto de los nombres de las columnas, es hora de borrar del corpus todas las palabras vacías, pero, para no eliminarlas del todo, pues puede que te venga bien tener una tabla con todas las palabras, guardarás la lista vaciada en mensajes_vaciado. Para borrar los términos no deseados se usa la función anti_join() cuyo argumento es el nombre de la tabla que contiene la lista de palabras que se han de borrar.
La forma de actuar de anti_join() es mirar en la columna palabra de la tabla mensajes_palabras y comprobar si alguna de las palabras se encuentra recogida en vacias. Si lo está, la borra. Ejecuta la orden. La respuesta de R habrá sido
## Joining with `by = join_by(palabra)`Esto quiere decir que tanto vacias como mensajes_palabras tienen una variable en común palabras que es la que ha permitido que funcione. De no haber cambiado el nombre de la variable, R habría respondido con un mensaje de error.
Error: `by` required, because the data sources have no common variables
Call `rlang::last_error()` to see a backtraceComprueba si en Environment ha aparecido el nuevo objeto mensajes_vaciado. Compara la cantidad de observaciones que tiene mensajes_palabras y las que tiene el nuevo objeto mensajes_vaciado. El primero tiene 65362 mientras que el segundo se ha reducido a 31252. Te has quitado de un plumazo 34110 palabras-token, más de la mitad de las que constituyen el corpus. Examina la tabla. La forma más sencilla es escribiendo en la consola View(mensajes_vaciado). Tan pronto como pulses intro se abre en la parte del editor una nueva pestaña con el contenido de mensajes_vaciado.
Fíjate que el nombre de la pestaña es el mismo que el del objeto que acabas de crear mensajes_vaciado y que tiene tres columna anno, parrafo, y palabra, y en el borde inferior informa de que está mostrando las líneas 1 a 16 de 31252 entradas (la cantidad de líneas mostradas varia de acuerdo con la altura de la ventana, por lo que la cantidad que te menciono y la que puede aparecer en tu pantalla depende de tu ordenador). Recorre la tabla. Verás que hay números (p. ej. 1976), y algunas palabras cuyo significado no es muy interesante (tantos, toda, frente –en otras circunstancias puede serlo–, casi, mera, sino, hacia, así, alguno, tan…). No ha quedado muy limpia, sigue habiendo palabras poco interesantes. Esto se debe a que la lista creada por Snowball, aunque es amplia no es muy completa, porque no tiene, por ejemplo, el mas adversativo ni el si condicional, tampoco los pronombres éste, ése, áquel, etc.). Por ese motivo, en el proyecto 7PartidasDigital hemos creado una lista de palabras vacías más extensa que incluye esas antiguallas ortográficas que he mencionado, alguna errata, demasiado usual, del tipo –tí–, algunas abreviaturas como sr., sra., d., dña., dª, sto., etc., y las letras del alfabeto. Su uso es tan sencillo como el de la lista que ofrece tidytext de serie.
La tienes en el repositorio del proyecto, por lo que que vas a descargarla y guardarla en tu ordenador con
vacias <- read_csv("https://raw.githubusercontent.com/7PartidasDigital/AnaText/master/datos/diccionarios/vacias.txt",
locale = default_locale())Cuando ejecutes la orden, en la consola aparecerá el mensaje
## Rows: 465 Columns: 1
## ── Column specification ────────────────────────────────────────────────────────────────────────────────
## Delimiter: ","
## chr (1): palabra
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Lo que te indica R es que ha leído el fichero y que hay una única columna llamada palabra cuyo contenido son caracteres.
Te explico la orden. Le has pedido que guarde en vacias un fichero que hay en un repositorio externo (pero bien podría ser tu ordenador, tan solo tienes que cambiar la url por la ruta dentro de tu máquina). Para resolver el problema que los ordenadores Windows tienen con las letras acentuadas, le indicas que debe leerlo con el sistema de codificación de tu ordenador locale = default_locale().
Si quieres guardar en tu ordenador la lista de palabras, para no tener que depender del repositorio, usa esta orden
"datos/vacias.txt", que es algo más sencillo que toda la dirección del repositorio.
Si se ha cargado bien, tendrás en Environment un objeto llamado vacias con 466 obs. of 1 variable. Puedes inspeccionarlo con View(vacias). Ya tienes la lista de palabras vacías que te ayudará a limpiar el corpus de las palabras gramaticales que no aportan, en este momento, nada. Recopia la orden
y ejecútala. Te responderá con
## Joining with `by = join_by(palabra)`Fíjate que ahora que el objeto mensajes_vaciado (lo tienes en la ventana Environment) tiene 29856 observaciones, es decir, 29856 palabras; bastantes menos que cuando lo limpiaste con la lista que tiene tidytext de serie. Vamos a ver, ahora, cuáles son las palabras más frecuentes del corpus. Para hacer el recuento vale con
pero esto solo te permitirá ver las 10 primeras y te indicará que ahora solo hay 6386 palabras-tipo.
## # A tibble: 6,386 × 2
## palabra n
## <chr> <int>
## 1 españa 372
## 2 españoles 232
## 3 sociedad 179
## 4 año 177
## 5 debemos 163
## 6 futuro 154
## 7 paz 146
## 8 convivencia 122
## 9 hoy 117
## 10 gran 110
## # ℹ 6,376 more rowsVamos a verlo de manera gráfica. Como lo que has visto al principio de este capítulo, en la figura 5.1, pero un poco más elegante. Copia el código que hay a continuación, pero no lo ejecutes hasta que hayas leído la explicación de qué es lo que hará.
mensajes_vaciado %>%
count(palabra, sort = T) %>%
filter(n > 65) %>%
mutate(palabra = reorder(palabra, n)) %>%
ggplot(aes(x = palabra, y = n, fill = palabra)) +
geom_bar(stat="identity") +
theme_minimal() +
theme(legend.position = "none") +
ylab("Número de veces que aparecen") +
xlab(NULL) +
ggtitle("Mensajes de Navidad 1975-2023") +
coord_flip()Lo de la primera línea lo tienes claro, es de dónde va a extraer los datos, de mensajes_vaciado. En la segunda, count(), contará cuantas ocurrencias tiene cada palabra-tipo y las ordenará de mayor a menor. En la tercera solo tendrá en cuenta aquellas que aparezcan 65 o más veces (> 65), lo que se consigue con la función filter(). Puesto que se ha creado una nueva tabla interna, que no vas a ver, tienes que crear una nueva columna con mutate() que tendrá una columna llamada palabra para almacenar esta nueva información y, además, la vas a reordenar por las frecuencias, de mayor a menor, para que sea más sencilla la lectura.
Ahora vienen las instrucciones para dibujar la gráfica encabezadas por ggplot(). Ya te advertí que para hacerlas bonitas hay que escribir algunas líneas de código algo complicadillas. Recuerda que cada instrucción de ggplot() se une a la siguiente con un +, no con %>%.
El primer argumento de ggplot() es qué es lo que ha de dibujar, y se le indica con aes(). Y lo que quieres es que en el eje horizontal x represente las palabras, en el vertical y marque la cantidad de veces que aparece cada palabra. El argumento fill = palabra provocará que cada una de las barras tenga un color para cada palabra, para que no sea una serie de aburridas barras grises (que es el color por defecto). Dentro de un ratito verás el resultado.
La función geom_bar(), aunque ya lo sabes de capítulos anteriores, indica cuál será del tipo de gráfico que dibujará. En este caso, de barras. El argumento stat = "identity" lo que le dice a R es que la altura de las barras representa los valores de n.
Las cuatro líneas siguientes son las responsables de no imprimir una leyenda para explicar el gráfico theme(legend.position = "none"); qué leyenda debe haber en el eje y y lo haces con ylab("Número de veces que aparecen"); que no debe haber ninguna etiqueta identificaba en el eje x, para lo que usas xlab(NULL); y, por último, cuál será el título del gráfico con ggtitle("Mensajes de Navidad 1975-2023"). La última línea, coord_flip() fuerza a que el eje y se imprima en la parte horizontal, y que el eje x se sitúe en la vertical puesto que así será más fácil leerlo. Ya sabes qué es lo que va a hacer, así que ejecútalo. El resultado tiene que ser el bonito gráfico multicolor de la figura 5.2.
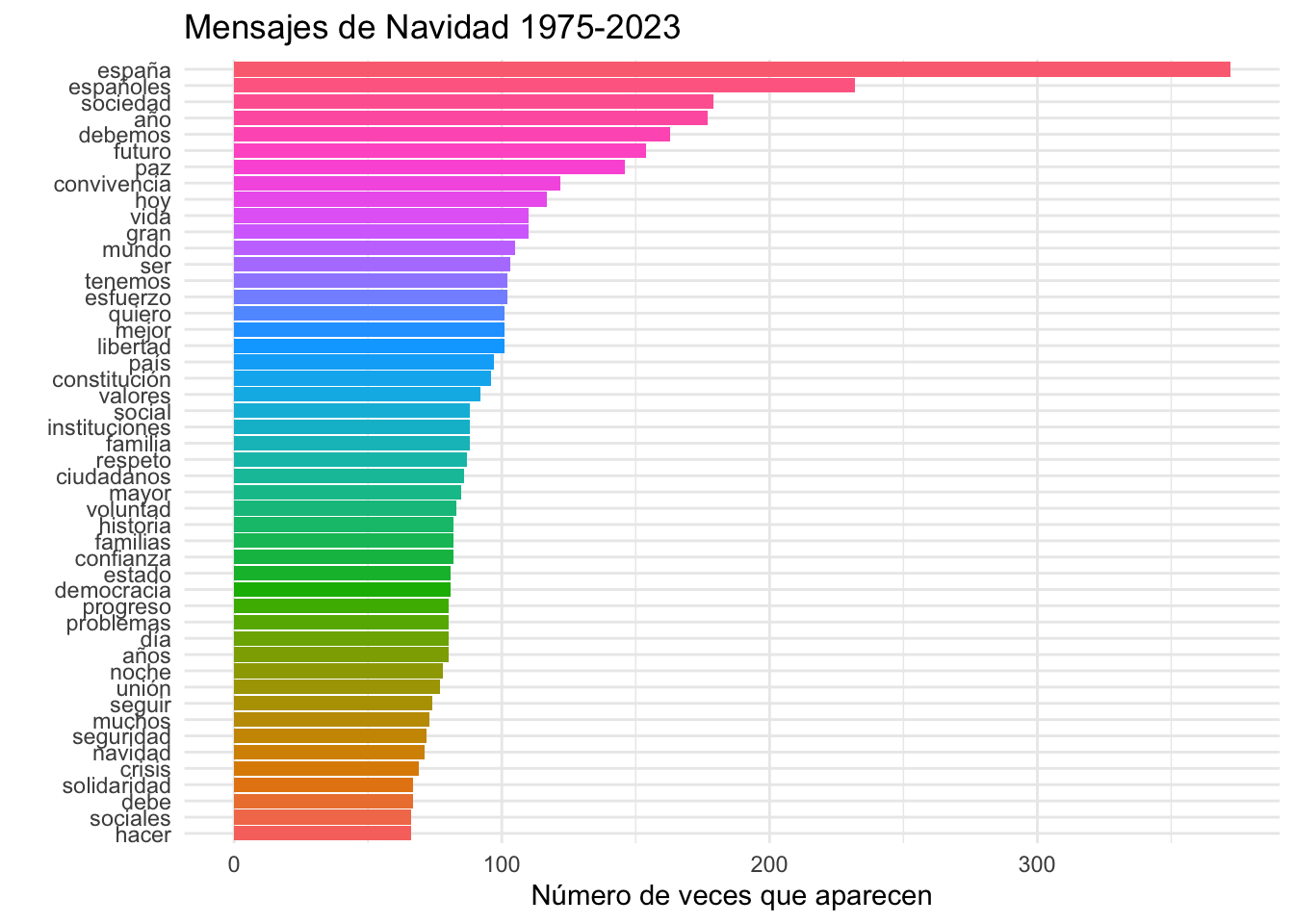
Figura 5.2: Las 30 palabras más frecuentes en los mensajes de Navidad con embellecimientos
filter(); mira el resultado si borras fill = palabra.
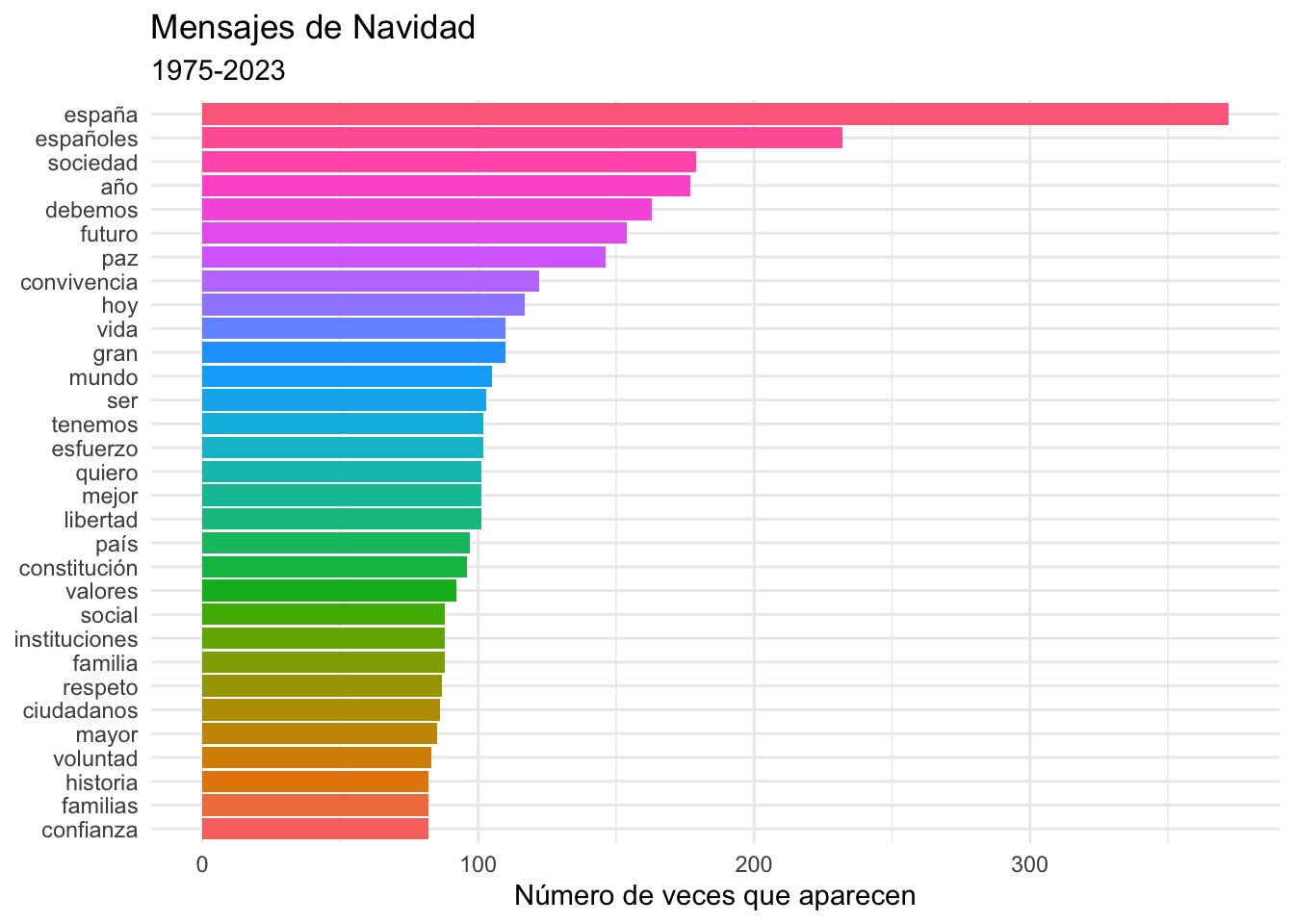
Figura 5.3: Gráfico que has de obtener modificando el código que ya tienes
5.4 Palabras vacías propias
Si te fijas, de las palabras que aparecen más de 65 veces varias son esperables: año, años, día, noche, país ya que se trata del mensaje en el que se recapitulan algunos de los hechos más importantes del año de un país; el mensaje se lee en el contexto de unas fiestas que se desarrollan en una serie de días, en una noche determinada y, por supuesto, el mensaje se dirige a todos los ciudadanos de España, es decir, a todos los españoles. Podrías borrar estas palabras. Aquí no son un gran estorbo, pero, pongamos por caso, en el análisis de una novela, o conjunto de novelas, abundarán los nombres propios, y eso podría ofuscar un tanto los resultados.
Considera el gráfico de la figura 5.4 que corresponde a las quince palabras más frecuentes en la novela Los Pazos de Ulloa de Emilia Pardo Bazán.
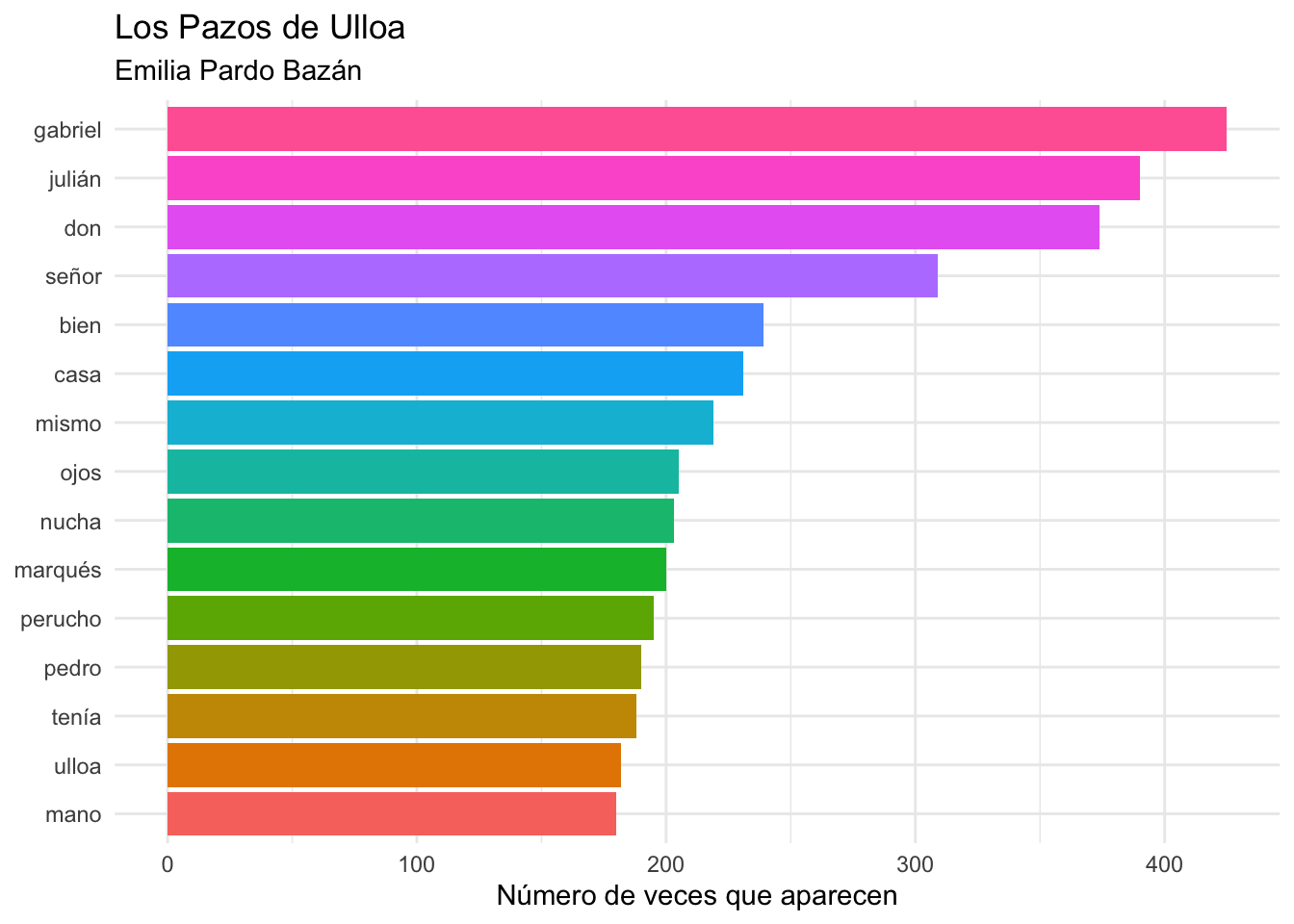
Figura 5.4: Las 15 palabras más frecuentes en Los Pazos de Ulloa
De ellas, siete son nombres propios: Gabriel, Julián, Nucha, Perucho, Pedro y Ulloa. Dos son sustantivos que indefectiblemente aparecen junto a un nombre propios: don y marqués. Señor queda en duda. Bien, mismo y la forma verbal tenía poco dicen. Por lo tanto, de las quince palabras más frecuentes solo nos quedan tres: casa, ojos y mano.
Puedes borrar todas esas palabras que poco dicen acerca del texto. Es decir, puedes crear tu propia lista de palabras vacías para cada análisis que hagas. Para lograrlo tienes que generar una tabla que contengan todas esas palabras que estimas que no sirven para nada. Para verlo más claro vamos a jugar un poco con Los Pazos de Ulloa.
Para cargar la novela de doña Emilia ejecuta esta orden (puedes copiarla en una sola línea, o bien dar un intro tras cada coma):
pazos <- tibble(texto = read_lines("https://raw.githubusercontent.com/7PartidasDigital/AnaText/master/datos/textos/pazos_ulloa.txt",
locale = default_locale(),
skip = 3))He condensado en una sola línea varias órdenes. Ya lo has visto antes. Le estás pidiendo a R que guarde en el objeto pazos el texto de la novela Los pazos de Ulloa que se encuentra en un repositorio externo. Ese objeto tiene que ser una tabla, lo que se consigue con tibble(), y ha de tener una columna llamada texto. Además, no ha de tener en cuenta las tres primeras líneas skip = 3 porque en ellas están los metadatos, mínimos, del fichero.
Emilia Pardo Bazán
Los Pazos de Ulloa
1886-1887Si todo ha ido bien, en la pestaña Environment habrá aparecido un nuevo objeto llamado pazos con 2815 obs. of 1 variable. Puedes ver el comienzo del contenido si ejecturas en la consola
## # A tibble: 2,815 × 1
## texto
## <chr>
## 1 PRIMERA PARTE
## 2 Los Pazos de Ulloa
## 3 TOMO I
## 4 I
## 5 Por más que el jinete trataba de sofrenarlo agarrándose con todas sus fuerzas a la única rienda de c…
## 6 Iba el jinete colorado, no como un pimiento, sino como una fresa, encendimiento propio de personas l…
## 7 Al acabarse el repecho, volvió el jaco a la sosegada andadura habitual, y pudo el jinete enderezarse…
## 8 —¿Tendrá usted la bondad de decirme si falta mucho para la casa del señor marqués de Ulloa?
## 9 —¿Para los Pazos de Ulloa? —contestó el peón repitiendo la pregunta.
## 10 —Eso es.
## # ℹ 2,805 more rowsAhora tienes que dividirlo en palabras-token y borrar las palabras vacías con
## Joining with `by = join_by(palabra)`Habrás obtenido un nuevo objeto llamado pazos_palabras con 82372 palabras-token. Además, en la consola se habrá impreso un mensaje recordándote que la eliminación de las palabras vacías se hizo por medio de la variable palabra.
Ahora tienes que borrar las palabras que has visto que son poco informativas. Para hacerlo tienes que crear una tabla con todas ellas. Vas a llamar a esta tabla vacias_adhoc (puedes usar cualquier nombre). Como es una tabla, usarás la función tibble(), y como argumento le indicarás que el nombre de la columna será palabra (¡cabía alguna duda!). El contenido será la serie de palabras que has decidido que no te interesa tener en cuenta. Para crear esta lista de palabras R tiene la función c() (‛concatenar’) que sirve para crear vectores, ya lo has visto en varias ocasiones. Como son cadenas alfanuméricas, debes encerrar cada elemento (cada palabra) entre comillas "" y separarlas con comas. La orden completa es la que hay a continuación. (Puede ser en una única línea, pero para que lo veas mejor he introducido un intro tras la coma que separa cada uno de los elementos.)
vacias_adhoc <- tibble(palabra = c("gabriel",
"julián",
"nucha",
"marqués",
"perucho",
"pedro",
"ulloa",
"don"))Cuando ejecutes la línea anterior, se creará una tabla con 8 observaciones y una sola variable. Esas son las ocho palabras extra que has decidido borrar del texto de Los Pazos de Ulloa. Ahora solo tienes que borrarlas. Ya sabes la fórmula, solo que esta vez el argumento de anti_join() será vacias_adhoc.
## Joining with `by = join_by(palabra)`El número de observaciones, es decir, de palabras que hay ahora en pazos_palabras es de 80213. Compara ahora la gráfica de la figura 5.5 con la de la figura 5.4.
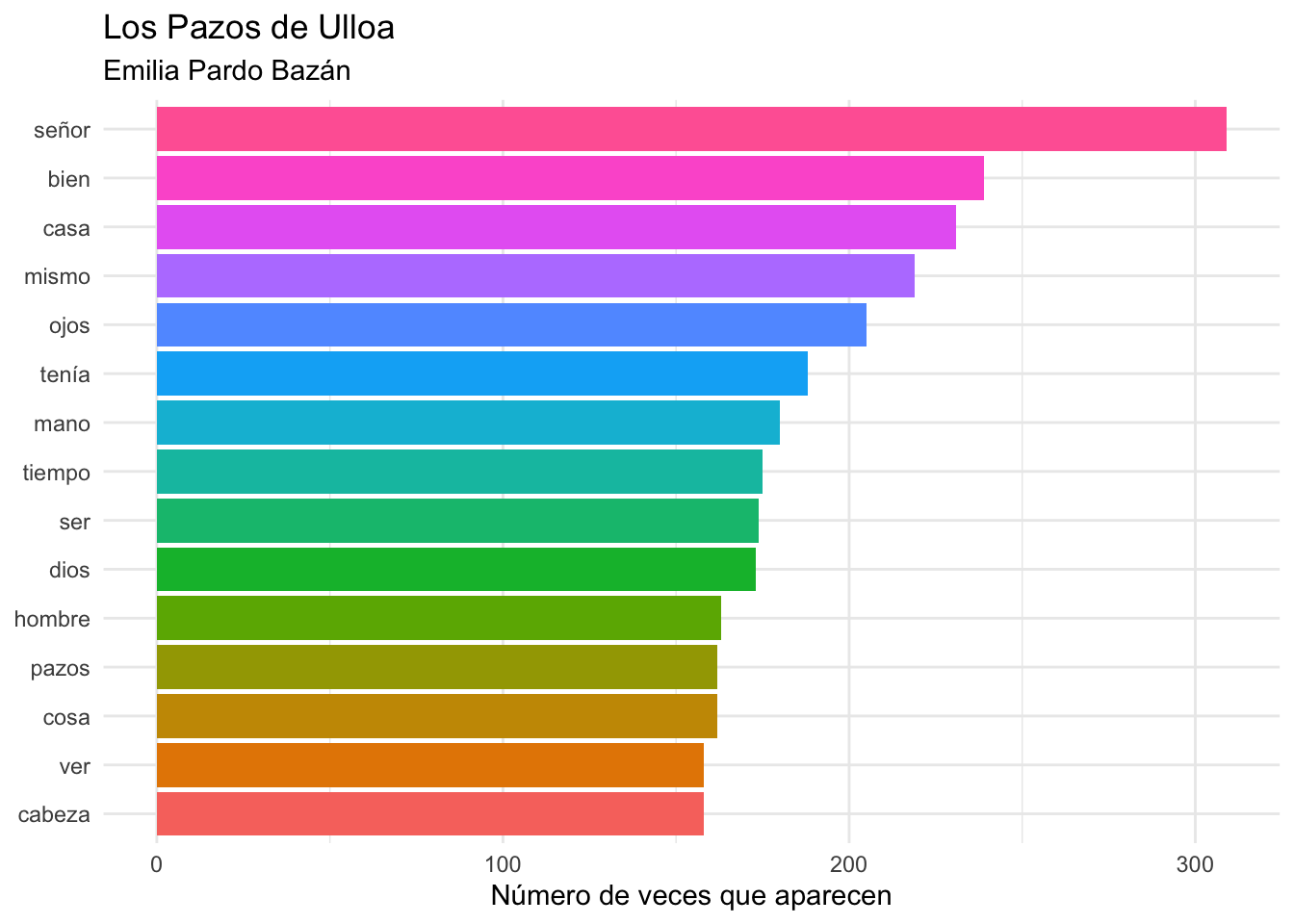
Figura 5.5: Las 15 palabras más frecuentes en Los Pazos de Ulloa tras aplicar tu propia lista de palabras vacías
La gráfica de la figura 5.5 se consigue con el bloque de código que hay a continuación.
pazos_palabras %>%
count(palabra, sort = T) %>%
top_n(15) %>%
mutate(palabra = reorder(palabra, n)) %>%
ggplot(aes(x = palabra, y = n, fill = palabra)) +
geom_bar(stat="identity") +
theme_minimal() +
theme(legend.position = "none") +
labs(title = "Los Pazos de Ulloa",
subtitle = "Emilia Pardo Bazán",
x = NULL,
y = "Número de veces que aparecen") +
coord_flip()No te lo explico porque lo tienes un poco más atrás. Volvemos a los Mensajes de Navidad, pero lo harás en el siguiente capítulo.

Quedan 22621 palabras-tipo. Para averiguarlo se usa esta expresión
pazos_palabras %>% count(palabra). Para regresar, pulsa↩︎