3 Primer análisis de texto
3.1 Introducción
En el capítulo anterior recolectaste el material que vas a necesitar para trabajar y para aprender a realizar análisis de textos con R. Ahora vas a inciarte en el análisis, y lo vas hacer con uno de los textos, el discurso de Nochebuena de 1975.
Como es posible que hayas estado cacharreando con RStudio y para evitar males mayores y, de paso, un buen quebradero de cabeza, inicia una nueva sesión de RStudio. El mejor sistema es cerrarlo y volver a arrancarlo. Una vez hecho, debes establecer como directorio de trabajo cuentapalabras. En un capítulo anterior te expliqué cómo hacerlo. Aunque la verdad sea dicha, todo este libro trabaja en ese diretorio, por lo que quizá sea mejor decirle a RStudio cuál ha de ser el directorio de trabajo por defecto, de manera que siempre que arranques RStudio utilice cuentapalabras y no tengas que preocuparte de establecerlo.
3.2 Trabajar con proyectos
Échale una ojeada al borde superior de la ventana de RStudio. En la parte derechas verás que hay un hexágono con una R dentro y que a su derecha dice Project: (None). Haz clic sobre esa etiqueta. Se abirá un pequeño desplegable. Haz clic en New Project…. Abrirá una ventana como la de la figura 3.1
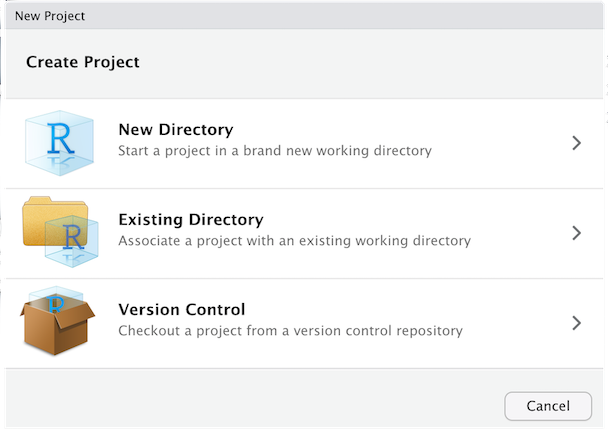
Figura 3.1: Panel de creación de proyecto
Puesto que ya has creado el directorio cuentapalabras, le indicarás a RStudio que el proyecto lo abrirás en un directorio que ya existe. Así que haz clic sobre Existing Directory. Se abrirá una nueva ventana como la de la figura 3.2 que te permitirá navegar por tu sistema de ficheros y carpetas hasta que encuentres dónde creaste el directorio cuentapalabras. Cuando lo hayas localizado, haz clic en Create Project. Lo más probable es que desaparezca todo de la pantalla de RStudio. No pasa nada, se está reiniciando para tener cuentapalabras como el directorio de trabajo por defecto.
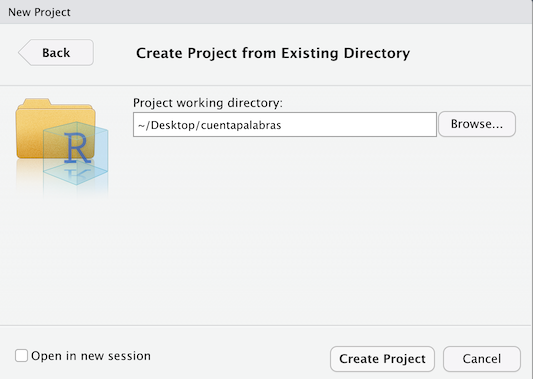
Figura 3.2: Navegador de selección
Para asegurate de que RStudio utiliza realmente el directorio cuentapalabras. Vamos a comprobar que realmente estás en cuentapalabras. Vuelve a echarle una ojeada al marco superior de RStudio, donde está el hexágnono, debe decir cuentapalabras (puede que haya algo más tras una raya). Si es así, está bien hecho.
Fíjate también en el panel Files. Verás en una franja gris intermedia un casilla blanca y a su lado una casita. Si la última palabra de esa línea dice cuentapalabras, entonces RStudio sabe que estás en el proyecto cuentapalabras. También puedes comprobarlo con
si lo que responde la consola acaba en cuentapalabras,
## [1] "/Users/JMFR/Library/CloudStorage/OneDrive-UVa/cuentapalabras"Siempre que inicies RStudio usará ese directorio por defecto, salvo que quieras trabajar con un proyecto diferente. En ese caso, debes hacer clic en el desplegable del hexágono y elegirlo o crearlo.
3.3 Leer el texto
Abre el editor de scripts (File > New File > R Script) para que vayas copiando las líneas de código que presento a continuación y los puedas ir ejecutando poco a poco.
Para este primer análisis vas a leer un único mensaje de Navidad, el del año 1975 que tienes en el fichero 1975.txt.
Lo primero es indicarle que el objeto en el que lo guardarás se llama discurso. A continuación introduces los símbolos de asignación <- y a la derecha la función readLines(), que, por el momento, solo requiere un argumento: el nombre del fichero y la ruta hasta él. Lo que tienes que escribir, entre los paréntesis, es "datos/mensajes/1975.txt". La línea que habrás escrito es
Si has pulsado intro y no ha sucedido nada es porque estás en el editor de RStudio. Para que se ejecute usa la combinación control e intro (cmd e intro en MacOS) o haz clic sobre el icono →Run que hay en el borde superior derecho del editor de RStudio.
Acuérdate. Si en el editor pulsas un sencillo intro tan solo pasas a la línea siguiente.
Cuando se ejecute la orden anterior, aparecerá en el panel Global Environment una línea que dirá
discurso chr [1:14] "En estas fiestas de nochebuena y…Esto significa que ha leído correctamente el fichero, que lo tienes guardado en el objeto discurso, y que se trata de un vector de caracteres (chr) que tiene 14 elementos –[1:14]–. Por último, muestra un poco del inicio (la cantidad depende del ancho de la pantalla). Puedes ver todo el texto si escribes en la consola discurso y pulsas intro.
aparecerá todo el texto del mensaje.
## [1] "En estas fiestas de nochebuena y navidad en que las familias españolas acentúan su sentido entrañable y parece que quisiéramos ser mejores, me dirijo a todos para felicitaros las pascuas y desearos un año 1976 lleno de venturas y felicidad."
## [2] "El año que finaliza nos ha dejado un sello de tristeza, que ha tenido como centro la enfermedad y la pérdida del que fue durante tantos años nuestro Generalísimo. El testamento dirigido al pueblo español es sin duda un documento histórico que refleja las enormes calidades humanas y los sentimientos llenos de patriotismo sobre los que quiso asentar toda su actuación al frente de nuestra nación."
## [3] "El hondo significado espiritual de estos días nos puede servir para recordar la actualidad del mensaje de Cristo, hace casi dos mil años."
## [4] "Fue un mensaje de paz, de unidad y de amor."
## [5] "Paz, que necesitamos para organizar nuestra convivencia. Pero que no se confunda con la mera paz material que excluye la violencia, sino también la paz de los espíritus y de las conciencias que evitando tensiones nos permitirá marchar hacia adelante, alcanzando así las metas que deseamos para nuestra patria."
## [6] "La unidad, necesaria para lograr la fortaleza que todo progreso demanda, que no elimina en modo alguno la variedad y que refuerza y enriquece los matices de un pueblo tan antiguo y con una historia tan fecunda como la nuestra."
## [7] "Y un mensaje de amor que es la esencia de nuestro cristianismo, el cual nos exige sacrificios, para que, prescindiendo de nuestras ambiciones personales, nos demos a los demás."
## [8] "En la alegría de esta noche no está quizá de más dejar paso a otros sentimientos; nuestro pensamiento y nuestro corazón han de pararse en aquellas familias en cuyo hogar aún no ha sido plenamente vencido el dolor o la dificultad. Que en todo hogar español reine la prosperidad y la justicia es una de las decididas voluntades de vuestro Rey."
## [9] "Es difícil encerrar en pocas palabras todos mis sentimientos en esta navidad. Nada me parece bastante cuando se trata de servir a nuestro pueblo. Soy consciente de las dificultades, pues muchas veces no se alcanza todo aquello que nos proponemos. Se necesita la ayuda de todos. Se necesita buena voluntad. Se necesita que se comprenda que hay que sacrificarse en aras de la justicia. El egoísmo de algunos puede perjudicar a muchos."
## [10] "Los problemas que tenemos ante nosotros no son fáciles, pero si permanecemos unidos y con voluntad tensa, el futuro será nuestro. Tengo gran confianza en las nuevas generaciones, pues conozco su gran sentido de la responsabilidad. Desearía que estos días meditásemos y que, dejando pequeñas diferencias, nos unamos para que España marche hacia las metas de justicia y grandeza que todos deseamos. Este es el reto de nuestro tiempo, esta es la primera exigencia de nuestra generación."
## [11] "Que el año santo, que pronto se abre en Compostela, sea un año de avance y progreso por el camino de la unidad."
## [12] "Tenemos las bases muy firmes que nos legó una generación sacrificada y el esfuerzo titánico de unos españoles ejemplares. Hoy les dedico desde aquí un homenaje de respeto y admiración."
## [13] "Al felicitaros otra vez y recordar muy especialmente a los que, ausentes de la patria, sienten la nostalgia de la lejanía, quiero desearos lo mejor para todos y para vuestras familias y despedirme con las palabras que resonaron en Belén en estos mismos días hace veinte siglos:"
## [14] "«Paz a los hombres de buena voluntad»."Para comprobar cuántos elementos tiene el objeto discurso ejecuta en la consola
El resultado tiene que ser
## [1] 14También vas a comprobar el tipo o clase de objeto que es. Lo logras al ejecutar en la consola
También lo puedes comprobar con
En cualquiera de los dos casos la respuesta será:
## [1] "character"Por lo tanto, la información que has visto en Global Environment y la que has extraído con estas instrucciones coinciden. Se trata de un vector de caracteres con 14 elementos. Fíjate que cada elemento, que se corresponde con un párrafo del discurso de la Navidad de 1975, está entrecomillado y que comienza con un número entre corchetes [1] … [14]. Ese número sirve para acceder a cualquier elemento de un vector. Si escribes en la consola
se imprimirá el primer párrafo.
## [1] "En estas fiestas de nochebuena y navidad en que las familias españolas acentúan su sentido entrañable y parece que quisiéramos ser mejores, me dirijo a todos para felicitaros las pascuas y desearos un año 1976 lleno de venturas y felicidad."Si lo que quieres es acceder al noveno párrafo (elemento), lo que tienes que ejecutar en la consola es
## [1] "Es difícil encerrar en pocas palabras todos mis sentimientos en esta navidad. Nada me parece bastante cuando se trata de servir a nuestro pueblo. Soy consciente de las dificultades, pues muchas veces no se alcanza todo aquello que nos proponemos. Se necesita la ayuda de todos. Se necesita buena voluntad. Se necesita que se comprenda que hay que sacrificarse en aras de la justicia. El egoísmo de algunos puede perjudicar a muchos."Fíjate en que en el resultado no se ha impreso el número [9] del elemento que has pedido sino [1]. Esto se debe a una de las peculiaridades de R, que considera que el resultado es un nuevo vector y, por consiguiente, tiene que indizarlo.
Compliquémoslo. Le vas a pedir que extraiga los párrafos 1 y 14, el primero y el último. Ejecuta en la consola
El resultado es
## [1] "En estas fiestas de nochebuena y navidad en que las familias españolas acentúan su sentido entrañable y parece que quisiéramos ser mejores, me dirijo a todos para felicitaros las pascuas y desearos un año 1976 lleno de venturas y felicidad."
## [2] "«Paz a los hombres de buena voluntad»."Fíjate que el primer párrafo sigue siendo el [1], pero el último, el decimocuarto del texto original, lo considera el segundo [2]. Te lo indico ahora para que no te sorprenda y te vuelvas loco buscando un elemento con un índice erróneo.
Supongo que tu tendencia, a la luz de que has usado discurso[1] para extraer el primer elemento y discurso[14] para ver el último, habrá sido pensar que tenías que escribir discurso[1,14]. Si hicieras eso obtendrías un mensaje de error (Error in discurso[1, 14] : número incorreto de dimensiones) ya que esa forma es la de acceder a las tablas (ya llegaremos a ello).
c(). De esta manera, lo que le estás indicando a R es que extraiga, consecutivamente, el contenido de los elementos 1 y 14 de discurso. Es como si hubieras ejecutado, uno tras otro las instrucciones, discurso[1] y discurso[14]. Sin embargo, aunque es posible, no es práctico. Piensa cuántas líneas tendrías que escribir si quisieras extraer, de una novela, pongo por caso, dos docenas o más de elementos para verlos. Sería horrible. Por eso has creado un vector interno que se ocupará de condensarlo en una sola expresión.
3.4 Dividir el texto en palabras
Para hacer análisis de textos con los ordenadores lo primero que hay que hacer, y lo básico, es contar las palabras que constituyen cada texto. Con los ordenadores el concepto palabra no tiene casi nada que ver con lo que un lingüista o un filólogo considera una palabra, salvo si la entendemos como palabra gráfica, tal y como la define la Ortografía básica de la lengua española, como
una sucesión de letras que aparecen en la línea de escritura entre espacios en blanco, o flanqueada por signos de puntuación o auxiliares (RAE 2012: 134).
En el ámbito de la minería de textos o en el del análisis automatizado de textos una palabra es una secuencia de caracteres palabra, es decir, cualquier letra o cualquier número y el guion bajo, situado entre dos espacios en blanco, o entre un espacio en blanco y un signo de puntuación. Considera la primera oración de la novela El capitán Alatriste, de Arturo Pérez-Reverte:
No era el hombre más honesto ni el más piadoso, pero era un hombre valiente.
Tiene 15 palabras que se encuentran entre un espacio en blanco, o un espacio en blanco y un signo de puntuación (consideramos que antes de «No» hay un espacio en blanco, aunque no lo veamos). En la tabla 3.1.
| Número | Palabra |
|---|---|
| 1 | No |
| 2 | era |
| 3 | el |
| 4 | hombre |
| 5 | más |
| 6 | honesto |
| 7 | ni |
| 8 | el |
| 9 | más |
| 10 | piadoso, |
| 11 | pero |
| 12 | era |
| 13 | un |
| 14 | hombre |
| 15 | valiente |
A estas se las designa palabras-token. Pero algunas de ellas se repiten. era, el, hombre y más aparecen dos veces, por lo que las palabras diferentes que realmente hay en la oración son once, como puedes observar en la tabla 3.2.
| Número | Palabra | Frecuencia |
|---|---|---|
| 1 | no | 1 |
| 2 | era | 2 |
| 3 | el | 2 |
| 4 | hombre | 2 |
| 5 | mas | 2 |
| 6 | honesto | 1 |
| 7 | ni | 1 |
| 8 | piadoso | 1 |
| 9 | pero | 1 |
| 10 | un | 1 |
| 11 | valiente | 1 |
A estas últimas se las designa palabras-tipo y son las únicas que podrían darnos un índice de la variedad léxica de un texto, no el número de palabras-token.
3.5 El mundo tidydata
R tiene varias formas de hacer la misma cosa y uno de los sistemas más cómodos para manejar datos textuales, para hacer lo que se denomina minería de textos, es por medio del llamado ecosistema tidydata. Este lo constituye un amplio número de librerías o paquetes que permiten manejar los datos de una manera más eficiente y sencilla. Es el sistema que vas a utilizar desde ahora. Podrías usar las funciones básicas de R, pero la programación serían más enrevesada.

La filosofía básica del sistema tidy es que convierte los datos en tablas (llamadas dataframes o tibbles) en las que cada variable es una columna y cada uno de los valores, que están en cada línea, que contiene una variable, es una observación. Esto hace que el manejo de los datos sea mucho más flexible y claro.
Para poder usar el sistema tidydata tienes que instalar dos paquetes o librerías: {tidyverse}, que incluye otros varios, y {tidytext}.
{ } que encierran los nombres de las librerías no son parte del nombre. Son una mera convención tipográfica que se ha extendido dentro de la comunidad R para distinguir el nombre del paquete de alguna función que pueda contender y que se llame igual. Así, por ejemplo, existe una librería que se llama {stylo} y dentro de ella una función que se llama stylo. Si pusiéramos solo stylo no sabríamos si estamos hablando de la función o de la librería, pero si ponemos {stylo} no hay equívoco alguno, sabemos que estamos hablando de la librería o paquete.
3.5.1 Instalar librerías
El paquete básico de R puede hacer muchísimas cosas, pero hay una legión de programadores por todo el mundo que escriben librerías que amplían las posibilidades del R básico. Estas librerías, también llamadas paquetes (packages), se han de instalar puesto que son accesorios muy útiles. Para instalar una librería se utiliza la función install.packages(). Ejecuta en la consola:
Durante un buen rato habrá mucha acción en la consola. R está instalando todas las librerías que constituyen {tidyverse} y {tidytext} y otras que estas dos necesitan para funcionar. Sabrás que ha finalizado el proceso cuando en la ventana de la consola vuelva aparecer el símbolo del sistema >.
Fíjate que los nombres de las librerías tienen que ir entre comillas. Da lo mismo que sean dobles "" que sencillas '', pero solo un tipo a la vez.
c("tidyverse", "tidytext"), lo que viene a ser lo mismo que ejecutar sucesivamente install.packages("tidyverse") e install.packages("tidytext"). Es lo mismo que has hecho cuando le has pedido, líneas atrás, que imprimiera los elementos 1 y 9 de discurso.
Una vez que se ha descargado e instalado una librería ya no hace falta volverla a instalar salvo para actualizarla.
Pero el que las tengas instaladas no quiere decir que R sepa que las tienes y que las puede usar, para ello tienes que cargarlas o invocarlas con la función library(). Así que carga las dos nuevas librerías con:
Cuando se cargue la librería {tidyverse} aparecerá mucha información
## ── Attaching core tidyverse packages ──────────────────────────────────────────────── tidyverse 2.0.0 ──
## ✔ dplyr 1.1.3 ✔ readr 2.1.4
## ✔ forcats 1.0.0 ✔ stringr 1.5.0
## ✔ ggplot2 3.4.3 ✔ tibble 3.2.1
## ✔ lubridate 1.9.3 ✔ tidyr 1.3.0
## ✔ purrr 1.0.2
## ── Conflicts ────────────────────────────────────────────────────────────────── tidyverse_conflicts() ──
## ✖ dplyr::filter() masks stats::filter()
## ✖ dplyr::lag() masks stats::lag()
## ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errorsNo tienes de qué preocuparte. Es meramente informativa. Da cuenta de qué versión de {tidyverse} tienes; informa de qué paquetes o librerías consta {tidyverse} y por último avisa de que hay unos pequeños conflictos con otras funciones de librería {stats}. ¡No pasa nada! Sencillamente informa. El sistema seguirá funcionando perfectamente.
3.5.2 Dividir en palabras-token
Ya tienes cargadas las liberías. Ahora vas a convertir el texto que tienes guardado en discurso en una tabla (tibble) con dos columnas. En la primera habrá un número que indicará el número del párrafo (en este caso, cada uno de los 14 elementos de discurso es un párrafo) y en la segunda se guardará el texto. Puede parecer una tontería, pero verás, según avanzas, que te hará la vida más fácil. Para transformar el objeto de caracteres discurso en esa tibble se emplea la función tibble(). Copia lo siguiente en el editor.
Lo primero que has hecho ha sido darle nombre a este nuevo objeto: mensaje y, a continuación, con la función tibble(), le has pedido que cree una tabla en la que habrá una columna llamada parrafo, en la que almacenará el número del párrafo, y otra llamada texto, en la que se guardará el texto de cada párrafo del mensaje que tienes guardado en discurso.
Para indicarle que introduzca el número del párrafo, lo más sencillo es decirle a R que mire cuántos elementos hay en discurso y que lo guarde en la casilla correspondiente de la columna (variable) parrafo. La manera de decirle que haga esa cuenta es con seq_along(). Entre los paréntesis le indicas quién es el responsable de establecer la secuencia, o, lo que es lo mismo, qué objeto conoce el número total de párrafos que tiene que numerar. Ejecuta la instrucción y, a continuación, escribe en la consola
Deberá aparecer algo idéntico a lo que hay a continuación (lo único que debe variar es la cantidad de texto que aparezca, pues depende del ancho de la ventana de la consola):
## # A tibble: 14 × 2
## parrafo texto
## <int> <chr>
## 1 1 En estas fiestas de nochebuena y navidad en que las familias españolas acentúan su sentido e…
## 2 2 El año que finaliza nos ha dejado un sello de tristeza, que ha tenido como centro la enferme…
## 3 3 El hondo significado espiritual de estos días nos puede servir para recordar la actualidad d…
## 4 4 Fue un mensaje de paz, de unidad y de amor.
## 5 5 Paz, que necesitamos para organizar nuestra convivencia. Pero que no se confunda con la mera…
## 6 6 La unidad, necesaria para lograr la fortaleza que todo progreso demanda, que no elimina en m…
## 7 7 Y un mensaje de amor que es la esencia de nuestro cristianismo, el cual nos exige sacrificio…
## 8 8 En la alegría de esta noche no está quizá de más dejar paso a otros sentimientos; nuestro pe…
## 9 9 Es difícil encerrar en pocas palabras todos mis sentimientos en esta navidad. Nada me parece…
## 10 10 Los problemas que tenemos ante nosotros no son fáciles, pero si permanecemos unidos y con vo…
## 11 11 Que el año santo, que pronto se abre en Compostela, sea un año de avance y progreso por el c…
## 12 12 Tenemos las bases muy firmes que nos legó una generación sacrificada y el esfuerzo titánico …
## 13 13 Al felicitaros otra vez y recordar muy especialmente a los que, ausentes de la patria, sient…
## 14 14 «Paz a los hombres de buena voluntad».Al ejecutar mensaje, R ha respondido con el contenido de ese objeto y con otras informaciones. Te dice que es una tibble (una tabla de tipo especial, son absolutamente irrelevantes, por ahora, las diferencias entre unas y otras tablas) que tiene catorce líneas y dos columnas. La primera columna se llama parrafo y su contenido son números enteros <int>; la segunda se llama texto y su contenido son caracteres <chr>.
Una data.frame y una tibble son prácticamente iguales, difieren en algunos detalles técnicos que no son de gran importancia por ahora. Lo realmente importante es que ambos tipos de objetos son tablas, como las de una hoja de cálculo, en la que las columnas pueden contener datos textuales –chr–, numéricos –int, num, dbl– y lógicos –TRUE, FALSE–, lo que las convierte en unos objetos muy flexibles para el análisis textual. Además las columnas (que son las variables) tienen nombres, con lo que es más sencillo referirse a ellas e identificarlas.
matrix. Estas solo pueden tener datos de un solo tipo: textuales, numéricos o lógicos, y tanto las columnas como las filas pueden tener nombres. Ya llegaremos a usarlas.
tibble es que el número índice, el que has visto que va entre corchetes [1], en ellas aparece sin los corchetes, en el margen izquierdo y sin ningún nombre ni indicación de clase en la columna, por lo que sabes que no son datos almacenados en la tabla. A pesar de ello, son datos e informaciones que podrás utilizar. ¿Te acuerdas de lo de la longitud? ¿Lo de lenght()? Aquí esta función te informaría del número de columnas, y para extraer el número de párrafos, ahora tienes que recurrir a la función nrow(), que contará el número de líneas que tiene la tabla.
Prueba los siguientes funciones en la consola:
el resultado tiene que ser:
## [1] 2En el caso de
debe ser:
## [1] 14Por lo tanto, tienes una tabla de 2 columnas, que es lo que te informa length() y 14 filas, que es lo que te cuenta la función nrow(). Con
averiguas que clase de objeto es
## [1] "tbl_df" "tbl" "data.frame"3.5.3 Dividir en token
Ahora vas a dividir el texto contenido en mensaje en palabras-token y guardarás la lista en el objeto mensaje_palabras. La instrucción es
La forma clásica de programar en R es dentro a fuera. Es decir, la función que esté más dentro de un instrucción será la primera que se ejecuta. Y a continuación se irán procesando las demás que haya de desde la más interna hacia la más externa (la que está más a la izquierda). Este sistema es un poco complicado de interpretar y seguir, sobre todo cuando anidad varias funciones. La verdad es que podrías ejecutarlas secuencialmente una detrás de otra y todo quedaría más claro, pero quizá no sea tan elegante.
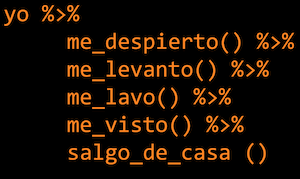
Los creadores de la librería {magrittr} desarrollaron un nuevo operador a que en inglés llaman pipe y cuya forma es %>%. Este operador permite encadenar las funciones de una manera más clara, lo que implica que es más fácil mantener y depurar el código. En Twitter me encontré una imagen que permite ver con claridad meridiana cómo funciona el operador %>%.
La forma de expresar la secuencia de Yo me despierto; me levanto; me lavo; me visto; y, salgo de casa, en el sistema usual de R se expresaría como se muestra en la figura 3.3.

Figura 3.3: Forma tradicional de programar en R
Pero con el operador %>% se expresarías de una manera más clara y fácil de seguir. Como puede ver en la figura ??. Lo que te permite añadir, con sencillez, pasos intermedios si fueran necesarios y sin que te pierdas con los paréntesis de cierre.
 %>%`
%>%`
%>%, pulsa intro. No se ejecutará. Si estás en la consola imprimirá un + en el margen izquierdo, pues está esperando a que completes la instrucción; si estás en el editor de RStudio saltará a la línea siguiente y lo que escribas a continuación estará sangrado, lo que te permitirá leer con mayor facilidad el código. Por ahora es claro y sencillo, pero te aseguro que se enredará insospechadamente.
Lo que le has dicho a R es que los datos de origen los encontrará en mensaje, por eso está antes de %>%. Con la función unnest_tokens() le estás ordenando que extraiga todas y cada una de las palabras que conforman el texto que hay almacenado en mensaje y que las guarde en la columna palabra de la nueva tabla que le has dicho que se llamará mensaje_palabras. Lo último que le indicas es que lo que ha de dividir en tokens se encuentra en la columna texto del objeto mensaje. Parece enredado, pero es bastante claro. Ejecútalo. No aparecerá nada en la consola. A continuación, escribe en la consola
El resultado será el comienzo de una tabla.
## # A tibble: 574 × 2
## parrafo palabra
## <int> <chr>
## 1 1 en
## 2 1 estas
## 3 1 fiestas
## 4 1 de
## 5 1 nochebuena
## 6 1 y
## 7 1 navidad
## 8 1 en
## 9 1 que
## 10 1 las
## # ℹ 564 more rowsCreo que no tengo mucho que explicarte. Ya lo sabes del resultado anterior. Es una tabla en la que hay 574 observaciones (filas) y 2 variables (columnas). La primera se llama parrafo, que has arrastrado desde mensaje, y recuerda en qué párrafo del mensaje original se encuentra cada palabra-token; es un número entero <int>. La segunda se llama palabra y su contenido son caracteres <chr>. La última línea te dice que además de las diez líneas impresas en la pantalla hay 564 más. Por lo tanto, ya sabes que el mensaje de Navidad de 1975 tiene 574 palabras-token.
Además de dividir el texto de mensaje en palabras, R ha eliminado la puntuación porque para contar palabras no es necesaria. Si tienes necesidad de hacer recuentos de signos de puntuación, sigues teniendo todo el texto inalterado en mensaje. También ha convertido todas las palabras a minúsculas. Es una decisión que puede parecer discutible porque se pierden algunos rasgos, por ejemplo, los de los nombres propios, pero es una información que no es pertinente en este momento y, en cambio, sí lo es que la máquina no haga diferencias entre el «En» inicial del texto –«En estas fiestas…»– y el «en» que hay un poco más abajo –«en que las…»–; ambos son lo mismo, pero para los ordenadores no puesto que cada letra, cada número, cada símbolo está codificado con un número; la «E» tiene el código 69 y la «e» el 101. Si no lo convirtieras a minúsculas serían dos palabras-tipo diferentes y los cálculos partirían con un error. Si por algún motivo necesitas conservar las mayúsculas, utiliza el argumento to_lower = FALSE. Pruébalo con esta línea de código.
En este caso, tan pronto como le has dicho a R que ejecute la expresión, ha impreso el resultado porque no le has dicho que la guarde en ningún otro objeto. No es necesario porque es un mero ejemplo. Observa que el primer «En» mantiene la mayúscula.
## # A tibble: 574 × 2
## parrafo palabra
## <int> <chr>
## 1 1 En
## 2 1 estas
## 3 1 fiestas
## 4 1 de
## 5 1 nochebuena
## 6 1 y
## 7 1 navidad
## 8 1 en
## 9 1 que
## 10 1 las
## # ℹ 564 more rowsLa función unnest_tokens() tiene otras posibilidades. Permite dividir el texto en oraciones o enunciados, en n-grams (ya lo verás en un capítulo más adelante), es decir, en secuencias de dos o más palabras juntas. Prueba esta orden en la consola.
## # A tibble: 27 × 2
## parrafo oraciones
## <int> <chr>
## 1 1 en estas fiestas de nochebuena y navidad en que las familias españolas acentúan su sentido e…
## 2 2 el año que finaliza nos ha dejado un sello de tristeza, que ha tenido como centro la enferme…
## 3 2 el testamento dirigido al pueblo español es sin duda un documento histórico que refleja las …
## 4 3 el hondo significado espiritual de estos días nos puede servir para recordar la actualidad d…
## 5 4 fue un mensaje de paz, de unidad y de amor.
## 6 5 paz, que necesitamos para organizar nuestra convivencia.
## 7 5 pero que no se confunda con la mera paz material que excluye la violencia, sino también la p…
## 8 6 la unidad, necesaria para lograr la fortaleza que todo progreso demanda, que no elimina en m…
## 9 7 y un mensaje de amor que es la esencia de nuestro cristianismo, el cual nos exige sacrificio…
## 10 8 en la alegría de esta noche no está quizá de más dejar paso a otros sentimientos; nuestro pe…
## # ℹ 17 more rowsLo que le has pedido a R es que divida el texto de mensaje en oraciones. Pero para que R sepa que tiene que dividirlo en oraciones y no en palabras (que es la forma por defecto), tienes que indicarlo con el argumento token = "sentences". Además, te interesa, en este momento, conservar las mayúsculas, por eso incluyes el argumento to_lower = FALSE. Observa que, de nuevo, ha arrastrado la variable parrafo, con lo que puedes saber cuántas oraciones hay en cada párrafo de este mensaje navideño: los párrafos 2, 5, 8 y 12 tiene dos oraciones, el párrafo 10 tiene 4 enunciados, mientras que los párrafos 1, 3, 4, 6, 7, 11, 13 y 14 solo tienen una. El párrafo que más oraciones tiene es el 9, que tiene 7. No lo ves porque lo que se imprime en la consola son solo las diez primeras líneas y el mensaje de 1975 tiene 27 enunciados.
mensaje en un nuevo objeto que se llame mensaje_enunciados.
Si en la pestaña Environment, debajo de Data, ha aparecido el objeto mensaje_enunciados y a su derecha dice 27 obs. of 2 variables, lo has conseguido. Era tan sencillo como poner antes de mensaje (a la izquierda) el nombre del objeto en que lo has de guardar –mensaje_enunciados– seguido de la secuencia de asignación <-.
mensaje_enunciados <- mensaje %>%
unnest_tokens(oraciones,
texto,
token = "sentences",
to_lower = FALSE)Ahora, lo que vas a hacer es añadir a mensajes_enunciados una columna en la que almacene el número de palabras que tiene cada oración. El código es
mensaje_enunciados <- mensaje %>%
unnest_tokens(oracion,
texto,
token = "sentences") %>%
mutate(NumPal = str_count(oracion,
pattern = "\\w+"))Lo único nuevo es la última línea de función. La función mutate() se encargará de crear e incluir en mensaje_enunciados una nueva columna (la añadirá en la parte derecha de la tabla) llamada NumPal que recogerá la información referente al número de palabras de cada oración. Lo complicadillo, quizá, es contar las palabras de cada oración.
La ventaja es que ya lo tienes divido en oraciones, con lo que únicamente tienes que decirle a R que cuente las palabras que hay en cada fila de mensaje_enunciados y eso lo consigues con la función str_count() (= string count = recuenta cadenas), la cual necesita dos argumentos: dónde está lo que ha de contar, en este caso en la columna oracion, y cómo lo ha de hacer, de lo que se encarga el argumento pattern = "". Y aquí es donde viene la complicación.
La forma más sencilla de contar el número de secuencias de caracteres-palabra (letras, números y guion bajo o combinación de ellos) que hay en cada oración es con una expresión regular, puesto que se trata de caracteres-palabra el patrón se expresa con \\w+. Esta notación lo que quiere decir es: busca cualquier grupo de caracteres-palabra \\w y esas secuencias pueden tener 1 o más componentes, lo que se indica con +.
Inspecciona el resultado de lo que acabas de hacer. Escribe en la consola
Tan pronto como pulses intro aparecerán las diez primeras líneas de la tabla que guarda el resultado.
## # A tibble: 27 × 3
## parrafo oracion NumPal
## <int> <chr> <int>
## 1 1 en estas fiestas de nochebuena y navidad en que las familias españolas acentúan su se… 40
## 2 2 el año que finaliza nos ha dejado un sello de tristeza, que ha tenido como centro la … 29
## 3 2 el testamento dirigido al pueblo español es sin duda un documento histórico que refle… 37
## 4 3 el hondo significado espiritual de estos días nos puede servir para recordar la actua… 23
## 5 4 fue un mensaje de paz, de unidad y de amor. 10
## 6 5 paz, que necesitamos para organizar nuestra convivencia. 7
## 7 5 pero que no se confunda con la mera paz material que excluye la violencia, sino tambi… 42
## 8 6 la unidad, necesaria para lograr la fortaleza que todo progreso demanda, que no elimi… 40
## 9 7 y un mensaje de amor que es la esencia de nuestro cristianismo, el cual nos exige sac… 29
## 10 8 en la alegría de esta noche no está quizá de más dejar paso a otros sentimientos; nue… 41
## # ℹ 17 more rowsComo puedes ver, tienes una tabla de 27 líneas, ya sabías que el mensaje de 1975 tenía 27 oraciones, pero fíjate en la columna de la derecha, la llamada NumPal que contiene números enteros <int>. Cada uno de esos números indica el número de palabras que tiene cada oración. Comprueba si lo ha hecho bien. Fíjate que la oración 5, que es la única del párrafo 4, según la columna NumPal, tiene 10 palabras. Cuéntalas a mano… Tiene diez palabras.
Vas a comprobar que están todas las palabras. Cuando un poco más atrás dividiste el texto en palabras-token viste que había 574 palabras. Vas a comprobar si el recuento de palabras que acabas de realizar cuadra con el número de palabras que has calculado por oración. Para ello basta con sumar el contenido de la columna NumPal de mensaje_enunciados. La función es sum() y esta lo único que requiere saber es dónde están los datos que ha de sumar. La forma de índicarselo es diciéndole a sum() que los datos están en mensaje_enunciados$NumPal. Prueba esto en la consola.
El resultado tiene que ser
## [1] 574¡Perfecto! La división en palabras-token y la suma del número de palabras que tiene cada enunciado coinciden.
Quizá te haya llamado la atención el argumento de sum(): mensaje_enunciados$NumPal. Ahí lo que le estás diciendo es que lo que tiene que sumar son los valores de la columna NumPal de la tabla mensaje_enunciados y la forma de indicarle a R cuál es la columna que ha de tener en cuenta es separando su nombre del nombre de la tabla con el símbolo $. He aquí la importancia de que cada columna (variable) tenga un nombre, puedes referirte a ellas por medio del nombre.
Otra manera de seleccionar las colunas es por medio del lugar que ocupan dentro de la tabla. Así, para realizar la suma anterior, tienes que ejecutar en la consola:
El resultado será idéntico:
## [1] 574Antes de concluir esta sección falta por averiguar cuántas palabras-tipo hay en el discurso de 1975. Se logra con la función count() que solo necesita un argumento: qué es lo que ha de contar. En este caso el número de filas diferentes que tiene la columna palabras.
Tan pronto como ejecutes la instrucción anterior te presentará el resultado. Bueno, la cabecera de la tabla.
## # A tibble: 291 × 2
## palabra n
## <chr> <int>
## 1 1976 1
## 2 a 7
## 3 abre 1
## 4 acentúan 1
## 5 actuación 1
## 6 actualidad 1
## 7 adelante 1
## 8 admiración 1
## 9 al 3
## 10 alcanza 1
## # ℹ 281 more rowsLa primera línea del resultado te dice que en el mensaje de 1975 hay 291 palabras-tipo y, a continuación, te informa de cuántas veces aparecen las diez primeras (por orden alfabético). Si quisieras verlas ordenadas por el número de ocurrencias de cada una de las palabras-tipo, tienes que darle a count() (= cuenta) otro argumento: sort = (= ordena). Si lo quieres de mayor a menor frecuencia el valor de sort será TRUE o T.
con lo que el resultado será
## # A tibble: 291 × 2
## palabra n
## <chr> <int>
## 1 de 37
## 2 que 32
## 3 la 23
## 4 y 23
## 5 en 14
## 6 el 11
## 7 las 11
## 8 para 9
## 9 los 8
## 10 nos 8
## # ℹ 281 more rowsYa sabes cuáles son las palabras más frecuentes en el discurso de 1975. La verdad es que no son muy excitantes, todas son palabras gramaticales.
3.5.4 Contar el número de caracteres (letras)
Ahora vas a contar cuántas letras tiene cada palabra. La información básica la tienes en mensaje_palabras; ahí tienes dos columnas, una te indica el párrafo, parrafo, y la otra, palabra, contiene cada uno de las palabra-tipo del texto. Ya sabes, lo acabas de ver, que para añadir una columna a una tabla que ya existe debes utilizar la función mutate(). Como lo que vas a contar es el número de letras (caracteres) que tiene cada palabra llamarás a la nueva columna NumLetras. Para contar los caracteres que hay en un elemento (en esta caso casilla de una tabla), R tiene la sencilla y eficaz función nchar() (= número de caracteres) que se ocupa de hacer el cálculo.
Así que lo que se pretende es que a mensaje_palabras se le añada una columna que se llame NumLetras y cuyo contenido sea el número de caracteres que tiene cada palabra-tipo que hay en la columna palabra. El código es
Ya está hecho. Compruébalo con
que imprimirá el comienzo de la tabla organizada de acuerdo con la secuencia original del texto.
## # A tibble: 574 × 3
## parrafo palabra NumLetras
## <int> <chr> <int>
## 1 1 en 2
## 2 1 estas 5
## 3 1 fiestas 7
## 4 1 de 2
## 5 1 nochebuena 10
## 6 1 y 1
## 7 1 navidad 7
## 8 1 en 2
## 9 1 que 3
## 10 1 las 3
## # ℹ 564 more rowsEste resultado, sin embargo, oscurece un poco la visión global del número de letras que tiene cada palabra. Quieres saber cuántas longitudes diferentes hay, cuál es la longitud más frecuente (o abundante), cuántas letras tiene la palabra más larga. Extraer esta información es muy sencillo. Solo tienes que pedirle a R que cuente cuántas longitudes diferentes hay y que lo presente en una tabla. Ahora bien, le puedes pedir que el resultado lo presente ordenado por en número de letras con
El resultado, como de costumbre, es el comienzo de una tabla. En la primera línea te dice que la tabla tiene 14 líneas y dos columnas. Esto quiere decir que hay catorce longitudes diferentes.
## # A tibble: 14 × 2
## NumLetras n
## <int> <int>
## 1 1 31
## 2 2 126
## 3 3 101
## 4 4 55
## 5 5 44
## 6 6 42
## 7 7 59
## 8 8 47
## 9 9 22
## 10 10 21
## 11 11 14
## 12 12 9
## 13 13 2
## 14 15 1Puesto que solo hay 14 longitudes diferentes, R ha impreso todos los resultados y puedes, por tanto, ver cuál es la longitud más frecuente. Sin embargo, a veces, las tablas son mucho más largas y por este motivo no puedes ver los resultados con facilidad porque estarían muy dispersados a lo largo de la tabla, por lo que debes ordenarlos de mayor menor. Ya has visto cómo lo puedes conseguir, basta con que a count() le añadas el argumento sort = TRUE.
Ya la tienes ordenada por frecuencias, de mayor a menor.
## # A tibble: 14 × 2
## NumLetras n
## <int> <int>
## 1 2 126
## 2 3 101
## 3 7 59
## 4 4 55
## 5 8 47
## 6 5 44
## 7 6 42
## 8 1 31
## 9 9 22
## 10 10 21
## 11 11 14
## 12 12 9
## 13 13 2
## 14 15 13.6 Cálculo de frecuencias
Ya tienes un montón de información numérica acerca del texto del mensaje de Navidad de 1975. Sabes cuántas palabras-token tiene, cuántas palabras-tipo, cuáles son las más frecuentes, cuántas oraciones y cuántas palabras por oración tiene cada una de ellas, cuántas letras tiene cada palabra, que las más abundantes son las de dos letras y que la más larga tiene 15. Tienes a tu alcance un montón de información numérica que te puede contar muchas cosas del texto. Vamos hacer unos cuantos análisis estadísticos elementales.
3.6.1 Frecuencia absoluta
Un poco antes has visto cómo conseguir las palabras-tipo y contar cuantas ocurrencias hay de cada una de ellas con
lo que imprimirá en la consola
## # A tibble: 291 × 2
## palabra n
## <chr> <int>
## 1 de 37
## 2 que 32
## 3 la 23
## 4 y 23
## 5 en 14
## 6 el 11
## 7 las 11
## 8 para 9
## 9 los 8
## 10 nos 8
## # ℹ 281 more rowsEl resultado no es muy excitante, tan solo te informa de que el mensaje de Navidad de 1975 tiene 291 palabras-tipo y cuántas veces aparece cada una de ellas (bueno, tan solo las diez primeras). Son palabras que no dicen nada. Es más, salvo nos, todas están entre las 11 palabras más frecuentes del listado de las 1.000 palabras más frecuentes del CREA, el Corpus de Referencia del Español Actual de la Real Academia Española. nos está en la posición 62 de esa misa lista, así que tampoco informa de mucho.
Lo que has estado obteniendo son las frecuencias absolutas de las palabras-token, de las palabras-tipo y del número de letras de cada palabra. Este es el estadístico más básico y consiste en el contar cuantos valores hay en cada uno de los conjuntos.
3.6.2 Frecuencia relativa
Otro estadístico básico de interés es la proporción de cada una de ellas con respecto a todo el texto, es decir, la frecuencia relativa. Es un cálculo muy sencillo. Tan solo hay que dividir el número de ocurrencias de cada palabra-tipo por el total de palabras-token del texto.
\[Frecuencia relativa =\frac{Frecuencia absoluta de la palabra tipo}{Número total de palabras tokens en el corpus} \]
Vas hacer el cálculo para cada palabra-tipo y lo vas a guardar en una columna que llamarás relativa. Copia este código y ejecútalo.
mensaje_frecuencias <- mensaje_palabras %>%
count(palabra, sort = T) %>%
mutate(relativa = n / sum(n)) Lo primero que le indicas a R es que guarde el resultado de esta operación en la tabla mensaje_frecuencias. Le dices, además, que los datos los tiene que buscar en mensaje_palabras. Lo siguiente que ha de hacer es contar con count() el número de veces que aparece cada palabra-tipo las cuales están guardadas en la variable palabra y ha de ordenarlas de mayor a menor frecuencia absoluta con sort = T. Nada nuevo. Sin embargo, en la última línea le pides que ha de crear una nueva columna con mutate() que se llamará relativa y que debe rellenar cada casilla con el resultado de dividir el número de ocurrencias de cada palabra-tipo n por la suma del número total de veces que aparece cada palabra-tipo sum(n). Esta suma es idéntica al número de palabras-token, pero como no querrás tener que introducirlo manualmente, le dices R que lo calcule. La razón es muy sencilla: te permite utilizar esa misma línea de código con independencia de la longitud del texto y, por lo tanto, del número de palabras-token que contenga el texto.
Escribe ahora en la consola mensaje_frecuencias y pulsa intro para que puedas ver el resultado (el principio).
## # A tibble: 291 × 3
## palabra n relativa
## <chr> <int> <dbl>
## 1 de 37 0.0645
## 2 que 32 0.0557
## 3 la 23 0.0401
## 4 y 23 0.0401
## 5 en 14 0.0244
## 6 el 11 0.0192
## 7 las 11 0.0192
## 8 para 9 0.0157
## 9 los 8 0.0139
## 10 nos 8 0.0139
## # ℹ 281 more rowsComo puedes observar, es una tabla semejante a la que se creó con mensaje_palabras, solo que esta tiene algo más de información: la columna con la proporción de cada palabra-tipo, la llamada relativa. La marca <dbl> indica que los números están en el formato de coma flotante de doble precisión, que es algo de lo que puedes pasar, por ahora, pero si tienes curiosidad de saberlo, puedes mirarlo en Wikipedia.
3.7 Representar los datos gráficamente
3.7.1 Introducción
Para finalizar este capítulo, vas a representar gráficament el número de palabras que hay en cada oración. Ya lo has calculado y lo tienes guardado en la tabla mensaje_enunciados. Échale una nueva ojeada. Ejectua en la consola
## # A tibble: 27 × 3
## parrafo oracion NumPal
## <int> <chr> <int>
## 1 1 en estas fiestas de nochebuena y navidad en que las familias españolas acentúan su se… 40
## 2 2 el año que finaliza nos ha dejado un sello de tristeza, que ha tenido como centro la … 29
## 3 2 el testamento dirigido al pueblo español es sin duda un documento histórico que refle… 37
## 4 3 el hondo significado espiritual de estos días nos puede servir para recordar la actua… 23
## 5 4 fue un mensaje de paz, de unidad y de amor. 10
## 6 5 paz, que necesitamos para organizar nuestra convivencia. 7
## 7 5 pero que no se confunda con la mera paz material que excluye la violencia, sino tambi… 42
## 8 6 la unidad, necesaria para lograr la fortaleza que todo progreso demanda, que no elimi… 40
## 9 7 y un mensaje de amor que es la esencia de nuestro cristianismo, el cual nos exige sac… 29
## 10 8 en la alegría de esta noche no está quizá de más dejar paso a otros sentimientos; nue… 41
## # ℹ 17 more rowsComo puedes ver, tienes una tabla con tres columnas. La primera, llamada parrafo tiene el número de párrafo del texto del Mensaje de Navidad de 1975. La segunda, llamada oracion, tiene el texto de cada una de las 27 oraciones que constituyen el mensaje. La tercera columna se llama NumPal, tiene el número de palabras en cada oración. No es muy informativa, aunque puedas ver toda la tabla con esta expresión
en la que le indicas que imprima con print() la tabla mensaje_enunciados. Hasta aquí es lo mismo que ejecutar en la consola mensaje_enunciados. Lo mágico es el argumento n =. Si a la derecha del igual pones Inf, R se ocupará de imprimir todas las líneas de la tabla.
## # A tibble: 27 × 3
## parrafo oracion NumPal
## <int> <chr> <int>
## 1 1 en estas fiestas de nochebuena y navidad en que las familias españolas acentúan su se… 40
## 2 2 el año que finaliza nos ha dejado un sello de tristeza, que ha tenido como centro la … 29
## 3 2 el testamento dirigido al pueblo español es sin duda un documento histórico que refle… 37
## 4 3 el hondo significado espiritual de estos días nos puede servir para recordar la actua… 23
## 5 4 fue un mensaje de paz, de unidad y de amor. 10
## 6 5 paz, que necesitamos para organizar nuestra convivencia. 7
## 7 5 pero que no se confunda con la mera paz material que excluye la violencia, sino tambi… 42
## 8 6 la unidad, necesaria para lograr la fortaleza que todo progreso demanda, que no elimi… 40
## 9 7 y un mensaje de amor que es la esencia de nuestro cristianismo, el cual nos exige sac… 29
## 10 8 en la alegría de esta noche no está quizá de más dejar paso a otros sentimientos; nue… 41
## 11 8 que en todo hogar español reine la prosperidad y la justicia es una de las decididas … 20
## 12 9 es difícil encerrar en pocas palabras todos mis sentimientos en esta navidad. 12
## 13 9 nada me parece bastante cuando se trata de servir a nuestro pueblo. 12
## 14 9 soy consciente de las dificultades, pues muchas veces no se alcanza todo aquello que … 16
## 15 9 se necesita la ayuda de todos. 6
## 16 9 se necesita buena voluntad. 4
## 17 9 se necesita que se comprenda que hay que sacrificarse en aras de la justicia. 14
## 18 9 el egoísmo de algunos puede perjudicar a muchos. 8
## 19 10 los problemas que tenemos ante nosotros no son fáciles, pero si permanecemos unidos y… 21
## 20 10 tengo gran confianza en las nuevas generaciones, pues conozco su gran sentido de la r… 15
## 21 10 desearía que estos días meditásemos y que, dejando pequeñas diferencias, nos unamos p… 26
## 22 10 este es el reto de nuestro tiempo, esta es la primera exigencia de nuestra generación. 15
## 23 11 que el año santo, que pronto se abre en compostela, sea un año de avance y progreso p… 23
## 24 12 tenemos las bases muy firmes que nos legó una generación sacrificada y el esfuerzo ti… 19
## 25 12 hoy les dedico desde aquí un homenaje de respeto y admiración. 11
## 26 13 al felicitaros otra vez y recordar muy especialmente a los que, ausentes de la patria… 47
## 27 14 «paz a los hombres de buena voluntad». 7Sé cuidadoso con este modo de examinar la tablas, te puedes encontrar con que se imprimen varios cientos o miles de líneas. Para tablas grandes te recomiendo que utilices la función View(), en la que el argumento es el nombre de la tabla que quieres ver. Por ejemplo
Tan pronto como ejecutes esta función, en la ventana del editor se abrirá una nueva pestaña como la que ves en la figura 3.4 que te permitirá revisar con facilidad la tabla ya que te puedes desplazar hacia adelante y hacia atrás como si se tratara de una página web.
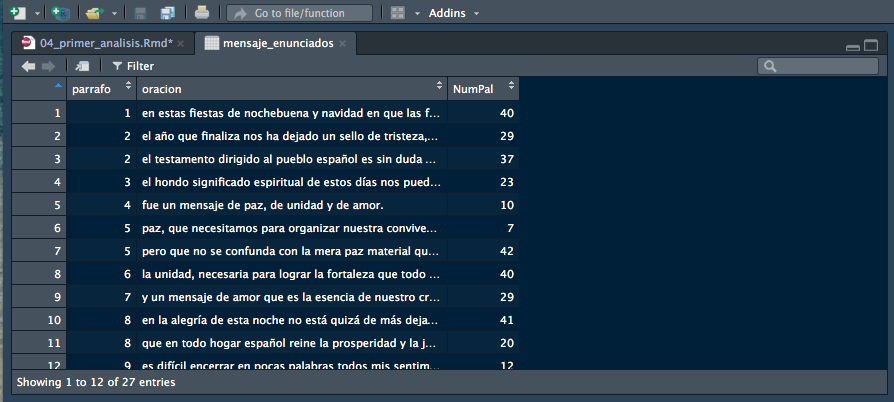
Figura 3.4: Contenido de mensaje_enunciados en el visor de RStudio
Data de la pestaña Environment obtendrás el mismo resultado.
3.7.2 La librería {ggplot2}
Revisar un tabla no suele ser muy informativo, largas lista de números son ininterpretables. La mejor manera de comunicar este tipo de resultados es con un gráfico. R tiene de serie un conjunto de funciones para dibujar gráficas, aunque son eficaces son muy poco vistosas.
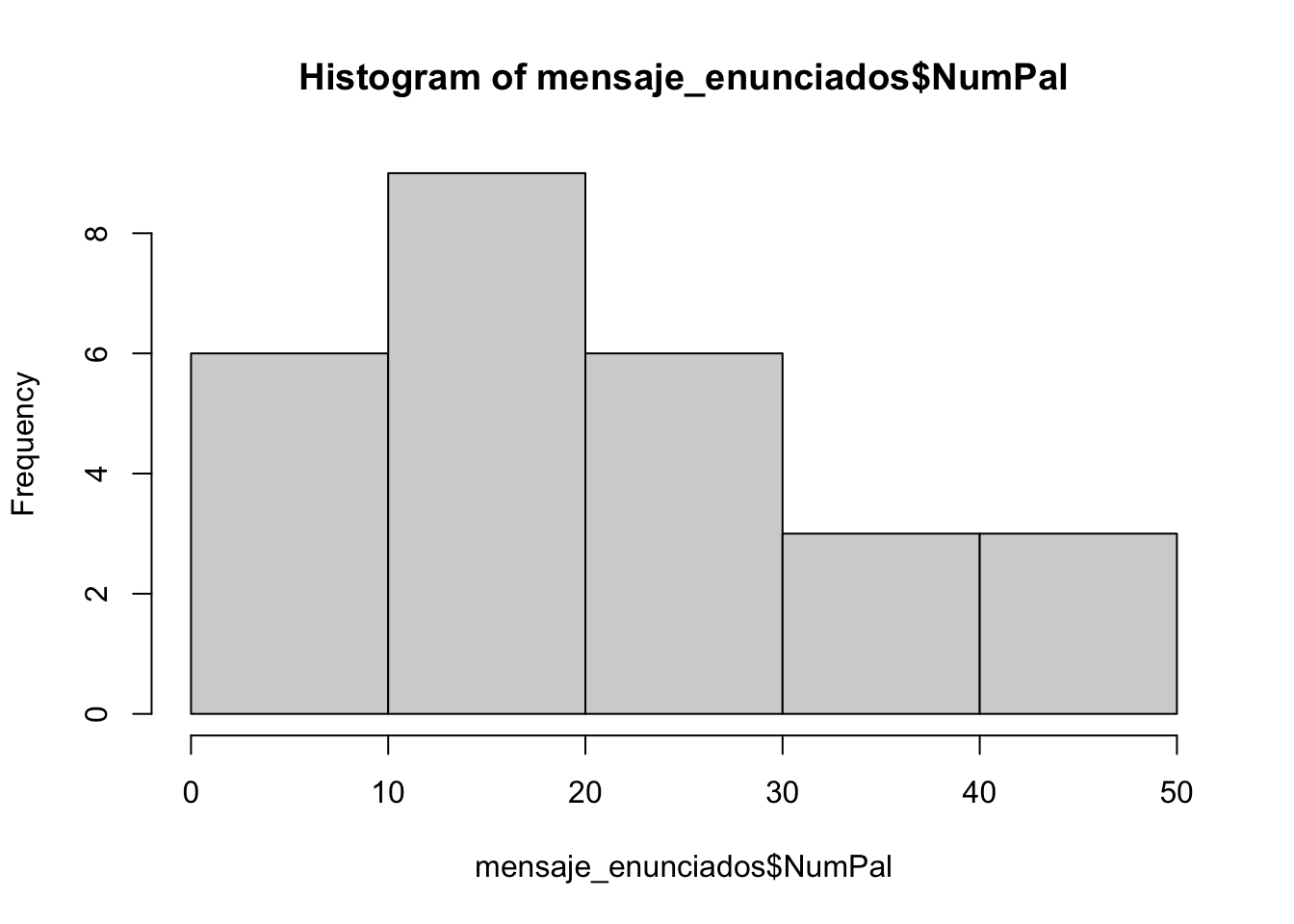
Figura 3.5: Histograma de la frecuencia (eje vertical) del número de palabras en cada oración de mensaje_enunciado
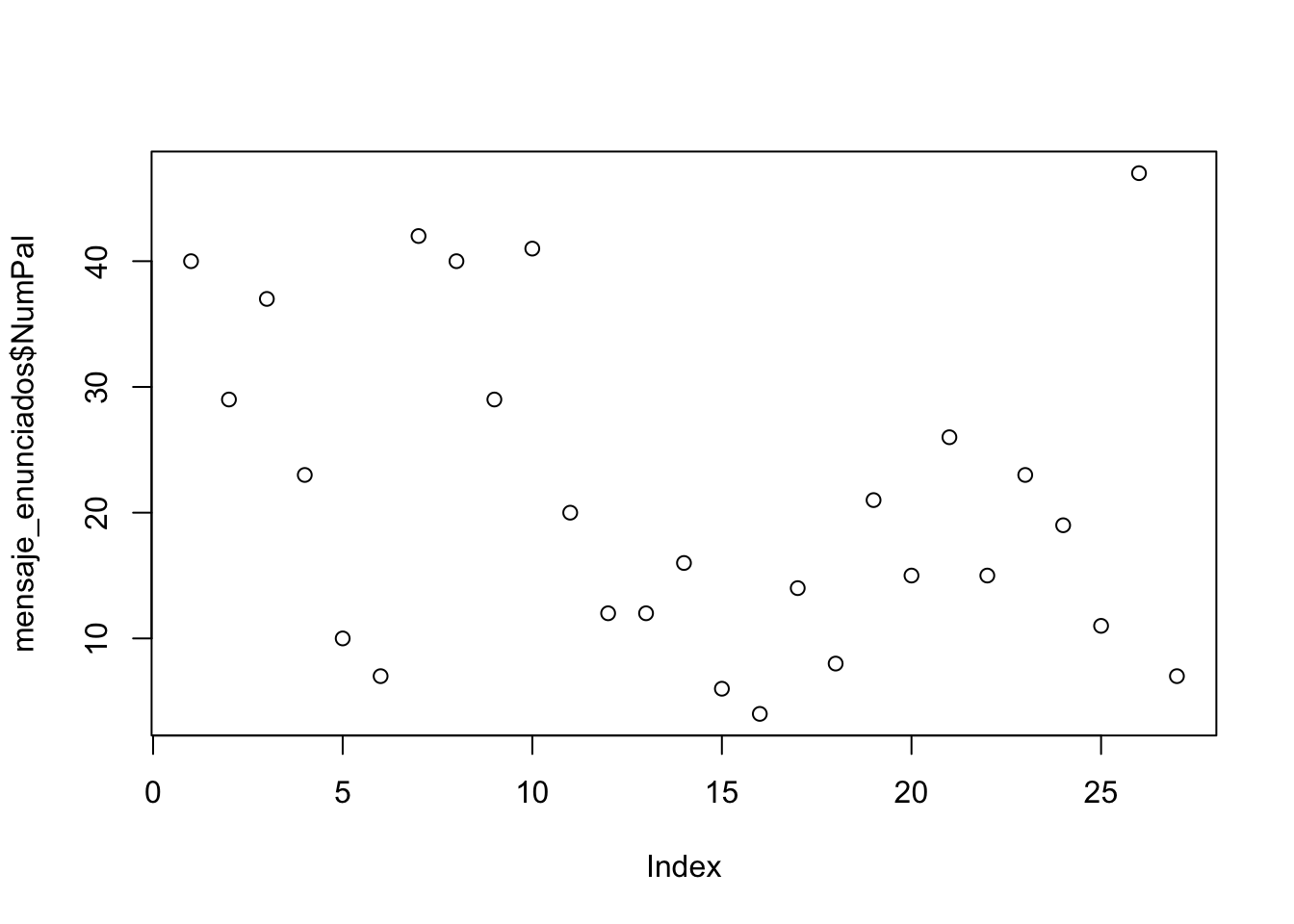
Figura 3.6: Diagrama de puntos de la frecuencia (eje vertical) del número de palabras en cada oración de mensaje_enunciado
Los gráficos de las figura 3.5 y 3.6 se han obtenido con estas dos sencillas intrucciones: hist() para el gráfico de barras o histograma y plot() para el de puntos.
El ecosistema tidydata incorpora un potentísima librería de gráficos con la que se puede dibujar todo tipo de gráficas desde un sencillo histograma o gráfico de barras como el de la figura 3.7.
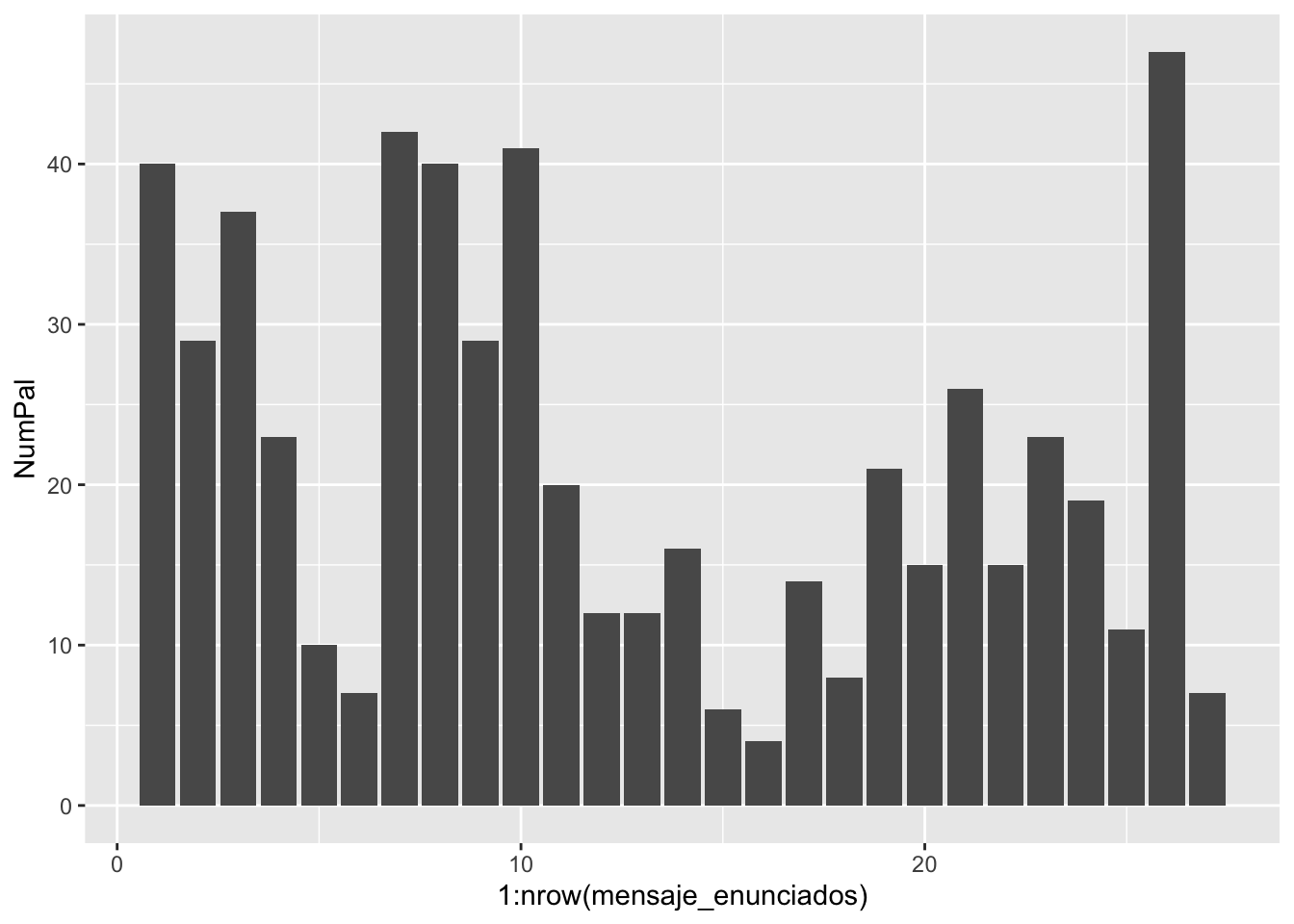
Figura 3.7: Histograma básico con ggplot
que se consigue con esta instrucción
hasta complejísimos gráficos a base de capas que irás viendo a lo largo de los siguientes capítulos.
No tienes que instalar ni cargar la librería {ggplot2}. Como te he dicho, forma parte del universo tidydata, por lo que siempre que cargues la librería {tidyverse} la tendrás a tu disposición.
Lo que le has pedido a ggplot() con la instrucción anterior es que tome los datos de mensaje_enunciados (primer argumento) y que los represente en la gráfica con la función aes() (segundo argumento). Esta necesita saber qué va en qué eje. Primero los datos del eje X y después los del Y. En el eje X (el horizontal) mostrará el número que identifica cada oración. Como puede variar de un texto a otro, tienes que decirle que ese número irá desde 1 al número total de líneas nrow() que tenga mensaje_enunciados. En el eje Y (el vertical) marcará la cantidad de palabras que tiene cada oración, información que tienes guardada en NumPal.
Pero esa primera parte de la instrucción solo dibuja el fondo del gráfico y los datos de los ejes horizontan y vertical, así como los nombres de las variables que utilizará para trazarlo, como puedes ver en la figura 3.8.
Figura 3.8: Fondo de cualquier gráfico generado con {ggplot2}
Pero aún no tiene ni idea de qué tipo de gráfico ha de dibujar. Por eso ggplot() necesita, como mínimo, otra función que se lo indique. En este caso será un gráfico de barras, lo que se expresa con la función geom_bar() que se une a la primera parte de la instrucción con un +. Así, podrás encadenar muchas características gráficas que te permitirán hacer gráficos más estéticos y visualmente atractivos.
ggplot() se pueden complicar y ser muy extensas (ya lo verás), te recomiendo que introduzcas un intro después de cada coma de cada argumento y otro intro cada vez que tengas que poner un + para añadir una nueva función de ggplot(). Esta estretegia te permitirá leer con mayor facilidad el código y corregirlo (depurarlo).
La función que se ocupa de dibujar una gráfica de barras es geom_bar() que requiere el argumento stat = 'identity'. Este lo que hace que la altura de la barras represente los valores de los datos; en este caso los valores de NumPal.
Si por el contrario hubieras preferido una gráfica de puntos (gráfico de dispersión) como el de la figura 3.9, basta con que cambies geom_bar por geom_point() que no necesita, en este caso, argumento alguno puesto que dibujará un punto en la posición correcta para cada enunciado y número de palabras.
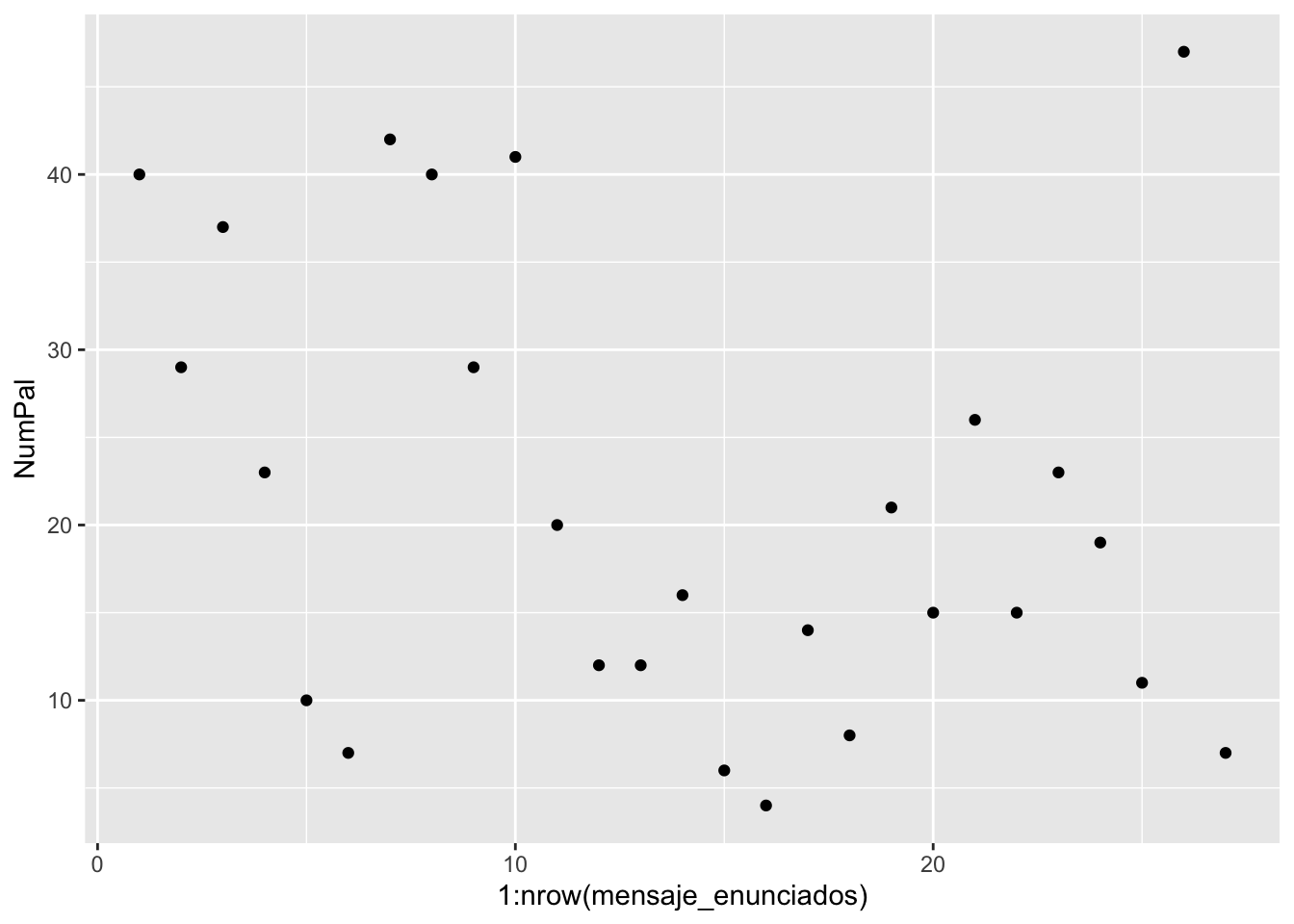
Figura 3.9: Gráfico de puntos con ggplot
Un gráfica de líneas como la de la figura 3.10, que es un poco más clara que la de puntos.
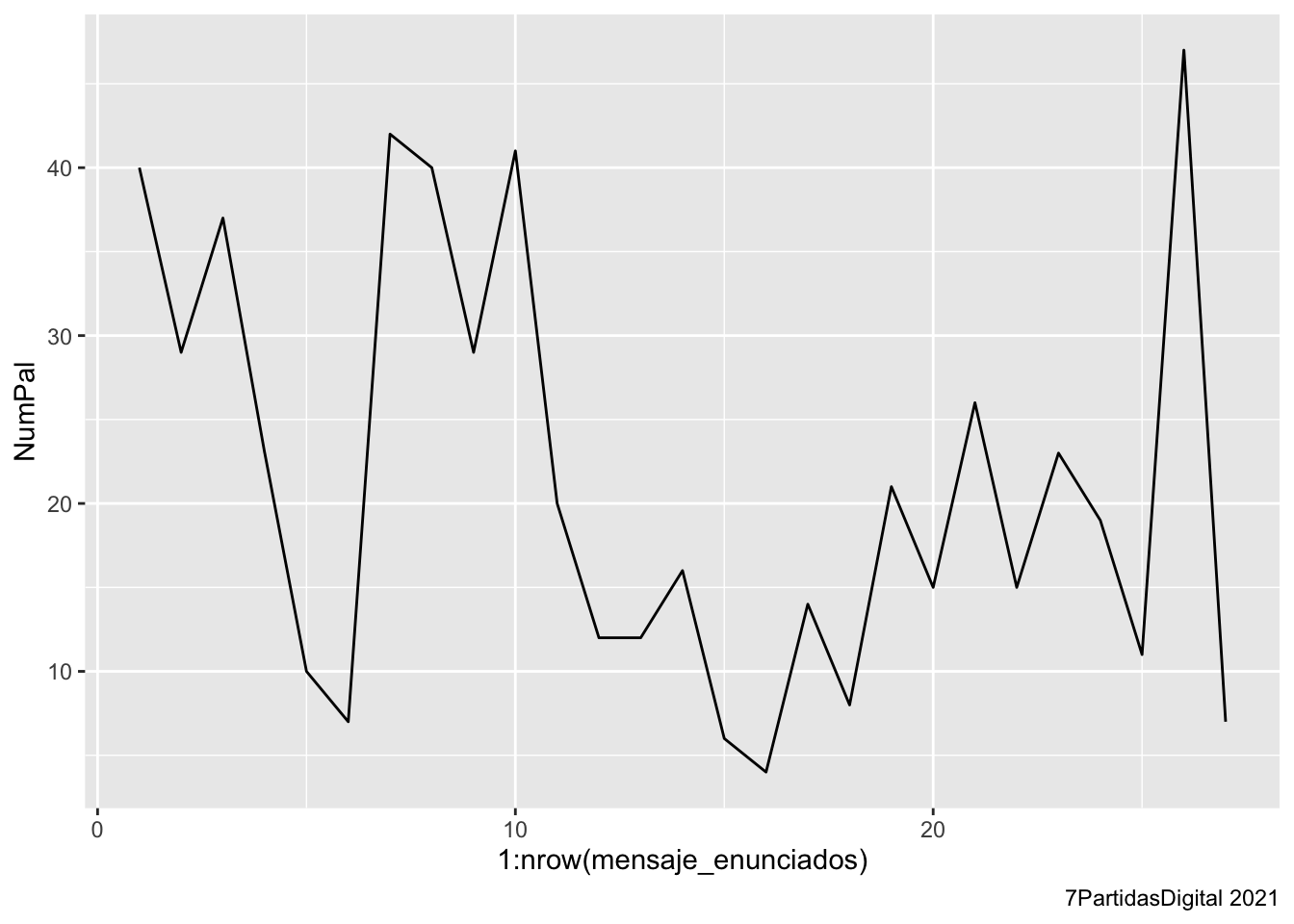
Figura 3.10: Gráfico de líneas con ggplot
Este se obtiene cambiando geom_bar() o geom_point() por geom_line(). El código para la gráfica de líneas de la figura 3.10 es
Si te fijas, la etiqueta del eje horizontal –1:nrow(mensaje_enunciados)– no es muy informativa. Se puede cambiar con la función labs() y dentro de ella indicarle cuál será el literal del eje horizontal x = "Número de oración" como puedes ver en la figura 3.11. Añade esta línea –labs(x = "Número de oración")– (acuérdate de poner un + al final de la línea anterior).
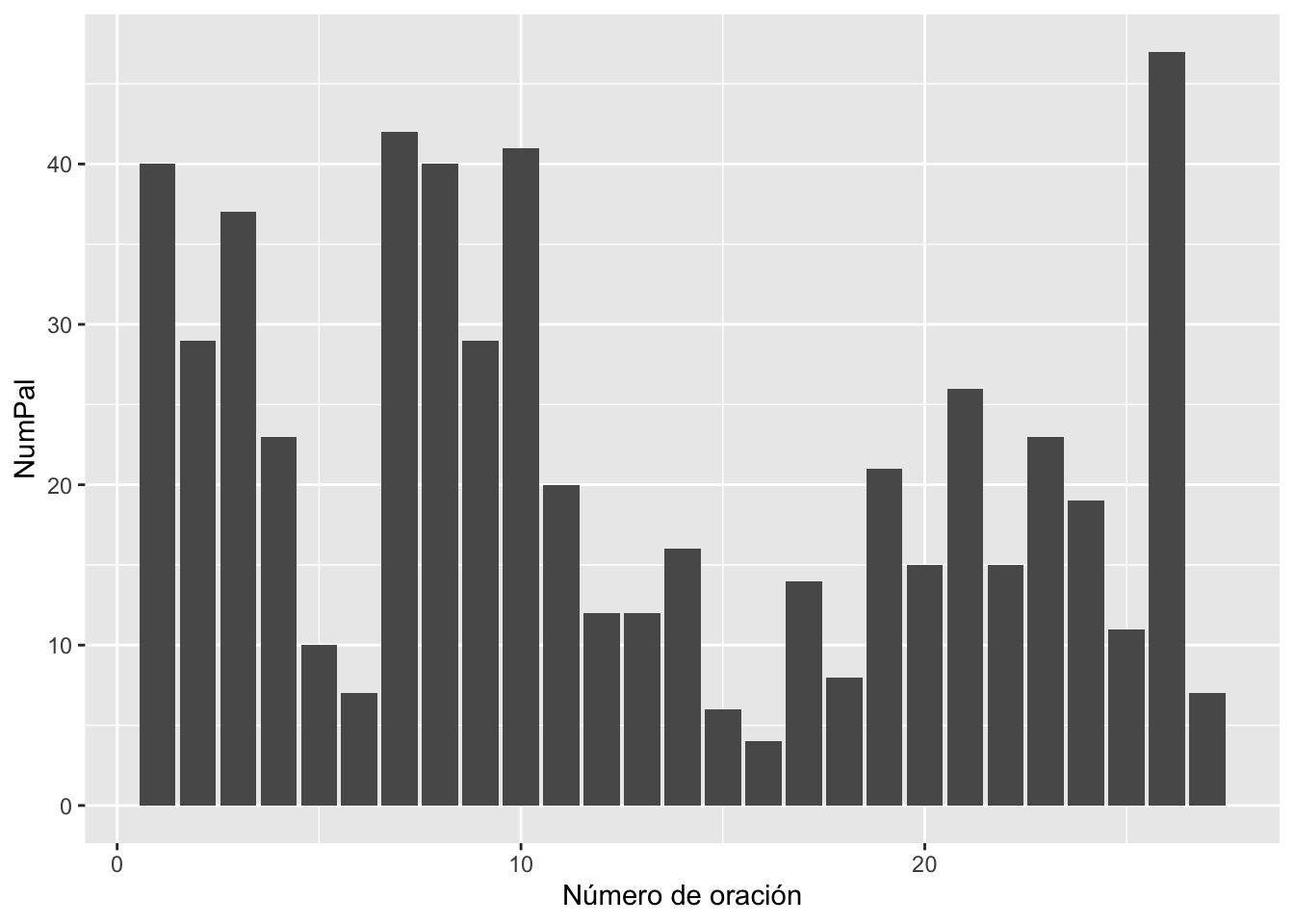
Figura 3.11: Con un nuevo literal para el eje X
Incluso le puedes poner al gráfico un título (y su correspondiente subtítulo) con la función ggtitle(). Añade esta nueva línea (acuérdate de poner un + al final de la línea anterior).
El resultado será mucho más interesante y explicativo, como puedes ver en la figura 3.12.
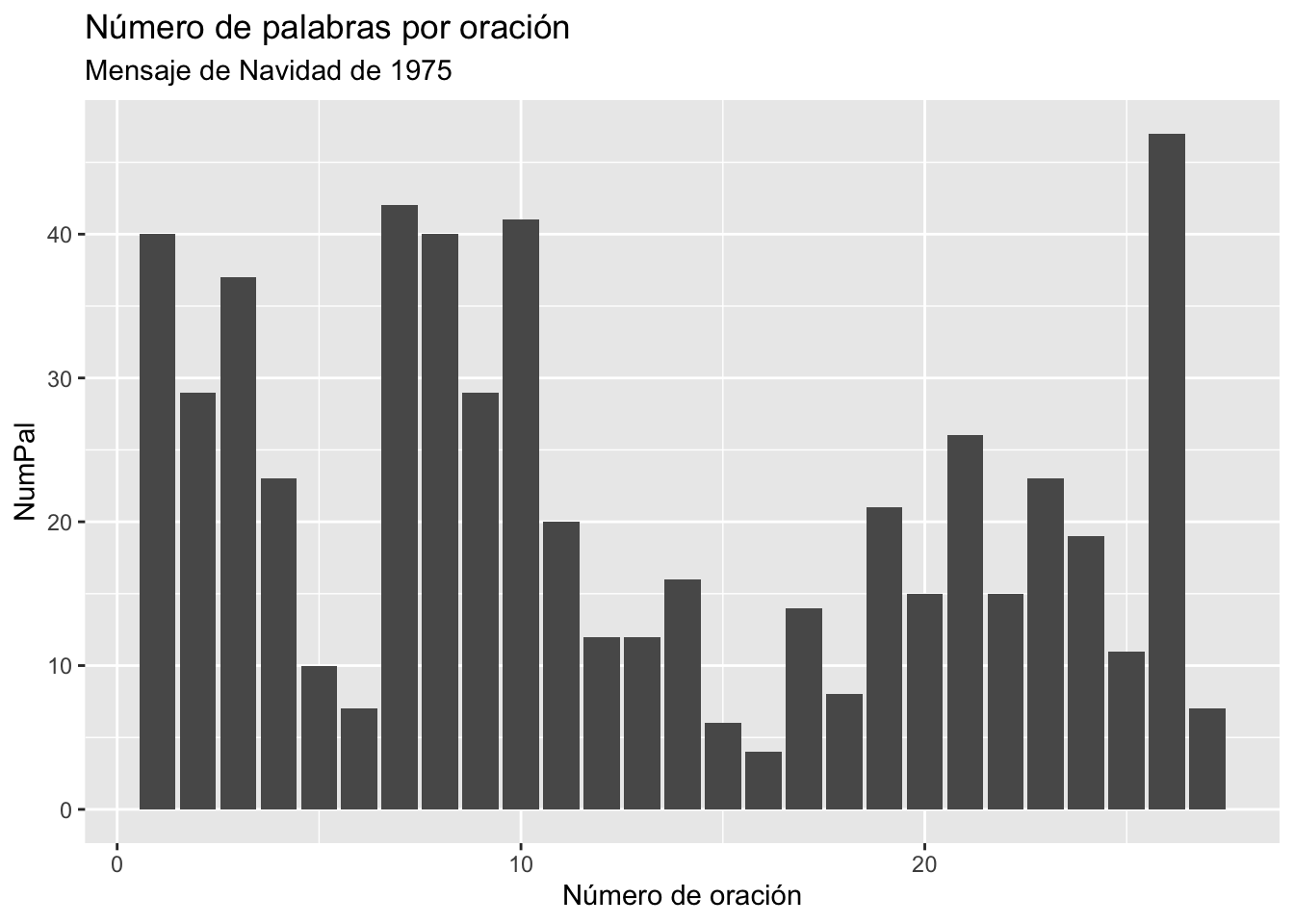
Figura 3.12: Gráfica con ggplot()con títulos y literal del eje X propios
Con unas pocas instrucciones has obtenido un gráfico bastante interesante para transmitir tus hallazgos.
3.8 Unos datos estadísticos más
Si revisas la gráfica de la figura 3.12 verás que las oraciones de este primer discurso navideño son muy variables en su longitud. Quizá te interesaría conocer algunos datos estadísticos más de los que ya sabes: frecuencia absoluta de las palabras-token, de las palabra-tipo, la frecuencia relativa de cada palabra-tipo dentro del texto, el número de letras de cada palabra e incluso el número de oraciones y palabras que tiene cada una de ellas.
Sigamos con esta última información: el número de oraciones por párrafo y el de palabras por oración, que es algo que tienes guardado en mensaje_enunciados. Ahora vas a averiguar cuántas palabras tiene la oración más larga, cuántas la más corta, cuál es la media (promedio) y la mediana de palabras por oración, una serie de datos que te hablan de las medidas de tendencia central y también de las de dispersión (ya las veremos en otro capítulo más adelante) del texto.
Todos esos datos los puedes extraer con unas pocas instrucciones de R
max(mensaje_enunciados$NumPal) # Mayor número de palabras en una oración
min(mensaje_enunciados$NumPal) # Menor número de palabras en una oración
mean(mensaje_enunciados$NumPal) # Media o promedio
median(mensaje_enunciados$NumPal) # Medianaque arrojará los siguientes resultados:
## [1] 47## [1] 4## [1] 21.25926## [1] 19Pero para extraerlo has tenido que hacerlo medida a medida. Sin embargo, puedes obtener toda esa información, y otros dos datos, los cuartiles, con la función summary().
que ofrece los resultados en una pequeña tabla.
## Min. 1st Qu. Median Mean 3rd Qu. Max.
## 4.00 11.50 19.00 21.26 29.00 47.00Acabas de averiguar que la media es de 21.2592593 palabras por oración. Pero es algo que no puedes ver con claridad en el gráfico. Con una línea más de código, puedes dibujarla en la gráfica. Es complicadilla, pero el resultado merece la pena. Cópiala inmediatamente debajo de la línea que comienza geom_bar().
geom_hline(yintercept = mean(mensaje_enunciados$NumPal),
linetype = "dashed",
colour = "red",
size = 0.4) +La función geom_hline() sirve para dibujar una línea horizontal, para lo que requiere cuatro argumentos, pero solo el primero es necesario, los otros tres son para añadir decoración a la línea.
El argumento yintercept = lo que hace es calcular a qué altura del eje vertical debe dibujar la línea y de dónde debe extraer los datos para ese cálculo. Eso es lo que se expresa a la derecha del =. Como lo que quieres es marcar la media (el promedio) y esta es una función, como has visto, que tiene R de serie –mean()–, tan solo la tienes que añadir a la derecha del =. Ahora, entre los paréntesis de mean(), tienes que indicarle a R dónde están los datos de los que ha de extraer la media. Estos se encuentras en la columna NumPal de la tabla mensaje_enunciados. Ya te he explicado cómo se le indica a R cuál es la tabla y cuál es la columna, con lo que el primer argumento es yintercept = mean(mensaje_enunciados$NumPal).
Los otros tres son de decoración. Si no los usaras, la media se marcaría con una línea negra como puedes ver en la figura 3.13.
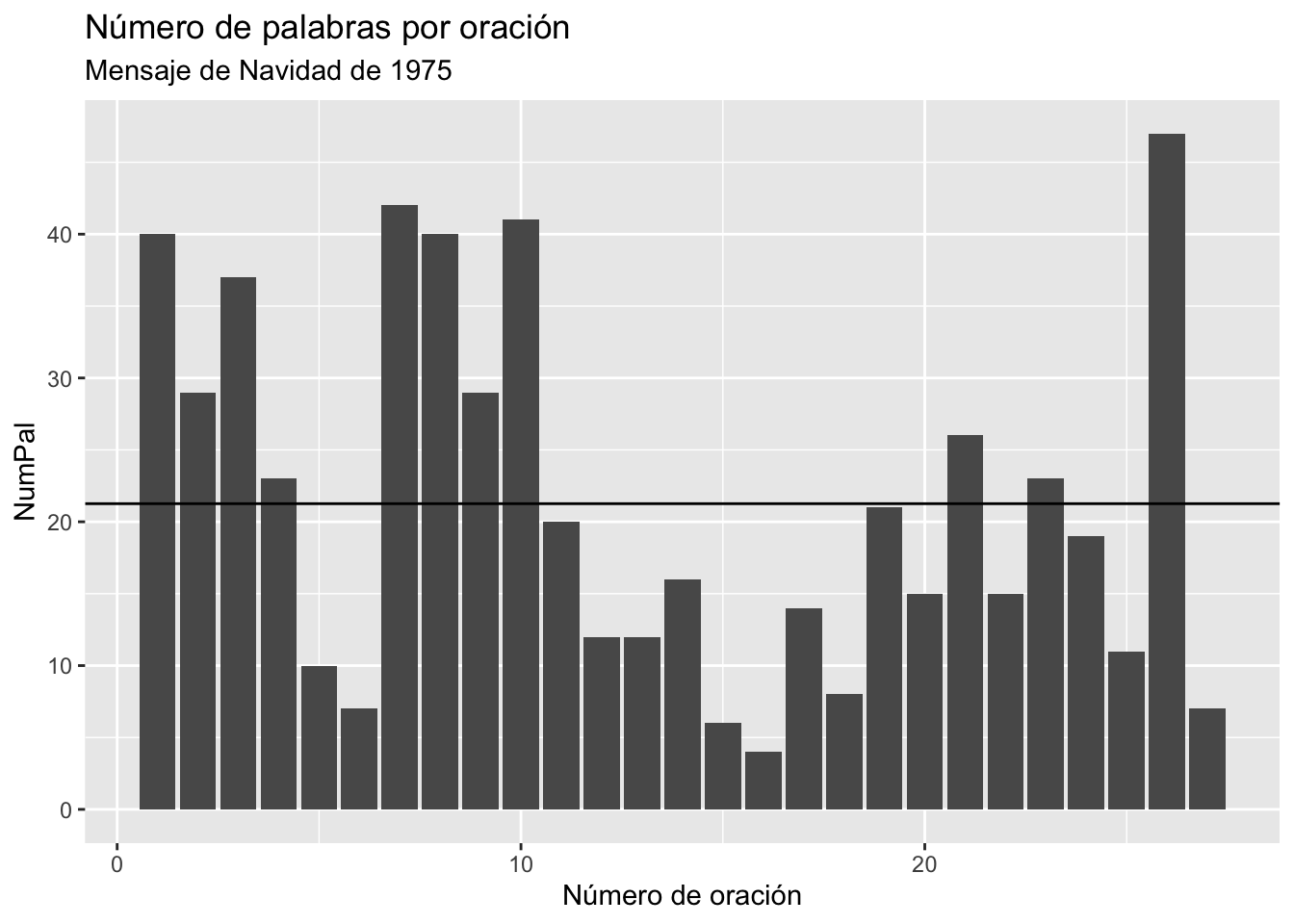
Figura 3.13: Trazado de la media con una línea negra
Quizá sea suficiente, pero nos gusta decorar un poco las cosas para hacerlas más atractivas e informativas. Así, el argumento linetype = sirve para seleccionar el diseño de la línea. Tienes siete tipos posibles: twodash, solid, longdash, dotted, dotdash, dashed y blank, que se han de indicar encerrados entre comillas. Puedes ver cómo se representan en la figura 3.14.
Figura 3.14: Tipos de línea (linetype) en ggplot
En vez de utilizar los nombres entrecomillados puedes usar el número que hay al comienzo de cada tipo de línea, pero eso te obligaría a sabértelos de memoria.

Figura 3.15: Nombre de colores en R
El argumento colour = "" es para seleccionar el color. R tiene una amplísima paleta. Puedes usar los nombres más usuales de los colores en inglés, pero si quieres algo más exótico aquí tienes en la figura 3.15 tienes un buen catálogo con el que jugar. El último argumento, size =, indica el grosor que ha de tener la línea. Como puedes ver no es muy complicado… o quizá sí.
El resultado es el de la figura 3.16
## Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
## ℹ Please use `linewidth` instead.
## This warning is displayed once every 8 hours.
## Call `lifecycle::last_lifecycle_warnings()` to see where this warning was generated.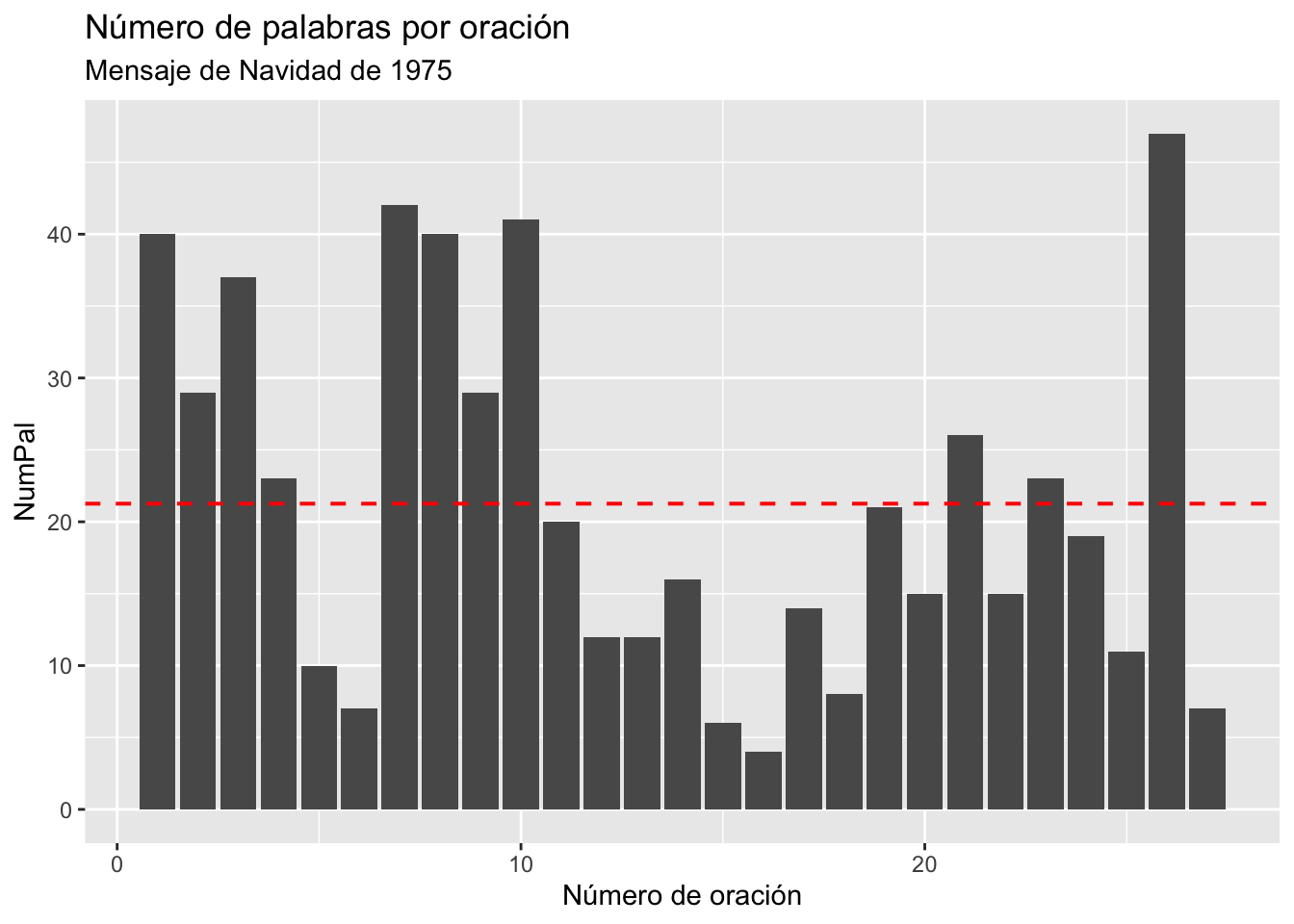
Figura 3.16: Gráfica con todos los elementos
El código completo para dibujar la gráfica de la figura 3.16 es
ggplot(mensaje_enunciados,
aes(1:nrow(mensaje_enunciados),
NumPal)) +
geom_bar(stat = 'identity') +
geom_hline(yintercept = mean(mensaje_enunciados$NumPal),
linetype = "dashed",
colour = "red",
size = 0.7) +
labs(x = "Número de oración") +
ggtitle("Número de palabras por oración",
subtitle = "Mensaje de Navidad de 1975")median). Es decir, del valor central del número de palabras por oración que ofrece el mensaje de 1975. El aspecto final tiene que ser el de la figura 3.17 que hay inmediatamente debajo de esta propuesta. También puedes cambiar y jugar con los colores.
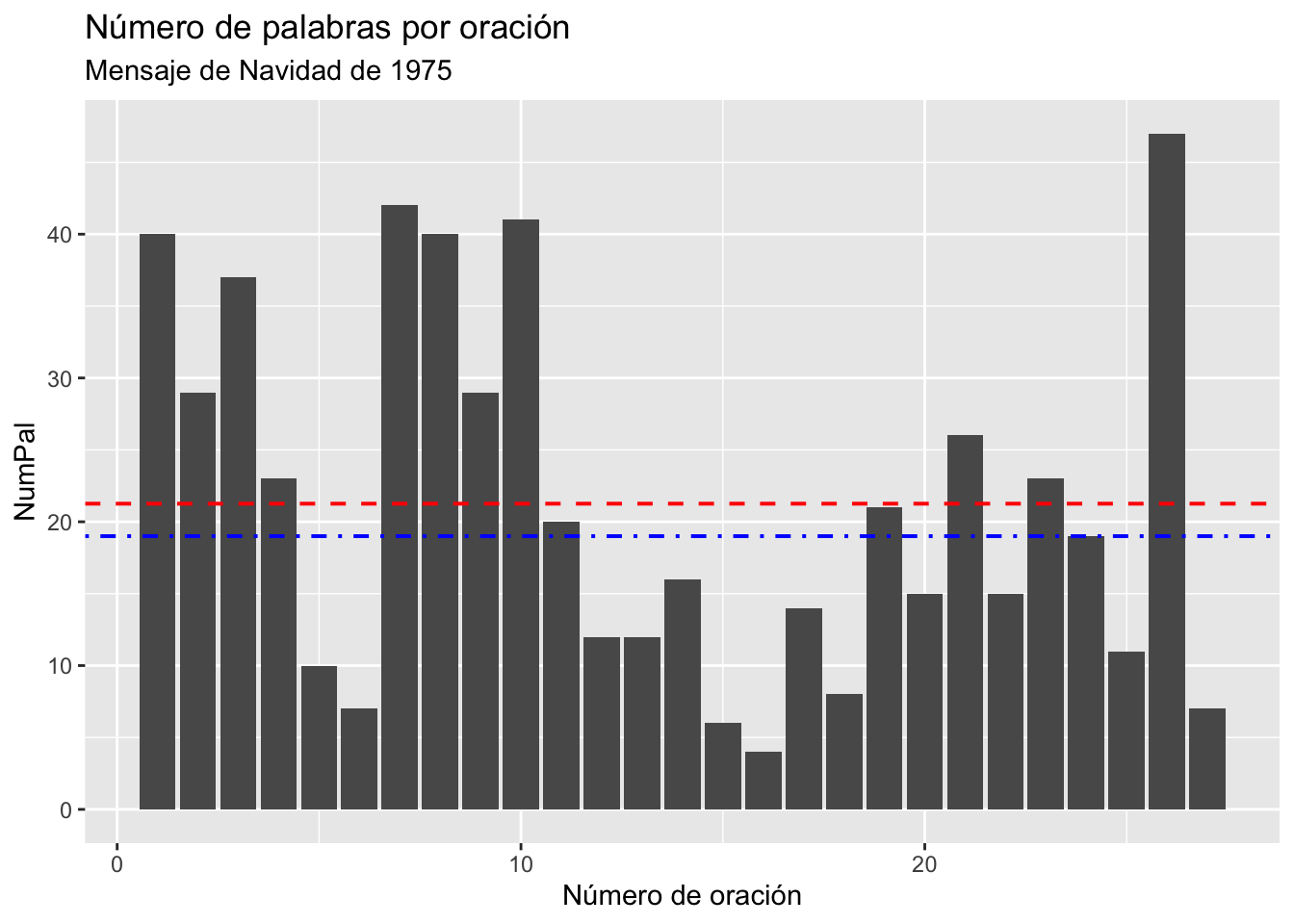
Figura 3.17: Resultado que debes obtener
3.9 Sobre la media, la mediana y la moda
A lo largo de este libro usaré muchos términos matemáticos y estadísticos que es posible que tengas un poco olvidados. Te los iré refrescando de vez en cuando. En este capítulo he hablado de frecuencias absolutas, frecuencias relativas, media y mediana. Te recuerdo que son la media y la mediana y también otro estadístico: la moda.
Considera el primer enunciado de El Capitán Alatriste de Pérez Reverte:
No era el hombre más honesto ni el más piadoso, pero era un hombre valiente.
Ya viste que tiene 15 palabras-token y 11 palabras-tipo. Ahora contaremos las letras que tiene cada palabra. El resultado lo tienes en la tabla 3.3.
| palabras | No | era | el | hombre | más | honesto | ni | el | más | piadoso, | pero | era | un | hombre | valiente |
| letras | 2 | 3 | 2 | 6 | 3 | 7 | 2 | 2 | 3 | 8 | 4 | 3 | 2 | 6 | 8 |
3.9.1 Media
La media, también conocida como promedio, es el resultado de la suma de todos los valores dividida por el número de casos que constituyen el conjunto:
\[\frac{suma de todos los valores}{número de casos}\]
es este caso se trata de la suma del número de letras de cada palabra dividida por el número de palabras que constituyen la frase:
\[\frac{2 + 3 + 2 + 6 + 3 + 7 + 2 + 2 + 3 + 7 + 4 + 3 + 2 + 6 + 8}{15} = \frac{60}{15} = 4 \]
Por lo tanto la media es de 4 letras por palabra.
3.9.2 Mediana
La mediana es el valor medio de la serie. Para calcularlo, lo mejor es ordenar los valores de menor a mayor.
Una vez ordenados, tienes que averiguar cuál es el valor que se encuentra justo en la mitad de la serie. Puesto que tienes 15 palabras, un número impar de elementos, la mediana será el valor situado en la octava posición, que es la que está justo en el centro porque habrá siete observaciones a la izquierda y otras tantas a la derecha.
| Mitad (50 %) inferior | Mediana | Mitad (50 %) superior | |
|---|---|---|---|
| orden | 1 2 3 4 5 6 7 | 8 | 9 10 11 12 13 14 15 |
| valor | 2 2 2 2 2 3 3 | 3 | 3 4 6 6 7 7 8 |
Por lo tanto, la mediana es 3. No tienen por qué coincidir media y mediana.
La cosa se complica, ligeramente, cuando el número de observaciones es par porque no existe una posición media exacta. En este caso, la mediana es el resultado de calcular la media de los dos valores que se encuentren en las dos posiciones centrales.
Considera este caso en el que tienes doce valores ordenados de menor a mayor.
| Mitad (50 %) inferior | Mediana | Mitad (50 %) superior | |
|---|---|---|---|
| orden | 1 2 3 4 5 | 6 7 | 8 9 10 11 12 |
| valor | 1 2 2 2 3 | 3 4 | 6 6 8 9 9 |
Observa que en las posiciones centrales, la sexta y la séptima, se hallan los valores 3 y 4. Para calcular la mediana lo que tienes que hacer es sumar ambos valores y dividirlos entre dos:
\[\frac{3+4}{2} = 3.5\]
Así, pues, la mediana es 3.5.
3.9.3 Moda
La moda es el valor que tiene el mayor número de ocurrencias. Es tan sencillo como contar cuántas palabras hay de cada longitud (volvemos a Alatriste).
| longitud | 2 | 3 | 4 | 6 | 7 | 8 |
| ocurrencias | 5 | 4 | 1 | 2 | 2 | 1 |
Puesto que las palabras de dos letras son las que más veces ocurren, 5 casos, la moda es 2.
Estos son los tres estadísticos más básicos de las llamadas medidas de tendencia central, es decir, aquellas que pretenden resumir en un solo valor un conjunto de valores, por lo que representan un centro en torno al cual se encuentra ubicado un conjunto de datos.
