8 Colocación, coocurrencia y redes léxicas
8.1 Introducción
A lo largo de los capítulos anteriores has estado manejando palabras individuales, en unos casos como palabras gráficas, por lo que no era posible distinguir entre las diferentes categorías de una palabra como bajo, que puede ser sustantivo, adjetivo, verbo y preposición, aunque es un problema que aprendiste a resolver en el capítulo De las palabras a las clases de palabras, cuando te introduje en el etiquetado morfológico automatizado. Ya sabes cómo hacerlo con la librería {udpipe}. Pero siguen siendo palabras aisladas, y ninguna palabra significada nada si no está rodeada de otras, o aplicando el principio de Firth (1957: 6) «conocerás una palabra por sus compañeras». Esto último es la base teórica del análisis de colocaciones: el significado de una palabra se basa en el significado de las palabras que la flanquean, puesto que las palabras tienen sus preferencias y suelen elegir como compañeras otras con las que forman combinaciones frecuentes. Así, loncha, en el sentido de porción de algo, solo se puede usar con jamón, chorizo, queso y tocino pero no decimos, al menos en España, una loncha de pan sino una rebanada y esta no la usamos con jamón, chorizo, queso o tocino8.
El otro concepto que surgió de las investigaciones de la lingüística de corpus es el de coocurrencia: palabras que coaparecen a una cierta distancia. Mientras que constitución española o Unión Europea son un bigrama y una colocación, pues podemos encontrar estas dos palabras exactamente así en los textos), regiones y ciudades tienden a coocurrir juntas sin un orden exacto estable (figura 8.1).
 (1980-2001)](imagenes/08-Bigramas.jpg)
Figura 8.1: Figura 1. Coocurrencia de ciudades y regiones en el CREA (1980-2001)
Para ver cuán a menudo la palabra X sigue a la palabra Y, o si A y B coocurren en un texto y en qué constelaciones o redes de palabras conforman, bien en una obra, bien en un autor, bien en un corpus y analizar cuáles son las preferencias, R puede ser de gran ayuda.
8.2 Análisis de n-gram
Ya sabes cómo dividir un texto en palabras individuales con la función unnest_tokens(), incluso la usaste al principio para dividir el texto en oraciones (véase Primer análisis de texto). Ahora lo vas a dividir en n-grams, es decir, en combinaciones de n palabras. Algo sencillo de hacer en R.
8.2.1 Preparar el entorno
Como de costumbre, si has estado jugando con RStudio, asegúrate de que no hay nada extraño. Cierra RStudio e inicia una nueva sesión. A continuación carga las librería básicas.
Recuerda que cuando se llama a la libería {tidyverse} aparece un mensaje que informa de los paquetes que lo conforman y avisa de que hay unos pequeños conflictos. No tienes de qué preocuparte.
Ahora, copia este fragmento de código.
ficheros <- list.files(path ="datos/mensajes", pattern = "\\d+")
anno <- as.character(c(1975:2023))
rey <- c(rep("Juan Carlos I", 39),rep("Felipe VI", 10))
mensajes <- tibble(anno = character(),
rey = character(),
parrafo = numeric(),
texto = character())
for (i in 1:length(ficheros)){
discurso <- readLines(paste("datos/mensajes",
ficheros[i],
sep = "/"))
temporal <- tibble(anno = anno[i],
rey = rey[i],
parrafo = seq_along(discurso),
texto = discurso)
mensajes <- bind_rows(mensajes, temporal)
}
mensajes$rey <- factor(mensajes$rey, levels = c("Juan Carlos I", "Felipe VI"))
mensajes$anno <- factor(mensajes$anno)Es un viejo conocido que te permitirá tener en la memoria del ordenador todos los textos en una única tabla.
Lo siguiente es cargar el fichero de palabras vacías para eliminar, en el momento que sea necesario, aquellas palabras de alta frecuencia, pero nulo rendimiento.
vacias <- read_tsv("https://raw.githubusercontent.com/7PartidasDigital/AnaText/master/datos/diccionarios/vacias.txt",
locale = default_locale())## Rows: 465 Columns: 1
## ── Column specification ────────────────────────────────────────────────────────────────────────────────
## Delimiter: "\t"
## chr (1): palabra
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.El aviso que ha aparecido en la consola te informa de que todo se ha guardado en una columna (variable) llamada palabra y que el tipo de datos es caracteres.
Por último, borras, para mayor claridad, los objetos que se han creado para construir la tabla que contiene el texto.
En Environment solo deben estar los objetos mensajes y vacias. Con lo que ya puedes continuar puesto que tienes el material disponible.
8.3 Dividir en n-gram
Dividir en bigramas o trigramas el texto de los mensajes de Navidad es sencillo con la función unnest_tokens(). Hasta ahora solo te habías preocupado de los unigramas, es decir, de dividirlo en palabras gráficas, una tras otra con
lo que daba como resultado una tabla como esta
## # A tibble: 65,362 × 4
## anno rey parrafo palabra
## <fct> <fct> <dbl> <chr>
## 1 1975 Juan Carlos I 1 en
## 2 1975 Juan Carlos I 1 estas
## 3 1975 Juan Carlos I 1 fiestas
## 4 1975 Juan Carlos I 1 de
## 5 1975 Juan Carlos I 1 nochebuena
## 6 1975 Juan Carlos I 1 y
## 7 1975 Juan Carlos I 1 navidad
## 8 1975 Juan Carlos I 1 en
## 9 1975 Juan Carlos I 1 que
## 10 1975 Juan Carlos I 1 las
## # ℹ 65,352 more rowsDividirlo en bigramas, o trigramas (o cuantas palabras quieras que constituya el n-grama), requiere dos argumentos más: token = y n =. token indica cómo lo dividirás (ya lo viste con "sentences", y hasta ahora no empleaste el argumento token porque por defecto usa "words"), en esta ocasión lo harás con "ngrams", pero tienes que indicarle cuántos elementos constituirán cada n-gram, y eso es la tarea del argumento n (2 para bigramas, 3 para trigramas, etc.).
El resultado de lo anterior es
## # A tibble: 63,867 × 4
## anno rey parrafo bigrama
## <fct> <fct> <dbl> <chr>
## 1 1975 Juan Carlos I 1 en estas
## 2 1975 Juan Carlos I 1 estas fiestas
## 3 1975 Juan Carlos I 1 fiestas de
## 4 1975 Juan Carlos I 1 de nochebuena
## 5 1975 Juan Carlos I 1 nochebuena y
## 6 1975 Juan Carlos I 1 y navidad
## 7 1975 Juan Carlos I 1 navidad en
## 8 1975 Juan Carlos I 1 en que
## 9 1975 Juan Carlos I 1 que las
## 10 1975 Juan Carlos I 1 las familias
## # ℹ 63,857 more rowsSi en vez de n = 2 hubieras puesto n = 3 el resultado habría sido
## # A tibble: 62,407 × 4
## anno rey parrafo bigrama
## <fct> <fct> <dbl> <chr>
## 1 1975 Juan Carlos I 1 en estas fiestas
## 2 1975 Juan Carlos I 1 estas fiestas de
## 3 1975 Juan Carlos I 1 fiestas de nochebuena
## 4 1975 Juan Carlos I 1 de nochebuena y
## 5 1975 Juan Carlos I 1 nochebuena y navidad
## 6 1975 Juan Carlos I 1 y navidad en
## 7 1975 Juan Carlos I 1 navidad en que
## 8 1975 Juan Carlos I 1 en que las
## 9 1975 Juan Carlos I 1 que las familias
## 10 1975 Juan Carlos I 1 las familias españolas
## # ℹ 62,397 more rowsFíjate en los resultados. Las palabras se repiten de un grupo a otro: en estas, estas fiestas, fiestas de, etc. Esto lo has hecho para todo el corpus de los mensajes de Navidad. Ya conoces la forma de averiguar cuáles eran los unigramas más frecuentes, lo conseguías con la función count(). Para contabilizar los n-gram tienes que emplear la misma función. Pero repite la división en bigramas y guarda los resultados en mensajes_bigramas.
Contarlos y ponerlos en orden decreciente se consigue con
lo que te dará como resultado
## # A tibble: 31,304 × 2
## bigrama n
## <chr> <int>
## 1 de la 468
## 2 en el 298
## 3 en la 266
## 4 de los 228
## 5 a la 206
## 6 a los 201
## 7 y de 200
## 8 y la 198
## 9 los españoles 172
## 10 que nos 156
## # ℹ 31,294 more rows8.4 Borrar palabras vacías en un bigrama
Como de costumbre, no es muy informativo el resultado. De nuevo las palabras gramaticales, preposiciones, determinantes y conjunciones están en cabeza. Solo hay una palabra semántica, españoles, por lo demás esperable ya que es un mensaje que se dirige a todos los españoles. Podrías estar tentado en recurrir a la función anti_join() para borrar las palabras vacías. Sin embargo, no puedes hacerlo directamente puesto que en la lista de palabras vacías que has cargado (vacias) solo tienes palabras sencillas (unigramas), no tienes bigramas, que es lo que hay en mensajes_bigramas, con lo que el sistema no funcionaría.
8.4.1 Separar los bigramas
Como de costumbre, R tiene una solución: separar los constituyentes de los bigramas y borrar todos los elementos que consideres vacíos. Aunque lo puedes poner todo en una sola orden, voy a presentártelo en varios pasos para que veas el procedimiento y su lógica.
En primer lugar, separarás los dos elementos con la función separate() y el resultado lo guardarás en una nueva tabla que llamarás bigramas_separados.
Lo que has hecho ha sido decirle que los bigramas que hay enmensajes_bigramas los divida en dos nuevas columnas (variables) que se llamarán palabra1 y palabra2 y que el elemento que indica cuál es la frontera entre ambos componentes, que se indica con el argumento sep =, es un espacio en blanco (deja un espacio en blanco entre las comillas). Si ahora escribes en la consola bigramas_separados y pulsas intro, deberás obtener una tabla como esta
## # A tibble: 63,867 × 5
## anno rey parrafo palabra1 palabra2
## <fct> <fct> <dbl> <chr> <chr>
## 1 1975 Juan Carlos I 1 en estas
## 2 1975 Juan Carlos I 1 estas fiestas
## 3 1975 Juan Carlos I 1 fiestas de
## 4 1975 Juan Carlos I 1 de nochebuena
## 5 1975 Juan Carlos I 1 nochebuena y
## 6 1975 Juan Carlos I 1 y navidad
## 7 1975 Juan Carlos I 1 navidad en
## 8 1975 Juan Carlos I 1 en que
## 9 1975 Juan Carlos I 1 que las
## 10 1975 Juan Carlos I 1 las familias
## # ℹ 63,857 more rowsque tiene dos columnas (variables) llamadas palabra1 y palabra2 y cada una de ellas contiene una de las dos pieza de cada bigrama. Si lees las palabras de la columna palabra1 verás que sigues teniendo el texto de los mensajes. En palabra2 también lo tienes, pero le falta la primera palabra.
8.4.2 Borrar las palabras vacías con %in%
En el siguiente paso, borrarás todas las palabras vacías, pero tampoco harás uso de la función anti_join() que has utilizado con anterioridad. Vas a usar una técnica diferente. Le vas a pedir que extraiga con %in% de bigramas_separados todas aquellas palabras, tanto de la columna palabra1 como de palabra2, que no estén –!– en vacias$palabra (es decir, en la columna llamada palabra de la tabla vacias) y que las guarde en bigramas_filtrados.
bigramas_filtrados <- bigramas_separados %>%
filter(!palabra1 %in% vacias$palabra,
!palabra2 %in% vacias$palabra)%in% es un operador lógico que se utiliza para identificar (o comprobar) si en un elemento del vector que hay a la izquierda del operador se encuentra dentro del vector situado a la derecha. Considera que tienes este vector
a <- c("mañana", "tarde", "noche")
y quieres comprobar si en él está el término mediodía interrogas a R con
"día" %in% a
Responderá
[1] FALSE
Mientras que si le preguntas
"tarde" %in% a
la respuesta será
[1] TRUE
puesto que tarde es uno de los elemetos de a.
%in% será siempre TRUE o FALSE, con lo que es un operador muy interesante en las condiciones.
Ahora puedes comprobar el resultado, de las diez más frecuentes.
Al ejecutar la orden anterior, se debe imprimir en la consola un resultado idéntico a este
## # A tibble: 6,980 × 3
## palabra1 palabra2 n
## <chr> <chr> <int>
## 1 buenas noches 46
## 2 unión europea 31
## 3 mejores deseos 24
## 4 crisis económica 22
## 5 sociedad española 22
## 6 pueblo español 19
## 7 año nuevo 17
## 8 feliz navidad 17
## 9 convivencia democrática 13
## 10 debemos seguir 13
## # ℹ 6,970 more rowsEsos diez primeros bigramas ya son una poderosa pista acerca del contenido de los mensajes. De acuerdo, partías de la base de que se trataba de unos discursos políticos que se emiten en la noche de la víspera de Navidad y que la referencia al año nuevo es obligatoria. Podrías borrar, en una segunda pasada, como hiciste con los nombres propios de la novela Los Pazos de Ulloa, aquellas palabras que son de poca o nula información debido a que son altamente esperables y, por tanto, poco informativas. Borra todo lo referente a la época en la que se pronuncian los discursos de Navidad.
bigramas_filtrados <- bigramas_filtrados %>%
filter(!palabra1 %in% c("año", "feliz", "navidad", "buenas", "noches", "nuevo", "mejores", "deseos"),
!palabra2 %in% c("año", "feliz", "navidad", "buenas", "noches", "nuevo", "mejores", "deseos"))Ahora podrías presentar en un gráfico de barras como el de la figura 8.2.
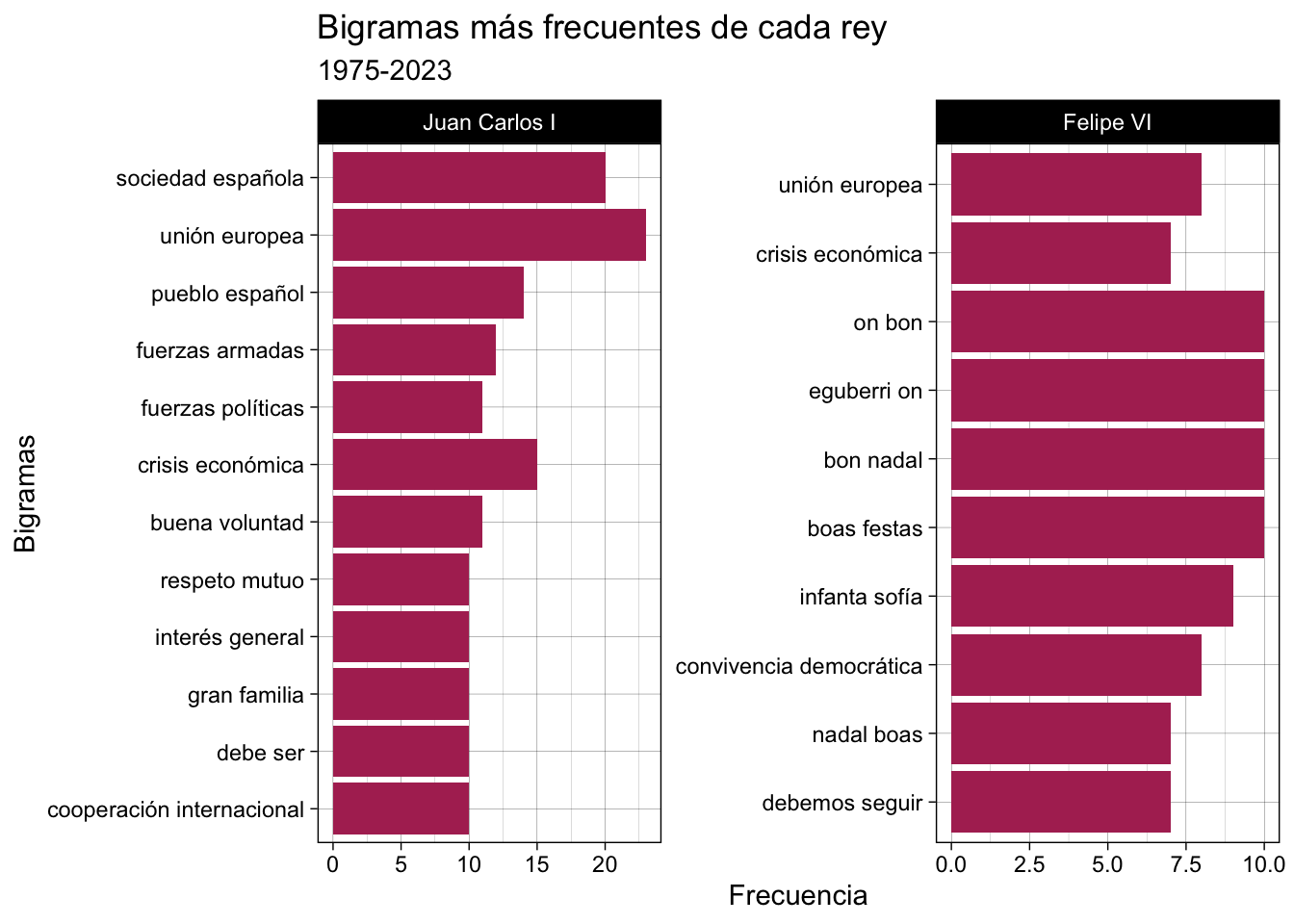
Figura 8.2: Bigramas más frecuentes de cada rey
Pero para conseguirlo tienes que reunir de nuevo los dos elementos de cada bigrama. Si antes usaste separate() para separar los dos elementos, en esta ocasión usarás unite() para reunirlos. Es una obviedad…
y a continuación le pides que los recuente con
lo que te dará como resultado una tabla como esta
## # A tibble: 7,086 × 3
## rey bigrama n
## <fct> <chr> <int>
## 1 Juan Carlos I unión europea 23
## 2 Juan Carlos I sociedad española 20
## 3 Juan Carlos I crisis económica 15
## 4 Juan Carlos I pueblo español 14
## 5 Juan Carlos I fuerzas armadas 12
## 6 Juan Carlos I buena voluntad 11
## 7 Juan Carlos I fuerzas políticas 11
## 8 Juan Carlos I cooperación internacional 10
## 9 Juan Carlos I debe ser 10
## 10 Juan Carlos I gran familia 10
## # ℹ 7,076 more rowsEs semejante, pero no idéntica, a la que obtuviste un poco antes. Fíjate que aquella tiene tres columnas palabra1, palabra2 y n, mientras que en esta ocasión tan solo tienes dos, bigrama y n, con lo que tratar los datos será un poco más sencillo porque solo tienes una variable categórica bigrama y otra continua n.
El código para obtener la gráfica de la figura 8.2 es el que hay a continuación. No creo que sea necesario explicar qué hace en cada paso. Ya lo has visto en varias ocasiones.
bigramas_unidos %>%
count(rey, bigrama, sort = T) %>%
group_by(rey) %>%
top_n(10) %>%
ggplot() +
geom_col(aes(y = n , x = reorder(bigrama,n)),
fill = "maroon") +
coord_flip() +
facet_wrap(~ rey, ncol = 2, scales = "free") +
theme_linedraw() +
labs(x = "Bigramas", y = "Frecuencia") +
ggtitle("Bigramas más frecuentes de cada rey", subtitle = "1975-2023")8.5 n-gram como redes
En las secciones anteriores has extraído los bigramas más frecuentes del corpus con el que estás trabajando, pero a veces es más interesante observar las múltiples relaciones que existen entre las palabras que constituyen un corpus. La mejor manera de hacerlo es por medio de un grafo como el de la figura 8.3 que corresponde a la Biblia. Ten en cuenta que los he limitado a los que aparecen 25 o más veces para que sea un poco legible.

Figura 8.3: Grafo de los bigramas más usuales en la Biblia. El primer elemento de bigrama es el punto y el segundo es la palabra que hay en la punta de la flecha
¿QUÉ ES UN GRAFO?
Un grafo es un dibujo que tiene vértices o nodos y aristas que unen los vértices entre sí. O dicho de otra manera, son puntos que se conectan unos con otros y lo que que representan es cómo se relacionan los vértices unos con otros y esto permite representar gráficamente las relaciones binarias entre los elementos de un conjunto. Un ejemplo clásico de un grafo es una red de ordenadores, en la que cada ordenador (o terminal) es un vértice y las conexiones entre ellos son las aristas que los unen.
La figura 8.4 es un grafo que corresponde a un pequeño susbconjunto del grafo de la figura 8.3 en el que puedes ver qué adjetivos se relacionan (mayoritariamente) con el sustantivo lado. Se trata de un grafo orientado puesto que muestra que al sustantivo lado le siguen los adjetivos que indican los cuatro puntos cardinales: norte, sur, oriental y occidental.
En Wikipedia puedes leerlo algo, elemental, sobre los grafos y la teoría de grafos.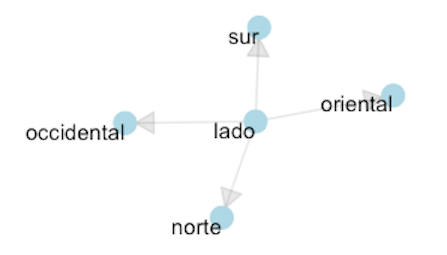
Figura 8.4: Grafo del sustantivo lado en la Biblia
Para hacer este tipo de grafos necesitarás dos librerías nuevas: {igraph} y {ggraph}. Así que instálalas.
y cárgalas junto con la librería {grid}, que es de los paquetes básicos de R.
Recuerda que solo tienes que instalar una vez las librerías, por lo general la primera vez que las usas.
Si alguna vez invocas una librería que no tienes instalada, R te responderá con un mensaje de error.
Error in library(NOMBRE_LIBRERÍA) : there is no package called ‘NOMBRE_LIBRERÍA’
install.packages("NOMBRE_LIBRERÍA")
El corpus que estás manejando es muy pequeñito, poco más de 6 000 bigramas, pero solo 15 de ellos tienen más de 10 ocurrencias, con lo que no vas a ser muy exigente y vas a considerar todos aquellos que tienen una ocurrencia de aparición mayor de 5 (> 5), lo cual te dará 82 bigramas. El grafo que obtendrás al final es el de la figura ??.
 > 5`) en los mensajes de Navidad
> 5`) en los mensajes de Navidad
Para realizar el grafo anterior ya tienes en la memoria del ordenador casi todo el material preparado. Tan solo tienes que hacer un recuento de los bigramas limpios, que son los que tienes recogidos en bigramas_filtrados, y que guardarás en recuento_bigramas
que es una tabla que tendrá 6833 observaciones y 3 variables. Échale una ojeada con recuento_bigramas e intro.
## # A tibble: 6,833 × 3
## palabra1 palabra2 n
## <chr> <chr> <int>
## 1 unión europea 31
## 2 crisis económica 22
## 3 sociedad española 22
## 4 pueblo español 19
## 5 convivencia democrática 13
## 6 debemos seguir 13
## 7 fuerzas armadas 13
## 8 fuerzas políticas 13
## 9 interés general 13
## 10 buena voluntad 11
## # ℹ 6,823 more rowsA continuación, crearás la lista con los datos necesarios para trazar el grafo. No hay que hacer mucho, de los cálculos se encarga la función graph_from_data_frame() de la librería igraph, la cual tomará de la tabla recuento_bigramas el nodo o vértice de partida (palabra1), el nodo de llegada (palabra2) y el valor numérico asociado a cada borde o arista (edge) que es lo que hay en n. El otro dato que has de proporcionar es el número mínimo de ocurrencias que ha de tener en cuenta para extraer los datos. Aquí la única regla sencilla es echarle una ojeada a recuento_bigramas con View() y tomar una decisión. La exploración de recuento_bigramas, como te he dicho, muestra que de los más de 6 000 bigramas que hay, los 82 primeros tienen una frecuencia de uso mayor que 5 (> 5), por lo que le indicas a filter() que ha de seleccionar solo aquellos casos que aparezcan 5 o más veces.
El contenido de la lista que se genera puede parecer críptico. Escribe grafo_bigramas en la consola y pulsa intro.
## IGRAPH e5685f6 DN-- 114 69 --
## + attr: name (v/c), n (e/n)
## + edges from e5685f6 (vertex names):
## [1] unión ->europea crisis ->económica sociedad ->española
## [4] pueblo ->español convivencia->democrática debemos ->seguir
## [7] fuerzas ->armadas fuerzas ->políticas interés ->general
## [10] buena ->voluntad cooperación->internacional debe ->ser
## [13] respeto ->mutuo vida ->colectiva boas ->festas
## [16] bon ->nadal eguberri ->on gran ->esfuerzo
## [19] gran ->familia gran ->nación on ->bon
## [22] sentirnos ->orgullosos comunidad ->internacional infanta ->sofía
## + ... omitted several edgesEsta tabla te informa de que es un grafo dirigido (D) en el que los nodos tienen nombre (N) y que hay 69 nodos y 41 aristas (edges). Hay dos atributos (attr), uno llamado name, que son las palabras que constituyen los diferentes bigramas, que servirán de nodos o vértices, y otro, n, que contiene los valores numéricos con los que trazará los bordes o aristas, las líneas que unirán los nodos. Después presenta unos pocos de los vértices o nodos, del que parte y al que llega unión -> europea, sociedad -> española, etc. La secuencia de letras y números que hay tras IGRAPH en la primera línea y a continuación de + edges from, en la tercera, es un identificador interno. Cuando lo ejecute varias varias veces, obtendrás diferentes números. Durante las pruebas he obtenido: 5d84511, 8cc180d, b138b783, 67ec22c y otros muchos. Si lo haces tú, aparecerán otros diferentes.
Ya solo queda dibujarlo. Para esto se utiliza la librería {ggraph} desarrollada para trazar las redes creadas por {igraph} porque esta no tiene grandes capacidades gráficas, no era su objetivo. Lo han diseñado para tener una sintaxis idéntica a la de {ggplot2}, librería a la que ya estás acostumbrado.
ggraph(grafo_bigramas, layout = "nicely") +
geom_edge_link() +
geom_node_point() +
geom_node_text(aes(label = name), vjust = 1, hjust = 1)La función básica es ggraph() que se comporta como ggplot(). Así que lo primero es decirle de dónde extraerá los datos. En este caso del objeto grafo_bigramas que has creado en el paso anterior y con layout = "" le indicas cómo los dispondrá. De los muchos algoritmos disponibles, he seleccionado nicely que determinará por sí mismo cómo disponer los nodos.
La función geom_edge_link() sirve para dibujar la línea que conectará los dos nodos: el de partida y el de llegada. geom_node_point() determina cómo será el dibujo del nodo y geom_node_text() se ocupa de imprimir las palabras que están guardadas dentro de un atributo de grafo_bigramas que se llama name y sobre lo que no tienes control alguno. vjust y hjust ajustan la situación tanto vertical como horizontal de las palabras, mejor dicho, de las etiquetas. Este sencillo sistema ofrece como resultado el grafo de la figura ??.
 > 5`) en los mensajes de Navidad
> 5`) en los mensajes de Navidad
Hacerlo más bonito, como el de la Biblia de la figura 8.3, como puedes suponer, complica la orden. Básicamente es la misma que has utilizado para dibujar el grafo de la figura ??. La primera y la última (ahora penúltima) líneas se mantienen idénticas. La nueva línea final theme_void() lo que hace es que no se imprima el fondo gris, la parrilla ni las etiquetas de los ejes x e y. A geom_node_point() lo que se le ha añadido es el detalle del color y el tamaño del punto del nodo con size.
ggraph(grafo_bigramas, layout = "nicely") +
geom_edge_link(aes(edge_alpha = n),
show.legend = FALSE,
arrow = arrow(type = "closed",
length = unit(3, "mm"))) +
geom_node_point(color = "lightblue", size = 3) +
geom_node_text(aes(label = name), vjust = 1, hjust = 1) +
theme_void()El código anterior dibujará el grafo de la figura ??, en el que tienes los detalles estéticos.
 > 5`) en los mensajes de Navidad con mejoras estéticas
> 5`) en los mensajes de Navidad con mejoras estéticas
La que realmente se ha complicado es la instrucción que dibuja las líneas que unen los nodos puesto que se le han añadido algunos aspectos estéticos con aes(). edge_alpha lo que hace es que los enlaces entre los dos elementos del bigrama sean más o menos transparentes basándose en el número de ocurrencias almacenado en n, lo que ayuda a ver cuáles son más frecuentes (cuanto más oscuro). La función show_legend = FALSE evita que en el margen derecho se imprima una leyenda con los valores. Aquí no interesa, en otras ocasiones puede que sí. La función arrow es cómo se dibujará la punta de la fecha que indica en qué dirección va el enlace; el argumento type puede ser closed o open y length especifica la altura de la punta de flecha. He usado como unidad mm, pero la mayoría de los estadistas usan pulgadas (inches), aunque hay otras posibilidades.
8.6 Coocurrencias
A veces puedes estar interesado en analizar qué palabras tienden a coaparecer en un texto determinado (cf. figura 8.1), incluso si están en capítulos o párrafos diferentes. Este tipo de análisis es posible por medio de la llamada comparación por pares (pairwise), un método que se emplea mucho en las ciencias sociales. Con esto puedes contabilizar qué palabras coaparecen en cada sección (párrafo en este caso) de los textos. La matemática que hay detrás es compleja, como muchas otras que estás empleando, pero no tienes que preocuparte por ello (aunque deberías de empezar a estudiar algo de estadística). Los programadores de las librerías han creado funciones que te permiten realizar estos análisis y representarlos con gran sencillez sin tener en cuenta las fórmulas que subyacen. La función que hará la comparación por pares está en una librería llamada {widyr}. Instálala.
y, obviamente, cárgala.
Puesto que tendrás en la memoria el objeto mensajes que tiene todos los mensajes de Navidad, vas a extraer de él todos los mensajes del rey Juan Carlos I y renumerarás todos y cada uno de los párrafos consecutivamente, con independencia del año en el que lo pronunció. Además, lo dividirás en palabras-token y eliminarás las palabras vacías.
mensajes_rey <- mensajes %>%
filter(rey =="Juan Carlos I") %>%
mutate(seccion = row_number()) %>%
unnest_tokens(palabra, texto) %>%
filter(!palabra %in% vacias$palabra)Aunque todas estas instrucciones las has visto antes, te recuerdo rápidamente qué hacen. El resultado lo guardarás en el objeto mensajes_rey. Primero extraerás de mensajes todos los mensajes de Juan Carlos I con la función filter(rey == "Juan Carlos I"). Crearás con mutate() una nueva variable (columna) que llamarás seccion que consiste en el número de la fila row_number(). Después lo dividirás en palabras-token con unnest_tokens() y eliminarás las palabras vacías con filter(). Si ejecutas en la consola
podrás ver parte del resultado.
## # A tibble: 22,999 × 5
## anno rey parrafo seccion palabra
## <fct> <fct> <dbl> <int> <chr>
## 1 1975 Juan Carlos I 1 1 fiestas
## 2 1975 Juan Carlos I 1 1 nochebuena
## 3 1975 Juan Carlos I 1 1 navidad
## 4 1975 Juan Carlos I 1 1 familias
## 5 1975 Juan Carlos I 1 1 españolas
## 6 1975 Juan Carlos I 1 1 acentúan
## 7 1975 Juan Carlos I 1 1 sentido
## 8 1975 Juan Carlos I 1 1 entrañable
## 9 1975 Juan Carlos I 1 1 parece
## 10 1975 Juan Carlos I 1 1 quisiéramos
## # ℹ 22,989 more rowsAhora lo dividirás en pares de palabras y las contabilizarás. Es algo parecido a lo que has hecho en los bigramas, pero esta vez con la función pairwise_count(). El resultado lo almacenarás en pares_palabras.
Una vez que ejecutes la orden anterior, que contará las palabras por sección, puedes ver el contenido (parcialmente) ejecutando en la consola
con lo que verás el comienzo de una grandísima tabla
## # A tibble: 437,220 × 3
## item1 item2 n
## <chr> <chr> <dbl>
## 1 españoles españa 62
## 2 españa españoles 62
## 3 españoles año 36
## 4 año españoles 36
## 5 españa año 33
## 6 año españa 33
## 7 buenas noches 33
## 8 noches buenas 33
## 9 españa paz 31
## 10 paz españa 31
## # ℹ 437,210 more rowscon 437220 filas con parejas de palabras que coaparecen en cada párrafo de los mensajes. Se parece a la tabla en la que separaste los bigramas en dos (palabra1, palabra2), solo que ahora se llaman item1 e item2 (las nombra así la función, por lo que no merece la pena enredar). Parece que españoles es la palabra con mayor número de ocurrencias y, posiblemente, de coapariciones. Verlas es muy sencillo con filter().
Cuando ejecutes la expresión anterior, aparecerá en la consola una tabla más reducida.
## # A tibble: 1,660 × 3
## item1 item2 n
## <chr> <chr> <dbl>
## 1 españoles españa 62
## 2 españoles año 36
## 3 españoles paz 24
## 4 españoles familia 24
## 5 españoles futuro 20
## 6 españoles afecto 20
## 7 españoles corona 18
## 8 españoles quiero 17
## 9 españoles deseos 16
## 10 españoles ser 15
## # ℹ 1,650 more rowsEs decir, hay 1 660 posibles coapariciones de españoles y que la coocurrencia más usual es españoles y españa, con 62 casos. Pero esto no es muy significativo puesto que son, por sí, las palabras con mayor frecuencia de aparición (280 y 186 ocurrencias respectivamente) en el corpus. Lo que te interesa es examinar la correlación que existe entre las palabras, lo cual te indicará cuán a menudo aparecen juntas con referencia a cuántas veces están separadas. Lo que aquí se busca, ¡horror!, es el coeficiente phi. Este estadístico se centra más en ver si ambas palabras aparecen juntas que en comprobar que no lo hacen. De nuevo, la matemática es enredada, pero {widyr} tiene una función que se va a ocupar de hacer las cuentas. Se trata de pairwise_cor() y la sintaxis es idéntica a la de pairwise_count(). Copia estas líneas de código.
palabras_correlacion <- mensajes_rey %>%
group_by(palabra) %>%
filter(n() >= 5) %>%
pairwise_cor(palabra,
seccion,
sort = TRUE)Lo que vas a hacer es guardar el resultado del cálculo en palabras_correlacion y los datos para el cálculo los sacarás de mensajes_rey. Para ello tienes que agrupar los datos con group_by() por medio de la variable palabra. Solo considerará, para ello usarás filter(), aquellas palabras cuya frecuencia de aparición sea mayor o igual a 5 (>= 5) y, por último, calculará el coeficiente phi. El resultado debe ser (tras escribir en la consola palabras_correlación y pulsar intro)
## # A tibble: 1,082,640 × 3
## item1 item2 correlation
## <chr> <chr> <dbl>
## 1 buenas noches 0.942
## 2 noches buenas 0.942
## 3 asturias príncipe 0.816
## 4 príncipe asturias 0.816
## 5 competitividad innovación 0.790
## 6 innovación competitividad 0.790
## 7 tráfico inmigración 0.670
## 8 inmigración tráfico 0.670
## 9 felices pascuas 0.666
## 10 pascuas felices 0.666
## # ℹ 1,082,630 more rowsLo que has realizado en esta ocasión es el coeficiente de correlación que sirve para comprobar, y medir, la fuerza y la dirección de una relación lineal entre dos variables. El resultado de este estadístico es siempre un número comprendido entre +1 y -1, por lo que sabrías que el uso de uno de los términos aumenta mientras que el otro disminuye proporcionalmente. 0 indica que no hay relación lineal alguna. Esa es la información que te ofrece la columna correlation. Por lo tanto, cuanto más alejado esté el coeficiente de 0, la dependencia entre las dos variables (palabras en este caso) es mayor y, por consiguiente, cuanto más cerca esté de 0 será menor. No hay una regla fija para interpretar los datos de correlacion. La tabla 8.1, sin embargo, te puede echar una mano.
| -.1 | Relación lineal descendente (negativa) perfecta |
| -.7 | Relación lineal descendente (negativa) fuerte |
| -.5 | Relación lineal descendente (negativa) moderada |
| -.3 | Relación lineal descendente (negativa) débil |
| 0 | No existe relación lineal |
| +.3 | Relación lineal ascendente (positiva) débil |
| +.5 | Relación lineal ascendente (positiva) moderada |
| +.7 | Relación lineal ascendente (positiva) fuerte |
| +1 | Relación lineal ascendente (positiva) perfecta) |
Este tipo de resultado te permite examinar cuáles son las palabras que pueden aparecer más correlacionadas con un término como terrorismo. Es algo que puedes hacer, de nuevo, con filter():
Al ejecutar la orden anterior puedes ver el comienzo de la tabla con los resultados.
## # A tibble: 1,040 × 3
## item1 item2 correlation
## <chr> <chr> <dbl>
## 1 terrorismo víctimas 0.479
## 2 terrorismo acabar 0.314
## 3 terrorismo amenazas 0.248
## 4 terrorismo familias 0.206
## 5 terrorismo lucha 0.204
## 6 terrorismo cooperación 0.186
## 7 terrorismo inocentes 0.183
## 8 terrorismo terror 0.183
## 9 terrorismo emocionado 0.177
## 10 terrorismo internacional 0.170
## # ℹ 1,030 more rowsA partir de estos cálculos, puedes obtener un gráfico, como el de la figura 8.5, con las palabras que se relacionan con algunas de las que nos hablan de los temas más candentes en los discursos del rey: constitución, terrorismo, crisis, libertades, país.
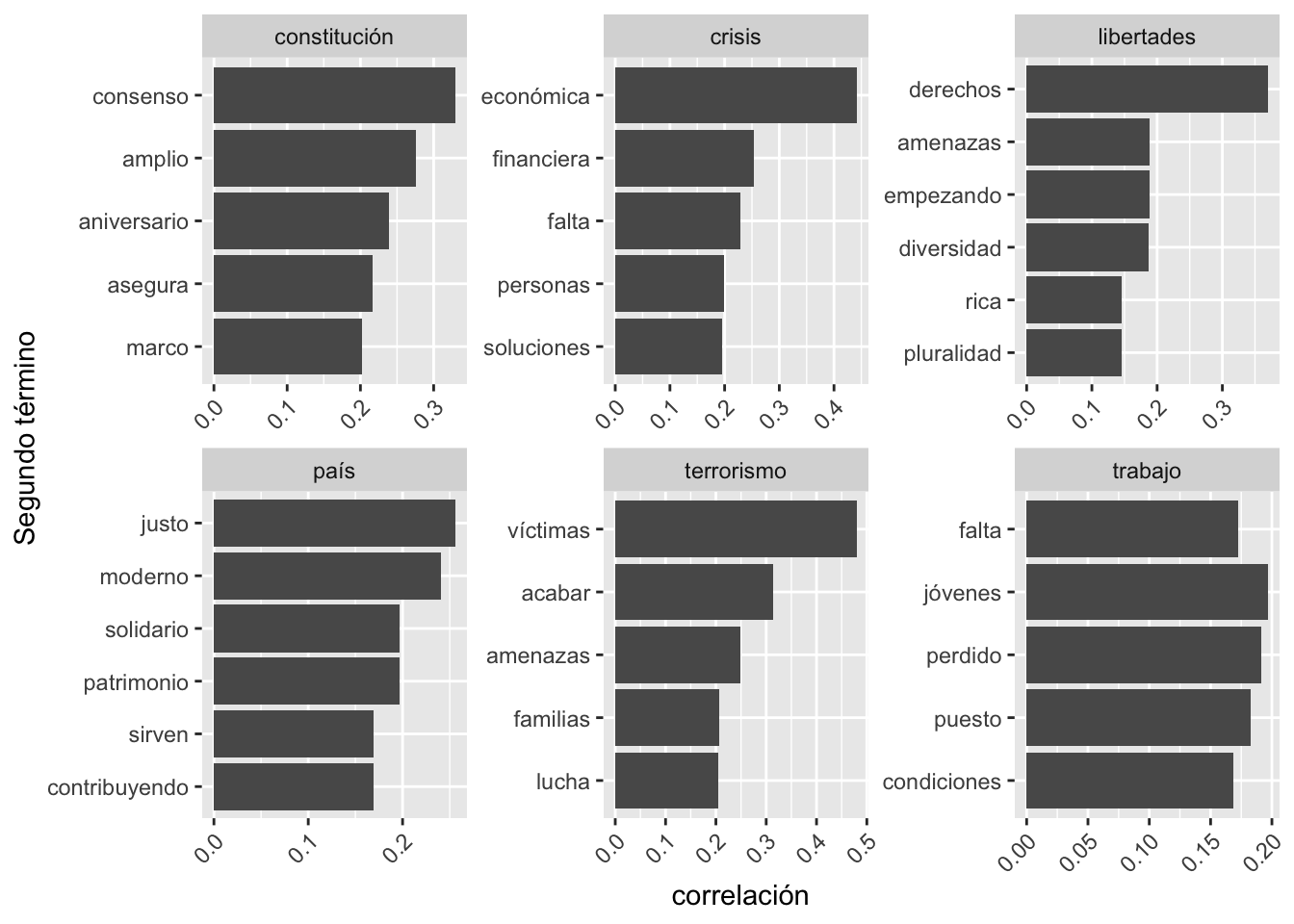
Figura 8.5: Palabras que más se correlacionan con constitución, terrorismo, crisis, libertades y país
En la consola se habrá impreso el mensaje
## Selecting by correlationque te indica que la selección para trazar el gráfico se ha hecho por medio de la columna correlation. Los seis gráficos de la figura 8.5 los consigues con este bloque de código:
palabras_correlacion %>%
filter(item1 %in% c("constitución",
"terrorismo",
"crisis",
"libertades",
"país",
"trabajo")) %>%
group_by(item1) %>%
top_n(5) %>%
ungroup() %>%
mutate(item2 = reorder(item2, correlation)) %>%
ggplot(aes(item2, correlation)) +
geom_bar(stat = "identity") +
facet_wrap(~ item1, scales = "free") +
coord_flip()No te lo explico, todo lo que hay en estas líneas te lo he contado con anterioridad. Trata de desentrañarlo tú, y juega con las palabras de filter() para ver otros casos interesantes (europa, fronteras, extranjeros, patrimonio, hombres, mujeres, política, etc.).
Correlación en el eje Y y Segundo término en el eje X. En algún capítulo anterior (cfr. [Más gráficos con {ggplot2}]) te he contado como se hace. La solución, como de costumbre, la tienes al final del capítulo9.
De la misma manera que trazaste un grafo para visualizar la red que conformaban los bigramas, también se puede trazar un grafo para ver los grupos (agrupaciones) de palabras que se dan en los mensajes de navidad del rey Juan Carlos I, como puedes ver en la figura 8.6.

Figura 8.6: Red de palabras en los mensajes de Navidad del rey Juan Carlos I
El código es parecido al de los grafos de los bigramas.
palabras_correlacion %>%
filter(correlation > .35) %>%
graph_from_data_frame() %>%
ggraph(layout = "nicely") +
geom_edge_link(aes(edge_alpha = correlation), show.legend = FALSE) +
geom_node_point(color = "lightblue", size = 5) +
geom_node_text(aes(label = name), repel = TRUE) +
theme_void()datos/mensajes, así que busca cómo solventar este pequeño escollo.
library(tidyverse)
anno <- c(1937:1939,1946:1974)
ruta <- "https://raw.githubusercontent.com/7PartidasDigital/AnaText/master/datos/mensajes/"
for (i in 1:length(anno)){
discurso <- read_lines(paste(ruta,
anno[i],
".txt",
sep = ""),
locale = default_locale())
write_lines(discurso,
paste(anno[i],
".txt",
sep = ""))
}.txt al final de cada año, como en los mensajes de Navidad.

En México, EE. UU., Argentina y Chile se pueden encontrar rebanadas de pechuga de pavo, de queso, de carne… Recuerda que en lingüística no se puede decir: No se usa, no existe.↩︎
Tienes que añadir estas líneas de código
theme(legend.position = 'none', axis.text.x = element_text(angle = 45, hjust = 1))ylabs(x = "Segundo término", y = "correlación"). Recuerda poner un+al final la primera línea. Para regresar pulsa↩︎