4 Avance en el análisis textual
4.1 Introducción
En el capítulo anterior aprendiste a leer un único texto, a dividirlo en palabras-token, a averiguar cuántas palabras-tipo tenía, a dividirlo en oraciones, a establecer cuántas oraciones tenía cada párrafo, cuántas palabras había en cada una de ellas, cuántas letras tenía cada palabra e, incluso, a representar algunos datos en una gráfica. Ahora vamos a complicar la cosa. Vas a leer los 49 Mensajes de Navidad de los reyes de España; los vas a almacenar en una única tibble y vas a realizar un primer análisis exploratorio de todos los mensajes.
Se supone que tienes en el ordenador un directorio llamado cuentapalabras y dentro de él debe haber una subcarpeta que se llama datos y dentro de esta tiene que haber otra llamada mensajes con todos los mensajes de Navidad identificados con el número de año y la extensión .txt. Compruébalo.
Arranca RStudio. Comprueba si en el borde superior, junto al hexágono duce cuentapalabras. Si no es así, haz clic en ese desplegable que, probablemente, dirá Project: (None). Una vez se haya desplegado, mira a ver si está cuentapalabras. Si es así, haz clic sobre el nombre; en caso contrario haz clic en Open Project… y navega por el ordenador hasta localizar el directorio cuentapalabras; selecciónalo y cliquea en el botón Open. Esto hará que RStudio se reinicie. Comprueba ahora en la pestaña Files que está el directorio datos. Haz clic sobre él. Aparecerá el contenido de datos. Dentro de él debe haber un directorio que se llama mensajes. Haz clic en él. Una vez que lo hayas hecho, en la ventana aparecerá la lista de los ficheros con los mensajes de Navidad. Deberá tener el mismo aspecto que el de la figura 4.1.
Figura 4.1: Contenido (parcial) de cuentapalabras/datos/mensajes
También lo puedes comprobar si escribes en la consola
el resultado tiene que ser
## [1] "1975.txt" "1976.txt" "1977.txt" "1978.txt" "1979.txt" "1980.txt" "1981.txt" "1982.txt" "1983.txt"
## [10] "1984.txt" "1985.txt" "1986.txt" "1987.txt" "1988.txt" "1989.txt" "1990.txt" "1991.txt" "1992.txt"
## [19] "1993.txt" "1994.txt" "1995.txt" "1996.txt" "1997.txt" "1998.txt" "1999.txt" "2000.txt" "2001.txt"
## [28] "2002.txt" "2003.txt" "2004.txt" "2005.txt" "2006.txt" "2007.txt" "2008.txt" "2009.txt" "2010.txt"
## [37] "2011.txt" "2012.txt" "2013.txt" "2014.txt" "2015.txt" "2016.txt" "2017.txt" "2018.txt" "2019.txt"
## [46] "2020.txt" "2021.txt" "2022.txt" "2023.txt"Antes de seguir abre el editor de RStudio (File > New File > RScript), así podrás guardar todo el trabajo que hagas en este capítulo.
intro, tan solo cambia de línea para que sigas escribiendo. Para que se ejecute tienes que situarte en la línea de código que quieres y pulsar a la vez control (cmd en Mac) e intro o bien hacer clic en el botón →Run que hay en la parte superior derecha del marco del editor de RStudio.
Lo primero es cargar las dos librerías básicas.
Ya sabes que cuando se carga {tidyverse} te informa de una serie de detalles. Puedes pasar de ellos tranquilamente. No volveré a recordarte la existencia de estas advertencias, ni se imprimirán en las páginas que quedan de este libro.
4.2 Leer los mensajes
Son 49 ficheros. Cargarlos uno a uno, como te mostré en el capítulo anterior, es una pésima solución. Hay una forma sencilla de hacerlo, pero requiere varias líneas de código.
Lo primero es indicarle a R cómo se llaman los ficheros que quieres analizar. Para eso utilizarás la función list.files(). Puedes usarla sin ningún argumento, pero eso te podría originar problemas si el directorio, como suele ocurrir, tiene una mezcla de cosas, aunque no debería ser el caso. Para solucionarlo tienes a tu disposición el atributo pattern = "" que sirve para indicarle qué ficheros debe elegir. Se supone que en la carpeta mensajes solo tienes los ficheros de los mensajes y todos están nombrados de la misma manera: aaaa.txt, donde aaaa es un número entre 1975 y 2023, y lo que quieres es leer todos los ficheros txt. La forma de indicárselo es con "txt", donde el asterisco le indica que solo debe leer los ficheros que tengan el sufijo txt. Además, tienes que indicarle que no están en el directorio de trabajo, sino en una subsubcarpeta llamada mensajes. Para eso se emplea el argumento path = "". La expresión será
Tan pronto como la ejecutes (control intro), la respuesta de la consola será:
## [1] "1975.txt" "1976.txt" "1977.txt" "1978.txt" "1979.txt" "1980.txt" "1981.txt" "1982.txt" "1983.txt"
## [10] "1984.txt" "1985.txt" "1986.txt" "1987.txt" "1988.txt" "1989.txt" "1990.txt" "1991.txt" "1992.txt"
## [19] "1993.txt" "1994.txt" "1995.txt" "1996.txt" "1997.txt" "1998.txt" "1999.txt" "2000.txt" "2001.txt"
## [28] "2002.txt" "2003.txt" "2004.txt" "2005.txt" "2006.txt" "2007.txt" "2008.txt" "2009.txt" "2010.txt"
## [37] "2011.txt" "2012.txt" "2013.txt" "2014.txt" "2015.txt" "2016.txt" "2017.txt" "2018.txt" "2019.txt"
## [46] "2020.txt" "2021.txt" "2022.txt" "2023.txt"Pero como esa información la usarás para hacer más cosas, tienes que guardarla en algún sitio. Qué mejor que un vector de caracteres llamado ficheros. Así, pues, la orden completa es:
Una vez hayas ejecutado la orden anterior, aparecerá en la pestaña Environment la palabra ficheros y a su lado la secuencia chr [1:49] "1975.txt" "1976.txt"…. Si lo ves, es que todo ha ido bien. Otra forma de comprobarlo es escribir en la consola
Una vez que pulses intro el resulta debería ser idéntico a lo que has hecho un poco antes.
## [1] "1975.txt" "1976.txt" "1977.txt" "1978.txt" "1979.txt" "1980.txt" "1981.txt" "1982.txt" "1983.txt"
## [10] "1984.txt" "1985.txt" "1986.txt" "1987.txt" "1988.txt" "1989.txt" "1990.txt" "1991.txt" "1992.txt"
## [19] "1993.txt" "1994.txt" "1995.txt" "1996.txt" "1997.txt" "1998.txt" "1999.txt" "2000.txt" "2001.txt"
## [28] "2002.txt" "2003.txt" "2004.txt" "2005.txt" "2006.txt" "2007.txt" "2008.txt" "2009.txt" "2010.txt"
## [37] "2011.txt" "2012.txt" "2013.txt" "2014.txt" "2015.txt" "2016.txt" "2017.txt" "2018.txt" "2019.txt"
## [46] "2020.txt" "2021.txt" "2022.txt" "2023.txt"Vas a necesitar el número de cada año para identificar cada uno de los textos según los leas y guardes en la tabla que vas a crear. Para ello vas a usar el objeto anno (no se te ocurra usar la ñ ni letras acentuadas, te pueden dar problemas infinitos). Esos números ya los tienes guardados en ficheros, por lo que los vas a extraer de ahí. Pero no solo tienes los números de los años, sino también el punto y las tres letras del sufijo (.txt). Tienes que borrar esto último y para ello usarás la función gsub(), que hace uso de las reglas de expresión regular.
grep: grepl, sub, gsub, regexpr, gregexpr y regexec, o cuando exija un argumento pattern = "", los metacaracteres del tipo \d, \s, \w, \., etc. tienen que llevar obligatoriamente una doble barra \\d, \\s, \\w, \\., etc. para que R los interprete correctamente.
La orden completa para hacerlo es
Le dice a R que busque en todos los elementos del objeto ficheros la secuencia .txt (\\. es para que R sepa que tiene que buscar un . no cualquier carácter, que es lo que quiere decir el . en las reglas de expresión regular) y la borre, por eso no hay nada entre las comillas que hay en la segunda línea. Lo que quiere decir gsub es sustitución global, o sea, busca y reemplaza, pero con ciertas condiciones.
perl = TRUE es para asegurarte de que las reglas de expresión regular funcionan de una manera determinada porque, contrariamente a lo pudieras creer, hay varios formas, flavours dicen los informáticos, de expresiones regulares.
Para comprobar que se ha realizado bien la orden anterior, ejecuta en la consola
Deberá imprimirse en la pantalla la secuencia 1975 … 2023.
## [1] "1975" "1976" "1977" "1978" "1979" "1980" "1981" "1982" "1983" "1984" "1985" "1986" "1987" "1988"
## [15] "1989" "1990" "1991" "1992" "1993" "1994" "1995" "1996" "1997" "1998" "1999" "2000" "2001" "2002"
## [29] "2003" "2004" "2005" "2006" "2007" "2008" "2009" "2010" "2011" "2012" "2013" "2014" "2015" "2016"
## [43] "2017" "2018" "2019" "2020" "2021" "2022" "2023"Todos los números deben estar entrecomillados esto te recuerda que el contenido de anno es un vector de caracteres. Puedes comprobarlo en la consola con
que te responderá con
## [1] "character"Has utilizado el patrón .txt para leer todos los ficheros que tienes en el directorio datos/mensajes. Ahora imagina que en esa misma carpeta tienes otros ficheros llamados mensajes.txt, resultados.txt y solo quieres leer aquellos cuyo nombre está conformado únicamente por números, puesto que son los que tienes que procesar. ¿Cómo lo harías?
Los ficheros que leerás del disco duro los tienes que guardar en una tabla. Como vas a usar un bucle for para leerlos, tienes que crear previamente una tabla vacía para que los almacene uno detrás de otro. Llamarás a la tabla mensajes. La instrucción es
La función tibble() creará una tabla vacía que tendrá tres columnas llamadas anno, parrafo y texto. La primera y la tercera contendrán caracteres –character()– mientras que la primera tendrá valores numéricos –numeric()–. Cuando ejecutes esta instrucción, no aparecerá nada en la consola, pero échale una mirada a la pestaña Environment, se habrá imprimido debajo de una línea etiquetada Data esta información: mensajes 0 obs. of 3 variables. Eso quiere decir que has creado la tabla llamada mensajes con tres columnas (variables) y ninguna línea (observación). Es decir, está vacía.
También la puedes crear sin mayores complicaciones con
Después el mismo sistema se encargará de ver de qué tipo es cada varible y cómo se ha de llamar, pues tendrás que declararlas en otro lugar.
Ahora hay que rellenarla y para ello usarás un bucle for. Ya lo usaste para bajar los mensajes de Navidad, por lo que ya conoces su estructura, aunque hay una ligera variación en el sistema de control. Copia todas las líneas en el editor de RStudio y, a continuación, te explico qué es lo que hará el bucle paso por paso.
for (i in 1:length(ficheros)){
discurso <- readLines(paste("datos/mensajes",
ficheros[i],
sep = "/"))
temporal <- tibble(anno = anno[i],
parrafo = seq_along(discurso),
texto = discurso)
mensajes <- bind_rows(mensajes, temporal)
}La forma de decirle a R cuál es el número máximo de ficheros que ha de leer es con la función length(), que ya has visto. Entre los paréntesis le indicas de qué objeto debe extraer la longitud, en este caso ficheros, y que debe dar tantas vueltas como elementos haya en ficheros y comience la cuenta en 1.
La siguiente línea lo que hace es guardar en discurso un fichero, el cual ha leído del disco duro con la función readLines(). El único argumento que necesita es el del nombre del fichero, pero como los tienes en un directorio llamado datos/mensajes, debes de añadirlo al nombre del fichero. Para eso se usa la función paste() que junta "datos/mensajes" con el contenido de ficheros[i], cuyo valor cambiará en cada iteración del bucle. Puesto que es un directorio, el pegamento con el que unirás ambos elementos es una /, y la forma de decirle a R cuál es el adhesivo es con el argumento sep = "/". (¡Ojo a los paréntesis!).
El paso siguiente es convertir en una tabla el fichero que acabas de leer. Como en cada paso leerá un texto diferente, usarás una tabla intermedia que llamarás temporal. Para crearla usarás la función tibble(). Los argumentos, creo que los recuerdas, son anno, que es el año en el que se emitió y lo extraes del objeto anno; parrafo es el número de cada uno de los párrafos que constituyen cada mensaje navideño. Esto lo construye R con la función seq_along(), que lo que hace es decirle: ponte a contar hasta el número máximo de elementos que haya en discurso y guarda cada uno de esos números en la casilla correspondiente de la columna parrafo. El último argumento es texto, es el nombre de la columna en la que se almacenará el texto (cada párrafo) del mensaje leído.
Todo esto crea una tabla cuyo aspecto es como este, que corresponde al comienzo del mensaje de 2023. Lo puedes ver en tu consola si ejecutas temporal y pulsas intro.
## # A tibble: 34 × 3
## anno parrafo texto
## <chr> <int> <chr>
## 1 2023 1 Como cada Nochebuena, tengo la oportunidad de felicitaros la Navidad y de transmitiros…
## 2 2023 2 Las dificultades económicas y sociales que afectan a la vida diaria de muchos españole…
## 3 2023 3 Así pues, son muchas las cuestiones concretas que me gustaría abordar con vosotros hoy…
## 4 2023 4 Este año, nuestra Constitución ha cumplido 45 años. Durante estos años de vida democrá…
## 5 2023 5 No podemos olvidar que uno de nuestros grandes activos en democracia es, precisamente,…
## 6 2023 6 En Asturias en octubre pasado, señalé -y así lo creo-, que es con la unión, con el esf…
## 7 2023 7 Naturalmente, en España todo ciudadano tiene derecho a pensar, a expresarse y defender…
## 8 2023 8 Y esa unión, que tiene profundas raíces históricas y culturales, debe descansar sobre …
## 9 2023 9 Esos son los valores que nos cohesionan, que le dan fortaleza y permanencia a un siste…
## 10 2023 10 Y así los define y establece nuestra Constitución, que ha sido el mayor éxito político…
## # ℹ 24 more rowsEs decir, se trata de una tabla (A tibble) con 34 filas y 3 columnas que se llaman anno, parrafo y texto. La primera y la tercera son de caracteres –<chr>– y la segunda de números enteros –<int>–.
La última línea del bucle lo que hace es acumular en la tabla mensajes lo que hay en la tabla temporal en cada una de las vueltas del bucle. Lo tiene que hacer línea por línea porque quieres que se añada por debajo del mensaje anterior, por lo que usarás la función bind_rows(). Si no lo hicieras así, al final el contenido de mensajes sería el texto del último fichero leído porque al leer un nuevo fichero se borra el contenido de temporal y se sustituye por el del fichero que acaba de leer.
Cuando ejecutes el bucle, el ordenador leerá en milisegundos los 49 ficheros y los reunirá, uno debajo de otro, o, si prefieres, uno a continuación de otro, en una tabla que tendrá 1495 filas y 3 columnas. Para que veas el comienzo de este nuevo objeto, ejecuta en la consola
presentará la información básica de la tabla junto con las diez primeras líneas (párrafos) del mensaje del año 1975.
## # A tibble: 1,495 × 3
## anno parrafo texto
## <chr> <int> <chr>
## 1 1975 1 En estas fiestas de nochebuena y navidad en que las familias españolas acentúan su sen…
## 2 1975 2 El año que finaliza nos ha dejado un sello de tristeza, que ha tenido como centro la e…
## 3 1975 3 El hondo significado espiritual de estos días nos puede servir para recordar la actual…
## 4 1975 4 Fue un mensaje de paz, de unidad y de amor.
## 5 1975 5 Paz, que necesitamos para organizar nuestra convivencia. Pero que no se confunda con l…
## 6 1975 6 La unidad, necesaria para lograr la fortaleza que todo progreso demanda, que no elimin…
## 7 1975 7 Y un mensaje de amor que es la esencia de nuestro cristianismo, el cual nos exige sacr…
## 8 1975 8 En la alegría de esta noche no está quizá de más dejar paso a otros sentimientos; nues…
## 9 1975 9 Es difícil encerrar en pocas palabras todos mis sentimientos en esta navidad. Nada me …
## 10 1975 10 Los problemas que tenemos ante nosotros no son fáciles, pero si permanecemos unidos y …
## # ℹ 1,485 more rowsparrafo, en la segunda línea dice <dbl> mientras que en la tabla anterior decía <int>. No tienes nada de que preocuparte, R ha cambiado la precisión de los números de enteros –int– a doble precisión –dbl–. No tiene mayor importancia.
4.2.1 Dividir los textos en palabras-token
Ya estás preparado para iniciar el análisis de todos los mensajes de Navidad. Lo primero es dividirlos en palabras-token que guardarás en una tabla que llamarás mensajes_palabras.
%>%, pulsa intro. Pasará a la línea siguiente y la sangrará. Podrías no hacerlo, pero leer el código será una pesadilla. Al hacerlo así, verás las cosas un poco más claras.
Una vez que ejecutes la orden anterior, tendrás un objeto llamado mensajes_palabras que tendrá 3 columnas y 65362 líneas. Para que lo compruebes, ejecuta en la consola
El resultado será
## # A tibble: 65,362 × 3
## anno parrafo palabra
## <chr> <int> <chr>
## 1 1975 1 en
## 2 1975 1 estas
## 3 1975 1 fiestas
## 4 1975 1 de
## 5 1975 1 nochebuena
## 6 1975 1 y
## 7 1975 1 navidad
## 8 1975 1 en
## 9 1975 1 que
## 10 1975 1 las
## # ℹ 65,352 more rowsEsta tabla es poco informativa ya que lo único que ha hecho ha sido dividir los 49 mensajes en palabras, indicar el número del párrafo en el que se encuentra y el año en que se emitió. Tan solo sabes que esos 49 mensajes tienen en total 65362 palabras-token. Supongo que lo primero que querrías saber es el promedio de palabras de los 49 mensajes. Puedes averiguarlo dividiendo el número de total de palabras por el número de mensajes emitidos. Podrías hacerlo con esta expresión
que daría como resultado 1333.9183673 palabras por mensaje navideño. Pero he obtenido el dividendo y el divisor de dos sitios cuanto menos peculiares: del número de líneas (nrow) que tiene mensajes_palabras y la longitud (length) del vector ficheros, puesto que son los dos únicos que, a primera vista, tienen los datos necesarios. Pero la información que puedes obtener sigue siendo parca. La verdad es que dentro de mensajes_palabras hay mucha más información de interés, pero hay que extraerla. Recordarás del capítulo anterior que puedes averiguar cuántas palabras-tipo y qué frecuencia absoluta tiene cada una de ellas. Tan solo necesitas ejecutar esta expresión
que te responderá con el comienzo de una tabla.
## # A tibble: 6,652 × 2
## palabra n
## <chr> <int>
## 1 de 3966
## 2 y 3392
## 3 la 2542
## 4 que 2503
## 5 en 2006
## 6 a 1527
## 7 el 1368
## 8 los 1194
## 9 con 891
## 10 las 717
## # ℹ 6,642 more rowsAhora ya sabes cuántas palabras-tipo hay: 6652, y también cuántas veces se repite cada una de ellas (bueno, solo puedes ver las 10 primeras; si quieres verlas todas, escribe en la consola View(mensajes_palabras). Cuando pulses intro se abrirá una nueva pestaña en la ventana del editor y podrás recorrer toda la tabla. Fíjate que puedes leer el texto, pues todas las palabras se mantienen en el orden en el que estaban en el fichero original).
Saber cuántas veces aparece una palabra tampoco es muy informativo. Para que realmente quiera decir algo tiene que ser por medio de una proporción. Esa proporción se calcula dividiendo el número de veces que aparece cada palabra-tipo, es el valor de la columna n, por el total de palabras-token (la suma de todos los valores de la columna n: sum(n)). Para poderlo hacer con comodidad tienes que crear una columna, lo que se hace con el verbo (también puedes llamarlo función) mutate(), tienes que darle un nombre a esta nueva variable; en este caso la llamarás relativa. Por último, has de decirle qué es lo que quieres que almacene ahí. Para lograrlo tan solo hay que añadir una línea a la expresión anterior mutate(relativa = n / sum(n)). Así, pues, la orden completa es
cuyo el resultado será
## # A tibble: 6,652 × 3
## palabra n relativa
## <chr> <int> <dbl>
## 1 de 3966 0.0607
## 2 y 3392 0.0519
## 3 la 2542 0.0389
## 4 que 2503 0.0383
## 5 en 2006 0.0307
## 6 a 1527 0.0234
## 7 el 1368 0.0209
## 8 los 1194 0.0183
## 9 con 891 0.0136
## 10 las 717 0.0110
## # ℹ 6,642 more rowsComo puedes ver, ahora tienes una tabla de tres columnas. En una tienes cada una de las palabras (palabra), en la segunda la frecuencia absoluta (n), el número de veces que aparece cada una de ellas, y en la tercera la frecuencia relativa (relativa), es decir, la proporción que supone cada palabra dentro de todo el corpus. Pero ninguno de estos resultados se ha almacenado en ninguna parte. R tan solo ha hecho los cálculos porque no le has dicho que los guarde.
Puedes crear una tabla que recoja toda esta información para cuando te sea necesaria. Llámala mensajes_frecuencias. Y con una sola orden calculará las frecuencias absoluta y relativa y las almacenará en las variables (columnas) correspondientes. La línea de código definitiva es
mensajes_frecuencias <- mensajes_palabras %>%
count(palabra, sort = T) %>%
mutate(relativa = n / sum(n))El resultado tiene que ser idéntico a lo que has hecho un poco antes. La única diferencia es que ahora lo tienes guardado en un objeto llamado mensanjes_frecuencias. Lo puedes ver si ejecutas en la consola esta orden
que imprimirá la cabecera de la tabla de resultados.
## # A tibble: 6,652 × 3
## palabra n relativa
## <chr> <int> <dbl>
## 1 de 3966 0.0607
## 2 y 3392 0.0519
## 3 la 2542 0.0389
## 4 que 2503 0.0383
## 5 en 2006 0.0307
## 6 a 1527 0.0234
## 7 el 1368 0.0209
## 8 los 1194 0.0183
## 9 con 891 0.0136
## 10 las 717 0.0110
## # ℹ 6,642 more rowsmensajes_palabras? Pistas… Las funciones de R para calcularlo las viste en el capítulo anterior, al final, con las gráficas. Pero la respuesta la puedes encontrar al hacer clic en este numerito3.
4.2.2 Agrupar y filtrar los datos
Ahora una pregunta que te puedes hacer es si se pueden realizar los cálculos para cada año, o lo que es lo mismo, para cada uno de los mensajes. Sí. Lo único que hay que decirle a R es que los cálculos debe hacerlos agrupando las observaciones. Para esto está la función group_by(). Esta lo único que necesita es saber cuál es la variable por la cual agrupará los datos, puesto que nos interesa por años, la columna será anno. La orden es
frecuencias_anno <- mensajes_palabras %>%
group_by(anno) %>%
count(palabra, sort =T) %>%
mutate(relativa = n / sum(n)) %>%
ungroup()Lo que contiene frecuencias_anno son cuatro columnas: anno en el que se usa cada palabra, la palabra (palabra), la frecuencia absoluta por año (n) y la frecuencia relativa de cada palabra por cada año (relativa). Puedes verlo ejecutando en la consola
## # A tibble: 27,896 × 4
## anno palabra n relativa
## <chr> <chr> <int> <dbl>
## 1 1979 de 155 0.0650
## 2 1979 y 119 0.0499
## 3 1995 de 112 0.0662
## 4 2014 de 109 0.0663
## 5 2015 y 106 0.0629
## 6 1979 la 104 0.0436
## 7 1992 de 104 0.0709
## 8 2015 de 102 0.0605
## 9 2020 y 101 0.0595
## 10 1979 que 100 0.0419
## # ℹ 27,886 more rowsSe han ordenado por frecuencias absolutas (n), de mayor a menor, porque eso lo que le has ordenado en count(). Si en esa línea omitieras el argumento sort = T, el resultado sería alfabético por año, como puedes ver en este otro resultado.
## # A tibble: 27,896 × 4
## anno palabra n relativa
## <chr> <chr> <int> <dbl>
## 1 1975 1976 1 0.00174
## 2 1975 a 7 0.0122
## 3 1975 abre 1 0.00174
## 4 1975 acentúan 1 0.00174
## 5 1975 actuación 1 0.00174
## 6 1975 actualidad 1 0.00174
## 7 1975 adelante 1 0.00174
## 8 1975 admiración 1 0.00174
## 9 1975 al 3 0.00523
## 10 1975 alcanza 1 0.00174
## # ℹ 27,886 more rowsNo sé si se te habrá ocurrido pensar si es posible extraer solamente las palabras de un año y guardarlas en un tabla. Por supuesto que se puede hacer. Para eso está la función filter() en la que él único argumento necesario es indicar cuál es la columna que controlará la extracción. Puesto que quieres hacerlo por años, la columna será anno y de ella tan solo quieres los datos correspondientes al año 1992. La orden es
== ya que, ¡oh maravillas de la informática!, = sirve para asignar valores, pero ya te dije que no lo usaras. Es mejor limitarlo para los argumentos.
Una vez que lo hayas ejecutado, tendrás en la tabla palabras_1992 el recuento de todas las palabras: 650 palabras-tipo (palabra) y las frecuencias absoluta (n) y relativa (relativa) de cada una de ellas. Para verlo ejecuta en la consola esta orden
que imprimirá el comienzo de la tabla palabras_1992.
## # A tibble: 650 × 4
## anno palabra n relativa
## <chr> <chr> <int> <dbl>
## 1 1992 de 104 0.0709
## 2 1992 y 67 0.0457
## 3 1992 la 54 0.0368
## 4 1992 que 49 0.0334
## 5 1992 a 46 0.0314
## 6 1992 en 36 0.0246
## 7 1992 con 29 0.0198
## 8 1992 los 28 0.0191
## 9 1992 el 22 0.0150
## 10 1992 por 20 0.0136
## # ℹ 640 more rowsPero no sabes cuál es el número de palabras-token del mensaje de 1992. Es fácil averiguarlo. Basta con sumar la columna n de palabras_1992 (recuerda que el nombre de la tabla y el de la columna que quieres sumar, u operar, se unen con $).
El resultado tiene que ser
## [1] 1466relativa de palabras_1992? El resultado está tras este numerito4.
4.3 Más gráficos con {ggplot}
Mirar tablas puede ser muy aburrido y muy poco informativo. Ya viste en el capítulo anterior que puedes hacer gráficos fantásticos para presentar los resultados. Ahora no los vas a hacer espectaculares, tan solo informativos, como este gráfico de barras (figura 4.2) que informa de cuántas palabras tiene cada mensaje.
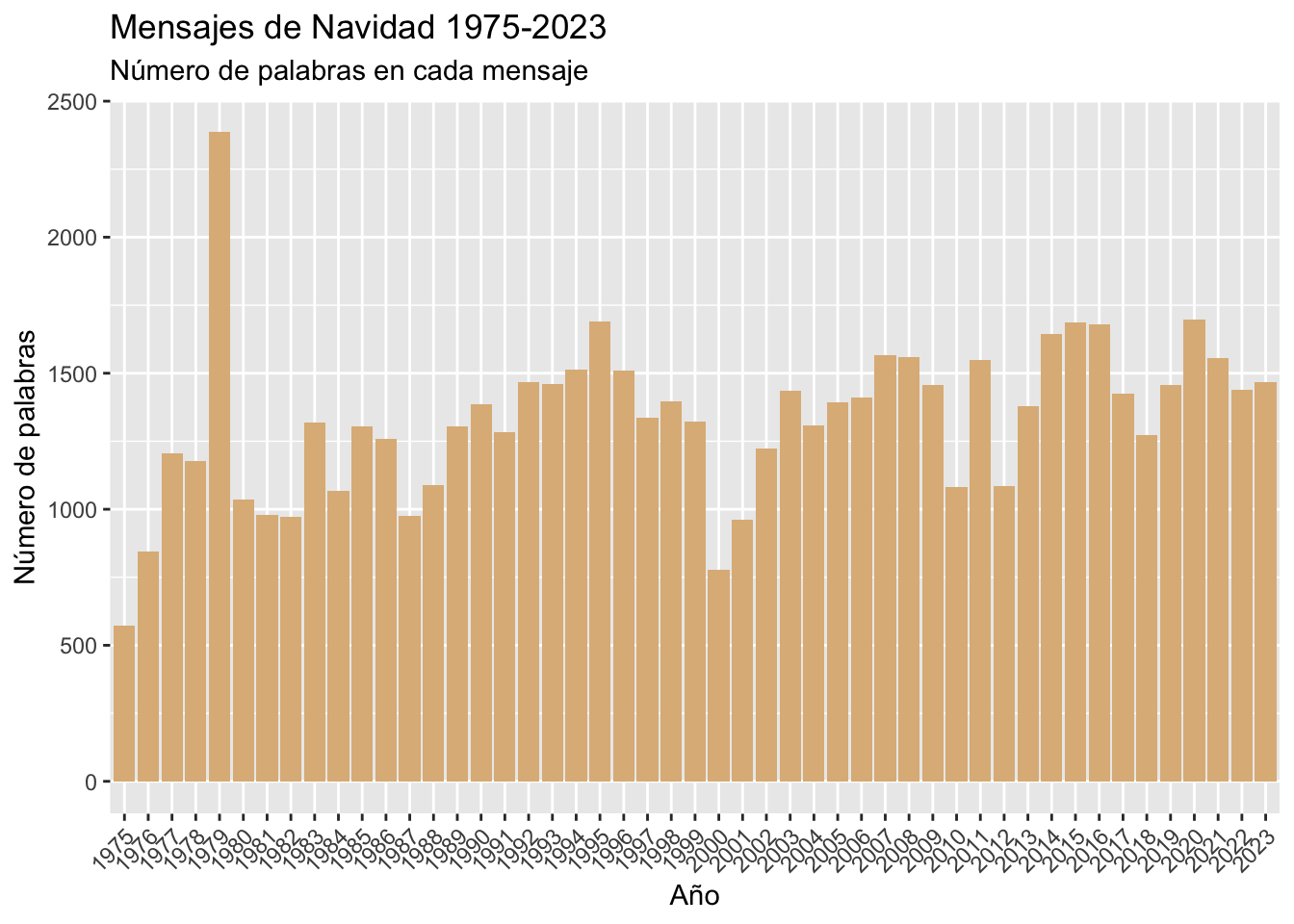
Figura 4.2: Gráfico que obtendrás al final del capítulo
La función ggplot() es la mejor para dibujar los gráficos. Copia estas líneas de código en el editor de RStudio.
mensajes_palabras %>%
group_by(anno) %>%
count() %>%
ggplot() +
geom_bar(aes(anno,
n),
stat = 'identity')Lo primero que le has dicho es que los datos que va a utilizar están en mensajes_palabras. Como lo que quieres es representar gráficamente la cantidad de palabras que contiene cada uno de los mensajes de Navidad, la única forma de hacerlo es agrupando los datos con group_by(), y la columna que sirve para controlarlo, es la del año anno. Por lo tanto, group_by(anno). Una vez agrupados los datos por años, tiene que contarlos. Para eso está count().
Por último, la instrucción, en dos líneas, para dibujarlo. De ello se encarga ggplot() y lo que ha de saber es el tipo de gráfico que tiene que dibujar. Como lo que quieres es uno de barras (también llamados histogramas), la función es geom_bar() y dentro de esta debes indicarle qué datos ha de usar de la tabla. Estos se indican con aes(), como lo que quieres es representar los años y cuántas palabras en cada uno de los mensajes de cada año, tienes que usar las variables anno (que será lo que se imprima en el eje X u horizontal) y n (en el eje Y o vertical), que es la que contiene la cantidad de palabras de cada uno de los mensajes. Con stat = 'identity' lo que se le indica a R es que la altura de las barras representa los valores de los datos.
Fíjate que al final de todas las líneas de código está el símbolo %>%, pero cuando llegas a ggplot() se cambia a +.
ggplot se concatenan con +, mientras que las ordenes fuera de los gráficos las has ido encadenando con %>%. Esto es muy importante. No lo olvides.
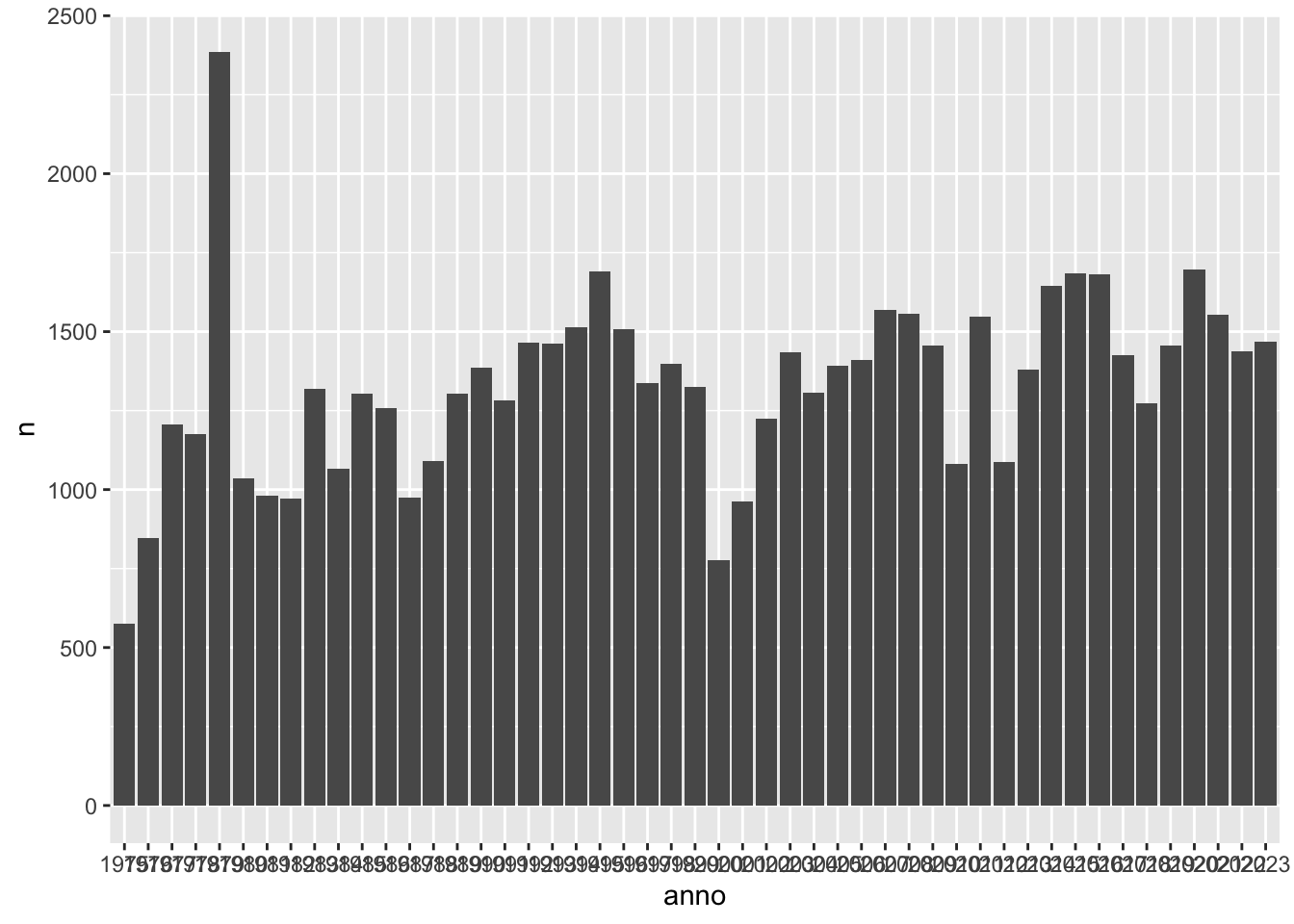
Figura 4.3: Primer paso del gráfico
Como puedes ver en la gráfica de la figura 4.3, los resultados aparecen ordenados por años, por lo que son como los dientes de un serrucho, lo que hace difícil ver en qué años fueron los discursos más extensos y cuándo los más breves. Se pueden reordenar las barras, para tener una mejor visión, con la función reorder(). Como el eje que hay que reordenar es el que refleja la variable categórica, es decir, los años, es el eje X el que ha de incluir la función reorder(). Esta tiene dos argumentos: la variable categórica considerada, anno, y la continua por medio de la cual se reorganizarán los años, que es las cantidades almacenadas en n.
mensajes_palabras %>%
group_by(anno) %>%
count() %>%
ggplot() +
geom_bar(aes(x = reorder(anno, n),
y = n),
stat = 'identity')Al ejecutar la orden anterior, se consigue una gráfica como la de la figura 4.4 en la que los mensajes se ordenan de menor a mayor.
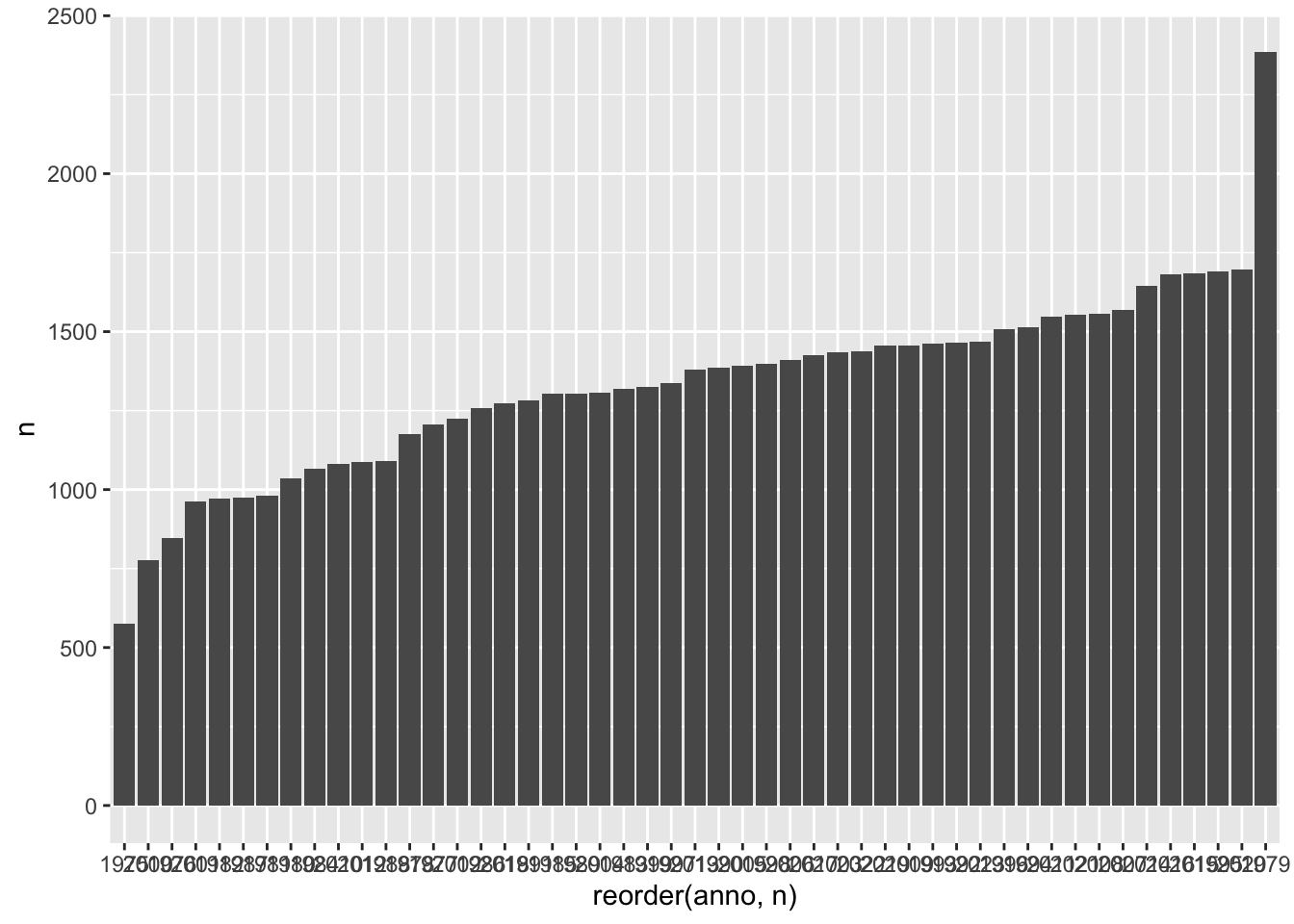
Figura 4.4: Años ordenados de menor a mayor número de palabras
Si quieres que sea de mayor a menor, entonces tienes que indicarle a reorder() que la variable que controla el orden de las barras es decreciente, y eso se consigue con -n. Sí, es algo absurdo, pero es así.
mensajes_palabras %>%
group_by(anno) %>%
count() %>%
ggplot() +
geom_bar(aes(x = reorder(anno, -n),
y = n),
stat = 'identity')por lo que tendrá la apariencia que muestra la figura 4.5.
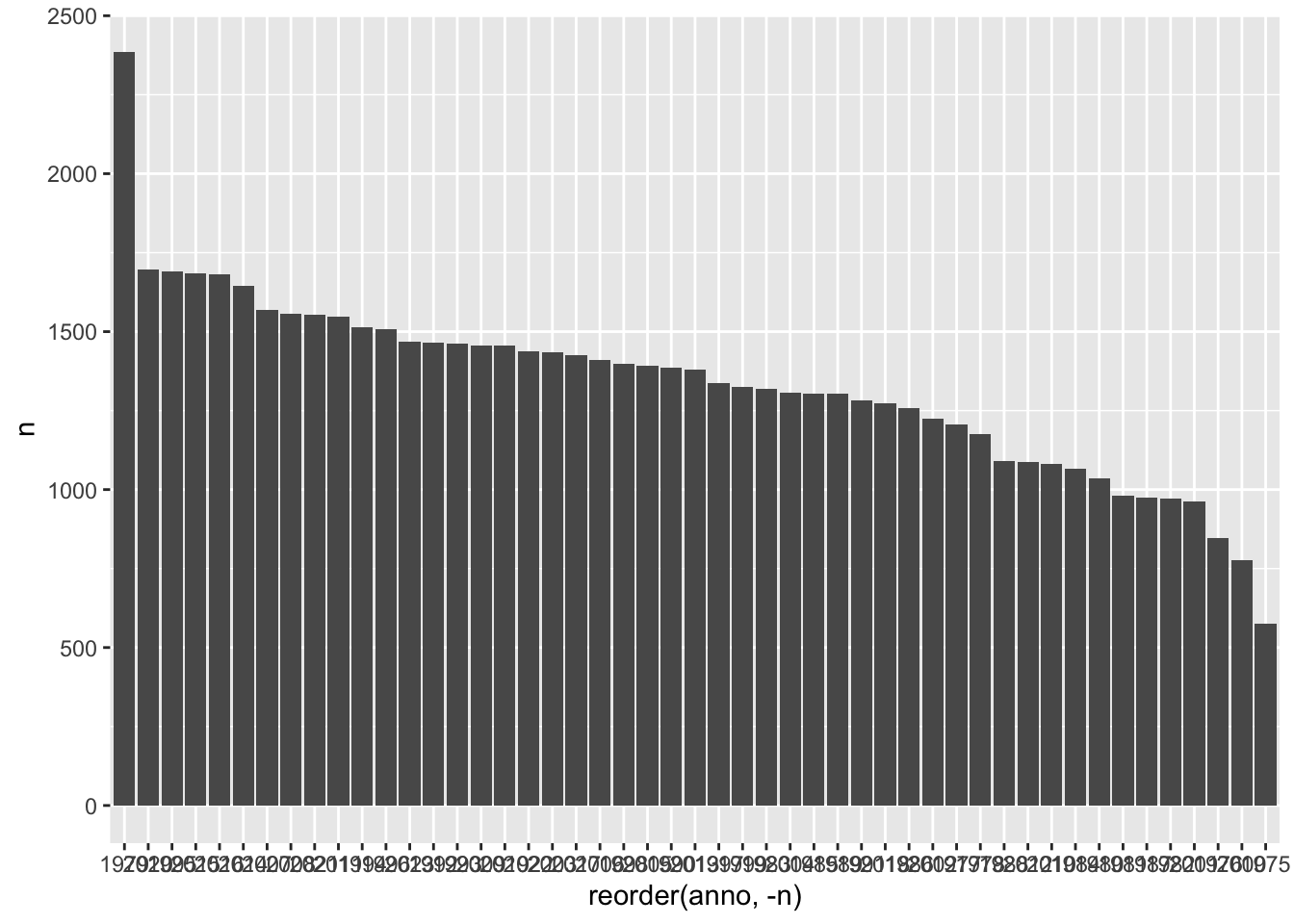
Figura 4.5: Años ordenados de mayor a mayor número de palabras
Ahora es mucho más sencillo ver cuál es el mensaje con más palabras y cuál es el que tiene menos. Se pueden añadir multitud de pequeños detalles: darle inclinación a los nombres de las variables de eje horizontal para que sean más fáciles de leer; añadir un título y un subtítulo al gráfico; incluir etiquetas qué indiquen que información ofrece el eje vertical y cambiar, si se cree pertinente, la etiqueta del eje horizontal. Y, por supuesto, colorearlo, como puedes ver en el gráfico de la figura 4.6.
Figura 4.6: El mismo gráfico con los elementos decorativos
Recuerdas que te dije que se podían complicar las líneas de código… Aquí tienes un buen ejemplo: el código para obtener el gráfico de la figura 4.6 es este.
mensajes_palabras %>%
group_by(anno) %>%
count() %>%
ggplot() +
geom_bar(aes(anno, n),
stat = 'identity',
fill = "lightblue") +
theme(legend.position = 'none',
axis.text.x = element_text(angle = 45,
hjust = 1)) +
labs(x = "Año",
y = "Número de palabras") +
ggtitle("Mensajes de Navidad 1975-2023",
subtitle = "Número de palabras en cada mensaje")
En
pattern = "", en vez de usar*.txttendrías que utilizar\\d+. De esta manera le estás diciendo a R que lea solamente aquellos ficheros cuyo nombre tenga uno o más números.ficheros <- list.files(path = "datos/mensajes", pattern = "\\d+")Para regresar pulsa↩︎
Las funciones son
mean()ymedian(). La forma de calcularlas es:mean(mensajes_frecuencias$n) # La mediay
median(mensajes_frecuencias$n) # La medianaPara regresar pulsa↩︎
Si pensaste que sería 100, estás equivocado. Ninguna de las frecuencias que has calculado es superior a 1. Fíjate en el cuadro de resultados que hay antes de la pregunta: todas las frecuencias, y son las de mayor ocurrencia, comienzan por
0.0. Para llegar a 100, tendrías que haber multiplicado por 100 cada una de las frecuencias cuando las calculastemutate(relativa = n / sum(n)*100)Para regresar pulsa↩︎